






开篇背景
在当前降本增效的大背景下,谁能够合理的把成本治理下来,谁就有了在公司的优先生存权,防止自己成为被降本的对象(好尴尬!!!),今天介绍一下H公司在大数据存储这块的成本方案(做早了。。。)。
一样的套路,先看存储成本的公式:
存储成本=物理存储单价/磁盘利用率*数据冗余度*量*数据压缩比
为了优化最终值,我们可以:
- 降低物理存储的单价:购买更高密度的磁盘,或是分层存储
- l磁盘利用率:可以和云连接,提高存储安全水位线,参考作者视频号中关于“大数据融合云”的内容介绍;用tune2fs 命令看看系统有没预留空间,将其干掉,专门给hdfs的磁盘不需要此预留
- 数据冗余度:如引入hdfs ec,这块可以参考作者另外一篇文章《如何在hadoop2的环境中使用纠删码(hadoop Erasure Coding)-CSDN博客》
- 数据压缩比:如采用压缩算法或列存格式,降低文件大小
- 量:即意味着治理,这是本篇文章要介绍的内容
要降低业务使用存储的量,从方向上来说,主要有两个:
- 识别每张表的信息冗余度:也就是识别哪些ETL链路产生了逻辑冗余,导致数据所代表的“信息”在多个地方冗余存储了。虽然我们在ETL链路中,经常引入中间表或模型表来提高数据的易用性和可维护性,但冗余度如果太高,肯定是有问题,该方向,我们目前还在探索
- 识别表的生命期是否合理:这是本篇文章要介绍的内容。我们需要量化出一个指标,来指向我们治理的方向,同时也用来评估(制约)用户对存储的使用
治理数据生命期
数据表上,我们都会设置其保存周期,但是该周期时长由数据开发所设定,我们只能从单个表上去分析其设置的是否合理,但是当表很多之后(H公司的hive里面有上万的表),不可能挨个去询问。同时从管理角度看,虽然数据业务团队承担了存储成本,但平台团队依然有职责从整个平台的角度去回到老板的灵魂拷问:“你的用户用的合理吗?”
为了解决上面问题的尴尬,H公司从2021年做存储量上的治理,我们引入针对存储生命期合理性的量化指标,该指标可以评估用户设置的生命期是否合理。下面介绍该算法的思路:
存储数据的本质目的:
为什么数据需要存储下来,我们理解有两个目的:
- 信息的存储:如源头表,如果该表的数据被删除之后,那么就再也无法提取出该数据所隐含的信息
- 存储换易用性/存储换时间:该类表的目的是为了提升数据的使用体验,如果数据被删除之后,其对应的信息是可以被恢复的。
针对“存信息”这类表,平台团队不挑战其设置生命期的合理性,但是需要走审批流程,其流程中必须填写其理由,同时需要业务某一级的大领导来背书,这样平台团队就可以说“某某某同意的”,就可以把灵魂拷问的锅“甩出去”。。。
针对第二类“提高体验”的表,治理生命期的目的是为了“尽量让数据生命期贴合数据的实际需要”,换成大白话来举例,就是“这张表99%的场景都使用的是最近7天的数据,如果他的生命期如果设置成14天,那浪费接近50%,如果设置成7天,将会有x%的概率影响到用数体验”,我们的目的就是要把这句大白话用数学的方式描述下来
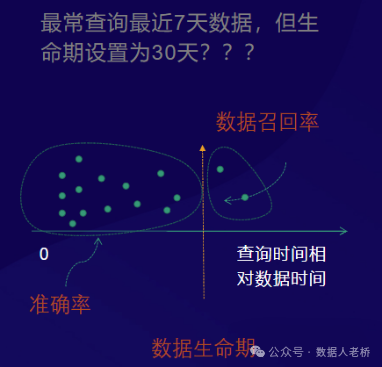
- 准确率:查询某天的数据时,数据还在,说明生命期设置合理
- 数据召回率:数据查询时,该天的数据已经被删除了,该天的数据需要通过重跑任务来补数,召回该天的数据。召回率越高,说明生命期设置的太短,用户体验影响越大。
数据准备
因为我们的目标是根据用户实际使用情况,分析表的生命期是否合理,因此需要记录每次查询时,“用户查询数据的相对天数”,该值指的是“查询任务执行的日期和被查询数据所属的日期的差值”,如2024-07-10查询了2024-07-05的数据,则该值为date_diff(2024-07-05,2024-07-11),表示“查询了最近6天的数据”,则该表至少要存储6天的数据。而所谓“每次”,最好是跟“用户的任务”相关,如“一个离线作业”,“一次adhoc查询”,如果一次用户任务中对表使用了两次,但只会计数一次,从而评估对“用户”的影响次数。该数据需要综合使用很多方式,每种方式总有其适应的场景和不足
提取查询数据的数据日期
-
分析SQL得到:从where中得到日期,这种情况,如果遇到对日期分区的过滤条件是表达式,会很麻烦,不仅要解析SQL,还得执行SQL函数
-
从hive metastore service中得到:在得到partition元信息的地方,拿到partition的location,从URL中解出分区对应的数据日期,这个方式,问题在于如果使用spark直接读取hdfs文件,则会漏掉
-
从hdfs的审计日志中得到,每次打开文件时,审计日志中留下记录。
-
从hdfs的fsimage中拿:每天解析fsimage中每个文件的last access日期,如果有变化,则说明当天有使用,但这种方式一天只能拿到“一次”,会漏掉“同一天多次使用”的场景
-
如果是mapreduce框架,如hiveSQL,从job.xml的inputpath中提取,如果是spark sql,则需要hack代码将其写到eventlog中
提取查询频次信息
上面的这些方式提取日期时,同时还需要在“频次”上做去重,也就是前面我们说的“用户同一个任务对同一天数据访问多次,只算一次”,因此需要根据某些值作为批次号去做去重,越在上层采集数据,批次号越容易注入,越底层,则越难。
1、在hive metastore service或hive,可以通过set conf的方式将离线作业或adhoc任务的ID传进去,后期通过这个ID来去重
2、如果是在hdfs层,暂时没想到合适的办法,卡点问题是hdfs的rpc接口无法传递额外参数
根据上面的操作,我们得到了每“次”使用数据时的“相对日期”,数据尽量完整。
数据建模
在本章节,我们需要用采集到的数据得到两个结论:
-
每张表合适的生命期
-
根据推荐的合适生命期和用户实际设置的生命期,量化其合理性,同时在部门或是其他管理维度上收敛成一个值,用该值进行评估、运营生命期的治理成果。
推荐表生命期
我们将上面得到的数据,例如某张表的数据如下:
将该数据作图为:
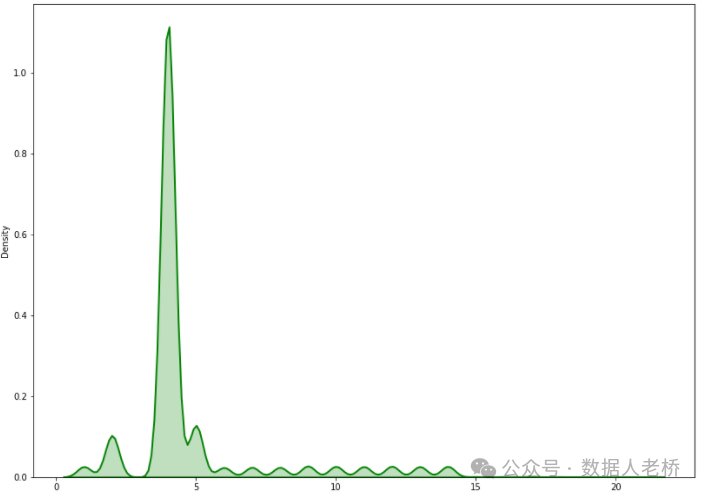
由于上图的分布不是正态分布,所以将数据转换一下变成近似正态分布。
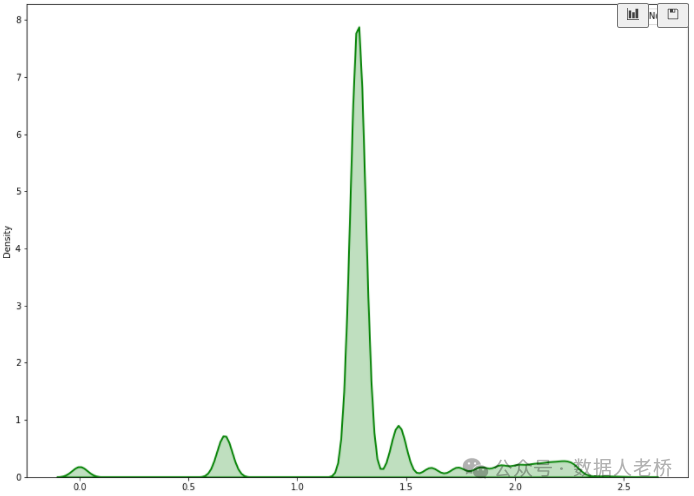
由于正态分布的特点,99.7%的数据落到【均值3倍的标准差】的范围之内
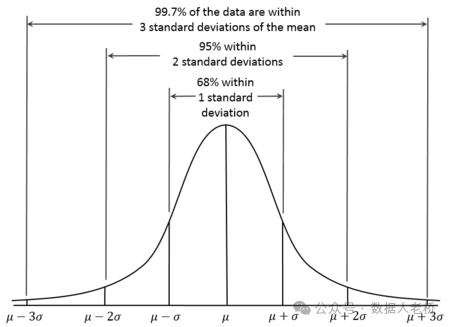
所以根据用户的半年内的历史访问数据,进行近似正态分布的数据转换后,以均值+ 3 倍的标准差为标准推荐表的保存天数大小,示例中的表推荐保存 18 天即可,按照真实的访问数据,若此表保存 18 天,会 106/123496 = 0.08% 的访问超出保存的天数,也就是我们前面所说的“数据召回率”
表生命期合理性评判
每张表的存储合理性得分计算公式为:

如表table_x,目前存储 66 天的数据,大小 170T,推荐保留 18 天的数据,得分为: 1-(66-18)/66 = 0.27,此表生命周期改为 18 的话,能够节省 123T 的存储空间,这样做了之后,评估分以及预期的治理成果也就都有了
部门得分
将表的实际大小作为权重,计算部门得分
sum((table_size/allszie) * table_score)
后续拿着这个分做部门治理的排名,推动各个业务部门自发治理即可
结束推荐
本篇文章只介绍了生命期合理性的评估,如果读者对ETL链路冗余导致的存储和算力的识别是实践,欢迎给老桥留言进行工作指导!!!
















 1766
1766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









