






 本文介绍了新手如何通过学习HTML结构和CSS选择器定位Pixiv网页中的图片元素,以及如何处理动态加载和获取图片下载链接,以便于爬虫抓取内容。
本文介绍了新手如何通过学习HTML结构和CSS选择器定位Pixiv网页中的图片元素,以及如何处理动态加载和获取图片下载链接,以便于爬虫抓取内容。
Chapter1
其实最开始我学习爬虫的时候,难的不是写代码,毕竟python的网页相关代码都是封装好的,调用一下API就可以了。难的是一个没有学过Html和JS的人如何如何从网页中找到对应的资源。这里以Pixiv为例子,详细解释新手该如何定位到网页里我们想要的元素。
Chapter2.1:
首先我们还是要解释一下网页代码HTML的构成。这是一个HTML代码示例:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<!-- 可以在这里添加其他头部元素,如链接到外部样式表、脚本等 -->
</head>
<body>
<!-- 页面内容主体 -->
<h1>This is a Heading</h1>
<p>This is a paragraph.</p>
<!-- 可以在这里添加其他页面元素,如图片、链接、表单等 -->
<!-- 页面内容主体结束 -->
<!-- 可以在这里添加页面底部元素,如脚本、版权信息等 -->
</body>
</html>我们只关心如何获取内容,而网页内容都出现在两个“<body>”之间,内容是什么?图片、视频、音频everything。这些内容都以链接的形式出现,比如这个链接“//www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png”就是百度首页的LOGO,有了这个链接后,调用Python的下载器就可以下载到本地了,至于怎么下,用几个线程下都不是特别重要的东西。
<> 是一对尖括号(也称为尖角括号或尖头括号),在HTML中用于定义元素。HTML元素是构建网页的基本构建块,它们由开始标签、内容和结束标签组成,尖括号用于包裹这些标签。比如<img>指示的就是一个图片元素,也就是说,如果我们想要在pixiv上找图片,只要搜索网页代码内部的<img>标签即可。
Chapter2.2:
如果是这样,那么我们只要随便点开一个网页,再查看网页源码就ok了?
 事实上不是,因为现代的网页显示的内容可不少,但事实上用户很可能浏览不了那么多内容,如果每次用户点开一个网页,就把用户可能看到的东西全部载入,不但服务器带宽受不了,用户内存可能也受不了,因此现代网页都使用JavaScript动态加载用户期望看到的内容。
事实上不是,因为现代的网页显示的内容可不少,但事实上用户很可能浏览不了那么多内容,如果每次用户点开一个网页,就把用户可能看到的东西全部载入,不但服务器带宽受不了,用户内存可能也受不了,因此现代网页都使用JavaScript动态加载用户期望看到的内容。
比如说我想看图片A,但我还没翻到图片A的页面,那么图片A自然就没有加载,自然也不会出现在网页的HTML代码里,我们自然也不可能通过爬虫获取它的数据。
Chapter3
言归正传,介绍如何定位网页元素:
以Pixiv的推荐页为例( R16都算不上......):
我们随便点击一个图片——右键——检查:
我们马上就定位到了图片:
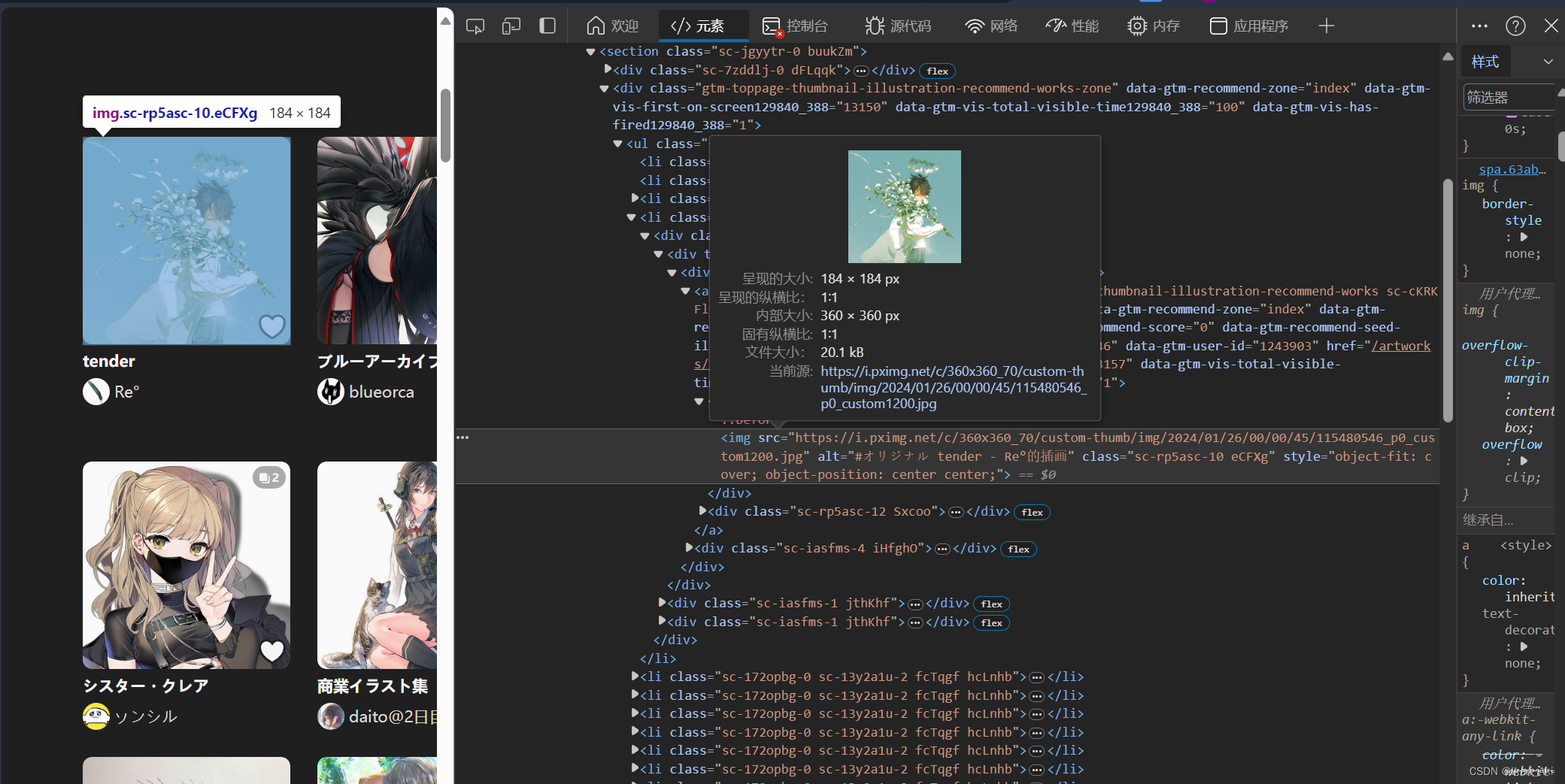
我们人知道了,python该如何知道呢?
imgs=browser.find_elements(By.CSS_SELECTOR,'div[class^="sc-rp5asc-9"]img')这代码使用了CSS 选择器来查找所有的符合要求的“语句”、div: 选择所有 <div> 元素。
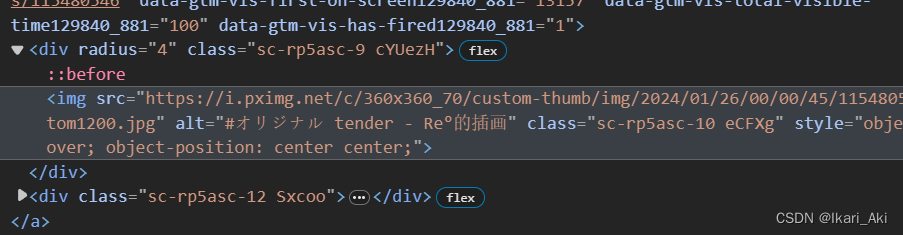
[class^="sc-rp5asc-9"]: 选择具有以 "sc-rp5asc-9" 开头的 class 属性值的 <div> 元素。
为什么要部分匹配,只匹配"sc-rp5asc-9“,而不直接查找class="sc-rp5asc-9 cYUezH"呢?因为pixiv的类名的后一部分会刷新,也就是 cYUezH不完全相同。
imgs里是什么?是所有符合要求的HTML语句,它还不是我们可以直接下载的内容,该如何找到下载链接呢?
pic_url=img[0].get_attribute('src').replace("i.pximg.net","i.pixiv.cat")上述代码就是获取第一条符合要求的语句里的图片下载链接。img[0].get_attribute('src')返回的是一个字符串,也就是下载链接。replace("i.pximg.net","i.pixiv.cat")就是将链接里的一部分替换掉,因为Pixiv对图片有一定的保护,你没法直接下载。
获取到的图片链接pic_url直接丢给下载器就行了

















 2999
2999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









