






sklearn官方文档的中文翻译
https://scikit-learn.org/stable/modules/linear_model.html#ordinary-least-squares
IDE使用jupyter lab
1.1 线性模型
本章讲述一系列回归方法,这些方法假定因变量是特征(自变量)的线性组合,因此称他们为线性模型。
将待预测的因变量记作
y
^
\hat{y}
y^, 线性模型的数学描述如下:
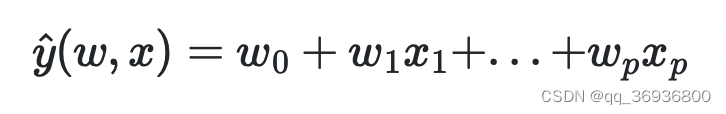
之后,我们把公式中的系数向量
w
=
(
w
1
,
.
.
.
,
w
p
)
w=(w_1,...,w_p)
w=(w1,...,wp)记作coef_,把截距
w
0
w_0
w0记作intercept_
1.1.1 普通最小二乘 OLS,Ordinary Least Squares
sklearn的linear_model模块中的LinearRegression()遵循最小二乘法进行拟合。拟合是指求出一个表现最好的模型的系数。
普通最小二乘法是衡量“表现最好”的一种方法:当由这组系数构成的这个线性模型的预测值
y
^
\hat{y}
y^与数据中已有的因变量
y
y
y之间差的平方和最小,则认为该模型表现最好。数学描述如下:
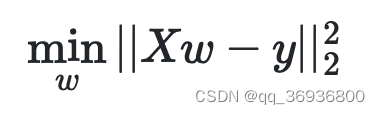
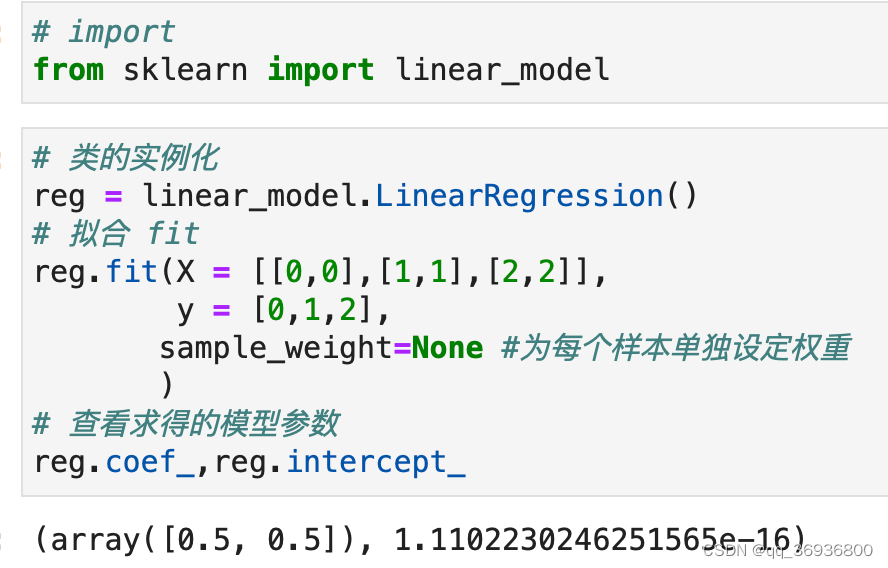
使用sklearn中的线性回归模型时:
- 先实例化
- 然后用fit方法放入自变量矩阵X和因变量y,模型会根据最小二乘法进行拟合
- 拟合后得到的系数和截距存储在模型的coef_和intercept_属性中
要注意的是:普通最小二乘法依赖于特征之间的独立性,如果自变量间有多重共线性(即几个自变量彼此高度相关),数据中因变量y值的随机误差的影响会很大。
1)非负最小二乘法
如果要拟合的模型的系数是非负的数量,比如频率、商品价格等,那么在实例化时可以设定LinearRegression(positive=True),将系数coef_限制为非负的(即可以是0)。
2)最小二乘法的复杂度
最小二乘法的计算是利用了特征矩阵X的奇异值进行降维,如果矩阵X的维度是(n_样本行数,m_特征列数),假定
n
样
本
行
数
>
m
特
征
列
数
n_{样本行数}>m_{特征列数}
n样本行数>m特征列数,那么该方法复杂度为
O
(
n
∗
m
2
)
O(n*m^2)
O(n∗m2)














 285
285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









