







CNN or RNN(LSTM)
一、背景
这次项目是导师的一个课题,大概需求是在工厂内,有许多生产设备,其设备的产出率与利润直接挂钩。因此,保证设备稳定的高产率是节约成本、提高利润的重要工作。而通常管理设备、依照当前状态,实时调整电压、电流等各相关指数通常是由专业技术人员负责,培养一个专业调控人员的成本是很高的,因此就需要一个模型能够代替人工对设备进行实时相控以保证高产率。
在本次项目里,目的也是如此。在本项目中,一个值x是人工无法实时测量的,只能在每次停炉检查的时候才能人工测量,但在工作时期,x这个值对炉中功率的影响尤其重要,操作人员通常是通过人工经验评估的方法对其进行评估,并依照经验对其他量进行调整。由此虽然效果也还行,但也只是差强人意。
若可以通过其他的可以实时获取的相关量,间接求出每一个时刻下的此值x,那对于工厂来说,就可以更加科学的进行调控,杜绝了人员犯错的风险。
数据大概如下所示: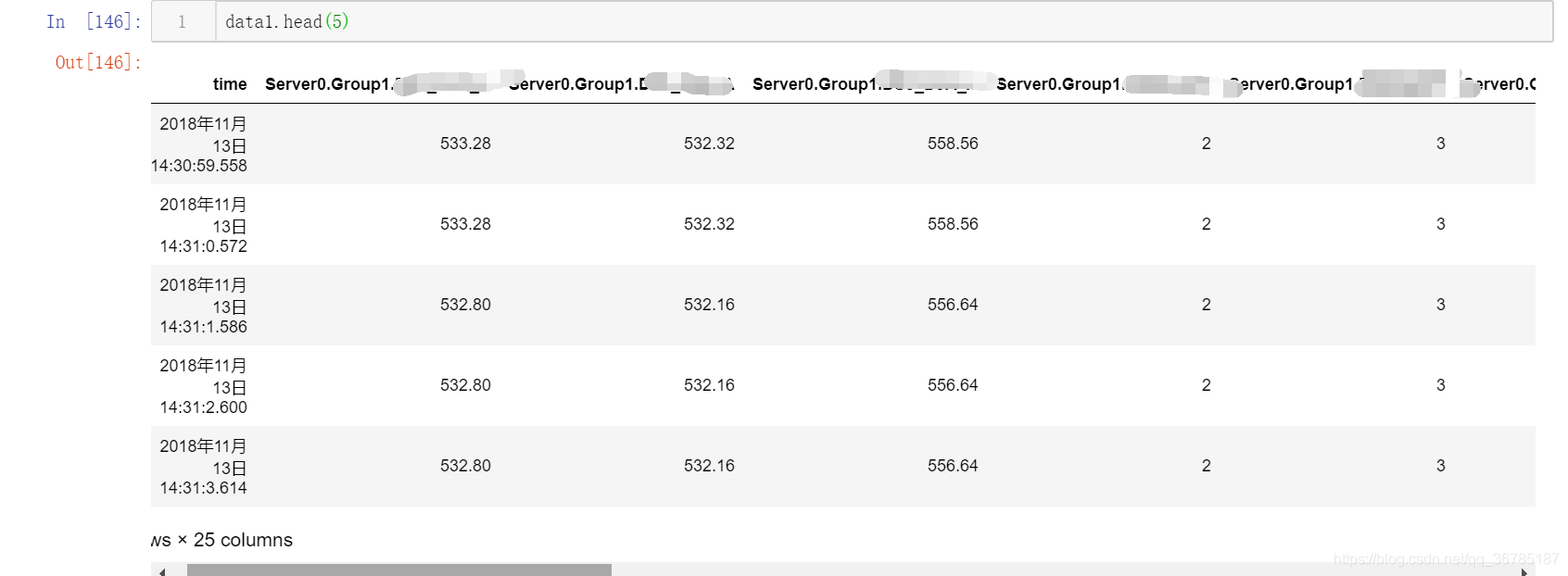
数据中可以看出,特征里有电压挡位、电流、功率、及相关参数。
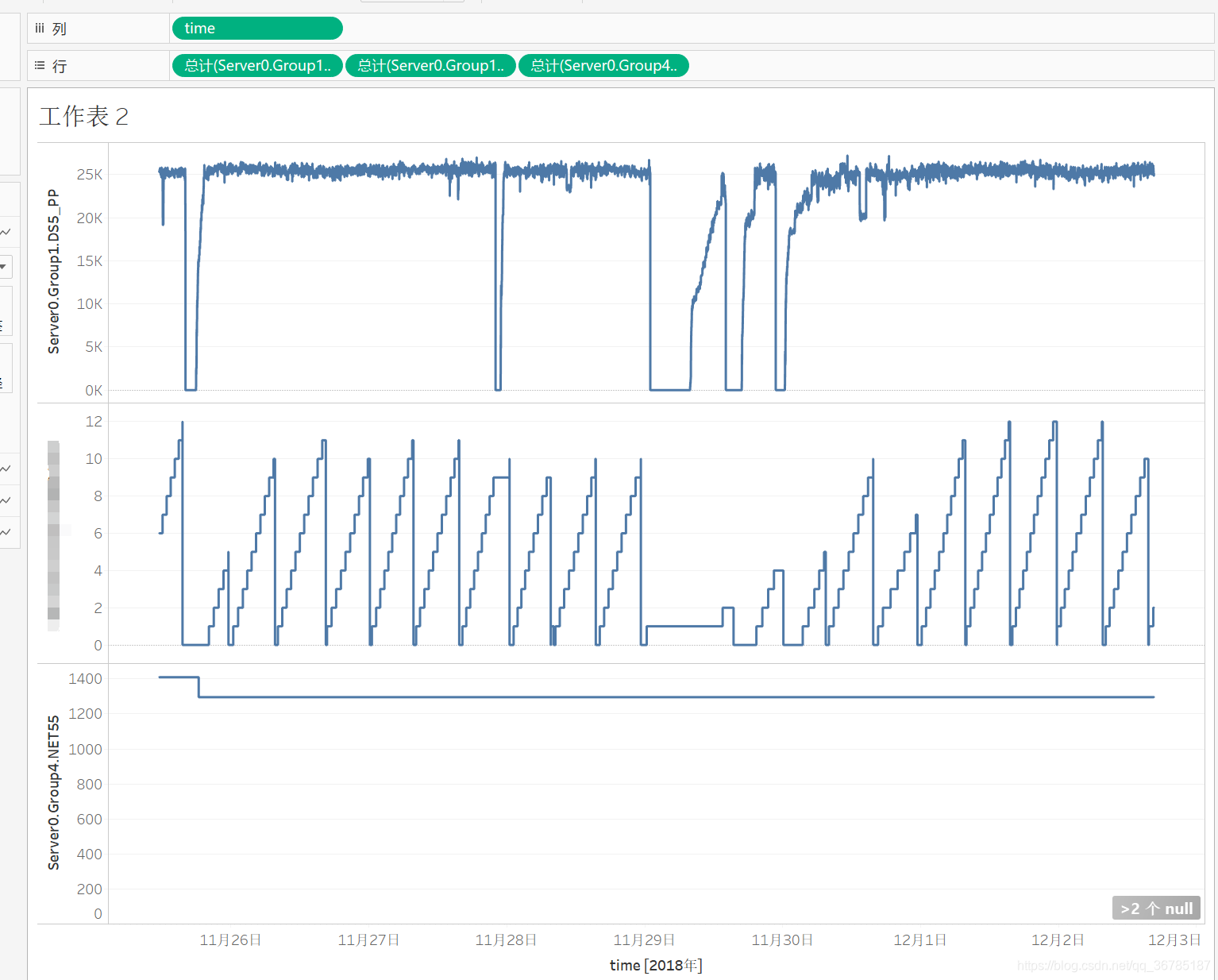
并且,对于我们需要预测出的量x,其并没有一一对应,几天才更新一次。并不能把这个x当作标记值y来直接建模。
每一组数据,大概有60W条左右,预测量的变化仅一次,y的严重缺失导致不能常规的去建模训练。因此,通过老师的帮助与提示,将目标放在了另一个可以自定义的参数x2上,借以预测出下一班次的压放次数x2,来间接预测出实时长度。
x2约八小时重置为0一次,如上图中,位于中间的部分,将每一段的所有数据作为特征变量,下一段的最高值作为预测值y。
对其进行建模,利用时序性的特点,将每一段中间约3万条数据作为时间跨度,去预测下一阶段的值。
二、数据预处理
#获取data1每一段的起点
dots_zero_start = []
for i in range(len(data1)):
if(data1.loc[i, 'Server0.Group1.DS5DJAYF'] == 0):
if(data1.loc[i + 1, 'Server0.Group1.DS5DJAYF'] != 0):
dots_zero_start.append(i)
else:
continue
#根据图删掉最后一个
del(dots_zero_start[13])
for num in range(len(dots_zero_start)):
time = data1.loc[dots_zero_start[num], 'time']
print(time + '\n')
print('起点一共有: ', len(dots_zero_start), '个')#获取每一段的尾点
dots_zero_end = []
for i in range(0, (len(data1) - 1)):
if(data1.loc[i, 'Server0.Group1.DS5DJAYF'] != 0):
if(data1.loc[i + 1, 'Server0.Group1.DS5DJAYF'] == 0):
dots_zero_end.append(i)
else:
continue
#根据图删掉第一个
del(dots_zero_end[0])
for num in range(len(dots_zero_end)):
time = data1.loc[dots_zero_end[num], 'time']
print(time + '\n')
print('起点一共有: ', len(dots_zero_end), '个')#计算每一段有多少个数据
minus = []
for i in range(len(dots_zero_end)):
m = dots_zero_end[i] - dots_zero_start[i]
minus.append(m)
minus#取出每一段的所有数据行
x_sets = []
for set_index in range(len(dots_zero_end)):
set_indexs = data1.loc[(dots_zero_start[set_index]) : (dots_zero_end[set_index])]
x_sets.append(set_indexs)x = x_sets[:-1]y = [8, 9, 10, 10, 8, 10, 11, 12, 10, 13, 13 ,13]#获取data2每一段的尾点
dots_zero_end2 = []
for i in range(0, (len(data2) - 1)):
if(data2.loc[i, 'Server0.Group1.DS5DJAYF'] != 0):
if(data2.loc[i + 1, 'Server0.Group1.DS5DJAYF'] == 0):
dots_zero_end2.append(i)
else:
continue
#根据图删掉第一个
del(dots_zero_end2[0])
del(dots_zero_end2[4])
del(dots_zero_end2[8])
dots_zero_end2 = dots_zero_end2[:10]
for num in range(len(dots_zero_end2)):
time = data2.loc[dots_zero_end2[num], 'time']
print(time)
print('起点一共有: ', len(dots_zero_end2), '个')#计算每一段有多少个数据
minus2 = []
for i in range(len(dots_zero_end2)):
m = dots_zero_end2[i] - dots_zero_start2[i]
minus2.append(m)
minus2#取出每一段的所有数据行
x_sets2 = []
for set_index in range(len(dots_zero_end2)):
set_indexs = data2.loc[(dots_zero_start2[set_index]) : (dots_zero_end2[set_index])]
x_sets2.append(set_indexs)x2 = x_sets2[:-1]y2 = [10, 11, 10, 11, 11, 10, 9, 10, 10] #获取data3每一段的起点
dots_zero_start3 = []
for i in range(len(data3)):
if(data3.loc[i, 'Server0.Group1.DS5DJAYF'] == 0):
if(data3.loc[i + 1, 'Server0.Group1.DS5DJAYF'] != 0):
dots_zero_start3.append(i)
else:
continue
del(dots_zero_start3[9])
dots_zero_start3 = dots_zero_start3[:16]
#根据图删掉最后一个
for num in range(len(dots_zero_start3)):
time = data3.loc[dots_zero_start3[num], 'time']
print(time + '\n')
print('起点一共有: ', len(dots_zero_start3), '个')
#获取data3每一段的尾点
dots_zero_end3 = []
for i in range(0, (len(data3) - 1)):
if(data3.loc[i, 'Server0.Group1.DS5DJAYF'] != 0):
if(data3.loc[i + 1, 'Server0.Group1.DS5DJAYF'] == 0):
dots_zero_end3.append(i)
else:
continue
#根据图删掉第一个
del(dots_zero_end3[0])
del(dots_zero_end3[9])
dots_zero_end3 = dots_zero_end3[:-5]
for num in range(len(dots_zero_end3)):
time = data3.loc[dots_zero_end3[num], 'time']
print(time)
print('起点一共有: ', len(dots_zero_end3), '个')#计算每一段有多少个数据
minus3 = []
for i in range(len(dots_zero_end3)):
m = dots_zero_end3[i] - dots_zero_start3[i]
minus3.append(m)
minus3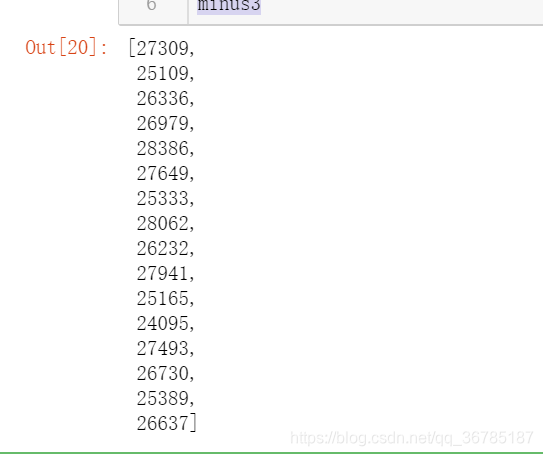
#取出每一段的所有数据行
x_sets3 = []
for set_index in range(len(dots_zero_end3)):
set_indexs = data3.loc[(dots_zero_start3[set_index]) : (dots_zero_end3[set_index])]
x_sets3.append(set_indexs)x3 = x_sets3[:-1]y3 = [10, 12, 12, 12, 12, 10, 11, 10, 9, 7, 7, 8, 9, 9, 6] x[0].head(1)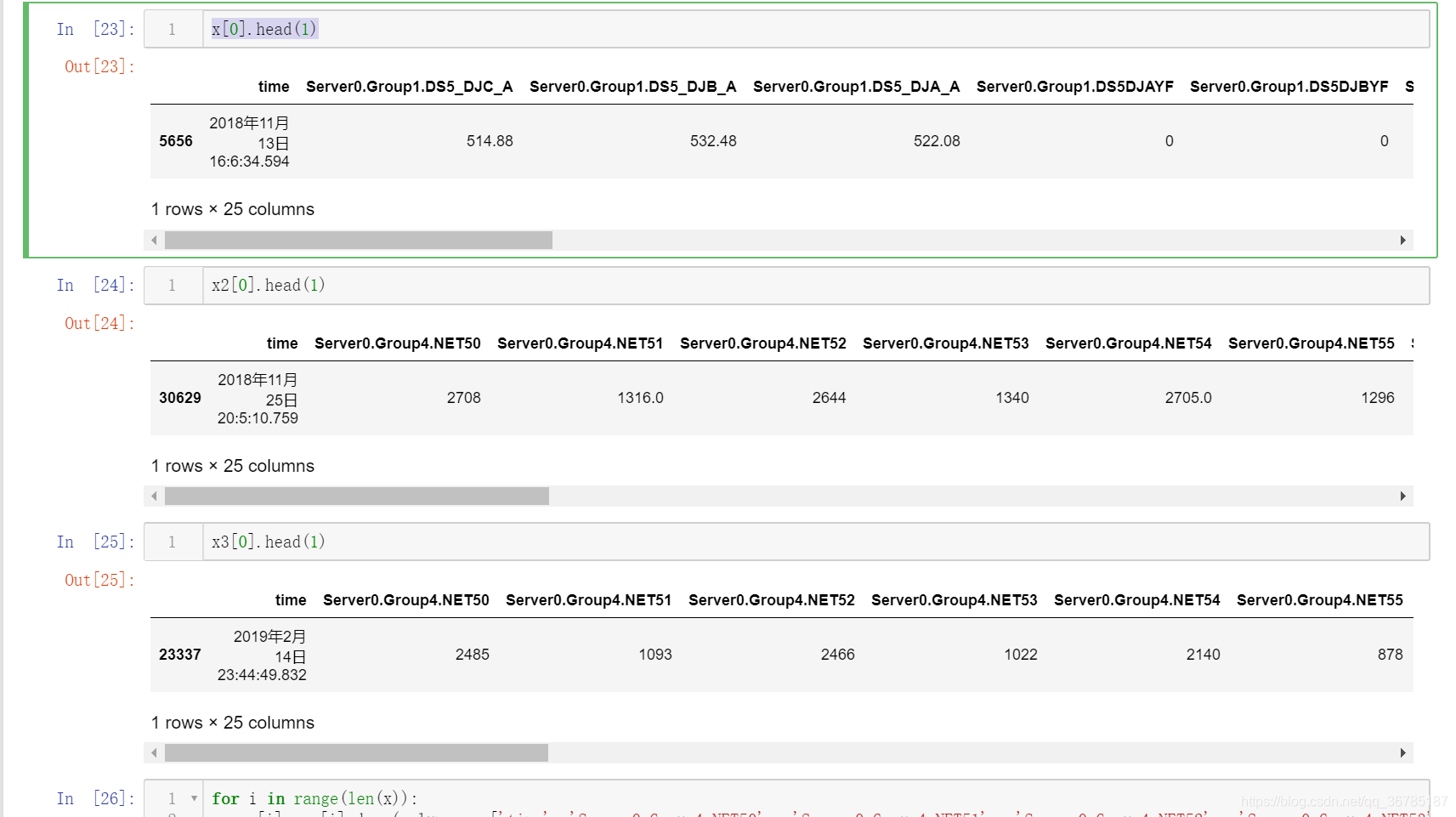
去除三个数据组中所有段之后,发现data3的变量顺序和其他不同,因此稍微修改一下
#修改x3次序,和x1、x2相同排序方式
for i in range(len(x3)):
DS5_DJC_A = x3[i]['Server0.Group1.DS5_DJC_A']
DS5_DJB_A = x3[i]['Server0.Group1.DS5_DJB_A']
DS5_DJA_A = x3[i]['Server0.Group1.DS5_DJA_A']
DS5DJAYF = x3[i]['Server0.Group1.DS5DJAYF']
DS5DJBYF = x3[i]['Server0.Group1.DS5DJBYF']
DS5DJCYF = x3[i]['Server0.Group1.DS5DJCYF']
DS5_P0 = x3[i]['Server0.Group1.DS5_P0']
DS5_COS = x3[i]['Server0.Group1.DS5_COS']
DS5_PP = x3[i]['Server0.Group1.DS5_PP']
DS5BYQC_D = x3[i]['Server0.Group1.DS5BYQC_D']
DS5BYQB_D = x3[i]['Server0.Group1.DS5BYQB_D']
DS5BYQA_D = x3[i]['Server0.Group1.DS5BYQA_D']
DS1BY11 = x3[i]['Server0.Group1.DS1BY11']
DS1BY10 = x3[i]['Server0.Group1.DS1BY10']
DS1BY09 = x3[i]['Server0.Group1.DS1BY09']
DS1DJ3_P = x3[i]['Server0.Group1.DS1DJ3_P']
DS1DJ2_P = x3[i]['Server0.Group1.DS1DJ2_P']
DS1DJ1_P = x3[i]['Server0.Group1.DS1DJ1_P']
a = pd.DataFrame()
a = pd.concat([a,DS5_DJC_A], axis = 1)
a = pd.concat([a,DS5_DJB_A], axis = 1)
a = pd.concat([a,DS5_DJA_A], axis = 1)
a = pd.concat([a,DS5DJAYF], axis = 1)
a = pd.concat([a,DS5DJBYF], axis = 1)
a = pd.concat([a,DS5DJCYF], axis = 1)
a = pd.concat([a,DS5_P0], axis = 1)
a = pd.concat([a,DS5_COS], axis = 1)
a = pd.concat([a, DS5_PP], axis = 1)
a = pd.concat([a, DS5BYQC_D], axis = 1)
a = pd.concat([a, DS5BYQB_D], axis = 1)
a = pd.concat([a, DS5BYQA_D], axis = 1)
a = pd.concat([a, DS1BY11], axis = 1)
a = pd.concat([a, DS1BY10], axis = 1)
a = pd.concat([a, DS1BY09], axis = 1)
a = pd.concat([a, DS1DJ3_P], axis = 1)
a = pd.concat([a, DS1DJ2_P], axis = 1)
a = pd.concat([a, DS1DJ1_P], axis = 1)
x3[i] = a这里有点智障了,脑子昏昏的,不想去编函数处理,看变量数量也不对,干脆就直接暴力的转顺序。。。
for i in range(len(x)):
x[i] = x[i].drop(columns = ['time', 'Server0.Group4.NET50', 'Server0.Group4.NET51', 'Server0.Group4.NET52', 'Server0.Group4.NET53', 'Server0.Group4.NET54', 'Server0.Group4.NET55'])
for i in range(len(x2)):
x2[i] = x2[i].drop(columns = ['time', 'Server0.Group4.NET50', 'Server0.Group4.NET51', 'Server0.Group4.NET52', 'Server0.Group4.NET53', 'Server0.Group4.NET54', 'Server0.Group4.NET55'])
for i in range(len(x3)):
x3[i] = x3[i].drop(columns = ['time', 'Server0.Group4.NET50', 'Server0.Group4.NET51', 'Server0.Group4.NET52', 'Server0.Group4.NET53', 'Server0.Group4.NET54', 'Server0.Group4.NET55'])这里把无关变量删去,那些都是不能实时变化的值
然后现在存在一个问题就是,每一段之间的数据量并不一样,所以如果想利用lstm或者cnn进行建模,需要对其做个处理。
大概有俩种思路:
一种是,将每一段的中位数、方差、平均数取出来,成一个3*18的矩阵作为输入。最终为n * 3 * 18的三维数据。
另一种是,干脆将所有数据扩充为30000 * 18的矩阵,对不满30000的,将中位数进行填充项,填满。
个人最后是采取了后者,因为想着每一段数据基本都是2万7千条左右,如果仅仅合并为3条,对特征的压缩抽象太严重了,不能很好的利用已有的大批量数据。
代码如下:
#填补data1所有数据
for index in range(len(x)):
mean = (pd.DataFrame(x[index].mean())).T
print('现在处理的是',index ,'段' + '/n')
if len(x[index]) < 30000:
for i in range(30000 - len(x[index])):
x[index] = x[index].append(mean)
print('增加',i,'个')#填补data2所有数据
for index in range(len(x2)):
mean = (pd.DataFrame(x2[index].mean())).T
print('现在处理的是',index ,'段' + '/n')
if len(x2[index]) < 30000:
for i in range(30000 - len(x2[index])):
x2[index] = x2[index].append(mean)
print('增加',i,'个')#填补data3所有数据
for index in range(len(x3)):
mean = (pd.DataFrame(x3[index].mean())).T
print('现在处理的是',index ,'段' + '/n')
if len(x3[index]) < 30000:
for i in range(30000 - len(x3[index])):
x3[index] = x3[index].append(mean)
print('增加',i,'个')X = x[0]
for i in range(1, len(x)):
X = pd.concat([X, x[i]], ignore_index=True)
for i in range(len(x2)):
X = pd.concat([X, x2[i]], ignore_index=True)
for i in range(len(x3)):
X = pd.concat([X, x3[i]], ignore_index=True)填充完以后,将三个data中的所有数据,拼接在一起,作为X,便于后续操作。
mms = MinMaxScaler()
X1 = mms.fit_transform(X1)因为数据的各变量量纲不同,因此需要做归一化处理,对其最大最小规范化。
X_all = X1.reshape(36, 30000,17 )因为三个data中,最终整理出来了36段含有y的数据段,因此,reshape一下
for i in range(len(y2)):
y.append(y2[i])
for i in range(len(y3)):
y.append(y3[i])
y将y也拼凑一下
二、建模
这里分成了俩个部分,第一个是使用了CNN进行建模,经过基本调参后得到:
model_cnn = Sequential()
model_cnn.add(Conv1D(input_shape = (30000,17),filters=50,kernel_size=3, padding='valid', activation='sigmoid',strides=1))
model_cnn.add(GlobalMaxPool1D())
model_cnn.add(Dense(1))
model_cnn.compile(loss='mean_squared_error', optimizer = 'adam', metrics=['mse'])
model_cnn.summary()# 训练模型并预测
random_state = np.random.RandomState(0)
# 随机化数据,并划分训练数据和测试数据
X_train, X_test, y_train, y_test = train_test_split(X_all, y, test_size=0.3,random_state=0)model_cnn.fit(X_train, y_train, epochs=1000,batch_size = 1, validation_data=(X_test, y_test))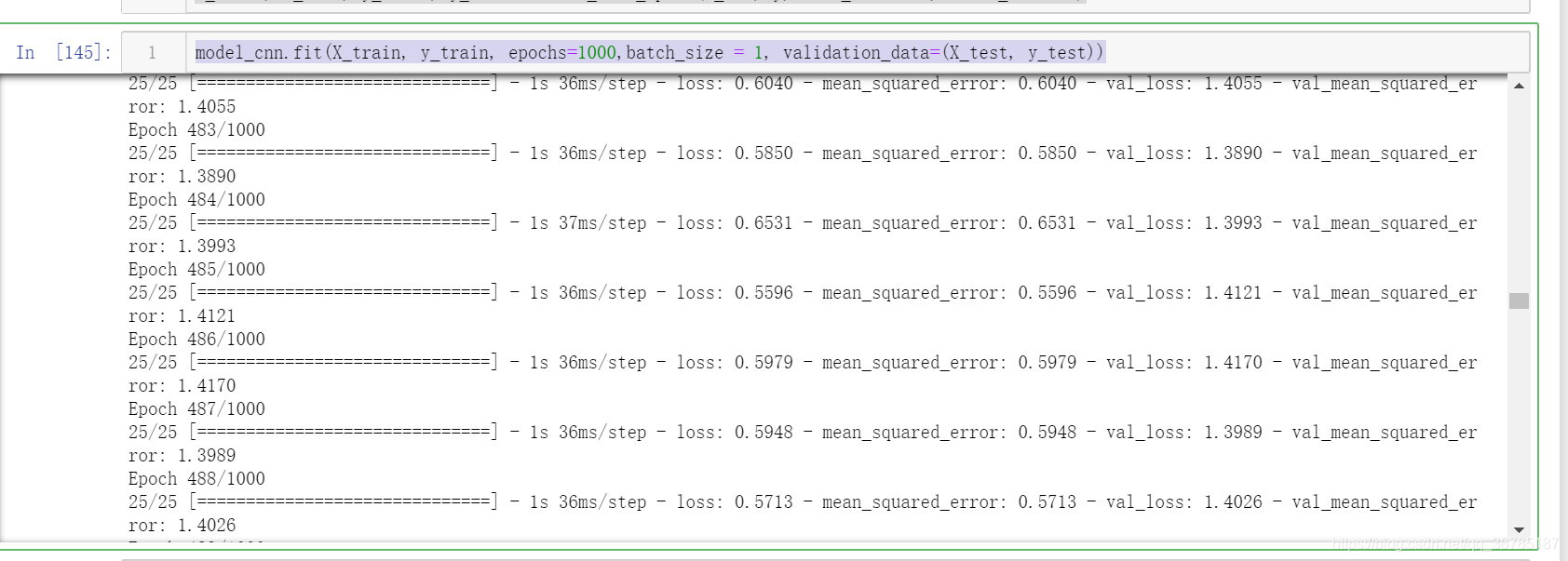
约在480次时开始稳定,最终训练集mse为0.5713,测试集mse为1.3890
然后是LSTM,这里吐槽一下,lstm的速度是真的慢的不行,一个epoch的时间就要470s,晚上睡觉的时候设为200次,第二天中午看,才跑了一半,但看了记录,发现到了49次的时候就开始稳定了
model_lstm = Sequential()
model_lstm.add(LSTM(len(X_train), input_shape = (30000, 7)))
model_lstm.add(Dense(1))
model_lstm.compile(loss = 'mse', optimizer = 'adam',metrics=['mse'])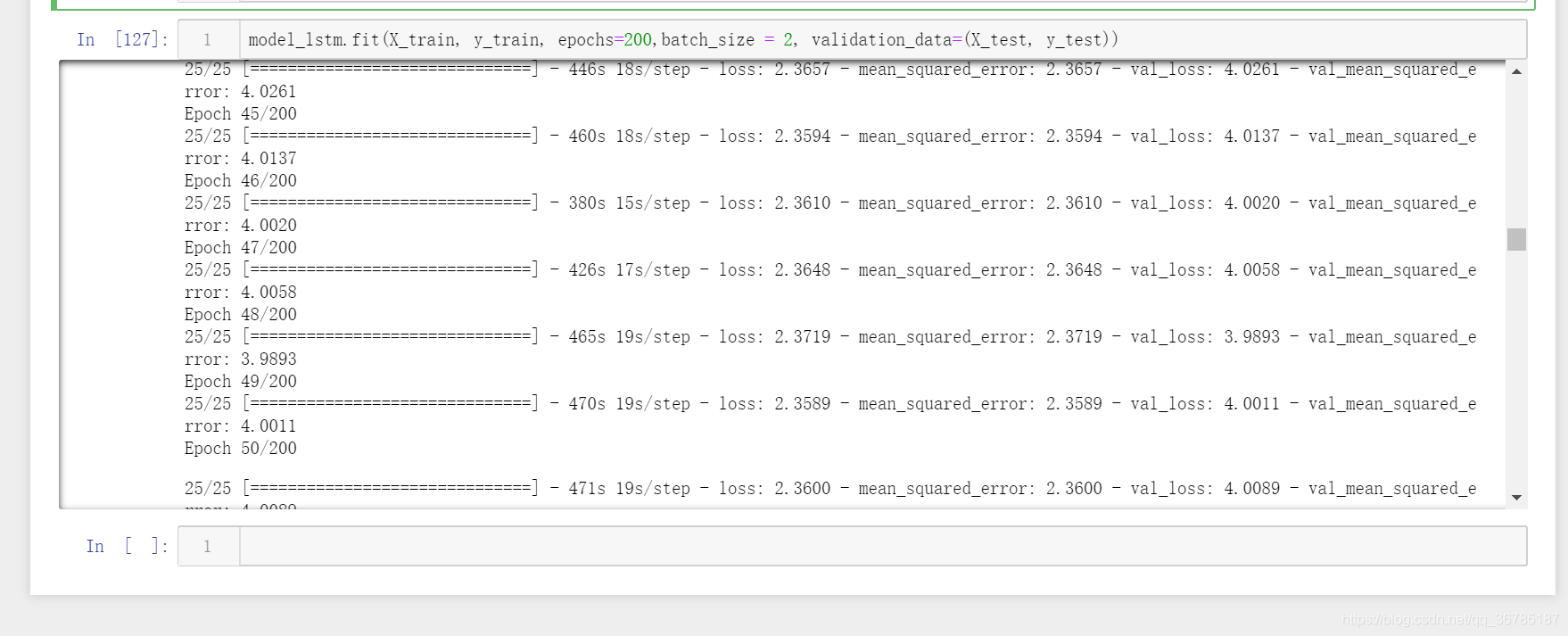
最终结果,训练集mse为2.3719,测试集的mse为3.9893,效果不如卷积的好
以上就是目前的研究现状,暂时还没有对数据特征进行构建、相关性检查删减,后期会继续尝试新的数据构建方式。
(数据不便外放,见谅!)















 27
27











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









