






 该博客介绍了如何利用Python通过GET请求调用深圳市政府开放数据平台提供的API,批量获取营运车辆GPS数据。首先,申请appKey,然后设置请求参数page和rows,通过循环遍历所有页面,将数据转换为DataFrame并存储到MySQL数据库中。整个过程中,使用了requests库获取数据,pandas处理数据,以及pymysql连接数据库。
该博客介绍了如何利用Python通过GET请求调用深圳市政府开放数据平台提供的API,批量获取营运车辆GPS数据。首先,申请appKey,然后设置请求参数page和rows,通过循环遍历所有页面,将数据转换为DataFrame并存储到MySQL数据库中。整个过程中,使用了requests库获取数据,pandas处理数据,以及pymysql连接数据库。
https://opendata.sz.gov.cn/data/api/toApiDetails/29200_00403621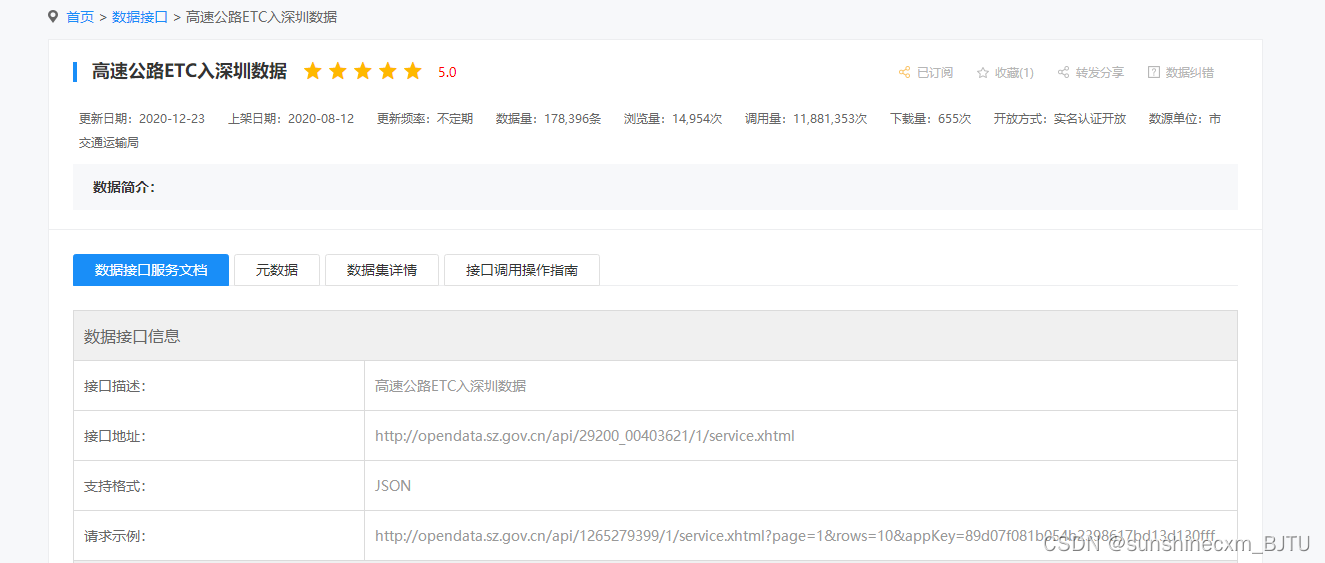
从上图可知,深圳市政府开放数据平台为每一个数据集提供了一个接口地址,并且只需要输入三个参数即可调用数据:appKey、page和rows。首先我们先“提交应用名称”和订阅接口以获取一个appKey,其实就是获取一个专属秘钥。其次,我们进入“测试接口”网页,见下图: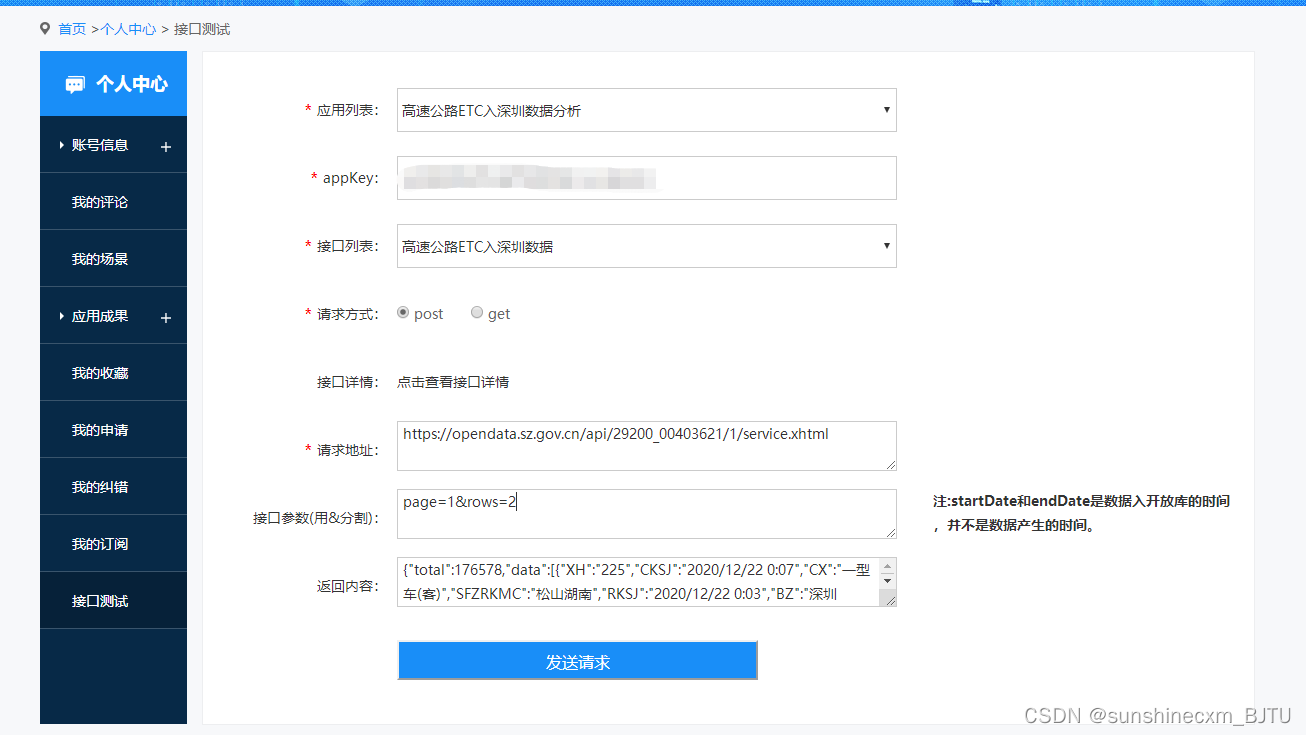
根据上图可知,在完成之前的步骤后,只需要确定“请求方式”和“API参数”后,我们点击蓝色的“发送请求”即可返回相应的内容。下面分别对“请求方式”和“API参数”进行分析。
用过爬虫的人都知道,最常用的网页请求方式就是get和post两种方式:
get:最常用的请求方式,一般用以获取或查询资源信息,也是大多数网站使用的方式,响应速度快;
post:相比于get方式,多了以表单形式上传的功能,因此除了查询信息外,还可以修改信息。
其次,上述的“API参数”需要输入两个值,分别为“page”和“rows”:
page:确定你要查询第几个页文件。例如,营运车辆GPS数据共有176578条,一般来说会将这么大的数据量分成几个部分,比如说分成100个部分,这样每个部分的数据量就不会过大,这里的说的部门就是“page”。
rows:确定你要在每个“page”里面存放多少行数据。例如上面的rows=2,就是第二个page里面只存储2行数据。
一般而言,page和rows是根据网页API的限制来定义的,设定每个page存储1000行,这共需要177个page(176578/1000=176.578)。
3 基于Python+MySQL工具的营运车辆GPS数据的批量获取
通过我们上面的分析,我们知道了营运车辆GPS数据的API调用原理,那么我们如何通过Python来进行批量数据获取呢?下面们将详细介绍这一实现过程。上述提到深圳市政府开放平台均支持get和post的请求方式获取数据,因为本文就用简单的get请求方式。用get方式获取数据需要调用request库中的get方法,所以读者需要先安装这个包。用法如下:
首先将之前的appKey和请求参数合并成一个url:
# url
url1 = 'https://opendata.sz.gov.cn/api/29200_00403621/1/service.xhtml?page='
url2 = str(page)
url3 = '&rows=10000'
url4 = '&appKey=XXX'
url = url1+url2+url3+url4
将获取到的数据存到strhtml变量中:
strhtml = requests.get(url)
这时候的strhtml代表整个网页的数据,但是我们只需要里面的源码,输入以下语句获取源码:
strhtml.text
获取源码以后,我们需要对其进行解析,转换为json格式:
dic = strhtml.json()
运行完这几个语句后,我们发现我们获取到了page1的5000行数据,他包含在dic的data键,是一个包含5000个元素的list。
由于上述代码只获取到page=1时的数据,如果我们需要获取全部页面的数据,则需要增加如下步骤:
- 增加一个循环,对每个页面的数据进行获取;
- 其次,由于获取的数据可读性较差,我们可以将获取的数据转换为DataFrame格式;
- 因为数据量较大,2133696行,故我们采取每读取一个page就将其存入到MySQL数据中。
import requests
import json
import pandas as pd
import pymysql
from sqlalchemy import create_engine
# 初始化数据库连接
# 按实际情况依次填写MySQL的用户名、密码、IP地址、端口、数据库名,
#一般而言只需要将下面的name和password替换即可
engine = create_engine('mysql+pymysql://name:password@localhost:3306/sample_veh_gps')
for page in range(1,428):
print(page)
pd_data = pd.DataFrame()
# url
url1 = 'https://opendata.sz.gov.cn/api/29200_00403621/1/service.xhtml?page='
url2 = str(page)
url3 = '&rows=10000'
url4 = '&appKey=c24286fbd4754aff9d099d1cec484343'
url = url1+url2+url3+url4
strhtml = requests.get(url)
strhtml.encoding = 'utf8'
dic = strhtml.json()
for i in range(0,len(dic['data'])):
pd_temp = pd.DataFrame.from_dict(dic['data'][i],orient='index').T
pd_data = pd_data.append(pd_temp,ignore_index=True)
try:
pd_data.to_sql('veh_gps',engine,index=False,if_exists='append')
except Exception as e:
print(e)

















 2919
2919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









