







1. JavaScript的定义
JavaScript,常被简称为JS,是一种轻量级的、解释或即时编译的编程语言。它是一种主要在用户浏览器上运行的脚本语言,是Web开发中不可或缺的一部分。JavaScript的设计哲学是“弱类型”和“动态类型”,这意味着变量的类型是在运行时决定的,而不是在编译时。
JavaScript最初是为了在HTML网页中添加动态交互性而创建的。它可以用来控制网页的行为,例如响应用户输入、操作HTML文档、处理数据以及与服务器进行通信。JavaScript的广泛应用使得它不仅限于浏览器环境,还可以在服务器端(如Node.js)、移动应用(如React Native)和桌面应用(如Electron)中使用。
JavaScript的核心功能包括:
- 变量和数据类型:可以存储和操作各种数据,如数字、字符串、布尔值、数组、对象等。
- 控制结构:如条件语句(if…else)、循环(for, while)等,用于控制程序的流程。
- 函数:用于封装可重用的代码块,可以接受参数并返回结果。
- 对象和原型:支持面向对象编程(OOP),通过对象和原型链实现继承和多态。
- 事件处理:通过事件监听器响应用户或系统的操作。
- DOM操作:通过DOM(Document Object Model)可以访问和操作HTML文档的结构和内容。
- AJAX:异步JavaScript和XML技术,允许在不重新加载整个页面的情况下与服务器交互。
- 模块和库:可以使用模块化编程和第三方库来扩展功能和简化开发。
2. 浏览器环境
浏览器引擎主要由以下几个核心组件构成:
- 解析引擎(Parser):负责解析HTML和CSS代码,将它们转化为可以被渲染引擎处理的数据结构。
- 渲染引擎(Rendering Engine):也称为布局引擎,它负责构建文档对象模型(DOM)树和样式对象模型(CSSOM)树,并将它们合并成渲染树(Render Tree)。渲染树决定了页面的视觉布局。
- JavaScript引擎:专门负责执行网页中的JavaScript代码。现代浏览器的JavaScript引擎通常会进行即时编译(JIT),以提高执行效率。
- 网络模块:负责处理HTTP、HTTPS等网络请求,下载网页资源。
- 存储模块:管理本地存储,如cookies、localStorage、sessionStorage等。
- 图形加速与渲染优化:利用GPU加速和优化技术提高渲染性能。
3. JavaScript执行过程
JavaScript代码的执行过程通常包括以下几个关键步骤:
3.1. 解析阶段
JavaScript引擎首先对源代码进行词法分析和语法分析,将代码转换成抽象语法树(AST)。在这个阶段,引擎会检查语法错误,并构建代码的内部表示结构。
3.2. 编译阶段
编译阶段包括代码优化和生成字节码或机器代码。在某些JavaScript引擎中,这一阶段还可能包括即时编译(JIT),即将热点代码编译成本机代码以提高执行效率。
3.3. 执行阶段
执行程序需要有执行环境,JavaScript引擎创建执行上下文(JavaScript代码运行的环境),并执行JavaScript代码。执行上下文包括变量环境、词法环境和作用域链等。
3.4. 事件循环
JavaScript是单线程的,但它通过事件循环机制来处理异步操作。事件循环监控任务队列,当执行栈为空时,它会取出任务队列中的任务执行。这些任务可能是宏任务或微任务,微任务在当前执行栈清空后立即执行,而宏任务则等待执行栈清空后按顺序执行。
3.5. 垃圾收集
JavaScript引擎还负责管理内存,通过垃圾收集机制回收不再使用的内存空间,以避免内存泄漏。
4. 变量提升
变量提升是JavaScript中的一个特性,它指的是在代码执行之前,变量和函数声明被移至其所在作用域的顶部的过程。这意味着即使在变量或函数声明之前尝试访问它们,也不会导致引用错误,它们会被赋予undefined值(对于变量)或作为函数可用(对于函数声明)。
4.1. 变量声明提升时,不会提升值;函数声明提升时,函数体也会提升
console.log(a); //undefined
var a=1;
console.log(fn); //ƒ fn(){}
function fn(){}
console.log(fn1); //undefined
var fn1 = function (){}
提升后:
var a;
function fn(){}
var fn1;
console.log(a); //undefined
a=1;
console.log(fn); //ƒ fn(){}
console.log(fn1); //undefined
fn1 = function (){}
4.2. 变量名冲突时,函数声明优先(覆盖变量声明)
console.log(fn); //ƒ fn(){}
var fn=1;
function fn(){}
console.log(fn); //1
提升后:
function fn(){}
console.log(fn); //ƒ fn(){}
fn=1;
console.log(fn); //1
4.3. 使用let,const
let,const关键字声明变量时,具有块级作用域,不会声明提升,只能在声明后调用变量
5. 事件循环
JavaScript事件循环的概念
JavaScript的事件循环(Event Loop)是其处理异步操作的核心机制。由于JavaScript是单线程的,事件循环允许它在不中断执行的情况下处理多个任务,包括用户交互、网络请求、定时器等。事件循环的基本流程包括执行同步任务、处理微任务队列、执行宏任务队列,以及在必要时进行UI渲染。
事件循环的工作原理
- 执行栈(Call Stack):同步代码按顺序执行,形成一个执行栈。当执行栈为空时,事件循环开始。
- 微任务队列(Microtask Queue):事件循环首先执行微任务队列中的任务,这些任务包括
Promise的回调函数、Object.observer回调等。 - 宏任务队列(Macrotask Queue):微任务执行完毕后,事件循环执行宏任务队列中的任务,如
setTimeout、setInterval、I/O操作等。 - UI渲染:在宏任务执行后,浏览器可能会进行UI渲染。
- 下一轮事件循环:完成上述步骤后,事件循环回到第一步,继续处理新的同步任务和异步任务。
事件循环的执行顺序
- 事件循环在每次迭代中优先处理微任务队列,然后处理宏任务队列。
- 在同一轮任务队列中,同一个微任务产生的微任务会放在这一轮微任务的后面,产生的宏任务会放在这一轮的宏任务后面。
- 在同一轮任务队列中,同一个宏任务产生的微任务会马上执行,产生的宏任务会放在这一轮的宏任务后面。
6. 垃圾回收
JavaScript的垃圾回收机制是自动管理内存的过程,它负责识别不再被使用的内存空间,并将其释放以供重新使用。垃圾回收器会周期性地运行,以清理不再可达的对象,这些对象是指没有任何活跃引用指向它们的对象。
标记-清除算法
标记-清除算法是现代浏览器普遍采用的垃圾回收算法。它分为两个阶段:
- 标记阶段:垃圾回收器从根对象(如全局变量和当前执行栈中的变量)开始,递归地标记所有可达的对象。
- 清除阶段:垃圾回收器清除所有未被标记的对象,这些对象被认为是垃圾,并释放它们占用的内存空间。
引用计数算法
虽然引用计数算法在早期的JavaScript实现中被使用,但由于它难以处理循环引用的问题,现代浏览器已不再使用这种算法。循环引用发生在两个或多个对象互相持有对方的引用,导致它们的引用计数永远不会降至零,即使它们实际上不再被使用。
分代收集
为了提高垃圾回收效率,许多JavaScript引擎采用了分代收集机制,将内存分为新生代和老生代。新生代存放生命周期较短的对象,而老生代存放生命周期较长的对象。垃圾回收器会根据不同代的特点采用不同的算法,新生代通常使用复制算法,而老生代使用标记-清除或标记-整理算法。
7. 数字类型
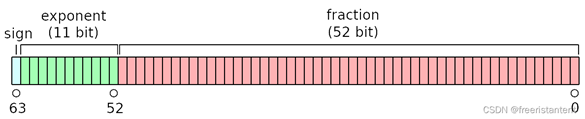
在JavaScript中,所有数字都是以64位双精度浮点数的形式存储的,这符合IEEE 754标准。这种表示方法包括一个符号位、11位指数位和52位尾数位。
7.1 存储结构
IEEE-754双精度浮点数(double floating-point)存储为64bit,由**符号位(s)、有偏指数(e)、小数部分(f)**组成:
7.2 类型划分
11位的指数部分可存储00000000000 ~ 11111111111(十进制范围为0 ~ 2047),取值可分为3种情况:
1. 11位指数不为00000000000和11111111111,即在00000000001 ~ 11111111110(1 ~ 2046)范围,这被称为规格化。
2. 指数值为00000000000(0),这被称为非规格化
3. 指数值为11111111111(2047),这是特殊值,有两种情况:
- 当52位小数部分f全为0时,
若符号位是0,则表示+Infinity(正无穷),0 11111111111 0000000000000000000000000000000000000000000000000000
若符号位是1,则表示-Infinity(负无穷),1 11111111111 0000000000000000000000000000000000000000000000000000 - 当52位小数部分f不全为0时,表示NaN(Not a Number)
0 11111111111 1010000000000000000000000000000000000000000001000000
7.3 规格化
规格化下,浮点数的形式可表示为(小数点前的1不存,默认是有个1):

其中:
- s为0或1,0表示正数,1表示负数,对应1bit的符号位
- f为52位有效位,其中的每一位b是0或1,对应52bit的小数部分(不足52位补0)
- c是超出52位的部分(如果有的话,需要舍入(精度会丢失),规则下述)
- e为十进制数值,其11位的二进制数值对应11bit的指数部分
- 1023为移码,移码值为2^{n-1} − 1,这里的n表示指数位数,对于64bit的双精度存储,n是11 (即2^10 – 1 = 1023)
7.4 移码
移码的目的是用于简化浮点数的阶码(有偏指数)运算。
个人理解,原本11位指数在二进制中只能表达0 ~ 2047的正数,但是实际运算中肯定还有负指数(即小数),如果为了区分正负指数再搞个指数符号位就太麻烦了,所以为了简化表达以及后续的计算,人为规定了(即IEEE-754标准)一个偏移值,让一部分数值表达负数,(0-1023) ~ (2047-1023),差不多一半表达负值一半表达正值。
在IEEE 754标准中,双精度浮点数的阶码偏移量是1023,这意味着实际存储的阶码值是指数值加上1023。

上面这个例子中,小数部分不存在舍入的问题(位数小于52位),那么如果小数超出了52位,如何处理呢?有以下几种情况:
- 第53位是0,无需处理
- 第53位是1且53位之后全是0:
- 若第52位是0,无需处理;
- 若第52位是1,那么向上舍入
- 第53位是1,且之后不全是0:那么向上舍入
注意,所以js在浮点数的计算上因为舍弃精度会导致误差
7.5 非规格化
非规格化可用以下形式表示(小数点前面是0):
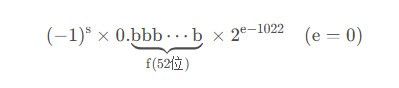
我们一般不会主动操作非规格化数字,它们是在运算中隐式产生的。
一般用于表达0到1之间非常小的数字,例如,当需要处理接近于0的物理量(如极小的力或电荷)时,非规格化数字可以提供更精细的数值表示。
7.6 整数范围
当 e - 1023 = 52,即e = 1075,小数f最大(52位全为1)时,能表示出最大安全正整数,
0 00000110100 1111111111111111111111111111111111111111111111111111
因为规格化数字小数点前还有一个1,所以最大的数是53个1,即253,但是再加1会精度溢出导致(253 == 2^53 + 1),所以2^53实际也不安全(无法和其他数字区分),
最终最大安全正整数为(2^53 - 1),最小安全负整数为-(2^53 - 1)
Number.MAX_SAFE_INTEGER == 2**53 - 1















 2808
2808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









