







 这段代码首先导入了所需的库,然后读取CSV数据并使用Word2Vec训练模型。接着,它将文本数据转换为向量形式,并构建了一个CNN和RNN模型。最后,对模型进行了训练并展示了训练过程中的准确率和损失情况。
这段代码首先导入了所需的库,然后读取CSV数据并使用Word2Vec训练模型。接着,它将文本数据转换为向量形式,并构建了一个CNN和RNN模型。最后,对模型进行了训练并展示了训练过程中的准确率和损失情况。
二、数据预处理
一开始还是导入需要用到的包
#导包
import numpy as np
import pandas as pd
import sys
from gensim.models import word2vec
import os
import gensim
from gensim.models.word2vec import LineSentence#读数据
data = pd.read_csv('./data.csv')
data
#训练
model = word2vec.Word2Vec(sentences,size = 100)
model.save('jk.model')向量化
#读取出数据
import pprint
text = data['split']
sentences = []
for item in text:
sentence = str(item).split(' ')
sentences.append(sentence)
def buildWordVector(imdb_w2v,text, size):
vec = np.zeros(size).reshape((1, size))
pad = np.zeros(size).reshape((1, size))
count = 0
for word in text.split():
try:
vec = np.vstack((vec, imdb_w2v[word].reshape((1, size))))
count += 1
except KeyError:
print (word)
vec = np.delete(vec, 0, 0)
#填充不满260的矩阵
if len(vec) < 260:
for i in range(260 - len(vec)):
vec = np.vstack((vec, pad))
return vec
for word in text.split():
try:
vec = np.vstack((vec, imdb_w2v[word].reshape((1, size))))
count += 1
except KeyError:
print (word)
if len(vec) < 260:
for i in range(260 - len(vec)):
vec = np.vstack((vec, pad))
result = buildWordVector(model_word, data.loc[1]['split'] , 100)
for i in range(1,len(data)):
result = np.concatenate((result, buildWordVector(model_word, data.loc[i]['split'] , 100)), axis = 0)
result.shape
x_all = result.reshape(2631,260,100)
import tensorflow as tf
from sklearn.model_selection import train_test_split
# 训练模型并预测
random_state = np.random.RandomState(0)
# 随机化数据,并划分训练数据和测试数据
X_train, X_test, y_train, y_test = train_test_split(x_all, y, test_size=0.2,random_state=0)
from keras.models import Sequential
from keras.layers import Dense, Activation, Flatten, Conv1D, Embedding, Dropout, MaxPool1D, GlobalMaxPool1D,Lambda, LSTM, TimeDistributed
from keras.optimizers import Adam
import kerasmodel = Sequential()
model_cnn.add(Conv1D(input_shape = (260,100),filters=100,kernel_size=3, padding='valid', activation='sigmoid',strides=1))
model_cnn.add(GlobalMaxPool1D())
model_cnn.add(Dense(y.shape[1], activation='softmax'))
model_cnn.add(Dropout(0.2))
model_cnn.compile(loss='categorical_hinge', optimizer = 'adam', metrics=['accuracy'])
model_cnn.summary()
model_rnn = Sequential()
model_rnn.add(LSTM(256, input_shape=(260,100), return_sequences=True))
model_rnn.add(Dropout(0.2))
model_rnn.add(LSTM(256))
model_rnn.add(Dense(1, activation='sigmoid'))
opt = Adam(lr=1e-3, decay=1e-5)
model_rnn.compile(loss='categorical_hinge', optimizer=opt)
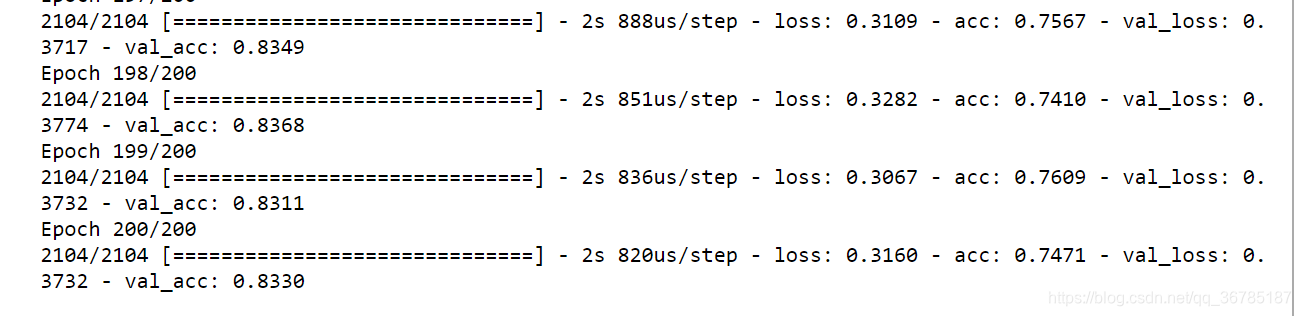
a = model_cnn.history
plt.plot(a.history['acc'], linewidth=0.5)
plt.plot(a.history['val_acc'],linewidth=0.5)
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['acc', 'val_acc'], loc = 'lower right')
plt.show()
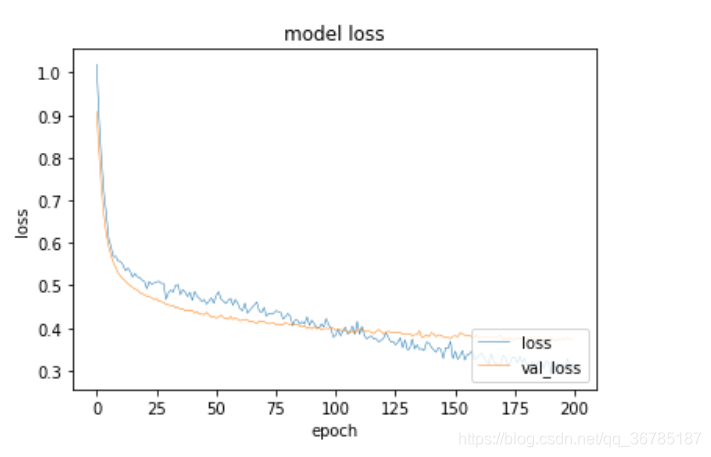
plt.plot(a.history['loss'], linewidth=0.5)
plt.plot(a.history['val_loss'], linewidth=0.5)
plt.title('model loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['loss', 'val_loss'], loc='lower right')
plt.show()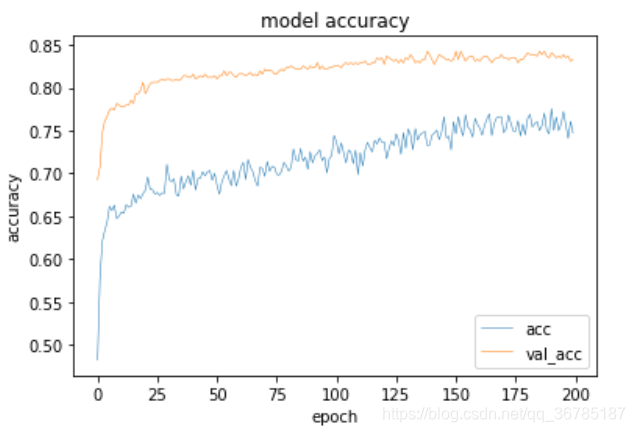


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









