







目录
前言
本题来源于全国职业技能大赛之大数据技术赛项工业数据处理赛题 - 离线数据处理 - 指标计算
注:由于个人设备问题,代码执行结果以及最后数据显示结果将不会给出。
题目:
提示:以下是本篇文章正文内容,下面案例可供参考(使用Scala语言编写)
一、读题分析
涉及组件:Scala,Spark,Hive
涉及知识点:
- Hive中联合主键去重
- 剔除脏数据
二、处理过程
-- 代码仅供参考 --
package A.offlineDataProcessing.shtd_industry.task3_indicatorCalculation
import org.apache.spark.sql.SparkSession
object answer_No3 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("MachineAvgProduceTime").master("spark://hadoop100:7077")
.enableHiveSupport()
.getOrCreate()
val df = spark.read.table("dwd.fact_produce_record").filter("ProduceCodeEndTime != '1900-01-01 00:00:00'")
df.createOrReplaceTempView("tempView")
// spark.sql("select * from tempView limit 5").show()
val resultDF = spark.sql(
"""
|SELECT distinct
| ProduceRecordID AS produce_record_id,
| ProduceMachineID AS produce_machine_id,
| unix_timestamp(ProduceCodeEndTime) - unix_timestamp(ProduceCodeStartTime) AS producetime,
| AVG(unix_timestamp(ProduceCodeEndTime) - unix_timestamp(ProduceCodeStartTime))
| OVER (PARTITION BY ProduceMachineID) AS produce_per_avgtime
|FROM tempView
|
|""".stripMargin)
resultDF.show()
resultDF.write.mode("overwrite").saveAsTable("dws.machine_produce_per_avgtime")
// 在Linux的命令行中根据设备id倒序排序查询前3条数据
// select * from machine_produce_per_avgtime order by produce_machine_id desc limit 3;
}
}
-- 代码仅供参考 --
三、重难点分析
Hive中联合主键去重(感觉我写的有点问题)
剔除脏数据(经常使用filter,这里不做赘述)
本期为指标计算第3篇,后续应该还会出5篇。
总结
这是一个关于使用Scala和Spark统计设备生产一个产品的平均耗时,并将结果存储在clickhouse数据库中,然后在Linux命令行工具中查询前三条设备id倒序排列的数据的问题。下面是具体的要求和表结构:
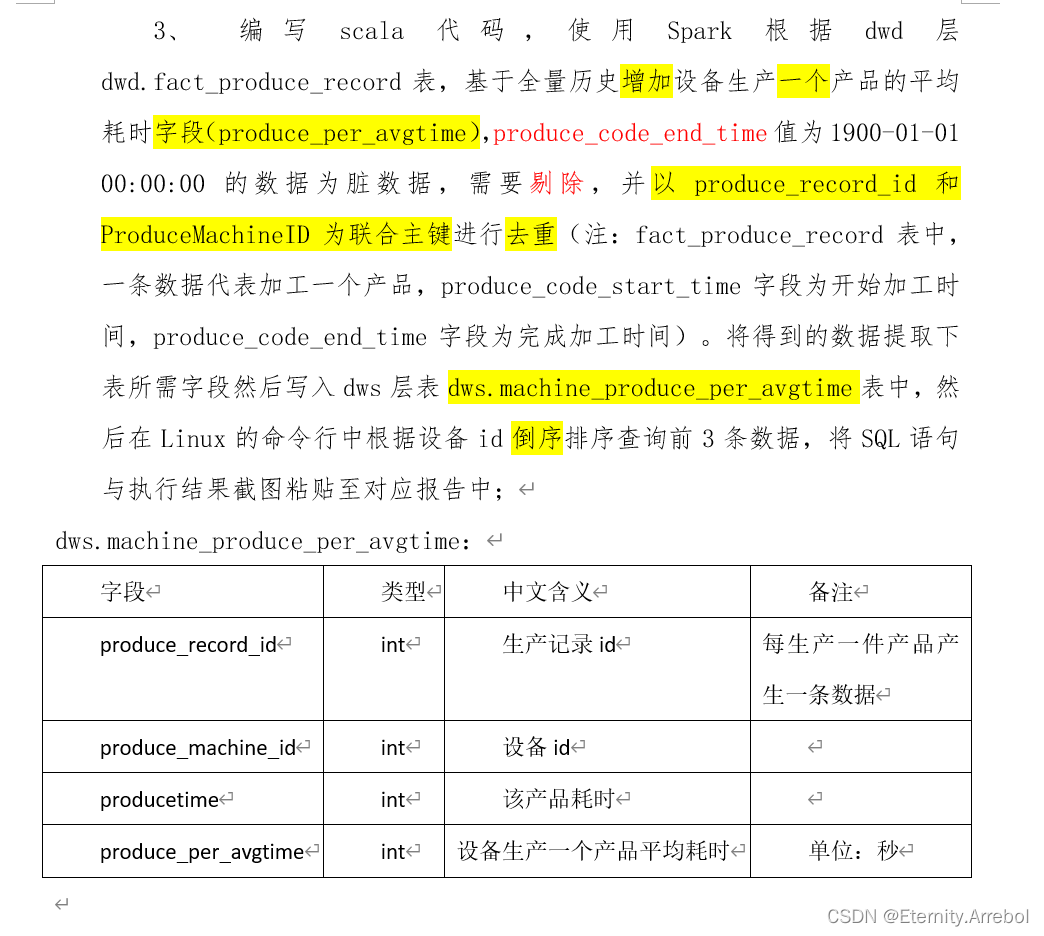
- 在dwd层fact_produce_record表中,基于全量历史增加设备,计算生产一个产品的平均时间字段(produce_per_avgtime),其中produce_code_end_time为1900-01-01 00:00:00的数据为脏数据,需要剔除。每生产一件产品产生一条数据,produce_code_start_time字段为开始加工时间,produce_code_end_time字段为完成加工时间。
- 将得到的数据提取下表所需字段,然后写入dws层表machine_produce_per_avgtime中,表结构包含produce_record_id(生产记录id)、produce_machine_id(设备id)、producetime(该产品耗时,单位为秒)和produce_per_avgtime(设备生产一个产品平均耗时,单位为秒)字段。
- 通过Linux的命令行工具查询出前3条设备id倒序排列的设备生产一个产品平均耗时数据,将SQL语句和执行结果截图粘贴到报告中。
注意:这个题目需要掌握Spark编程、clickhouse数据库以及Linux命令行工具的使用。
请关注我的大数据技术专栏大数据技术 作者: Eternity.Arrebol
请关注我获取更多与大数据相关的文章Eternity.Arrebol的博客
















 1411
1411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











