







cv文档出处
https://baijiahao.baidu.com/s?id=1708807538121555902&wfr=spider&for=pc
一、合适的线程模型
IO多路复用
a、为什么使用IO多路复用?
b、什么是IO多路复用?
c、redis是如何使用的?
a、因为redis是跑在单线程环境下(只针对客户端而言),所有操作都是顺序进行的,但是IO操作本身是非常耗时的,如果恰好有一个操作阻塞很久后面的命令就都无法正常执行,IO多路复用就是为了解决这个问题.
b、IO主要分为磁盘IO和网络IO,以网络IO为例
https://note.youdao.com/s/1ta3weca
阻塞IO-
客户端发起一个socket请求给服务端,服务端的serverSocket就创建一个socket和一个线程去和客户端进行通信,如果此时有成千上万个客户端发起请求,可想而知服务端根本无法创建着这么多socket和线程

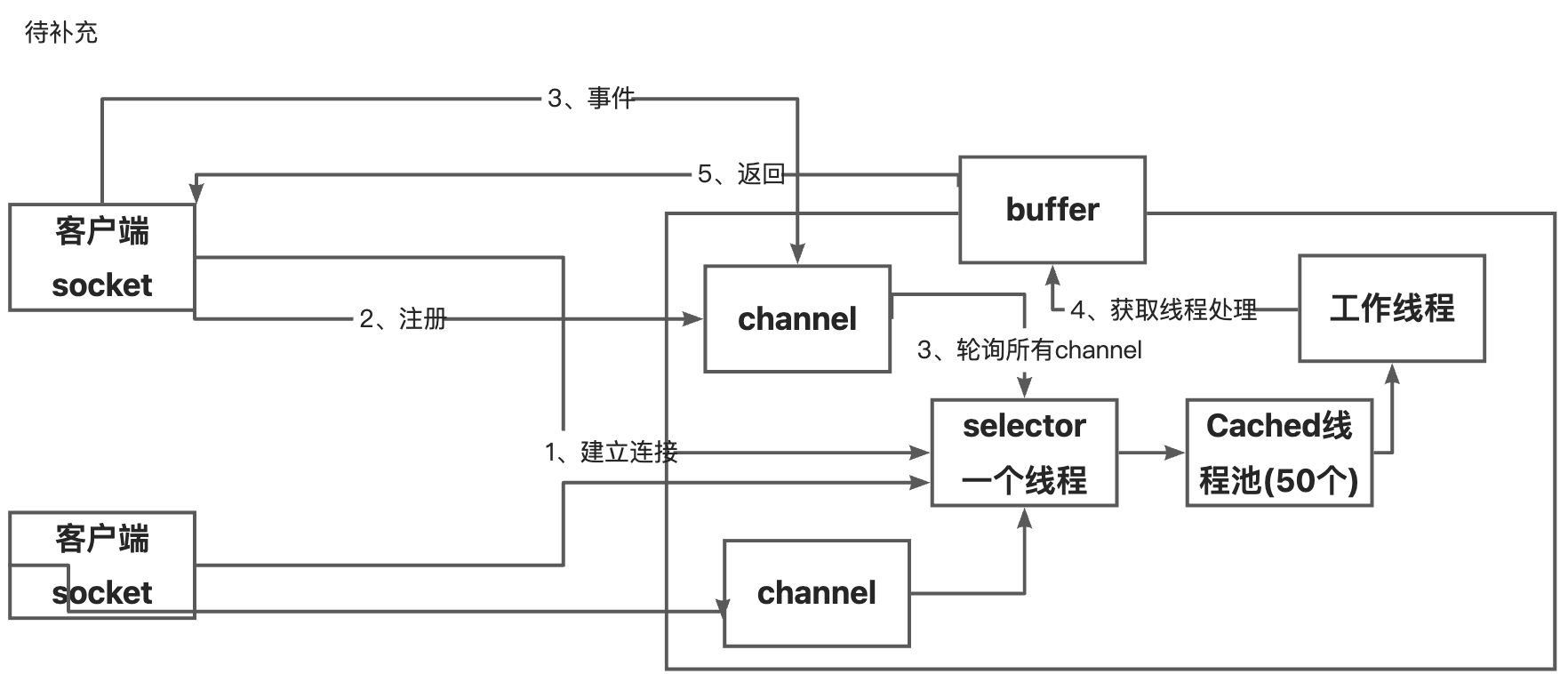
非阻塞IO-
非阻塞体现在所有的客户端请求过来服务端并不会创建一个线程去处理,而是去channel上进行注册,之后selector线程回去轮训所有的channel(这里体现了非阻塞),如果该channel上有事件那么就会去Cached线程池获取一个工作线程去处理(这里读取数据返回都是阻塞的),
IO复用模型
**为了解决非阻塞IO线程轮询造成的CPU占用高的问题,所以出现了IO复用模型.**IO复用中,使用其他线程去监听多个线程产生的事件,以提高效率;Linux中提供了select、poll、epoll来实现一个线程监听多个IO端口事件,而epoll方法是通过事件驱动的(那个流上有事件就通知我们),并且通过mmap减少复制开销
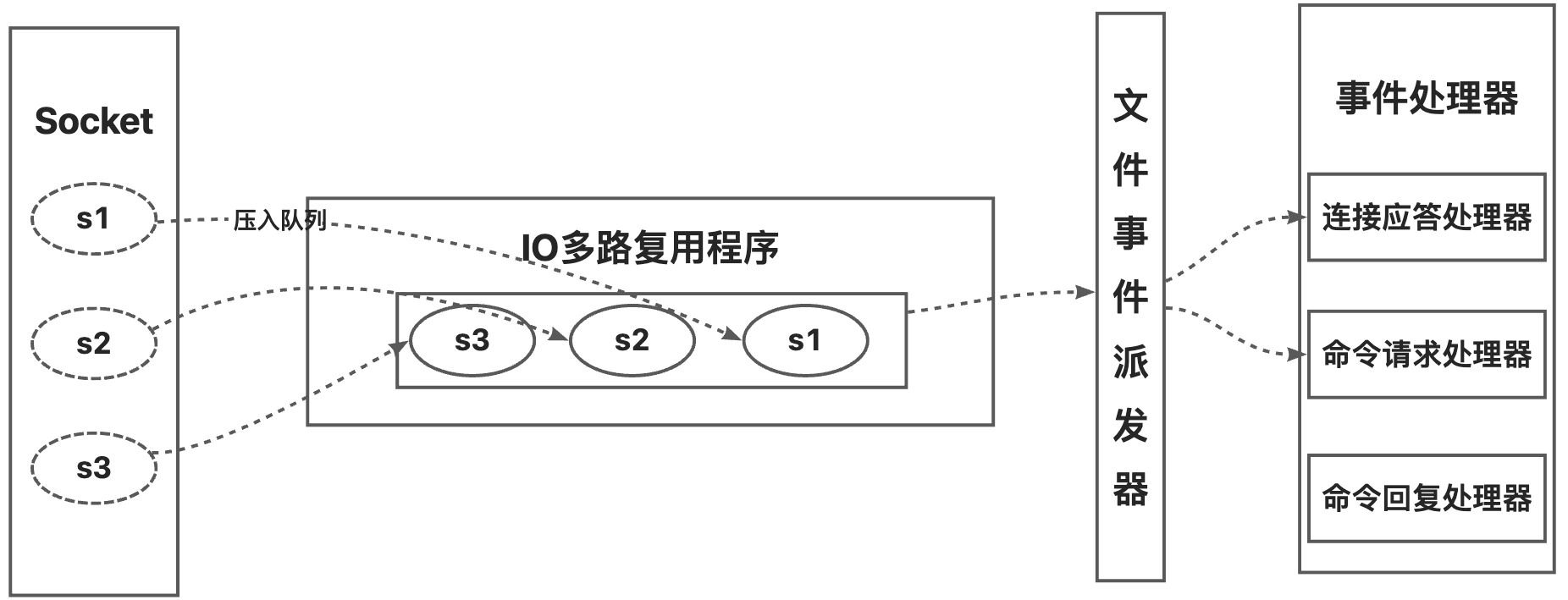
c、因为以上原因,redis基于reactor模式开发了自己的网络事件模型:称之为文件事件处理器,包括Socket、IO多路复用程序、文件事件派发器、事件处理器四个部分组成.
单线程
因为redis的瓶颈不在于cpu,而在于内存,单线程足以满足需求;也正是因为单线程没有额外的线程上下文切换负担;也不存在锁的竞争
二、基于内存实现
完全基于内存操作,避免了耗时的IO操作
三、高效的数据结构
为了提高效率redis拥有5种数据类型,每种数据类型底层对应了一至多种数据结构:
String对象-SDS
在O(1)的时间复杂度获取字符串长度;
内存重新分配:使用空间预分配和惰性空间释放来提升字符串长度变化时内存的分配效率;
List对象-双端链表和压缩列表
双端列表可以快速的获取前驱后继节点;
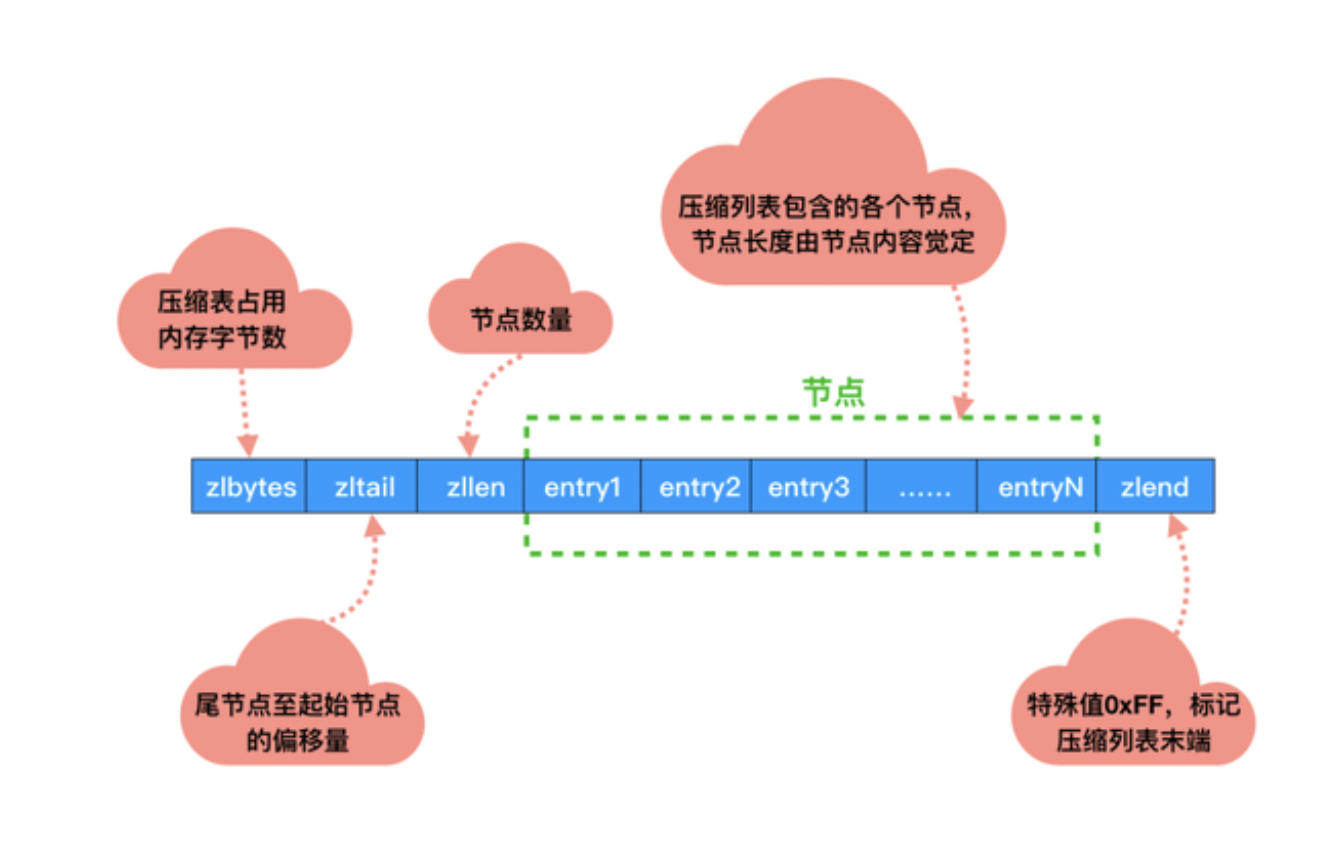
压缩列表是对内存的一种节约使用,开辟的一整块内存,遍历起来也会更快
Hash对象-压缩链表和字典
set对象-字典
zset对象-压缩链表和跳跃表















 684
684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









