







zk承受节点故障是(n-1)/2
.安装zookeeper集群
1.在s100上面上传zk压缩包
>cp /mnt/hgfs/BigData/第九天/zookeeper-3.4.10.tar.gz /data/
解压
>cd /data
>tar -xzvf zookeeper-3.4.10.tar.gz
2.发送到其他节点
>xsync /data/zookeeper-3.4.10
3.配置环境
[/etc/environment]
ZOOKEEPER_HOME=/data/zookeeper-3.4.10
Path=”$Path:/data/zookeeper-3.4.10/bin”
4.重启
>sudo reboot
5.测试
>zk
6. 修改配置文件
>cd /data/zookeeper-3.4.10/conf
>cp zoo_sample.cfg zoo.cfg
>sudo nano zoo.cfg
dataDir=/home/neworigin/zookeeper
server.1=s100:2888:3888
server.2=s101:2888:3888
server.3=s102:2888:3888
server.X=host:port1:port2 的意思, X 表示当前 host 所运行的服务的 zookeeper 服务的 id(在接下来填写 myid 时需要用到), port1 表示
zookeeper 中的 follower 连接到 leader 的端口号, port2 表示 leadership 时所用的端口号。
7.发送配置文件
>xsync zoo.cfg
8. 创建文件夹
>xcall mkdir -p/home/neworigin/zookeeper
>cd /home/neworigin/zookeeper
[s100]
>echo 1 > myid
[s101]
echo 2 > myid
[s102]
echo 3 > myid
文件内容为 zoo.cfg 中 master 所对应的 server.X。
9. 启动集群(s100、s101、s102一起启动zk,尽量避免启动时间差距大)
>zkServer.sh start
>xcall jps查看进程
------------s100-----------------
3862 QuorumPeerMain
4351 Jps
------------s101-----------------
3650 QuorumPeerMain
3980 Jps
------------s102-----------------
3961 Jps
3791 QuorumPeerMain
------------s103-----------------
3883 Jps
[查看状态 leader or follower]
>zkServer.shstatus
[暂停]
>zkServer.sh stop
~~~~~~~~~~~~~~~
zoo_sample.cfg:

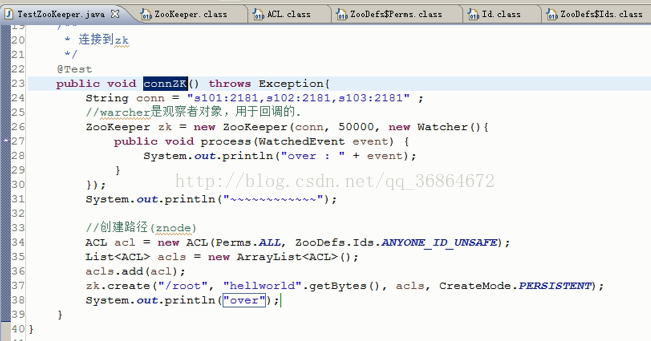
s100连接s101:

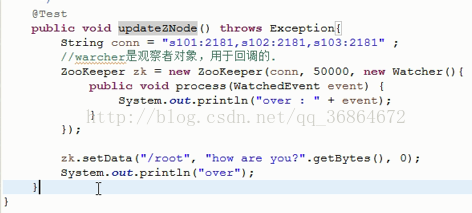
其实不用那么麻烦,上面还可用下述方法:

-----

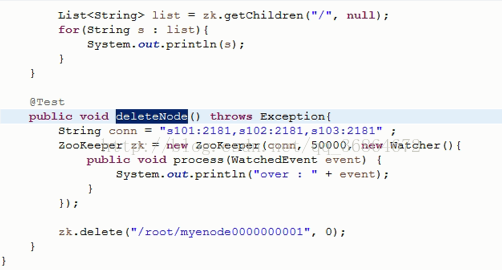
zk.getData();注册观察者,监听zk节点数据的改变。
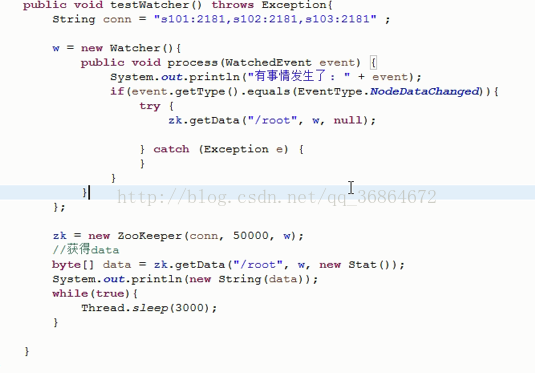

---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
zk遍历所有子节点树:
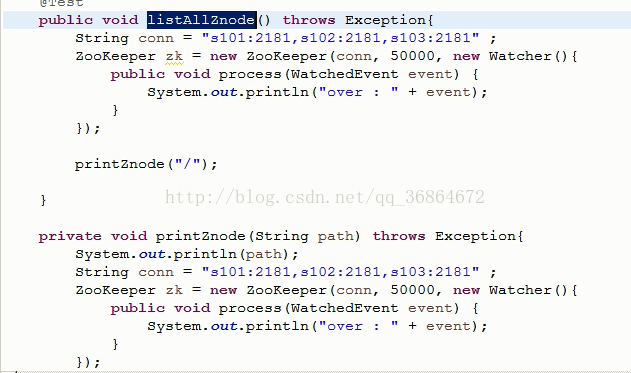
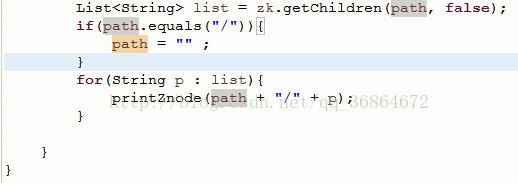
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
ZooKeeper可以运行在多种系统平台上面,表1展示了zk支持的系统平台,以及在该平台上是否支持开发环境或者生产环境。
表1:ZooKeeper支持的运行平台
| 系统 | 开发环境 | 生产环境 |
|---|---|---|
| Linux | 支持 | 支持 |
| Solaris | 支持 | 支持 |
| FreeBSD | 支持 | 支持 |
| Windows | 支持 | 不支持 |
| MacOS | 支持 | 不支持 |
ZooKeeper是用Java编写的,运行在Java环境上,因此,在部署zk的机器上需要安装Java运行环境。为了正常运行zk,我们需要JRE1.6或者以上的版本。
对于集群模式下的ZooKeeper部署,3个ZooKeeper服务进程是建议的最小进程数量,而且不同的服务进程建议部署在不同的物理机器上面,以减少机器宕机带来的风险,以实现ZooKeeper集群的高可用。
ZooKeeper对于机器的硬件配置没有太大的要求。例如,在Yahoo!内部,ZooKeeper部署的机器其配置通常如下:双核处理器,2GB内存,80GB硬盘。
二、下载
可以从 https://zookeeper.apache.org/releases.html 下载ZooKeeper,目前最新的稳定版本为 3.4.8 版本,用户可以自行选择一个速度较快的镜像来下载即可。
三、目录
下载并解压ZooKeeper软件压缩包后,可以看到zk包含以下的文件和目录:
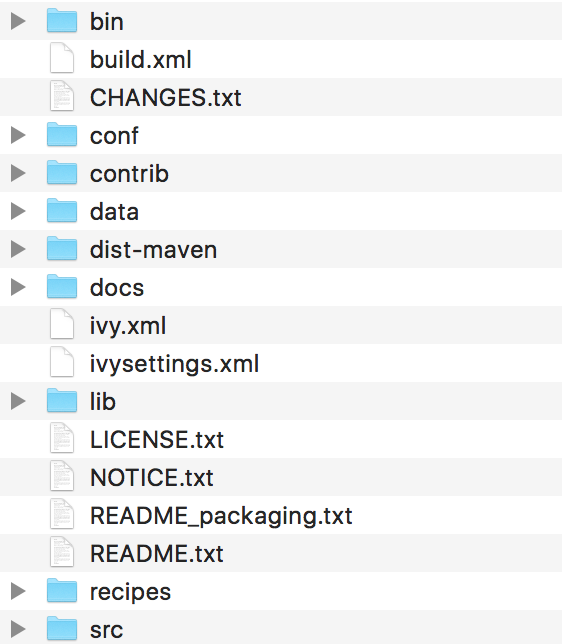
图1:ZooKeeper软件的文件和目录
- bin目录
zk的可执行脚本目录,包括zk服务进程,zk客户端,等脚本。其中,.sh是Linux环境下的脚本,.cmd是Windows环境下的脚本。 - conf目录
配置文件目录。zoo_sample.cfg为样例配置文件,需要修改为自己的名称,一般为zoo.cfg。log4j.properties为日志配置文件。 - lib
zk依赖的包。 - contrib目录
一些用于操作zk的工具包。 - recipes目录
zk某些用法的代码示例
四、单机模式
ZooKeeper的安装包括单机模式安装,以及集群模式安装。
单机模式较简单,是指只部署一个zk进程,客户端直接与该zk进程进行通信。
在开发测试环境下,通过来说没有较多的物理资源,因此我们常使用单机模式。当然在单台物理机上也可以部署集群模式,但这会增加单台物理机的资源消耗。故在开发环境中,我们一般使用单机模式。
但是要注意,生产环境下不可用单机模式,这是由于无论从系统可靠性还是读写性能,单机模式都不能满足生产的需求。
4.1 运行配置
上面提到,conf目录下提供了配置的样例zoo_sample.cfg,要将zk运行起来,需要将其名称修改为zoo.cfg。
打开zoo.cfg,可以看到默认的一些配置。
- tickTime
时长单位为毫秒,为zk使用的基本时间度量单位。例如,1 * tickTime是客户端与zk服务端的心跳时间,2 * tickTime是客户端会话的超时时间。
tickTime的默认值为2000毫秒,更低的tickTime值可以更快地发现超时问题,但也会导致更高的网络流量(心跳消息)和更高的CPU使用率(会话的跟踪处理)。 - clientPort
zk服务进程监听的TCP端口,默认情况下,服务端会监听2181端口。 - dataDir
无默认配置,必须配置,用于配置存储快照文件的目录。如果没有配置dataLogDir,那么事务日志也会存储在此目录。
4.2 启动
在Windows环境下,直接双击zkServer.cmd即可。在Linux环境下,进入bin目录,执行命令
- 1
这个命令使得zk服务进程在后台进行。如果想在前台中运行以便查看服务器进程的输出日志,可以通过以下命令运行:
- 1
执行此命令,可以看到大量详细信息的输出,以便允许查看服务器发生了什么。
使用文本编辑器打开zkServer.cmd或者zkServer.sh文件,可以看到其会调用zkEnv.cmd或者zkEnv.sh脚本。zkEnv脚本的作用是设置zk运行的一些环境变量,例如配置文件的位置和名称等。
4.3 连接
如果是连接同一台主机上的zk进程,那么直接运行bin/目录下的zkCli.cmd(Windows环境下)或者zkCli.sh(Linux环境下),即可连接上zk。
直接执行zkCli.cmd或者zkCli.sh命令默认以主机号 127.0.0.1,端口号 2181 来连接zk,如果要连接不同机器上的zk,可以使用 -server 参数,例如:
- 1
五、集群模式
单机模式的zk进程虽然便于开发与测试,但并不适合在生产环境使用。在生产环境下,我们需要使用集群模式来对zk进行部署。
注意
在集群模式下,建议至少部署3个zk进程,或者部署奇数个zk进程。如果只部署2个zk进程,当其中一个zk进程挂掉后,剩下的一个进程并不能构成一个quorum的大多数。因此,部署2个进程甚至比单机模式更不可靠,因为2个进程其中一个不可用的可能性比一个进程不可用的可能性还大。
5. 1 运行配置
在集群模式下,所有的zk进程可以使用相同的配置文件(是指各个zk进程部署在不同的机器上面),例如如下配置:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- initLimit
ZooKeeper集群模式下包含多个zk进程,其中一个进程为leader,余下的进程为follower。
当follower最初与leader建立连接时,它们之间会传输相当多的数据,尤其是follower的数据落后leader很多。initLimit配置follower与leader之间建立连接后进行同步的最长时间。 - syncLimit
配置follower和leader之间发送消息,请求和应答的最大时间长度。 - tickTime
tickTime则是上述两个超时配置的基本单位,例如对于initLimit,其配置值为5,说明其超时时间为 2000ms * 5 = 10秒。 - server.id=host:port1:port2
其中id为一个数字,表示zk进程的id,这个id也是dataDir目录下myid文件的内容。
host是该zk进程所在的IP地址,port1表示follower和leader交换消息所使用的端口,port2表示选举leader所使用的端口。 - dataDir
其配置的含义跟单机模式下的含义类似,不同的是集群模式下还有一个myid文件。myid文件的内容只有一行,且内容只能为1 - 255之间的数字,这个数字亦即上面介绍server.id中的id,表示zk进程的id。
注意
如果仅为了测试部署集群模式而在同一台机器上部署zk进程,server.id=host:port1:port2配置中的port参数必须不同。但是,为了减少机器宕机的风险,强烈建议在部署集群模式时,将zk进程部署不同的物理机器上面。
5.2 启动
假如我们打算在三台不同的机器 192.168.229.160,192.168.229.161,192.168.229.162上各部署一个zk进程,以构成一个zk集群。
三个zk进程均使用相同的 zoo.cfg 配置:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在三台机器dataDir目录( /home/myname/zookeeper 目录)下,分别生成一个myid文件,其内容分别为1,2,3。然后分别在这三台机器上启动zk进程,这样我们便将zk集群启动了起来。
5.3 连接
可以使用以下命令来连接一个zk集群:
- 1
成功连接后,可以看到如下输出:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
图2:客户端连接zk集群的输出日志
从日志输出可以看到,客户端连接的是192.168.229.162:2181进程(连接上哪台机器的zk进程是随机的),客户端已成功连接上zk集群。
参考资料
- http://zookeeper.apache.org/doc/trunk/zookeeperStarted.html
- http://zookeeper.apache.org/doc/trunk/zookeeperAdmin.html
- 《ZooKeeper分布式系统开发实战》课程,主讲人:玺感
- 《ZooKeeper分布式过程协同技术详解》,Flavio Junqueira等著,谢超等译
- 百度百科有关quorum的解释,http://baike.baidu.com/link?url=pqWrzgH-_VhMLnscR1iRTpPjovfyhxG-8Qs9HxGutiGi5bhnA_lX_pmabLQ-3MiDeigcHRFMYSbFg90RAYVAta
- 《Zookeeper 安装和配置》,http://coolxing.iteye.com/blog/1871009
Zookeeper安装
zookeeper的安装分为三种模式:单机模式、集群模式和伪集群模式。
- 单机模式
首先,从Apache官网下载一个Zookeeper稳定版本,本次教程采用的是zookeeper-3.4.9版本。
http:
//apache.fayea.com/zookeeper/zookeeper-3.4.9/
|
然后解压zookeeper-3.4.9.tar.gz文件到安装目录下:
tar -zxvf zookeepre-3.4.9.tar.gz
zookeeper要求Java运行环境,并且需要jdk版本1.6以上。为了以后的操作方便,可以对zookeeper的环境变量进行配置(该步骤可忽略)。方法如下,在/etc/profile文件中加入以下内容:
#Set Zookeeper Environment
export ZOOKEEPER_HOME=/root/zookeeper-3.4.9
export PATH=$ZOOKEEPER_HOME/bin;$ZOOKEEPER_HOME/conf
Zookeeper服务器包含在单个jar文件中(本环境下为 zookeeper-3.4.9.jar),安装此服务需要用户自己创建一个配置文件。默认配置文件路径为 Zookeeper-3.4.9/conf/目录下,文件名为zoo.cfg。进入conf/目录下可以看到一个zoo_sample.cfg文件,可供参考。通过以下代码在conf目录下创建zoo.cfg文件:
gedit zoo.cfg
在文件中输入以下内容并保存
tickTime=2000dataDir=/home/jxwch/hadoop/data/zookeeper
dataLogDir=/home/jxwch/hadoop/dataLog/zookeeper
clientPort=2181
在这个文件中,各个语句的含义:
tickTime : 服务器与客户端之间交互的基本时间单元(ms)
dataDir : 保存zookeeper数据路径
dataLogDir : 保存zookeeper日志路径,当此配置不存在时默认路径与dataDir一致
clientPort : 客户端访问zookeeper时经过服务器端时的端口号
使用单机模式时需要注意,在这种配置方式下,如果zookeeper服务器出现故障,zookeeper服务将会停止。
- 集群模式
zookeeper最主要的应用场景是集群,下面介绍如何在一个集群上部署一个zookeeper。只要集群上的大多数zookeeper服务启动了,那么总的zookeeper服务便是可用的。另外,最好使用奇数台服务器。如歌zookeeper拥有5台服务器,那么在最多2台服务器出现故障后,整个服务还可以正常使用。
之后的操作和单机模式的安装类似,我们同样需要Java环境,下载最新版的zookeeper并配置相应的环境变量。不同之处在于每台机器上的conf/zoo.cfg配置文件的参数设置不同,用户可以参考下面的配置:

tickTime=2000 initLimit=10 syncLimit=5 dataDir=/home/jxwch/server1/data dataLogDir=/home/jxwch/server1/dataLog clientPort=2181 server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888 maxClientCnxns=60
在这个配置文件中,新出现的语句的含义:
initLimit : 此配置表示允许follower连接并同步到leader的初始化时间,它以tickTime的倍数来表示。当超过设置倍数的tickTime时间,则连接失败。
syncLimit : Leader服务器与follower服务器之间信息同步允许的最大时间间隔,如果超过次间隔,默认follower服务器与leader服务器之间断开链接。
maxClientCnxns : 限制连接到zookeeper服务器客户端的数量
server.id=host:port:port : 表示了不同的zookeeper服务器的自身标识,作为集群的一部分,每一台服务器应该知道其他服务器的信息。用户可以从“server.id=host:port:port” 中读取到相关信息。在服务器的data(dataDir参数所指定的目录)下创建一个文件名为myid的文件,这个文件的内容只有一行,指定的是自身的id值。比如,服务器“1”应该在myid文件中写入“1”。这个id必须在集群环境中服务器标识中是唯一的,且大小在1~255之间。这一样配置中,zoo1代表第一台服务器的IP地址。第一个端口号(port)是从follower连接到leader机器的端口,第二个端口是用来进行leader选举时所用的端口。所以,在集群配置过程中有三个非常重要的端口:clientPort:2181、port:2888、port:3888。
- 伪集群模式
伪集群模式就是在单机环境下模拟集群的Zookeeper服务。
在zookeeper集群配置文件中,clientPort参数用来设置客户端连接zookeeper服务器的端口。server.1=IP1:2888:3888中,IP1指的是组成Zookeeper服务器的IP地址,2888为组成zookeeper服务器之间的通信端口,3888为用来选举leader的端口。由于伪集群模式中,我们使用的是同一台服务器,也就是说,需要在单台机器上运行多个zookeeper实例,所以我们必须要保证多个zookeeper实例的配置文件的client端口不能冲突。
下面简单介绍一下如何在单台机器上建立伪集群模式。首先将zookeeper-3.4.9.tar.gz分别解压到server1,server2,server3目录下:
tar -zxvf zookeeper-
3.4
.
9
.tar.gz /home/jxwch/server1
tar -zxvf zookeeper-
3.4
.
9
.tar.gz /home/jxwch/server2
tar -zxvf zookeeper-
3.4
.
9
.tar.gz /home/jxwch/server3
|
然后在server1/data/目录下创建文件myid文件并写入“1”,同样在server2/data/,目录下创建文件myid并写入“2”,server3进行同样的操作。
下面分别展示在server1/conf/、server2/conf/、server3/conf/目录下的zoo.cfg文件:
server1/conf/zoo.cfg文件
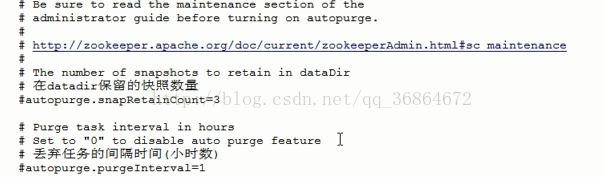
# Server 1 # The number of milliseconds of each tick # 服务器与客户端之间交互的基本时间单元(ms) tickTime=2000 # The number of ticks that the initial # synchronization phase can take # 此配置表示允许follower连接并同步到leader的初始化时间,它以tickTime的倍数来表示。当超过设置倍数的tickTime时间,则连接失败。 initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement # Leader服务器与follower服务器之间信息同步允许的最大时间间隔,如果超过次间隔,默认follower服务器与leader服务器之间断开链接 syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. # 保存zookeeper数据,日志路径 dataDir=/home/jxwch/server1/data dataLogDir=/home/jxwch/server1/dataLog # the port at which the clients will connect # 客户端与zookeeper相互交互的端口 clientPort=2181 server.1= 127.0.0.1:2888:3888 server.2= 127.0.0.1:2889:3889 server.3= 127.0.0.1:2890:3890 #server.A=B:C:D 其中A是一个数字,代表这是第几号服务器;B是服务器的IP地址;C表示服务器与群集中的“领导者”交换信息的端口;当领导者失效后,D表示用来执行选举时服务器相互通信的端口。 # the maximum number of client connections. # increase this if you need to handle more clients # 限制连接到zookeeper服务器客户端的数量 maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1
server2/conf/zoo.cfg文件
# Server 2 # The number of milliseconds of each tick # 服务器与客户端之间交互的基本时间单元(ms) tickTime=2000 # The number of ticks that the initial # synchronization phase can take # zookeeper所能接受的客户端数量 initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement # 服务器与客户端之间请求和应答的时间间隔 syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. # 保存zookeeper数据,日志路径 dataDir=/home/jxwch/server2/data dataLogDir=/home/jxwch/server2/dataLog # the port at which the clients will connect # 客户端与zookeeper相互交互的端口 clientPort=2182 server.1= 127.0.0.1:2888:3888 server.2= 127.0.0.1:2889:3889 server.3= 127.0.0.1:2890:3890 #server.A=B:C:D 其中A是一个数字,代表这是第几号服务器;B是服务器的IP地址;C表示服务器与群集中的“领导者”交换信息的端口;当领导者失效后,D表示用来执行选举时服务器相互通信的端口。 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1
server3/conf/zoo.cfg文件
# Server 3 # The number of milliseconds of each tick # 服务器与客户端之间交互的基本时间单元(ms) tickTime=2000 # The number of ticks that the initial # synchronization phase can take # zookeeper所能接受的客户端数量 initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement # 服务器与客户端之间请求和应答的时间间隔 syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. # 保存zookeeper数据,日志路径 dataDir=/home/jxwch/server3/data dataLogDir=/home/jxwch/server3/dataLog # the port at which the clients will connect # 客户端与zookeeper相互交互的端口 clientPort=2183 server.1= 127.0.0.1:2888:3888 server.2= 127.0.0.1:2889:3889 server.3= 127.0.0.1:2890:3890 #server.A=B:C:D 其中A是一个数字,代表这是第几号服务器;B是服务器的IP地址;C表示服务器与群集中的“领导者”交换信息的端口;当领导者失效后,D表示用来执行选举时服务器相互通信的端口。 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1
从上述三个代码清单可以发现,除了clientPort不同之外,dataDir和dataLogDir也不同。另外,不要忘记dataDir所对应的目录中创建的myid文件来指定对应的zookeeper服务器实例。
Zookeeper伪集群模式运行
当上述伪集群环境安装成功后就可以测试是否安装成功啦,我们可以尝尝鲜:
首先启动server1服务器:
cd server1/bin
bash zkServer.sh start
此时出现以下提示信息,表示启动成功:

打开zookeeper.out文件:
2017-02-23 16:17:46,419 [myid:] - INFO [main:QuorumPeerConfig@124] - Reading configuration from: /home/jxwch/server1/bin/../conf/zoo.cfg 2017-02-23 16:17:46,496 [myid:] - INFO [main:QuorumPeer$QuorumServer@149] - Resolved hostname: 127.0.0.1 to address: /127.0.0.1 2017-02-23 16:17:46,496 [myid:] - INFO [main:QuorumPeer$QuorumServer@149] - Resolved hostname: 127.0.0.1 to address: /127.0.0.1 2017-02-23 16:17:46,497 [myid:] - INFO [main:QuorumPeer$QuorumServer@149] - Resolved hostname: 127.0.0.1 to address: /127.0.0.1 2017-02-23 16:17:46,497 [myid:] - INFO [main:QuorumPeerConfig@352] - Defaulting to majority quorums 2017-02-23 16:17:46,511 [myid:1] - INFO [main:DatadirCleanupManager@78] - autopurge.snapRetainCount set to 3 2017-02-23 16:17:46,511 [myid:1] - INFO [main:DatadirCleanupManager@79] - autopurge.purgeInterval set to 0 2017-02-23 16:17:46,511 [myid:1] - INFO [main:DatadirCleanupManager@101] - Purge task is not scheduled. 2017-02-23 16:17:46,525 [myid:1] - INFO [main:QuorumPeerMain@127] - Starting quorum peer 2017-02-23 16:17:46,631 [myid:1] - INFO [main:NIOServerCnxnFactory@89] - binding to port 0.0.0.0/0.0.0.0:2181 2017-02-23 16:17:46,664 [myid:1] - INFO [main:QuorumPeer@1019] - tickTime set to 2000 2017-02-23 16:17:46,664 [myid:1] - INFO [main:QuorumPeer@1039] - minSessionTimeout set to -1 2017-02-23 16:17:46,664 [myid:1] - INFO [main:QuorumPeer@1050] - maxSessionTimeout set to -1 2017-02-23 16:17:46,665 [myid:1] - INFO [main:QuorumPeer@1065] - initLimit set to 10 2017-02-23 16:17:46,771 [myid:1] - INFO [main:FileSnap@83] - Reading snapshot /home/jxwch/server1/data/version-2/snapshot.400000015 2017-02-23 16:17:46,897 [myid:1] - INFO [ListenerThread:QuorumCnxManager$Listener@534] - My election bind port: /127.0.0.1:3888 2017-02-23 16:17:46,913 [myid:1] - INFO [QuorumPeer[myid=1]/0:0:0:0:0:0:0:0:2181:QuorumPeer@774] - LOOKING 2017-02-23 16:17:46,915 [myid:1] - INFO [QuorumPeer[myid=1]/0:0:0:0:0:0:0:0:2181:FastLeaderElection@818] - New election. My id = 1, proposed zxid=0x500000026 2017-02-23 16:17:46,922 [myid:1] - INFO [WorkerReceiver[myid=1]:FastLeaderElection@600] - Notification: 1 (message format version), 1 (n.leader), 0x500000026 (n.zxid), 0x1 (n.round), LOOKING (n.state), 1 (n.sid), 0x5 (n.peerEpoch) LOOKING (my state) 2017-02-23 16:17:46,940 [myid:1] - WARN [WorkerSender[myid=1]:QuorumCnxManager@400] - Cannot open channel to 2 at election address /127.0.0.1:3889 java.net.ConnectException: 拒绝连接 at java.net.PlainSocketImpl.socketConnect(Native Method) at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:339) at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:200) at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:182) at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392) at java.net.Socket.connect(Socket.java:579) at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectOne(QuorumCnxManager.java:381) at org.apache.zookeeper.server.quorum.QuorumCnxManager.toSend(QuorumCnxManager.java:354) at org.apache.zookeeper.server.quorum.FastLeaderElection$Messenger$WorkerSender.process(FastLeaderElection.java:452) at org.apache.zookeeper.server.quorum.FastLeaderElection$Messenger$WorkerSender.run(FastLeaderElection.java:433) at java.lang.Thread.run(Thread.java:745) 2017-02-23 16:17:46,943 [myid:1] - INFO [WorkerSender[myid=1]:QuorumPeer$QuorumServer@149] - Resolved hostname: 127.0.0.1 to address: /127.0.0.1 2017-02-23 16:17:46,944 [myid:1] - WARN [WorkerSender[myid=1]:QuorumCnxManager@400] - Cannot open channel to 3 at election address /127.0.0.1:3890 java.net.ConnectException: 拒绝连接 at java.net.PlainSocketImpl.socketConnect(Native Method) at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:339) at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:200) at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:182) at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392) at java.net.Socket.connect(Socket.java:579) at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectOne(QuorumCnxManager.java:381) at org.apache.zookeeper.server.quorum.QuorumCnxManager.toSend(QuorumCnxManager.java:354) at org.apache.zookeeper.server.quorum.FastLeaderElection$Messenger$WorkerSender.process(FastLeaderElection.java:452) at org.apache.zookeeper.server.quorum.FastLeaderElection$Messenger$WorkerSender.run(FastLeaderElection.java:433) at java.lang.Thread.run(Thread.java:745) 2017-02-23 16:17:46,944 [myid:1] - INFO [WorkerSender[myid=1]:QuorumPeer$QuorumServer@149] - Resolved hostname: 127.0.0.1 to address: /127.0.0.1
产生上述两条Waring信息是因为zookeeper服务的每个实例都拥有全局的配置信息,他们在启动的时候需要随时随地的进行leader选举,此时server1就需要和其他两个zookeeper实例进行通信,但是,另外两个zookeeper实例还没有启动起来,因此将会产生上述所示的提示信息。当我们用同样的方式启动server2和server3后就不会再有这样的警告信息了。
当三台服务器均成功启动后切换至server1/bin/目录下执行以下命令:
bash zkServer.sh status
终端出现以下提示信息:

说明server1服务器此时处于follower模式,同样切换至server2/bin目录下执行相同的命令,返回如下结果:

说明server2被选举为leader。
参考资料















 673
673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









