







附录A 理想的损失值
在训练GAN时,我们希望达到的理想状态是,生成器与鉴别器之间达到平衡。这时,鉴别器无法区分真实数据与生成器生成的数据。因为生成器已经学会了生成看起来足以以假乱真的数据。
我们来计算一下,当达到平衡时,鉴别器的损失值应该是多少。下面我们分别对均方误差(mean squared error, MSE)损失和二元交叉熵(binary cross entropy, BCE)损失进行计算。
A.1 MSE损失
均方误差损失的定义很简单。它先计算输出节点产生的值和预期的目标值之间的差值,也就是误差。误差可以是正值,也可以是负值。
如果我们把误差平方,就可以保证结果为正。均方误差就是这些平方误差的平均值。
该损失的数学表达式如下。对于长度为n的输出层的每个节点,实际输出为o,预期目标为t。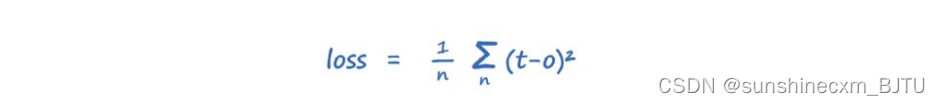
由于鉴别器只有一个输出节点,因此我们可以将以上表达式简化。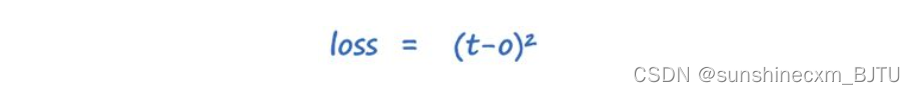
当鉴别器无法区分真实数据和生成数据时,它不会输出1,因为输出1表示它完全确信数据是真实的;
它也不会输出0,因为输出0表示它完全确信数据是生成的。
鉴别器会输出0.5,因为它对任何一种判断都没有信心。
如果输出为0.5,而目标值为1,则误差为0.5;当目标为0时,误差为−0.5。这两个误差经过平方后,结果都会得到0.25。
因此,一个平衡GAN的MSE损失为0.25。
A.2 BCE损失
二元交叉熵损失的计算基于概率和不确定性。下面逐个解释。
我们以MNIST分类器为例,它的神经网络有10个输出节点,每个输出节点对应一个类别。如果训练后的网络判断一个图像是数字4,那么第4个输出节点的值最高,其他节点的值会相对较低。
正如我们之前讲过的,这些值衡量了分类的置信度。另一种简单的思考方法,是把它们看作概率。这其实也很贴切,因为就像概率一样,输出节点的取值范围为0~1。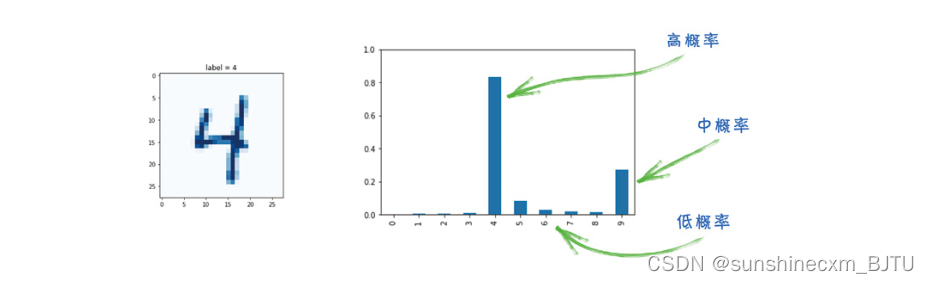
上图中,左边显示的是一幅代表4的图像,右边显示分类器的输出。从输出可以看出,网络给表示4的节点输出的概率最高,表示它认为这幅图像很可能是4。同时,它也给表示9的节点输出了中等的概率,表示它认为这幅图像也可能是9。另外,它给其他节点分配了很低的概率,表示它认为这幅图像看起来不像这些数字,如2或3等。
下表显示了输出值x和预期目标值y的两个例子。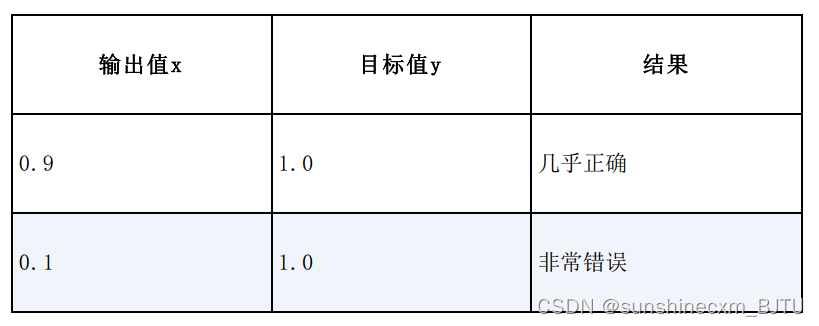
在上表的第1行,神经网络输出了一个概率为0.9的分类。由于目标值是1.0,所以几乎是正确的。对于这样的结果,一个好的损失函数会输出一个很小的结果。
在上表的第2行,分类结果的概率非常低,只有0.1。这说明网络并不认为这个分类是正确的。由于目标值是1.0,所以网络的结果错误。在这种情况下,一个好的损失函数应该输出一个很大的值。
现在,让我们从概率过渡到不确定性。
熵(Entropy)是描述不确定性的数学概念。假设有一枚不公平的硬币,两面都是正,那么得到正面的概率就是100%。同样地,得到反面的概率是0%。在任意一种情况下,我们对结果都是100%确定的。由于不确定性是0,因此我们说熵是0。
现在,假设我们有一枚公平的硬币,一面是正面,另一面是反面。这时,我们对结果的不确定性最大,即熵最大。
计算熵的数学表达式是
结果是所有可能结果的总和,而p是这些结果的概率。我们不会去探究这个表达式的来源,但我们可以通过绘图直观地看出为什么它的形状是正确的。
下图中,x轴是硬币为正面的概率,y轴是用上面的表达式计算得到的熵。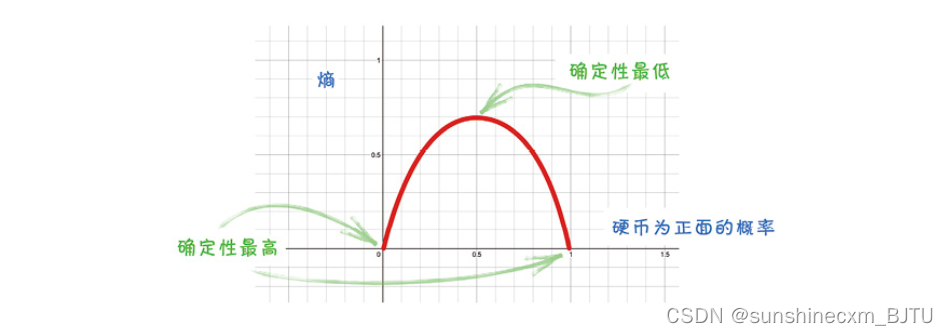
这幅图告诉我们,当一枚硬币两面都是正面,也就是p(正面)=1时,不确定性等于0。当两面都是反面,也就是p(正面)=0时,不确定性也等于0。如果硬币是公平的,即p(正面)=0.5时,熵最大。
我们了解了熵的工作原理。现在,让我们计算当硬币两面都是正面时的熵,也就是p(正面)=1。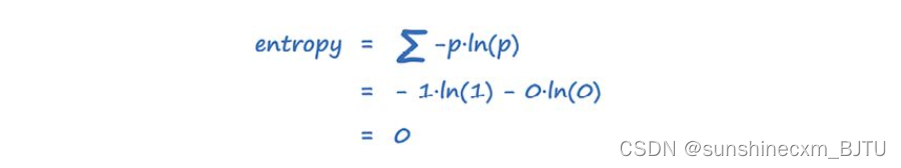
计算的结果包括两部分,分别对应硬币为正面和反面两种情况。正面的概率是1,反面的概率是0。因为ln 1是0,可以直接省略。即便ln 0是无定义的,由于乘以0,表达式0ln 0也是0。计算的结果与图中显示的p(正面)=1时的熵为0相吻合。
交叉熵(cross entropy)同样是衡量结果的不确定性的指标。这种不确定性,是由结果的实际可能性与
我们预想的可能性之间的差异而导致的。
这听起来很抽象,所以让我们回到之前的硬币例子。如果我们认为一枚硬币是公平的,但事实上它并不公平,我们就会对结果感到意外。这些结果具有不确定性。这正是交叉熵要衡量的信息。如果我们认为一枚硬币是公平的,实际上它也确实是公平的,那么我们就不会对结果感到惊讶。在这种情况下,交叉熵会很小。
我们可以把交叉熵看作两个概率分布之间的比较。它们的相似度越高,交叉熵就越小。两个概率分布完全相同时的交叉熵为0。
这与神经网络有什么关系呢?事实上,神经网络的目标输出是概率分布,而实际输出也是概率分布。如果它们之间差异很大,交叉熵就会很高;如果它们很相似,交叉熵就会很低。这也正是我们希望损失函数所要实现的。
以上是对交叉熵的直观的解释,以下用数学表达式定义。结果是所有可能分类的总和,其中x是观察到的概率,y是该分类的实际概率。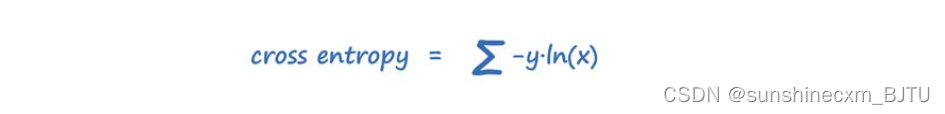
以之前的网络为例进行计算。输出值x为0.9,但实际应该是1.0。我们对所有可能的分类分别计算再求和。这里可能的分类是1.0和与它相反的0.0。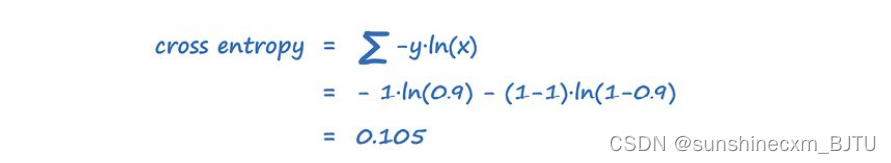
让我们换一个例子进行同样的计算。假设输出是0.1,而实际值应该是1.0。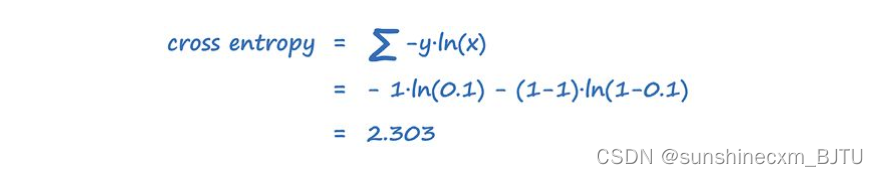
我们同样可以把这些结果汇总成一个表。相比上一个表多出一行,其中输出值x为0.9,实际应该是0.0。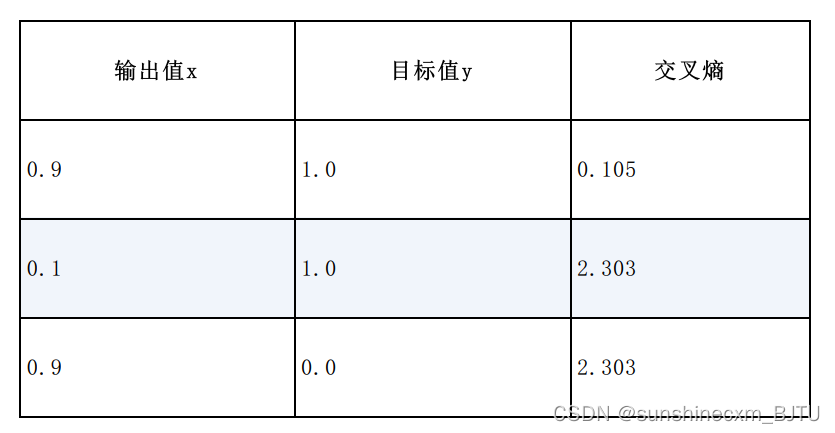
从前两行可以看出,在结果非常错误的情况下,交叉熵较大。而对于几乎正确的输出结果,交叉熵较小。从第3行可见,置信度高却错误的输出也有较大的交叉熵。这就是我们选择使用交叉熵作为损失函数的原因。
但为什么我们要用这种复杂的损失函数呢?毕竟计算MSE损失要简单得多,也更容易理解。
严格来说,我们可以使用任意一个可以惩罚错误输出的损失函数。有些人更喜欢对分类任务使用交叉熵,因为它可以从数学上被推导,而对于回归任务却不能。 但关键的原因在于,它对错误输出的惩罚力度更大。要知道,交叉熵与MSE损失的区别在于它包含对数,造成它的取值范围比1.0大得多。这种陡峭的损失函数可以反馈给神经网络很大的梯度。
下图显示,在正确输出是1.0时,不同观测输出的交叉熵损失。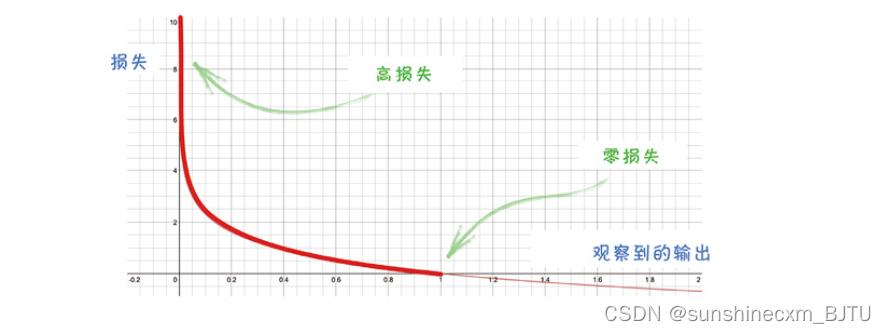
很明显,非常错误的输出对应非常大的损失值,梯度同样很大。
二元交叉熵是在只有两个分类的情况下使用的交叉熵。这正是鉴别器所面临的情况,真实数据为1.0,生成数据为0.0。
现在我们终于可以回答最初的问题了。当鉴别器和生成器达到平衡时,理想的二元交叉熵损失是多少?
当达到平衡时,鉴别器对两种数据的分类效果同样不佳,因此输出总是0.5。其中,有一些真实值是1.0,另一些应该是0.0。
对于x=0.5,y=1.0,我们计算交叉熵如下。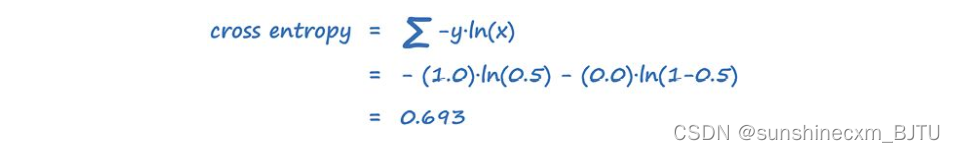
对于x=0.5和y=0.0,计算交叉熵得到的结果是一样的。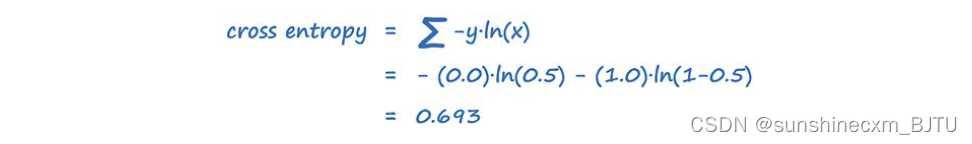
因此,使用BCELoss()损失函数时,GAN的理想损失值是0.693。















 1905
1905











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









