







 本文探讨了K近邻算法(KNN)中K值的选择及其对模型性能的影响,并介绍了如何使用交叉验证来找到最佳的K值,以防止过拟合并提高模型泛化能力。
本文探讨了K近邻算法(KNN)中K值的选择及其对模型性能的影响,并介绍了如何使用交叉验证来找到最佳的K值,以防止过拟合并提高模型泛化能力。
问题引出
之前我们使用K近邻算法尝试寻找用户年龄与预估薪资之间的某种相关性,以及他们是否有购买SUV的决定。主要代码如下:
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors=5, metric='minkowski', p=2)
classifier.fit(X_train, y_train)
现在有一个问题,上面的n_neighbors(k值)为什么是5,其他值可不可以?效果会怎么样?如何知道哪个k值的效果相对较好?这就需要用到交叉验证。
交叉验证有什么用,为什么要用它?
关于它有什么用,经过浏览相关网页获得了以下两点总结:
- 在数据集很小的时候防止过拟合。
- 找到合适的模型参数。
看到这里,不知道你对为什么要用交叉验证有没有明白一点点,说白了就是我们手头上的数据量太小,直接对数据量小的数据集进行训练集和测试集的划分,最后的效果即使很好,也不能确定后面部署上线的结果会一样好,因为模型效果表现仅仅局限于我们那少得可怜的数据集上。
假如我们有很多很多的数据,不要问多少,反正就是很多的那种,我个人觉得我们可以直接暴力的通过下面方式来找到KNN的最优k值:
import matplotlib.pyplot as plt
k_range = range(1, 51)
k_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
score = knn.score(X_test, y_test)
k_scores.append(score)
plt.plot(k_range, k_scores)
plt.xlabel('Vlaue of K for KNN')
plt.ylabel('Cross-Validated Accuracy')
plt.show()
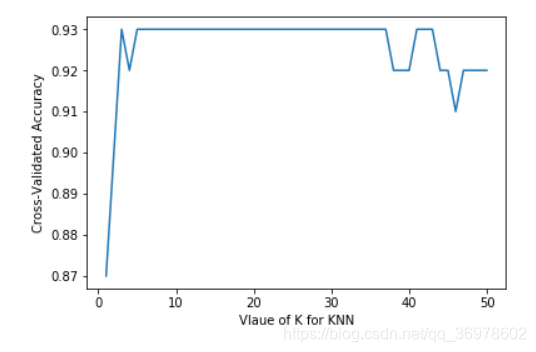
这样,在我们有大量数据前提下,我们就可以大致确定哪个k值最优了,或者直接做深度学习。
但是,现实中,我们往往很难收集到大量的数据,这种情况下,我们只好从我们那少得可怜的数据集下手了,也就是说,我们要在数据量少的情况下,尽量通过交叉验证来找到一组好的模型参数,让其在看到未知参数的情况也一样好,这样也就防止了模型训练的效果好,看到未知数据不好的过拟合情况。
如何交叉验证?
简单来说就是对数据集进行重新划分,不再像之前那样只是简单将数据集划分训练集和测试集。关于如何重新划分数据集,网上主要有两种方式。
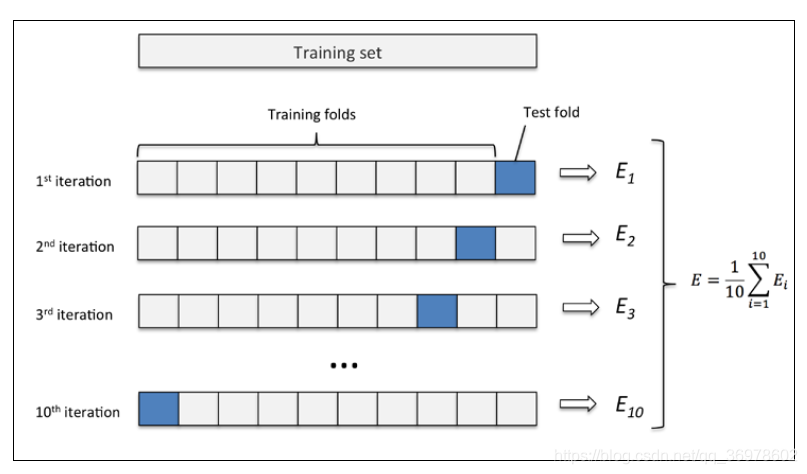
1、先将数据集划分为训练集和测试集,再对训练集划分为子训练集和子测试集,如下图:
2、直接将数据集划分如下所示:
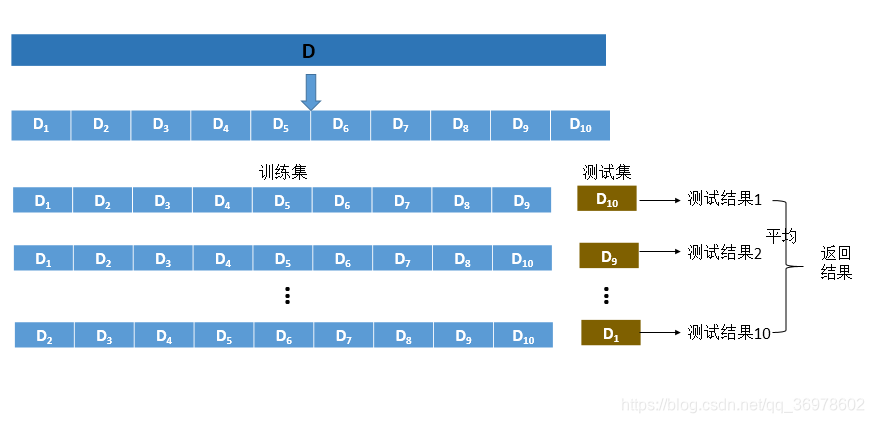
关于上面的两个方法,绝大多数都是第一种方式,我是这么认为的,既然交叉验证只是用来找到合适的模型参数,到最后我们要验证找的合适的模型参数是否合适,那么我们还是需要通过给模型看看它没有看过的数据来验证,所以我也支持第一种方法。
还有一点要说明的是,从上面的图中可以看出,交叉验证的时候同时训练十个模型(训练集和测试集都不一样),然后将结果取求和平均。到这里我又有一个疑惑,为什么是十个,不是五个,有浏览一些网站,总结一点:大家普遍用5个或者是10个。我后面会选5个的。不要问为什么,因为如果我用10个你也会问我同意的问题。
动手撸代码
又到开心又快乐的撸代码(我信你鬼)环节,对了,上面和接下来要做的都是基于sklearn的K近邻算法做的。为了更加深刻了解机器学习的敲代码步骤,下面将尽量从头开始做起。
案例描述
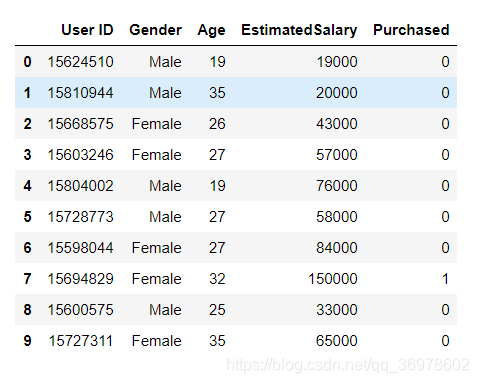
一家汽车公司刚刚推出了他们新型的豪华SUV,我们尝试预测哪些用户会购买这种全新SUV。数据集是从某社交网络中收集的用户信息。这些信息涉及用户ID、性别、年龄以及预估薪资,最后一列用来表示用户是否购买。我们将建立一种模型来预测用户是否购买这种SUV,该模型基于两个变量,分别是年龄和预计薪资。我们尝试寻找用户年龄与预估薪资之间的某种相关性,以及他们是否有购买SUV的决定。
导入常用相关库。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
导入数据集
dataset = pd.read_csv('./datasets/Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values
y = dataset.iloc[:, 4].values
将数据集划分成为训练集和测试集。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1/4, random_state=0)
数据标准化
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
运用训练集来做交叉验证,从而找到最优k值
我们因为要同时观察训练集的子训练集和测试集效果随着k的增加而变化情况,所以这里直接用 sklearn.model_selection 中的 vlidation_curve 来完成。
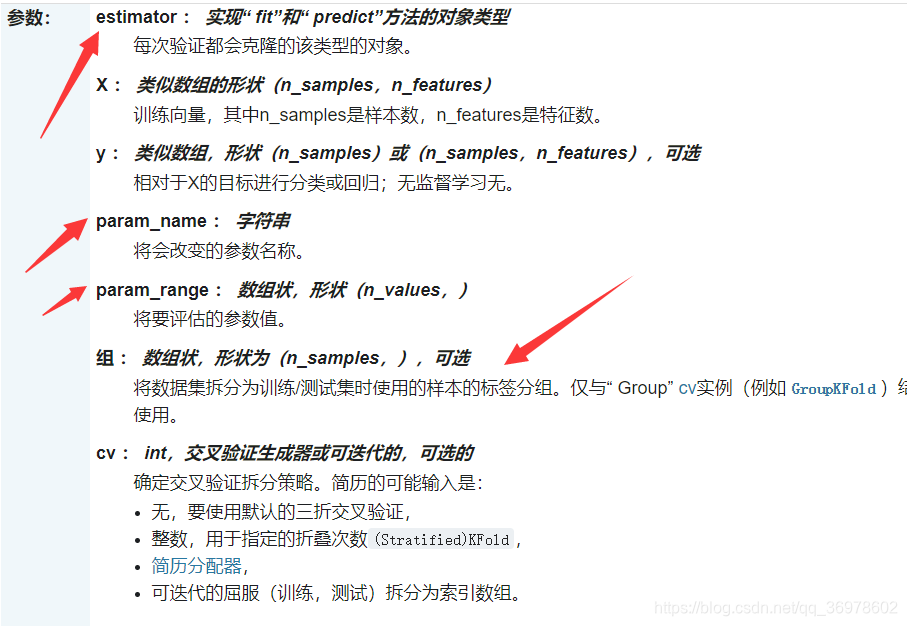

import matplotlib.pyplot as plt
from sklearn.model_selection import validation_curve
param_name = 'n_neighbors'
param_range = range(1, 51)
# scoring: 分类用 accuracy, 回归用 mean_squared_error
train_scores, test_scores = validation_curve(
KNeighborsClassifier(), X_train, y_train, cv=5,
param_name=param_name, param_range=param_range,
scoring='accuracy')
train_scores_mean = np.mean(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
plt.plot(param_range,train_scores_mean, color='red', label='train')
plt.plot(param_range, test_scores_mean, color='green', label='test')
plt.legend('best')
plt.xlabel('param range of k')
plt.ylabel('scores mean')
plt.show()
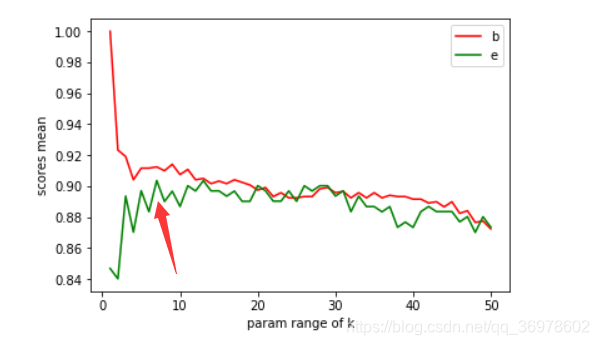
从上图我们可以看到最优的k值在7。
用找到的k值做模型训练
classifier = KNeighborsClassifier(n_neighbors=7)
classifier.fit(X_train, y_train)
用测试集测试结果
score = classifier.score(X_test, y_test)
print(score)
# ===> 0.93
到这里就结束了。最后要记住交叉验证不是用来提高模型准确率的,而是用来找到合适的模型参数,在数据集很小的时候防止过拟合。


















 848
848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









