







python爬虫中,定位目标数据位置是很关键的一步,今天就来讲其中的一种方法,也是最基础的一种方法。
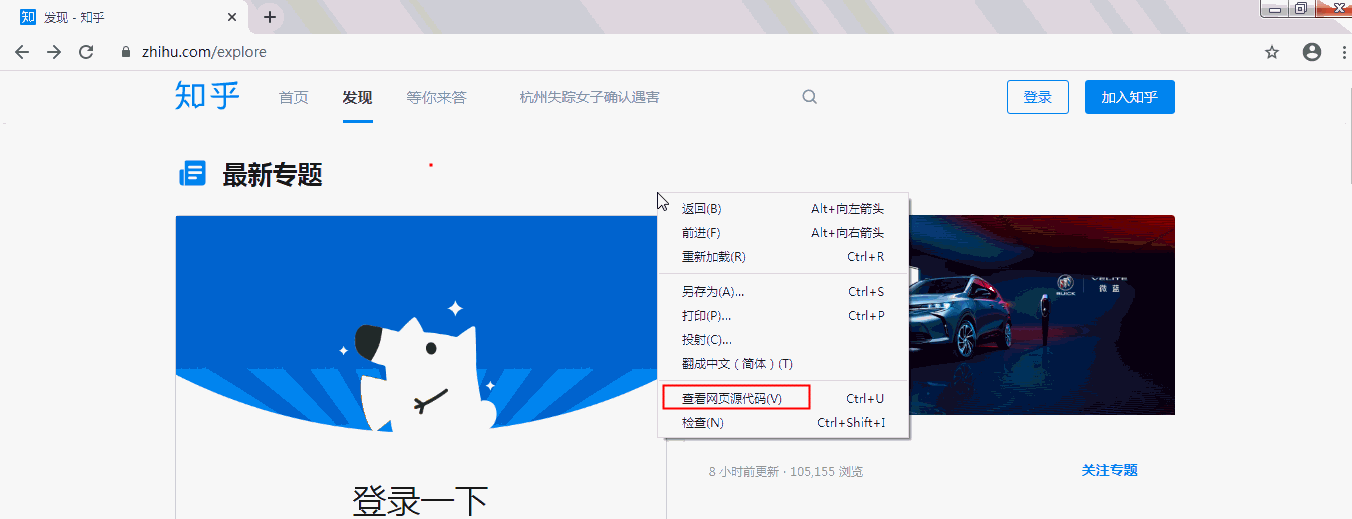
首先怎么看一个网页的源代码,例如打开知乎首页(网址:https://www.zhihu.com/explore),在网页任意空白处单击右键,然后点击【查看网页源代码】选项,就可以查看源代码了:
 源代码如下:
源代码如下:
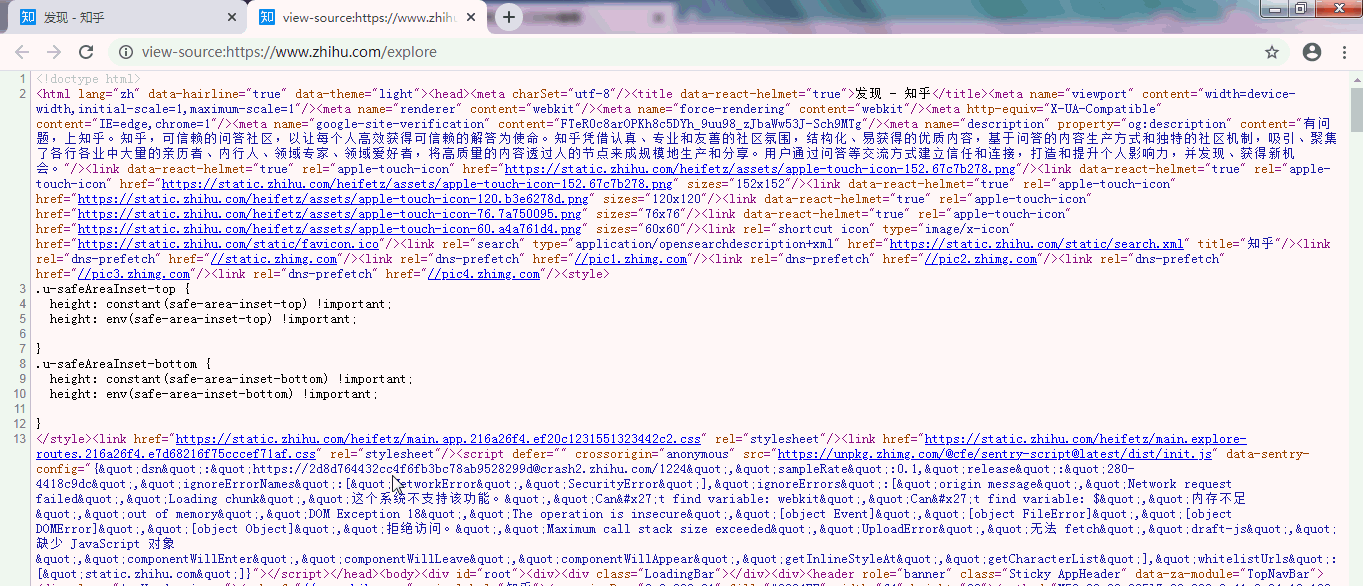
如果你是用Chrome浏览器,也可以直接在网页前面加前缀view-source:如,view-source:https://www.zhihu.com/explore,也是可以找到网页源代码。
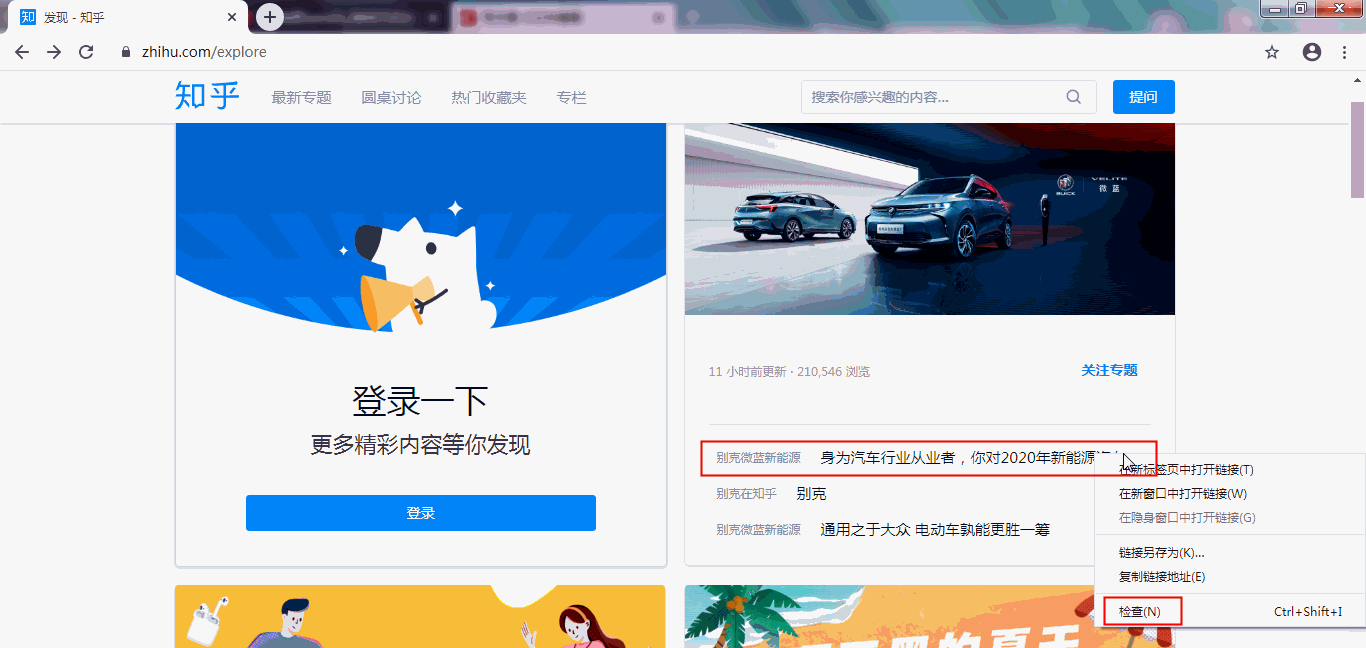
网页源代码是包含了网页的所有内容,但我们一般只需要部分的内容,如我只需要爬取知乎首页的某个标题信息,如下,鼠标停留在目标位置,单击右键,然后点击【检查】选项,就可以定位到该数据的代码位置了:
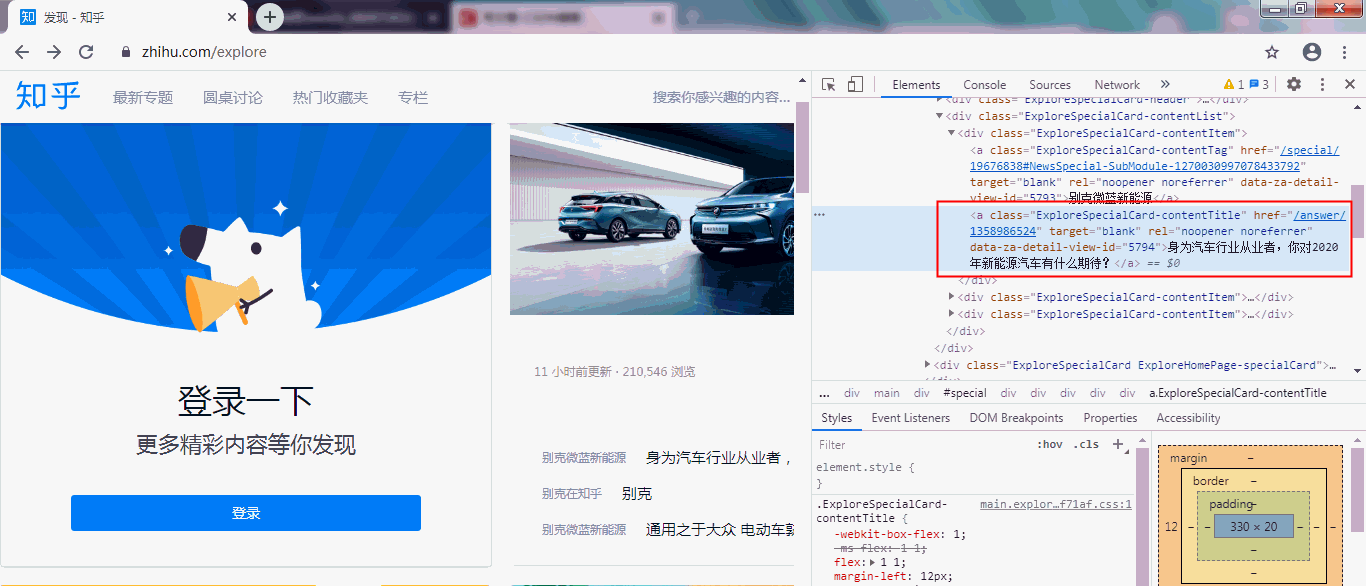
 目标数据位置如下:
目标数据位置如下:
最后再通过python代码将数据爬取出来,爬取代码请参考我的上一篇文章《python爬虫实例:爬取知乎首页专题信息》。
感悟:一步一个脚印,加油!















 1824
1824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









