






Hdfs的存储模式
传统的hdfs都是使用三副本方式进行存储,一份数据需要消耗三份磁盘,而从hadoop3开始,它开始支持Erasure Coding(简写为ec),并且支持如6+3,10+4,分别可以使用1.5和1.4副本比来存储数据,这比3副本节省了一半甚至更多的磁盘,在当前降本的大背景下,不可谓不重要。我们这次不讨论ec的具体原理和运维操作,网上这方面的材料已经够多的了,大家如果需要了解,可自行搜索或者询问chatgpt。
hdfs ec的成本收益如此大,为什么在行业内却落地的不多呢,究其原因,很大一部分是因为大家大数据生态里面用到的spark,trino,hive等计算引擎的版本,很多也还都是依赖hadoop2.x环境,而使用hdfs2的client,无法使用hdfs3的ec功能,因为ec很多逻辑都实现在hdfs3的client上,要解决这个问题,可以:
- 升级这些计算组件到依赖hadoop3,这里面涉及的内容太多,一般的团队根本升不动
- 把hdfs3 client上ec的功能迁移到hdfs2的client中,这更是大多数团队无法胜任的。
所以这便阻碍了hdfs ec的落地,因此要让hdfs ec落地,需要一个更加简单的方案,能够在hadoop2 client环境中使用hdfs3 ec,这边对现有计算引擎不会产生任何环境上的改变。
H公司的ec落地方案
h公司从国内某垂直领域内Top的公司,大数据集群的数据在百P数据量的规模,所以格外重视成本优化。21年开始落地ec,到22年初,整个hadoop中85%的数据就都是ec存储,这意味这不仅仅温冷数据我们放ec,并且热数据也放ec,让整个大数据的综合存储副本比降到了1.7,节省了近一半的大数据存储成本。
我们落地ec方案时,也遇到了上面所说的hadoop2.x client环境无法使用hdfs3 ec的问题,但我们没有修改hadoop一行代码,即解决了此问题。下面是我们的解决方案逻辑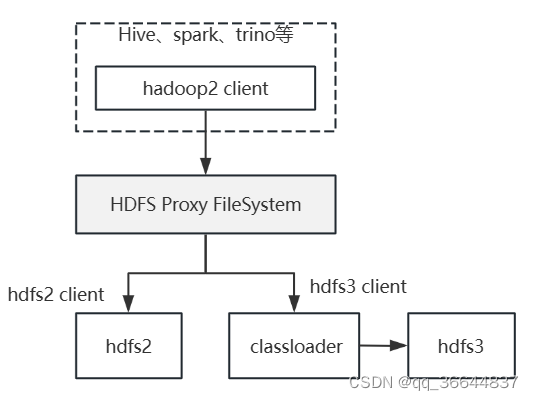
我们基于FileSystem重新实现了一个类,然后将hdfs协议映射到该类上,如:
<property>
<name>fs.hdfs.impl</name>
<value>hdfs3proxy.HDFS3ProxyFileSystemImpl</value>
</property>
在Proxy FileSystem中,根据path中namenode判定是hdfs2还是hdfs3,如果是hdfs3,则通过classloader,加载hdfs3的jar,而hdfs3的jar包,事先我们已经采用assembly的方式,将hdfs3所依赖的所有包然后外加HDFS3ProxyFileSystemImpl.class全部打了进去,形成hdfs3.jar,放到某个网络地址上,可以通过URL加载到该jar。如此便将hdfs2和hdfs3的环境给隔离开了。
类图如下
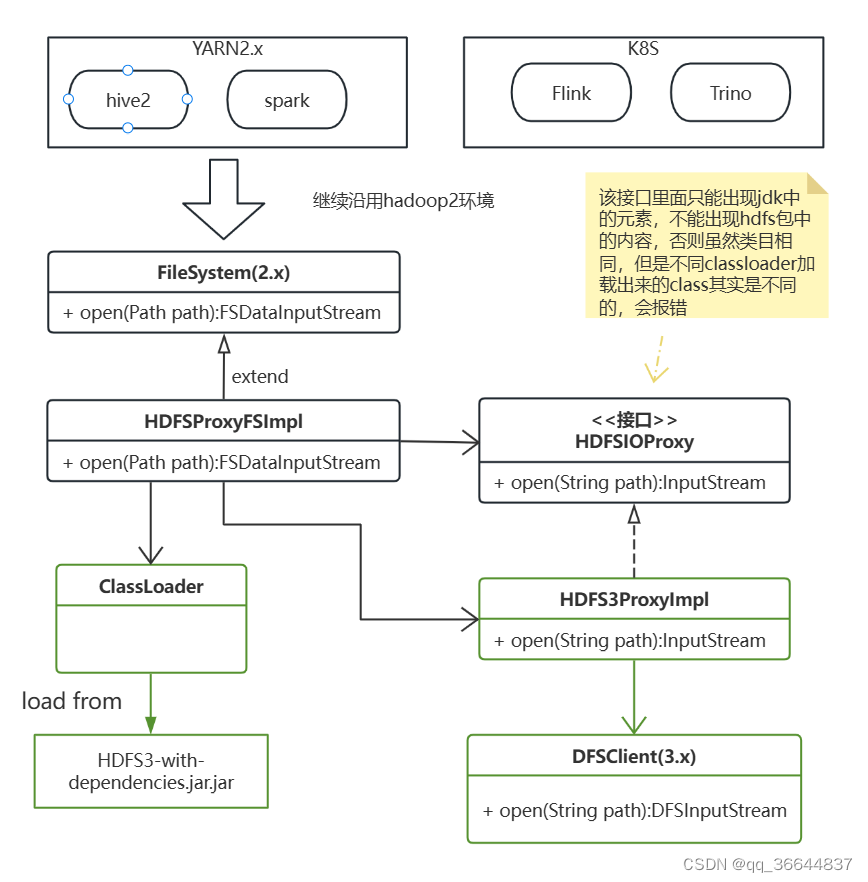
现在因为拿不到之前的源码了,我大概写了一下这块的程序框架来描述上面的基本思路,代码不是开箱即用的,只是为了描述大意,逻辑很简单,只是需要理解一下java的classloader机制即可。需要的同学欢迎去git上查阅git地址
需要私聊的,可以在视频号,公众号和B站等平台上搜索”数据人老桥“,为了发送私信
















 2340
2340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









