









Problem 1 :洗澡
问题描述
你是能看到第一题的 friends 呢。——hja
洗澡的地方, 有一段括号序列,将一个括号修改一次需要1的代价(将左括号变成右括号或者相反),求最小代价使得括号序列合法。
输入格式
一行一个括号序列。
输出格式
一行一个整数代表答案。
样例输入
())(
样例输出
2
数据范围与规定
对于50%的数据, 括号序列长度不超过100。
对于100%的数据, 括号序列长度不超过105且一定为偶数,只包含小括
号。
思路
题解:
暴力从左向右扫一遍,记录当前左括号比右括号多少个。
如果某个时刻左括号比右括号少了,那么把当前右括号改成左括号一定最好。
最后把多的左括号搞掉就行。
说的真粗暴….我好像写麻烦了..我的思路如下,其实相当于对题解算法的证明:
首先我们要把括号串转化为01串!233333方便而已
首先我们要开两个栈,存储未匹配的左括号(0)和右括号(1),然后合并为同一数列。
我们从前向后处理。
对于当前的括号,若为左括号,说明其后面没有与之匹配的右括号,那么我们一定要将其后一个括号(一定也为左括号)翻转为右括号与之匹配。因为对于当前括号及其后括号,个数一定为偶数(我们依次匹配过来了),翻转后一个括号与之匹配,与翻转其后其他括号与之匹配的消耗相同,方便起见翻转后一括号。
若为右括号,说明其前面没有与之匹配的左括号,我们必然要将其翻转,那么若其后面的一个括号为右括号,那么恰好匹配,若为左括号,我们就一定要翻转他使之与前一个匹配。因为对于当前括号及其后括号,个数一定为偶数,直接使用后一个右括号匹配,或者翻转后一个左括号,与翻转后一个右括号,与后面其他括号匹配,不翻转左括号与后面其他括号匹配消耗相同,方便起见如上处理。
代码
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
using namespace std;
int len,tot1,tot2,tot,ans;
int num[1000010];//01串
int tmp[1000010];//未匹配的括号
int stk1[1000010],stk2[1000010];//左,右括号栈
char ch[1000010];//原串
bool p[1000010];//是否已匹配
void merge_s()
{
int i=1,j=1;
while(i<=tot1&&j<=tot2)//归并
{
if(stk1[i]<stk2[j])
{
tmp[++tot]=0;
i++;
}
else
{
tmp[++tot]=1;
j++;
}
}
while(i<=tot1)
{
tmp[++tot]=0;
i++;
}
while(j<=tot2)
{
tmp[++tot]=1;
j++;
}
}
int main()
{
scanf("%s",&ch);
len=strlen(ch);
for(int i=0;i<len;i++)//转换为01串
{
if(ch[i]=='(')
num[i+1]=0;
if(ch[i]==')')
num[i+1]=1;
}
for(int i=1;i<=len;i++)
{
if(num[i]==0)
stk1[++tot1]=i;
if(num[i]==1)
{
if(!tot1)
stk2[++tot2]=i;
else tot1--;//匹配
}
}
merge_s();
for(int i=1;i<=tot;i++)
{
if(p[i])
continue;
if(tmp[i]==0)//后面不可能存在右括号只会有左括号
{
ans++;
tmp[i+1]=1;//翻转左括号,清晰
p[i+1]=1;
}
if(tmp[i]==1)//可能存在左括号或右括号
{
ans++;//无法与前面匹配,一定翻转
tmp[i]=0;
if(tmp[i+1]==0)//若后面为左括号
{
ans++;
tmp[i+1]=1;//左括号后面不可能存在右括号,所以必然翻转一个,对答案贡献相同
p[i+1]=1;
}
if(tmp[i+1]==1)//若后面为右括号
p[i+1]=1;//完成匹配
}
}
printf("%d",ans);
return 0;
}Problem 2 :日记
问题描述
你是能看到第二题的 friends 呢。——laekov
日记之中,写满了质数,两个质数之间如果没有其他质数,那么则称为相邻的质数。给定n, k,询问不超过n的数中能够表示成连续k个质数之和的最大
的数是多少。
输入格式
第一行一个整数t代表数据组数。
对于每组数据,一行行两个整数n, k。
输出格式
对于每组数据,一行一个整数代表答案。如果不存在,则输出−1。
样例输入
3
20 2
20 3
20 4
样例输出
18
15
17
数据范围与规定
对于20%的数据, 1 ≤ n ≤ 100。
对于40%的数据, t = 1。
对于另外20%的数据,所有的询问的n相等。
对于100%的数据, 1 ≤ t< 2000,1 ≤ n ≤ 10^6。
思路
预处理出1-10^6范围内的质数(50000个左右),每次二分选择起始位置,即选择区间的左端点,暴力统计区间和验证——或者前缀和或者线段树统计。
另外因为选择的最小元素不会超过n/k,由此缩小了一点二分范围(并没有太大作用)。
代码
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#define RI register int
using namespace std;
int t,n,k,tot,limit,pos,l,r,ans,sum;
int isprime[1000010];
bool flag;
bool vis[1000010];
void init()
{
for(RI i=2;i*i<=1000010;i++)
{
if(!vis[i])
{
for(RI j=i*i;j<=1000010;j+=i)
vis[j]=1;
}
}
for(RI i=2;i<=1000010;i++)
{
if(!vis[i])
isprime[++tot]=i;
}
for(int i=1;i<=50;i++)
cout<<isprime[i]<<endl;
}
int check(int p)
{
sum=0;
for(RI i=p;i<=p+k-1;i++)
sum+=isprime[i];
if(sum<=n)
return 1;
else return 0;
}
int main()
{
init();
scanf("%d",&t);
for(RI s=1;s<=t;s++)
{
scanf("%d%d",&n,&k);
flag=0;
limit=((n/k)+1);//起始元素上限
pos=lower_bound(isprime+1,isprime+tot+1,limit)-isprime;
l=1;
r=pos;
ans=-1;
while(l<=r)//二分起始位置
{
int mid=(l+r)>>1;
if(check(mid))//若没有超过n
{
ans=sum;
l=mid+1;
}
else r=mid-1;
}
printf("%d\n",ans);
}
return 0;
}Problem 3 :
问题描述
你是能看到第三题的 friends 呢。——aoao
洗完衣服,就要晒在树上。但是这个世界并没有树,我们需要重新开始造树。
我们一开始拥有T0,是一棵只有一个点的树,我们要用它造出更多的树。
生成第Ti棵树我们需要五个参数ai, bi, ci, di, li(ai, bi < i)。我们生成第i棵树是
将第ai棵树的ci号点和第bi棵树的di号点用一条长度为li的边连接起来形成的新
的树(不会改变原来两棵树)。下面我们需要对新树中的点重编号: 对于原来在
第ai棵树中的点, 我们不会改变他们的编号; 对于原来在第bi棵树中的点, 我们
会将他们的编号加上第ai棵树的点的个数作为新的编号。
定义
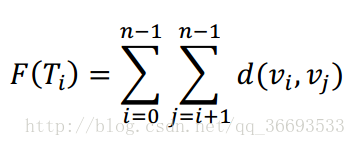
其中, n为树Ti的大小, vi, vj是Ti中的点, d(vi, vj)代表这两个点的距离。现
在希望你求出∀1 ≤ i ≤ m, F(Ti)是多少。
输入格式
第一行一个整数m,代表要造多少棵树。
接下来m行,每行5个数ai, bi, ci, di, li。
输出格式
m行每行一个整数代表F(Ti)对10^9 + 7取模之后的值。
样例输入
3
0 0 0 0 2
1 1 0 0 4
2 2 1 0 3
样例输出
2
28
216
数据规模与约定
对于30%的数据, 1 ≤ m ≤ 10。
对于60%的数据,每棵树的点数个数不超过105。
对于100%的数据, 1 ≤ m ≤ 60。
思路
考场没看明白样例….
正解是推式子然后记忆化搜索….可惜并不太理解。















 422
422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









