







【AIGC月报】AIGC大模型启元:2025.04
(1)UI-TARS Desktop(字节跳动Agent工具)
2025.03.26 你是否想象过,只需一句“帮我查旧金山的天气”,电脑就能自动打开浏览器搜索并展示结果?或是输入“发一条推特说‘你好世界’”,AI便替你完成所有点击和输入操作?字节跳动最新开源的 UI-TARS Desktop 让这一切成为现实!这款基于视觉语言模型的AI智能体,正在重新定义人机交互的边界。
基本特性:
-
自然语言操控
无需学习复杂指令,直接通过中文或英文描述任务目标。例如:“整理桌面文件并按日期归档”“在PPT第三页插入柱状图”,AI会自动解析指令并精准执行。
实测案例:用户输入“分析特斯拉未来股价”,系统自动调用浏览器、筛选数据并生成可视化图表
-
跨平台视觉交互
通过截图实时感知屏幕内容,结合视觉识别技术定位界面元素(如按钮、输入框),支持Windows和MacOS系统。即使面对动态变化的网页或软件界面,也能准确点击、拖拽、输入文字。
-
多工具协同工作流
集成浏览器、命令行、文件系统等工具,可串联复杂任务。例如规划旅行时,AI会依次完成机票比价、酒店筛选、行程导出Markdown等步骤,全程无需人工干预。
-
实时反馈与纠错
执行过程中展示操作轨迹和状态跟踪,若遇到异常(如页面加载失败),AI会自主调整策略或请求用户协助。
技术突破:
-
多模态感知架构
UI-TARS采用“数字视网膜”系统,通过改进型YOLO模型实现亚像素级元素识别,结合多模态Transformer模型打通视觉信号与语言指令的语义关联,摆脱传统自动化工具对API接口的依赖。
-
系统化推理能力
引入“System 2”深度推理机制,支持任务分解、反思修正和长期记忆。例如处理“修改PPT配色”任务时,AI会先分析当前幻灯片风格,再调整色系并确保全局一致性。
-
动态环境适应性
通过在线轨迹学习(Online Traces Bootstrapping)和反思微调(Reflective Fine-tuning),AI能从错误中快速迭代,应对未预见的界面变化,在OSWorld基准测试中任务成功率超24.6%,远超Claude等通用模型。
参考博客:字节跳动开源UI-TARS Desktop:用自然语言操控电脑的AI智能体来了!
开源地址:https://github.com/bytedance/UI-TARS-desktop/releases
(2)Qwen2.5-Omni(阿里巴巴全模态模型)
2025.03.27 阿里巴巴发布并开源的端到端全模态大模型,能处理文本、图像、音频和视频等多种输入,并生成文本与自然语音输出。Qwen2.5-Omni 的目标是构建一个能够同时处理文本、图像、音频和视频等多种模态输入,并以流式方式生成文本和自然语音响应的端到端多模态大模型。该模型不仅要在多模态任务中表现出色,还要在单模态任务中保持竞争力,同时具备实时交互的能力,为各种应用场景提供强大的技术支持。
1.全能创新架构
Qwen2.5-Omni 的 Thinker-Talker 架构使其能够同时处理文本、图像、音频和视频等多种模态输入,并生成相应的文本和语音响应。这种架构不仅支持跨模态理解,还能够以流式方式输出结果,使得模型在处理复杂的多模态任务时更加高效和自然。
2.实时音视频交互
Qwen2.5-Omni 支持实时音视频交互,能够处理分块输入并即时输出。这意味着模型可以在接收到输入数据的同时,立即生成响应,无需等待所有数据输入完成。这种实时性对于需要快速响应的应用场景(如视频会议、实时翻译等)具有重要意义。
3.自然流畅的语音生成
Qwen2.5-Omni 在语音生成的自然性和稳定性方面表现出色。它能够生成流畅、自然的语音,超越了许多现有的流式和非流式语音生成模型。这种高质量的语音生成能力使得模型在语音交互应用中更具优势。
4.全模态性能优势
Qwen2.5-Omni 在多模态任务 OmniBench 中达到了 SOTA(State-of-the-Art)表现。此外,在单模态任务中,如语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU、MMStar)、视频理解(MVBench)以及语音生成(Seed-tts-eval 和主观自然听感)等多个领域,Qwen2.5-Omni 也表现出色。这表明该模型不仅在多模态任务中表现出色,还在单模态任务中保持了竞争力。
5.卓越的端到端语音指令跟随能力
Qwen2.5-Omni 在端到端语音指令跟随方面表现出色。它能够准确理解和执行语音指令,与文本输入处理的效果相当。这种能力在 MMLU 通用知识理解和 GSM8K 数学推理等基准测试中得到了验证。
参考博客:https://mp.weixin.qq.com/s/7QcOmcevp-5zZQx_uAhIMg
GitHub:https://github.com/QwenLM/Qwen2.5-Omni
Hugging Face:https://huggingface.co/Qwen/Qwen2.5-Omni-7B
ModelScope:https://modelscope.cn/models/Qwen/Qwen2.5-Omni-7B
官网地址:https://qwenlm.github.io/blog/qwen2.5-omni
论文地址:https://github.com/QwenLM/Qwen2.5-Omni/blob/main/assets/Qwen2.5_Omni.pdf
体验地址:https://huggingface.co/spaces/Qwen/Qwen2.5-Omni-7B-Demo
(3)Project OASIS(模拟社会智能体系统)
2025.04.04 OASIS是一个开源的社会模拟环境,包含数百万基于大语言模型的智能体,旨在高度还原 Twitter、Reddit 等平台上数百万用户的真实行为。这或许是推动下一次智能体突破的关键一步。
以下是 OASIS 的四大关键特性:
- 📈 高度可扩展性: OASIS 支持最多一百万个智能体的模拟运行,使研究者可以在接近真实平台规模下研究社交网络动态。
- 📲 动态模拟环境: 支持社交关系与内容的实时变动,真实再现如 Twitter、Reddit 等平台的动态演化过程。
- 👍🏼 多样化操作空间: 智能体可执行 21 种操作,包括关注、评论、转发等,为交互行为提供了丰富维度。
- 🔥 集成推荐系统: 内置兴趣导向和热度评分推荐算法,能够模拟社交平台中用户发现内容、互动传播的真实机制。

OASIS 的系统由五大核心模块协同运行,每一部分都对应着现实社交平台的关键机制:
🗃️ 环境服务器(Environment Server)
这是整个模拟系统的大脑与中枢。它像一个庞大的数据库,持续记录模拟世界中的一切:包括帖子内容、用户资料、关注关系、点赞评论等互动数据。可以将它理解为模拟版的“Twitter 后台”,维持着整个平台的实时状态。
🔍 推荐系统(Recommendation System)
决定每个智能体能看到哪些内容,就像现实中的社交平台那样:
- 在类 Twitter 平台中,它展示关注用户的动态和个性化推荐内容;
- 在类 Reddit 平台中,它采用类似“热度算法”,根据点赞、点踩和发布时间综合排序;
- 同时,它还使用基于社交媒体数据训练的 AI 模型来判断内容相似度,让推荐更加贴近用户兴趣。
🤖 智能体模块(Agent Module)
这是 AI 用户真正“居住”的地方。每个智能体都具备以下特征:
- 能存储过往互动和兴趣偏好;
- 利用大语言模型(LLM)决定下一步行为;
- 拥有 23 种可执行操作,包括发帖、评论、关注他人等;
- 并且能够“思考”自己行为背后的动机。
⚡ 高性能推理模块(Scalable Inferencer)
OASIS 需要处理海量智能体的决策与行为,这一模块的作用是:
- 高效管理多张 GPU;
- 并行处理大量智能体的动作;
- 动态分配算力资源,保证运行流畅。
⏳ 时间引擎(Time Engine)
现实中人不会全天在线,OASIS 也考虑了时间因素:
- 每个智能体有自己的“作息时间表”,决定他们在一天中的活跃时段;
- 所有事件按照合理顺序发生,并带有真实的时间戳,确保模拟世界的节奏自然可信。
参考博客:Project OASIS:多智能体系统最大的潜力,或许藏在“模拟社会”中
GitHub开源仓库:https://github.com/camel-ai/oasis
论文地址:https://arxiv.org/abs/2411.11581
项目详情:https://oasis.camel-ai.org/
产品Matrix:https://matrix.eigent.ai/x
(4)Gemma 3(谷歌多模态模型)
2025.03.12 巴黎开发者大会上,谷歌正式推出第三代开源模型Gemma 3,首次实现 多模态原生支持+128K超长上下文 ,参数涵盖1B、4B、12B和27B四大版本, 单块GPU/TPU即可流畅运行 !最惊人的是,27B版本竟在LMArena竞技场以 1338 ELO分 碾压DeepSeek V3、o3-mini等巨头,跃居全球开源模型第二,仅次于DeepSeek R1。

性能炸裂:小身材大能量
-
数据量碾压 :27B模型基于14T tokens训练,1B版本也达2T tokens,支持 140+语言 ,视觉输入与结构化输出双突破。
-
数学暴涨45分 :27B模型在数学基准测试中较前代提升33-45分,逼近闭源版Gemini 1.5 Flash。
-
手机也能跑 :专为端侧优化,手机、笔记本、工作站全适配,开发者可轻松部署AI应用。
四大杀手锏,重新定义开源模型
-
单设备跑赢群雄 :27B模型仅需1个GPU,性能超越需32卡运行的Llama-405B,LMArena评分冲进全球前十。
-
视觉推理黑科技 :集成SigLIP编码器,可解析图像、视频,甚至读懂日文遥控器指令。
-
128K上下文海量处理 :自适应窗口算法破解高分辨率图像难题,非标准比例输入轻松应对。
-
函数调用+量化加速 :支持自动化工作流,官方量化版兼顾精度与效率,推理速度飙升。
技术内幕:如何炼成「小钢炮」?
- 蒸馏+强化学习三连击 :从大模型蒸馏知识,结合RLHF(人类反馈)、RLMF(机器反馈)、RLEF(代码执行反馈),数学与编码能力直接拉满。
- 分词器全面升级 :专为多语言设计,JAX框架+TPUv5集群训练,27B版本豪吞14T tokens。
- 视觉模块冻结策略 :保持4B/12B/27B视觉编码器一致性,训练效率最大化。
参考博客:重磅!谷歌Gemma 3震撼发布!手机单GPU跑多模态!ELO 1338分!对标DeepSeek!
(5)Llama 4(Meta多模态模型)
2025.03.12 MetaAI发布Llama4模型,本次共两系列模型Scout和Maverick模型,两个模型均为MoE架构模型。
Llama 4:领先的多模态智能,最新的模型套件,提供无与伦比的速度和效率,Llama4 Maverick 直接整到了lmarena.ai评测的Top2,开源圈新的王(领先后面的:ChatGPT-4o-latest、Grok-3-preview、Gemini-2.0-Flash-Thinking,DeepSeek V3/R1)
Llama 4 Behemoth(未开源):288B 活跃参数,16个专家,总参数量2T,最智能的蒸馏教师模型
Llama 4 Maverick:17B活跃参数,128个专家,总参数量400B,原生多模态支持1M上下文长度
Llama 4 Scout:7B活跃参数,16个专家,总参数量109B,行业领先的10M上下文长度,优化推理
Llama 4训练特点:
-
原生多模态:能够无缝集成文本和视觉token到统一的模型骨干中,实现文本和图像数据的早期融合。
-
智能调参 MetaP:用于智能调整训练超参数的新技术,这可能类似于 Meta 开源的 Ax 框架中的贝叶斯优化,能在有限的试验预算内进行自适应实验(如 A/B 测试)
-
后训练策略:重 RL 轻 SFT/DPO,提升在线 RL 的权重。过多的 SFT/DPO 会过度约束模型,限制其在 RL 阶段的探索能力
-
MoE架构:首次在 Llama 4 模型中使用混合专家架构,在训练和推理时更加计算高效,并且能够在固定的训练 FLOPs 预算下提供更高质量的结果。
参考博客:
官网地址: https://www.llama.com/llama-downloads/
Hugging Face: https://huggingface.co/meta-llama
参考论文:
- interleaved attention layers: https://arxiv.org/abs/2305.19466
- inference time temperature scaling: https://arxiv.org/pdf/2501.19399
- rotary position embeddings: https://arxiv.org/abs/2104.09864
(6)Sec-Gemini v1(谷歌网络安全大模型)
2025.04.06 谷歌推出实验性AI模型Sec-Gemini v1,旨在通过人工智能技术革新网络安全防御体系。该模型由Sec-Gemini团队成员Elie Burzstein和Marianna Tishchenko共同研发,旨在帮助网络安全人员应对日益复杂的网络威胁。
Sec-Gemini团队在博客中指出,网络安全领域长期存在固有的不对称性:防御方需要防范所有可能的攻击,而攻击者只需利用一个漏洞即可得手。这种失衡导致安全专业人员的工作既耗时又容易出错。Sec-Gemini v1试图通过AI工具"倍增"网络安全工作流程的效率,将优势重新拉回防御方。
技术架构与性能优势
该模型基于谷歌Gemini模型构建,整合了近实时的网络安全知识与最先进的推理能力。其数据来源包括:
-
Google威胁情报(GTI)
-
开源漏洞(OSV)数据库
-
Mandiant威胁情报
在关键性能指标测试中:
-
网络安全威胁情报基准(CTI-MCQ)表现优于竞品至少11%
-
根因映射基准(CTI-RCM)表现优于竞品至少10.5%,该基准评估模型解释漏洞描述、定位根本原因并按通用缺陷枚举(CWE)分类的能力
参考博客:谷歌发布网络安全AI新模型Sec-Gemini v1
(7)大模型应用防火墙(字节跳动)
2025.03.21 随着人工智能技术的广泛应用,AI安全面临新的挑战。为帮助企业应对这些挑战,火山引擎推出了全新的大模型应用防火墙,提供全方位的安全防护能力,从“被动防御”升级到“主动对抗”,有效降低由模型攻击、推理服务滥用和系统权限突破带来的风险,为企业构建一个安全可信的AI推理环境。
大模型应用防火墙具备卓越的安全防护效能。它能够有效抵御算力DDoS攻击,消除发生率约30%的恶意tokens消耗风险;通过防范提示词注入攻击,使敏感数据泄露事件发生率降低70%;降低模型滥用、幻觉、回复不准确的发生率90%以上**;严格满足输入输出合规要求,将不良信息输出率控制在5%以内。
火山引擎据丰富的攻防实践,构建了涵盖用户接入层、智能体层、服务/业务层、模型推理层、模型训练层的五层威胁模型。
案例一:提示词拼接注入攻击

针对提示词拼接注入攻击,火山引擎采用意图识别、防提示词注入、动态对抗和价值观校准等多重防护机制:
-
通过深度上下文引擎识别**97%**的隐式攻击。
-
基于千万级对抗样本训练,覆盖**20+提示词攻击场景,检出率达99%**以上。
-
实测违规内容及价值观偏移回答下降98%,轻量化架构可在100ms内完成风险拦截,误判率较行业低一半。
案例二:聊天数据窃取攻击

为了防止聊天数据被窃取,火山引擎采用了RAG数据加密/替换、模型计算环境安全性提升和访问识别等多种方法:
-
使用“深度学习小模型+大模型”的技术方案,对敏感数据进行脱敏处理,降低**96%**的泄露风险。
-
提供精调的提示词注入防护模型,支持多种攻击防护,并结合私密云计算方案确保核心数据即使被窃取也无法解密,使注入攻击拦截率达到99%。
案例三:系统权限攻击

面对SQL注入、RCE提权等专业化攻击,火山引擎的大模型应用防火墙不仅能识别固定规则的攻击代码,还能应对诱导生成的攻击代码:
-
在对话链路中实时拦截包含攻击行为的请求,源头切断威胁。
-
检测外部返回数据中的间接注入攻击,规避潜在威胁。
-
在应用发布时检测并拒绝包含恶意内容的应用。
案例四:可用性攻击

针对新型算力DDoS攻击和推理服务盗用问题,火山引擎构建了智能体算力防护体系:
-
识别**90%**的自动化“薅羊毛”行为。
-
动态资源熔断机制减少无效资源调用80%,帮助某头部厂商避免**40%**以上的算力损失。
火山引擎将继续致力于开发全面智能化防御策略与服务,帮助企业实现更加稳健的数字化转型,开辟一个安全可信的AI推理空间。
(8)Baichuan-M1(百川医疗语言模型)
2025.04.05 Baichuan-M1 是由百川智能(Baichuan Intelligence)研发的一款高性能大语言模型(Large Language Model, LLM),专注于中文及多语言场景下的自然语言处理(NLP)任务。以下是关于该模型的专业介绍:
1. 模型概述
研发背景:
Baichuan-M1 是百川智能推出的早期大模型之一,旨在填补中文领域高质量开源模型的空白,推动产业应用与学术研究。其设计兼顾通用性与垂直领域适配能力,支持复杂的语义理解、生成及推理任务。
技术定位:
基于Transformer架构,采用自回归预训练范式,通过千亿级token的高质量语料训练,优化了中文分词、多义词处理及文化语境适配等关键能力。
2. 核心特性
(1)语言能力
- 中文优先:在通用中文基准(如C-Eval、CLUE)中表现优异,针对古文、专业术语及网络用语进行了专项优化。
- 多语言扩展:支持英文、部分小语种的基本交互,具备跨语言迁移学习能力。
(2)技术架构
- 参数规模:公开资料显示为十亿级参数(具体未完全披露),平衡计算效率与性能。
- 训练数据:涵盖学术文献、百科、新闻、代码等多元语料,经严格去噪与偏差修正。
(3)应用适配
- 工具集成:支持外部API调用、数据库交互等插件化扩展,适配智能客服、内容生成等场景。
- 垂直领域微调:提供金融、医疗、法律等领域的适配方案,支持低资源场景下的参数高效微调(PEFT)。
3. 性能表现 - 基准测试:在中文理解(如文本分类、阅读理解)和生成任务(如摘要、对话)上,较同期同规模模型提升显著。例如:
- C-Eval:在人文、社科等子任务中达到Top 3性能(同参数量级)。
- 代码生成:基于HumanEval的Python任务通过率超60%。
- 推理效率:通过动态量化、模型剪枝等技术,在主流GPU(如A100)上实现毫秒级响应。
4. 开源与生态
- 开放程度:部分版本(如Baichuan-7B/13B)已开源,提供完整训练、推理代码及权重,遵循Apache 2.0协议。
- 工具链支持:配套发布高效推理框架(如vLLM适配)、微调工具包(集成LoRA等技术),降低部署门槛。
5. 应用场景
- 企业服务:知识库问答、自动化报告生成。
- 开发者工具:代码补全、文档摘要。
- 学术研究:作为基线模型用于NLP算法对比或迁移学习研究。
6. 局限性与挑战
- 长上下文处理:在超长文本(>4K tokens)连贯性上弱于部分千亿级模型。
- 实时性要求:极高并发场景需依赖额外分布式优化。
参考博客:https://mp.weixin.qq.com/s/_63moKNLJM4CHjWz6lT-Vw
Github代码:https://github.com/baichuan-inc/Baichuan-M1-14B
论文地址:https://arxiv.org/pdf/2502.12671
(9)GLM4-9B/32B、GLM-Z1(智谱华章)
2025.04.15 智谱开源 32B/9B 系列 GLM 模型,涵盖基座、推理、沉思模型,均遵循 MIT 许可协议。该系列模型现已通过全新平台Z.ai免费开放体验,并已同步上线智谱 MaaS 平台。
其中,推理模型 GLM-Z1-32B-0414 性能媲美 DeepSeek-R1 等顶尖模型,实测推理速度可达 200 Tokens/秒(MaaS 平台 bigmodel.cn),目前国内商业模型中速度最快。此外,其价格仅为 DeepSeek-R1 的 1/30。
智谱启用全新域名Z.ai,目前该平台整合了 32B 基座、推理、沉思三类 GLM 模型,后续将作为智谱最新模型的交互体验入口。
本次开源的所有模型均采用宽松的 MIT 许可协议。这意味着可以免费用于商业用途、自由分发,为开发者提供了极大的使用和开发自由度。我们开源了 9B 和 32B 两种尺寸的模型,包括基座模型、推理模型和沉思模型。
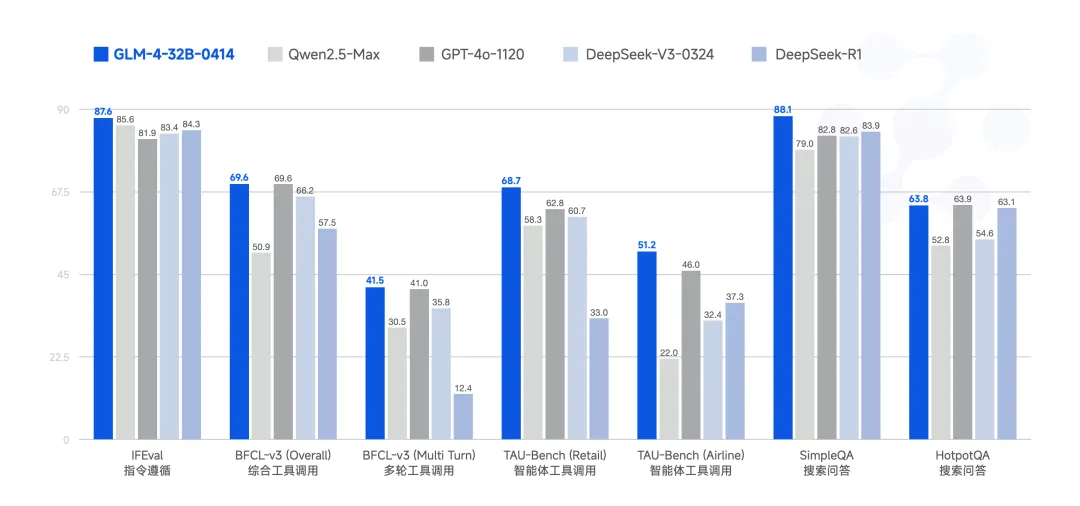
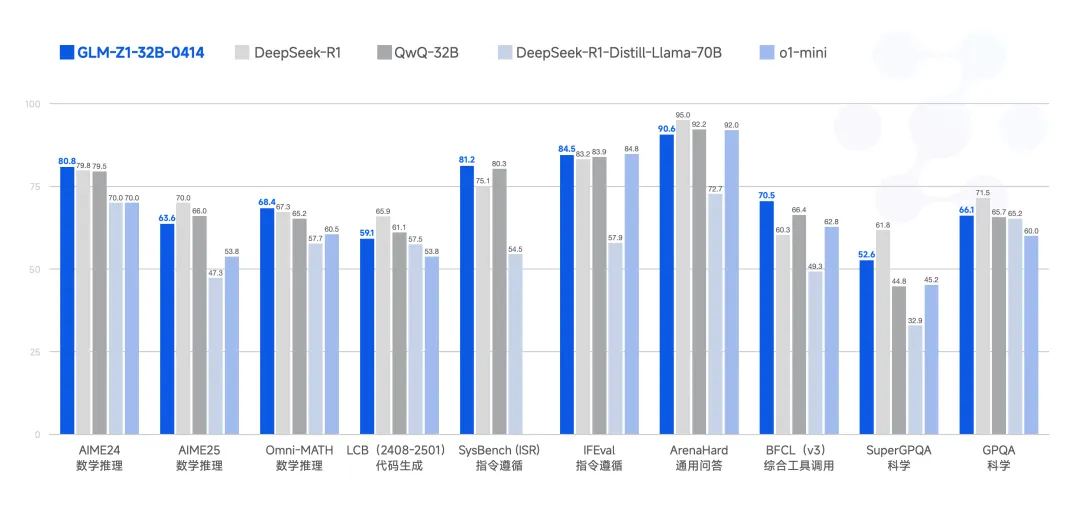
GLM-Z1-32B-0414 是一款具备深度思考能力的推理模型。该模型在 GLM-4-32B-0414 的基础上,采用了冷启动与扩展强化学习策略,并针对数学、代码、逻辑等关键任务进行了深度优化训练。与基础模型相比,GLM-Z1-32B-0414 的数理能力和复杂问题解决能力得到显著增强。此外,训练中整合了基于对战排序反馈的通用强化学习技术,有效提升了模型的通用能力。
在部分任务上,GLM-Z1-32B-0414 凭借 32B 参数,其性能已能与拥有 671B 参数的 DeepSeek-R1 相媲美。通过在 AIME 24/25、LiveCodeBench、GPQA 等基准测试中的评估,GLM-Z1-32B-0414 展现了较强的数理推理能力,能够支持解决更广泛复杂任务。
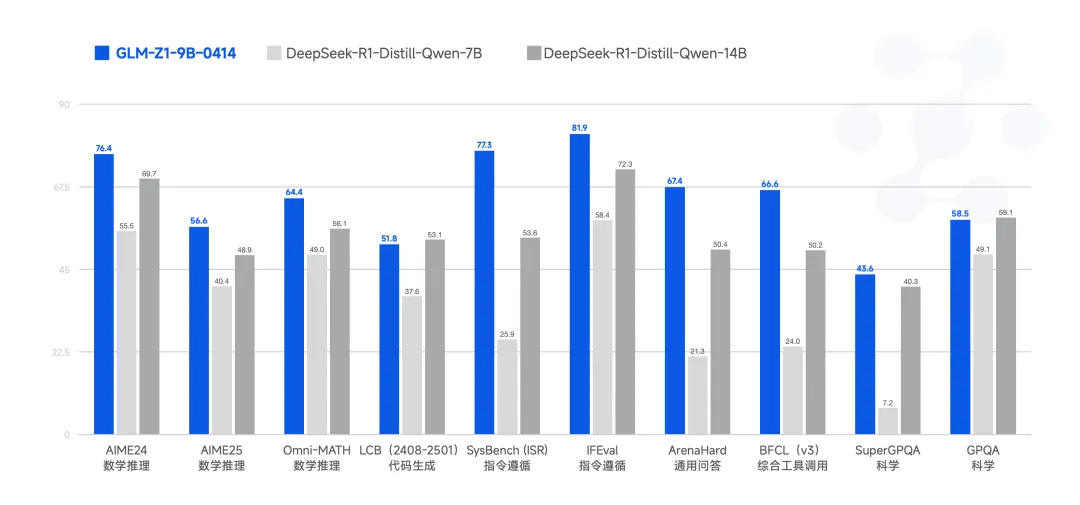
GLM-Z1-9B-0414 是一个惊喜。我们沿用了上述一系列技术,训练了一个 9B 的小尺寸模型。虽然参数量更少,GLM-Z1-9B-0414 在数学推理及通用任务上依然表现出色,整体性能已跻身同尺寸开源模型的领先水平。特别是在资源受限的场景下,该模型可以很好地在效率与效果之间取得平衡,为需要轻量化部署的用户提供强有力的选择。
上线的推理模型分为三个版本,分别满足不同场景需求:
- GLM-Z1-AirX(极速版):定位国内最快推理模型,推理速度可达 200 tokens/秒,比常规快 8 倍;
- GLM-Z1-Air(高性价比版):价格仅为 DeepSeek-R1 的 1/30,适合高频调用场景;
- GLM-Z1-Flash(免费版):支持 免费使用,旨在进一步降低模型使用门槛。
参考博客:https://mp.weixin.qq.com/s/7-vos2LIL3WIM1_qzyKTlw
体验地址:https://chat.z.ai/
开源地址:
(10)Veo 2(谷歌文生视频模型)
2025.04.16 谷歌DeepMind终于将大家期待已久的Veo 2整合到GeminiApp应用中,全面开放使用。
Veo 2可以最高生成8秒720P电影级视频,在运镜、文本语义还原、物理模拟、动作一致性等方面非常优秀,同时支持图片转视频功能。
根据谷歌公布的测试数据显示,Veo 2在用户偏好和提示还原方面已经超过了Sora、可灵1.5、Meta Movie Gen和Minimax。此外,从今天开始开发人员可以在Google AI Studio中通过API使用Veo 2。
参考博客:超越Sora!谷歌推出Veo 2,生成8秒超逼真视频
API地址:https://ai.google.dev/gemini-api/docs/video?hl=zh-cn
(11)Codex CLI(OpenAI轻量级代码Agent)
2025.04.17 OpenAI开源了一个终端轻量级代码Agent智能体——Codex CLI。
从凌晨到现在只用了5小时左右,Codex CLI直接破5000星霸榜Github,估计今天能破1万颗星,将成为一款明星级Agent。OpenAI联合创始人兼总裁Greg Brockman表示,Codex CLI只是第一款代码工具,未来还将继续开源Agent产品。
Codex CLI能根据用户输入的提示信息自动生成代码文件、运行代码、安装缺失的依赖并展示实时结果,例如,使用 codex “create the fanciest todo-list app” 命令就能创建一个待办事项应用程序。
Codex CLI也可以自动进行代码重构与测试,既能将类组件重写为 React Hooks组件,也能生成单元测试代码并执行测试直至通过。
在数据库迁移方面,Codex CLI能根据用户需求推断 ORM,创建数据库迁移文件并在沙盒数据库中运行这些迁移,例如,codex “Generate SQL migrations for adding a users table” 命令可生成添加用户表的 SQL 迁移文件。
文件操作也是其重要功能之一,Codex CLI支持对文件进行自动重命名、批量重命名等操作,并更新文件的导入和使用情况。
参考博客:OpenAI开源超火Agent,5小时破5000颗星,霸榜Github
开源地址:https://github.com/openai/codex?tab=readme-ov-file


















 454
454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









