








前置工作
要正常使用ML.NET,需要通过NuGet包管理其,引入如下NuGet包(图1,图2):

图1
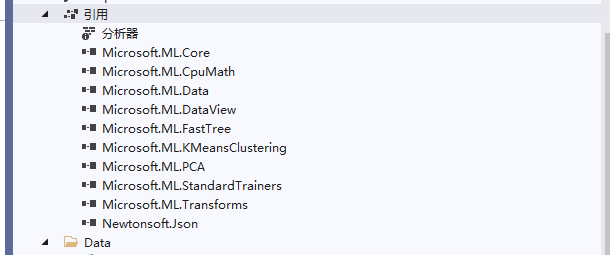
图2
除此之外,还需要准备数据源,本实例为通过身高,体重判断一个人的身材,数据需要三个字段,即身高,体重,是否身材好,本次文件格式为csv(图3,图4):
![]()
图3

图4
具体代码
前置工作准备好后,我们开始具体编码的开发,首先创建输入数据实体类FigureData和,输入数据实体类FigureDatePredicted,其中[LoadColumn(0)] 特性指示该属性对应该条数据中的第几个数据, FigureDatePredicted类需要继承FigureData 便于调试(图5,图6):

图5

图6
然后读取数据,并进行训练(图7)
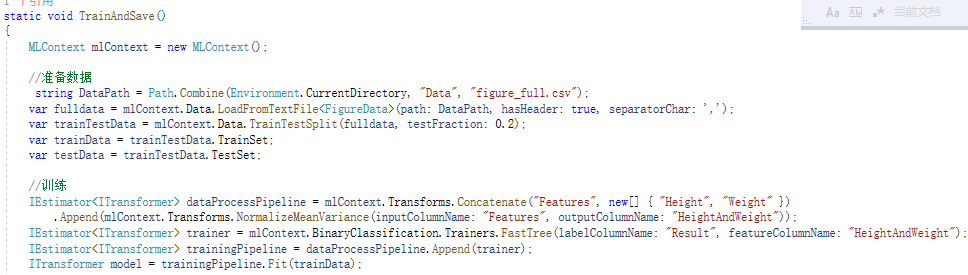
图7
其中, separatorChar用来分割数据的字符,区分出数据中的不同字段TrainTestSplit(fulldata,testFraction:0.2)用来随机分割数据,分成学习数据和评估用的数据,本次取出20%用作测试。不通过分割,准备两个数据文件,一个用来训练、一个用来评估,也是可行的。
IDataView这个数据集就类似一个表格,它的列(Column)是可以动态增加的,一开始我们通过LoadFromTextFile获得的数据集包括:Height、Weight、Result这几个列,在进行训练之前,还要对这个数据集进行处理,形成符合要求的数据集。
Concatenate这个方法是把多个列,组合成一个列,因为二元分类的机器学习算法只接收一个特征列,所以要把多个特征列(Height、Weight)组合成一个特征列Features(组合的结果应该是个float数组)。
NormalizeMeanVariance是对列进行归一化处理,这里输入列为:Features,输出列为:FeaturesNormalizedByMeanVar。
数据集就绪以后,就要选择学习算法,针对二元分类,本次选择了快速决策树算法FastTree,执行时需要告诉这个算法特征值放在哪个列里面(FeaturesNormalizedByMeanVar),标签值放在哪个列里面(Result)。
链接数据处理管道和算法形成学习管道,将数据集中的数据逐一通过学习管道进行学习,形成机器学习模型。
有了这个模型就可以通过它进行实际应用了。但一般不会现在就使用这个模型,需要先评估一下这个模型,然后把模型保存下来。以后应用时再通过文件读取出模型,然后进行应用,这样就不用等待学习的时间了,通常学习的时间都比较长。
执行完成后,还需要对结果进行评估并保存(图8)

图8
评估的过程就是对测试数据集进行批量转换(Transform),转换过的数据集会多出一个“PredictedLabel”的列,这个就是模型评估的结果,逐条将这个结果和实际结果(Result)进行比较,就最终形成了效果评估数据。
执行中可以打印这个评估结果,查看其成功率,一般成功率大于97%就是比较好的模型了。由于本次的数据比较整齐,所以我们这次评估的成功率为100%。
注意:评估过程不会提升现有的模型能力,只是对现有模型的一种检测。
创建预测引擎的功能和Transform是类似的,不过Transform是处理批量记录,这里只处理一条数据,而且这里的输入输出是实体对象, test是我们要预测的对象,预测后打印出预测结果图(9):

图9
注:本文参考版本较为老旧,最新版本建议使用SdcaLogisticRegression
















 2987
2987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









