







数据分类:结构化数据,指固定格式或有限长度(例如数据库数据,元数据等)/非结构化数据。指不定长或无固定格式(例如word文档等磁盘上的文件)
非结构化数据查询方法:全文检索(使用技术有:Lucene ,solr(更多操作类似于xml格式数据),ElasticSearch(更多操作json格式数据)),顺序扫描法()
半结构化数据:xml html
为什么使用solr:
1. solr本身也可以看成数据库,(no sql类型),但它比数据库搜索速度更快,所以在项目中我们一般把搜搜的部分交给solr,就像我们在京东首页所看到的商品信息,并不是来自数据库,而是来源于sorl的索引库
2. 数据库本身不能实现分词效果,而只能使用模糊查询,但是模糊查询非常低效,查询速度比较慢,由于在实际生活中,一般搜索是用的比较多的,这样数据库压力自然就很大,所以我们就让供专业的solr来做搜索功能
流程:
solr使用:
1、下载最新版本 https://mirror.bit.edu.cn/apache/lucene/solr/
解压直接使用,cmd进入slor解压下的bin目录 D:\solr-8.5.1\bin
启动命令:solr start
关闭命令:solr stop -all
重启solr :solr restart –p p_num
访问路径:http://localhost:8983/solr/
2、创建核心
在solr目录下 D:\solr-8.5.1\server\solr添加核心目录
将D:\solr-8.5.1\server\solr\configsets\sample_techproducts_configs目录下conf复制到创建的核心目录下
选择Core Admin
右侧输入框的name和 InstanceDir输入名称和创建的核心文件夹保持一致,创建成功
3、添加分词器
(1)、solr自带的中文分词器 配置:
将solr目录D:\solr-8.5.1\contrib\analysis-extras\lucene-libs\lucene-analyzers-smartcn-*-.jar复制到D:\solr-8.5.1\server\solr-webapp\webapp\libs下
在创建的核心目录下conf里面managed-schema文件中添加
fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="100"
analyzer type="index"
tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"
analyzer
analyzer type="query"
analyzer
fieldType
自带的分词效果以及扩展性不是很好
(2)、使用IK分词器
下载jar https://search.maven.org/search?q=com.github.magese,放入D:\solr-8.5.1\server\solr-webapp\webapp\libs下
在managed-schema文件中,增加如下代码
fieldType name="text_ik" class="solr.TextField"
analyzer type="index"
tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"
filter class="solr.LowerCaseFilterFactory"
analyzer
analyzer type="query"
tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"
filter class="solr.LowerCaseFilterFactory"
analyzer
fieldType
4、数据导入(数据库)
1、将mysql和solr-dataimporthander包放入D:\solr-8.5.1\server\solr-webapp\webapp\libs下
2、在solrconfig.xml中720行左右添加
requestHandler name="/dataimport"
class="org.apache.solr.handler.dataimport.DataImportHandler"
lst name="defaults"
str name="config" data-config.xml str
lst
requestHandler
3、创建data-config.xml文件,添加如下内容
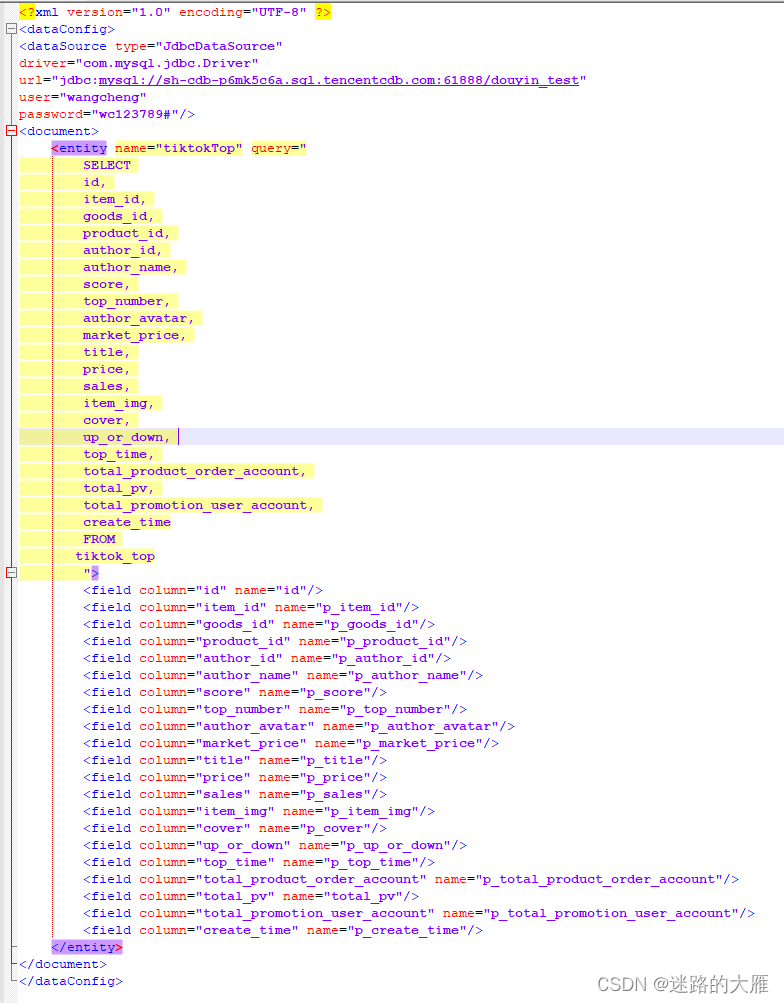
4、在manage-sxhema.xml中添加fieldId
field name="p_item_id" indexed="true" stored="true" type="string"
5、solr定时同步数据库数据
(1)在D:\solr-8.5.1\server\solr-webapp\webapp\WEB-INF下web.xml中添加监听器
org.apache.solr.handler.dataimport.scheduler.ApplicationListener
(2)在data-config.xml中添加sql,写在query的sql后面
deltaImportQuery="SELECT
id,
item_id,
author_avatar,
market_price,
title,
type
FROM
`tiktok_top`"
deltaQuery="select id from `tiktok_top`"
deltaQuery用于查询出所有经过修改的记录的ID,可能是修改操作,添加操作,删除操作产生的
deltaImportQuery则是获取以上的ID,然后把其全部数据获取,根据获取的数据 ,对索引库进行更新操作,可能是删除,添加,修改
(3)在D:\solr-8.5.1\server\solr下新建conf文件夹,在conf里面新建dataimport.properties文件,并写入以下内容
# to sync or not to sync 是否同步执行更新
# 1 - active; anything else - inactive 1 - 开启; 否则不开启
syncEnabled=1
#syncCores=game,resource 需要同步的solr core
syncCores=douyin_db
# solr server name or IP address solr server 名称或IP地址
# [defaults to localhost if empty] 默认为localhost
server=localhost
# solr server port solr server端口
# [defaults to 80 if empty] 默认为80
port=8983
# 定时任务执行增量更新的间隔,不能为0.5这样的数,默认设置为1分钟
interval=1
# application name/context
# [defaults to current ServletContextListener's context (app) name]
webapp=solr
#增量更新对应的访问参数,注意/dataimport?地址不同版本sorl了能地址名不同,具体可登录solr管理后台##查看dataimport的具体访问ULR
params=/dataimport?command=delta-import&clean=false&commit=true&optimize=false&wt=json&indent=true&verbose=false&debug=false
# 重做索引的时间间隔,单位分钟,默认7200,即5天;
# 为空,为0,或者注释掉:表示永不重做索引
reBuildIndexInterval=1
# 重做索引的参数,即全量更新
reBuildIndexParams=/dataimport?command=full-import&clean=true&commit=true&optimize=true&wt=json&indent=true&verbose=false&debug=false
# 重做索引时间间隔的计时开始时间,第一次真正执行的时间=reBuildIndexBeginTime+reBuildIndexInterval*60*1000;
# 两种格式:2012-04-11 03:10:00 或者 03:10:00,后一种会自动补全日期部分为服务启动时的日期
reBuildIndexBeginTime=16:49:00
6、客户端每一个属性意思
q – 查询字符串,必须的。Solr 中用来搜索的查询。有关该语法的完整描述,请参阅 参考资料 中的 “Lucene QueryParser Syntax”。可以通过追加一个分号和已索引且未进行断词的字段的名称来包含排序信息。默认的排序是 score desc,指按记分降序排序。 q=myField:Java AND otherField:developerWorks; date asc此查询搜索指定的两个字段并根据一个日期字段对结果进行排序。
start – 返回第一条记录在完整找到结果中的偏移位置,0开始,一般分页用。
rows – 指定返回结果最多有多少条记录,配合start来实现分页。
sort – 排序,格式:sort=+[,+]… 。示例:(inStock desc, price asc)表示先 “inStock” 降序, 再 “price” 升序,默认是相关性降序。
wt – (writer type)指定输出格式,可以有 xml, json, php, phps, 后面 solr 1.3增加的,要用通知我们,因为默认没有打开。
fq – (filter query)过虑查询,作用:在q查询符合结果中同时是fq查询符合的,
fl- field作为逗号分隔的列表指定文档结果中应返回的 Field 集。默认为 “*”,指所有的字段。“score” 指还应返回记分。例如 *,score
将返回所有字段及得分。用solrj的bean时,得在query中指定 query.set("fl", "*,score");
q.op – 覆盖schema.xml的defaultOperator(有空格时用"AND"还是用"OR"操作逻辑),一般默认指定
df – 默认的查询字段,一般默认指定
qt – (query type)指定那个类型来处理查询请求,一般不用指定,默认是standard。
indent – 返回的结果是否缩进,默认关闭,用 indent=true|on 开启,一般调试json,php,phps,ruby输出才有必要用这个参数。
version – 查询语法的版本,建议不使用它,由服务器指定默认值。
hight:
hl-highlight,h1=true,表示采用高亮。可以用h1.fl=field1,field2 来设定高亮显示的字段。
hl.fl: 用空格或逗号隔开的字段列表。要启用某个字段的highlight功能,就得保证该字段在schema中是stored。如果该参数未被给出,那么就会高 亮默认字段 standard handler会用df参数,dismax字段用qf参数。你可以使用星号去方便的高亮所有字段。如果你使用了通配符,那么要考虑启用 hl.requiredFieldMatch选项。
hl.requireFieldMatch:
如果置为true,除非该字段的查询结果不为空才会被高亮。它的默认值是false,意味 着它可能匹配某个字段却高亮一个不同的字段。如果hl.fl使用了通配符,那么就要启用该参数。尽管如此,如果你的查询是all字段(可能是使用 copy-field 指令),那么还是把它设为false,这样搜索结果能表明哪个字段的查询文本未被找到
hl.usePhraseHighlighter:
如果一个查询中含有短语(引号框起来的)那么会保证一定要完全匹配短语的才会被高亮。
hl.highlightMultiTerm
如果使用通配符和模糊搜索,那么会确保与通配符匹配的term会高亮。默认为false,同时hl.usePhraseHighlighter要为true。
hl.snippets:
这是highlighted片段的最大数。默认值为1,也几乎不会修改。如果某个特定的字段的该值被置为0(如f.allText.hl.snippets=0),这就表明该字段被禁用高亮了。你可能在hl.fl=*时会这么用。
hl.fragsize:
每个snippet返回的最大字符数。默认是100.如果为0,那么该字段不会被fragmented且整个字段的值会被返回。大字段时不会这么做。
hl.mergeContiguous:
如果被置为true,当snippet重叠时会merge起来。
hl.maxAnalyzedChars:
会搜索高亮的最大字符,默认值为51200,如果你想禁用,设为-1
hl.alternateField:
如果没有生成snippet(没有terms 匹配),那么使用另一个字段值作为返回。
hl.maxAlternateFieldLength:
如果hl.alternateField启用,则有时需要制定alternateField的最大字符长度,默认0是即没有限制。所以合理的值是应该为
hl.snippets * hl.fragsize这样返回结果的大小就能保持一致。
hl.formatter:一个提供可替换的formatting算法的扩展点。默认值是simple,这是目前仅有的选项。显然这不够用,你可以看看org.apache.solr.highlight.HtmlFormatter.java 和 solrconfig.xml中highlighting元素是如何配置的。
注意在不论原文中被高亮了什么值的情况下,如预先已存在的em tags,也不会被转义,所以在有时会导致假的高亮。
hl.fragmenter:
这个是solr制 定fragment算法的扩展点。gap是默认值。regex是另一种选项,这种选项指明highlight的边界由一个正则表达式确定。这是一种非典型 的高级选项。为了知道默认设置和fragmenters (and formatters)是如何配置的,可以看看solrconfig.xml中的highlight段。
regex 的fragmenter有如下选项:
hl.regex.pattern:正则表达式的pattern
hl.regex.slop:这是hl.fragsize能变化以适应正则表达式的因子。默认值是0.6,意思是如果hl.fragsize=100那么fragment的大小会从40-160.
1、下载tgz包 地址:https://www.apache.org/dyn/closer.lua/lucene/solr/8.5.2/solr-8.5.2.tgz
2、放到usr/local下面并解压
解压命令:tar -zxvf solr-8.4.1.tar
3、进入bin目录 ./solr start -force















 3939
3939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









