






三、文本分类有我:TF-IDF(词频-逆向文档频率)
对于TF很好理解,统计词袋中的词在每篇文章里出现的次数,没有出现的就是0。其实,直接使用TF就已经可以分类了,而且在小的数据集下表现还算ok,但是有个很突出的问题就是这样统计的话,文章的长短对分类的结果影响很大,因为文章越长出现词袋里的词的概率就越大,比如人文社科类的文章也会出现‘汽车’这个词,而且文章长了,‘汽车’可能出现的不止一次,这样分类的时候就很有可能把这种文章归到汽车类文章下了,但是结果肯定是不对的嘛。所以首先将这个数字归一化,即计算该词在谋篇文章中出现的频率,
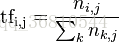
上式中,分子是某个词在文章中出现的次数,分母是文章中所有词出现的次数之和
IDF是一个词语普遍重要性的度量,某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到
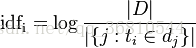
其中,分子为样本集中所有文章的总数,分母为 样本集中包含该词的总数(计算时因为已经统计了每个词的频率,所有用 总数-样本集中不包含该词的文章数 来计算),一般为了防止除0会将分母加1,所有代码中看到的是
idf = np.log(docNum / (1.0 + docNum - np.sum(self.__sample_data__ == 0, axis=0)))而进一步将tf的计算从单个文件扩展到了计算每个类的tf
for index, className in enumerate(self.__labelvec__):
if not matrixDic.has_key(className):
matrixDic[className] = [0] * self.__sample_data__.shape[1]
matrixDic[className]+=self.__sample_data__[index,:]/float(sum(self.__sample_data__[index,:]) + 1)最后将tf*log(idf)就是我们要的结果 np.array(weightMatrix) * log(idf)
说两句废话:在做矩阵运算的时候能用这种方式的就不要用for循环,效率真的差了很多。这次特意做了次试验,self.sample_data 是一个大约5600*140000的矩阵,采用for循环计算每列的idf大概需要7分钟,当然for循环里依然是for循环,而采用上面的形式后是11s !
四、贝叶斯是谁?
到这里已经把文本变成能够计算的矩阵了,那么怎 么算呢?贝叶斯说:我来!其实,回顾下我们是怎么把文章变成矩阵的,就是统计呗,那么很自然的就想到了条件概率咯。如果类1中出现词x1,x2,x3的概率很大,那么在x1,x2,x3出现的概率下出现类1的概率也应该很大,我们称前面的是先验概率,而后面的就是后验概率咯。这个问题,贝叶斯老先生早就给出答案了
进一步考虑全概公式:
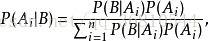
这里的A i就是每篇文章中词的tf-idf值, P ( B | A i )就是在出现词A1,A2,A3….Ai的情况下类B的概率,也就是我们最终要计算的结果, 而P (A i | B )就是在类B出现的情况下,出现词A1,A2,A3….Ai的概率,这个可以在样本集中直接计算得到。分母对于要计算的每个类都是一样的,不影响结果所以不用计算,这样分别计算待测样本在每个类下的概率,取最大的值的那个类就是我们的分类结果
def Pridict(self,testVec):
classProb = self.__classprob__
test_array = array(testVec,dtype=float)
vec = np.array([sum(np.log(self.dataMatrix[index,:] * test_array +1))+classProb[lable] for index, lable in enumerate(self.labelVec)])
maxVal = vec.max()
index = np.argwhere(vec == maxVal)
lable = self.labelVec[index[0][0]]
return lable这样就得到了文章开头的结果!
五、词向量模型
这里仅做一个抛砖引玉的作用,因为我也刚接触词向量没太长时间,怕误导了不明真相的群众。做个使用介绍吧,先说下我是怎么想的,很可能是错误的!我是在ubuntu16上直接安装的,分别对每个类训练了一个模型,也可能这个思路不对!然后,读了下gensim下的源码,发现most_similar()里的计算就是去查找新的词是否在模型中,然后给出分数,借助这个思路,我将待分类的文章里的每个词分别用每个模型的most_similar()函数计算一次,取结果的第一个数,然后所有词求和,哪个类得到的分数大就分到哪个类下,结果,分类结果很感人
2017-11-27 10:24:22,104 - main - INFO - the class 0 rate is 2.12765957447%
2017-11-27 10:24:22,104 - main - INFO - the class 1 rate is 0.348432055749%
2017-11-27 10:24:22,104 - main - INFO - the class 2 rate is 2.98507462687%
2017-11-27 10:24:22,104 - main - INFO - the class 3 rate is 0.367647058824%
2017-11-27 10:24:22,104 - main - INFO - the class 4 rate is 1.08108108108%
2017-11-27 10:24:22,104 - main - INFO - the class 5 rate is 1.02040816327%
2017-11-27 10:24:22,104 - main - INFO - the class 6 rate is 0.0%
2017-11-27 10:24:22,104 - main - INFO - the class 7 rate is 0.735294117647%
2017-11-27 10:24:22,104 - main - INFO - the class 8 rate is 28.8372093023%
2017-11-27 10:24:22,104 - main - INFO - the class 9 rate is 31.5589353612%
2017-11-27 10:24:22,105 - main - INFO - the total correct rate is 6.9825436409%
我已经不想说什么了。
简单实用介绍,输入是已经分词过的文件:
import multiprocessing
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
model = Word2Vec(LineSentence(fileName), size=400, window=5, min_count=5, workers=multiprocessing.cpu_count())
print model.wv[u'新车']
[ -6.10132441e-02 -1.15644395e-01 5.97980022e-01 2.00566962e-01
2.73794159e-02 1.44698828e-01 1.11371055e-01 2.28789579e-02
......
]
model.most_similar(u'新车')
[(u'\u62db\u6570', 0.9994064569473267), (u'\u7cfb\u5217', 0.9993598461151123),...]
#保存模型
model.save(modelName)
model.wv.save_word2vec_format(vecName, binary=False)
#加载模型
wvModel = Word2Vec.load(wvModelFile)基本操作就是这些了,很简单,有兴趣的话可以直接去看源码。
六、结语
从物理意义上来说,我觉得利用词向量去分类应该会得到更好的结果,但是刚接触,还需要多看资料。之所以把标题写成‘从词频到神经网络’一是因为词向量的模型是用一个简单的3层网络训练出来,二来,词向量是已经可以送入ANN进行训练的了,出于时间问题还没进行进一步的研究,希望下篇文章就是利用词向量训练ANN的内容。文章中出现的错误和有没交代清楚的还请通知我,第一次用CSDN的公式编辑器真心不会用啊,折腾了半天最后公式还是贴的图,求不BS ^_^

















 3762
3762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









