







优秀的激活函数
- 非线性:激活函数非线性时,多层神经网络可逼近所有函数
- 可微性:优化器大多用梯度下降更新参数
- 单调性:当激活函数是单调的,能保证单层网络的损失函数是凸函数
- 近似恒等性:f(x)≈x,当参数初始化为随机最小值时,神经网络更稳定
激活函数的输出范围
- 输出为有限值:基于梯度的优化方法更稳定
- 输出为无限值:缩小学习率效果会更好
常见的激活函数:
- sigmoid函数
- tanh函数
- ReLU函数
sigmoid函数
函数形式:
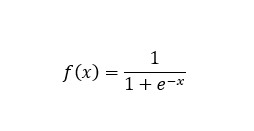

x = np.arange(-10,10,0.1)
y = 1/(1+np.power(np.e,-x))
plt.plot(x,y)
plt.grid()
plt.show
函数的导数:
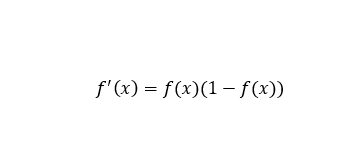

x = np.arange(-10,10,0.1)
y = 1/(1+np.power(np.e,-x))
z = y * (1-y)
plt.plot(x,z)
plt.grid()
plt.show
函数的特点:
- 易造成梯度消失
- 输出非0均值,收敛慢
- 幂运算复杂,训练时间长
tanh函数:
函数形式:
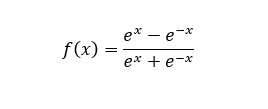

x = np.arange(-10,10,0.1)
y1 = np.power(np.e,x)
y2 = np.power(np.e,-x)
y = (y1-y2)/(y1+y2)
plt.plot(x,y)
plt.grid()
plt.show
函数的导数:
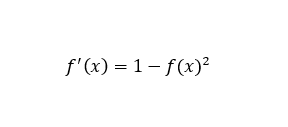

x = np.arange(-10,10,0.1)
y1 = np.power(np.e,x)
y2 = np.power(np.e,-x)
y = (y1-y2)/(y1+y2)
z = 1 - np.power(y,2)
plt.plot(x,z)
plt.grid()
plt.show
特点:
- 输出是0均值
- 易造成梯度消失
- 幂运算复杂,训练时间长
ReLU函数:
函数形式:


x = np.arange(-10,10,0.1)
y = np.where(np.greater(x,0),x,0)
plt.plot(x,y)
plt.grid()
plt.show
函数的导数:
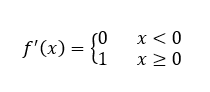

x = np.arange(-10,10,0.1)
y = np.where(np.greater(x,0),1,0)
plt.plot(x,y)
plt.grid()
plt.show
特点:
- 解决了梯度消失的问题
- 只需要判断输入是否大于0,计算简单
- 收敛速度比sigmod和tanh快
- 输出非0均值,收敛慢
- 某些神经元可能永远不会被激活,导致相应的参数永远不能被更新
更多
更多激活函数(来自维基百科,所以可能需要…懂的都懂)
初学建议
- 首先ReLu函数
- 学习率设置的小一些;也可以用动态缩小学习率,这样一开始要设置一个大的学习率
- 输出特征标准化,即让输入特征满足以0为均值,1为标准差的正态分布
- 初始参数中心化,即让随机生成的参数满足以0为均值,
 为标准差的正态分布
为标准差的正态分布















 9249
9249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









