







在昨天我们学习了Harris角点检测的方法,并且完成了原理到Sample到源码分析这一套学习过程,并且意外的知道了在它之上还有改进版,
不得不说知识是永无止尽的。今天我们开始撸一遍它的改进版算子 Shi-Tomasi角点以及OpenCV的goodFeatureToTrack()源码分析。
主要参考博客链接:
原理讲解:http://blog.csdn.net/u010682375/article/details/72810471 (清晰明了,深入的话估计要看原文)
Samples:http://blog.csdn.net/dcrmg/article/details/52551637 (目前主要是把它的OpenCV系列撸一遍)
OpenCV源码分析1:http://blog.csdn.net/xdfyoga1/article/details/44175637 (注释的非常清楚,博主牛人,大家去给他点赞吧!)
OpenCV源码分析2:http://blog.csdn.net/ZengDong_1991/article/details/45563301

1.原理:
我们学习了Harris角点检测后来1994年,J.shi和C.Tomasi在他们的文章《Good Features _to_Track》中对这个算法做了一个小小的修改,并得到了更好的结果。
文章我已经在GOOGLE上下下来了,但是竟然有30多页,我没怎么看,感兴趣的朋友可以自行下载或点击这里开始下载又或者留言。
Harris角点检测的打分方式为:
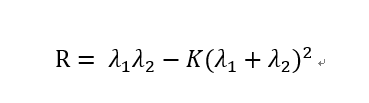
但 Shi-Tomasi使用的打分函数为:
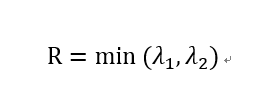
如果打分超过阈值,我们就认为它是一个角点。我们可以把它绘制到 λ1 ~λ2 空间中,就会得到下图:
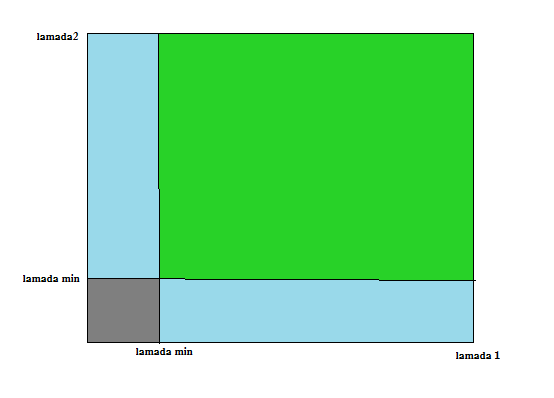
从这幅图中,我们可以看出来只有当 λ1 和 λ2 都大于最小值时,才被认为是角点(绿色区域)。
OpenCV 提供了函数: cv2.goodFeaturesToTrack()。这个函数可以帮我们使用 Shi-Tomasi 方法获取图像中 N 个最好的角点(也可以通过改变参数来使用 Harris 角点检测算法)。通常情况下,输入的应该是灰度图像。然后确定你想要检测到的角点数目。再设置角点的质量水平, 0到 1 之间。它代表了角点的最低质量,低于这个数的所有角点都会被忽略。最后在设置两个角点之间的最短欧式距离。根据这些信息,函数就能在图像上找到角点。所有低于质量水平的角点都会被忽略,然后再把合格角点按角点质量进行降序排列。函数会采用角点质量最高的那个角点(排序后的第一个),然后将它附近(最小距离之内)的角点删掉。按着这样的方式最后返回 N 个最佳角点。
2.Samples:
2.1函数原型:
//goodFeaturesToTrack有比cornerHarries更多的控制参数,函数原型:
void goodFeaturesToTrack( InputArray image, OutputArray corners,
int maxCorners, double qualityLevel, double minDistance,
InputArray mask=noArray(), int blockSize=3,
bool useHarrisDetector=false, double k=0.04);
/*第一个参数image:8位或32位单通道灰度图像;
第二个参数corners: 位置点向量,保存的是检测到角点的坐标;
第三个参数maxCorners: 定义可以检测到的角点的数量的最大值;
第四个参数qualityLevel: 检测到的角点的质量等级,角点特征值小于qualityLevel*最大特征
值的点将被舍弃;
第五个参数minDistance: 两个角点间最小间距,以像素为单位;
第六个参数mask: 指定检测区域,若检测整幅图像,mask置为空Mat();
第七个参数blockSize: 计算协方差矩阵时窗口大小;
第八个参数useHarrisDector: 是否使用Harris角点检测,为false,则使用Shi-Tomasi算子;
第九个参数K: 留给Harris角点检测算子用的中间参数,一般取经验值0.04~0.06.第8个参数为false时,改参数不起作用;
*/2.2完整代码:
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
using namespace cv;
Mat image;
Mat imageGray;
int thresh=5; //角点个数控制
int MaxThresh=255;
void Trackbar(int, void*);
int main()
{
image = imread("Test.bmp");
cvtColor(image,imageGray,CV_RGB2GRAY);
GaussianBlur(imageGray,imageGray,Size(5,5),1); //滤波
namedWindow("Corner Detected");
createTrackbar("threshold: ","Corner Detected",&thresh,MaxThresh,Trackbar);
imshow("Corner Detected",image);
Trackbar(0,0);
waitKey();
return 0;
}
void Trackbar(int,void*)
{
Mat dst, imageSource;
dst=Mat::zeros(image.size(),CV_32FC1);
imageSource=image.clone();
vector<Point2f> corners;
goodFeaturesToTrack(imageGray,corners,thresh,0.01,10,Mat());
for(int i=0; i<corners.size(); i++)
{
circle(imageSource,corners[i],2,Scalar(0,0,255),2);
}
imshow("Corner Detected",imageSource);
}
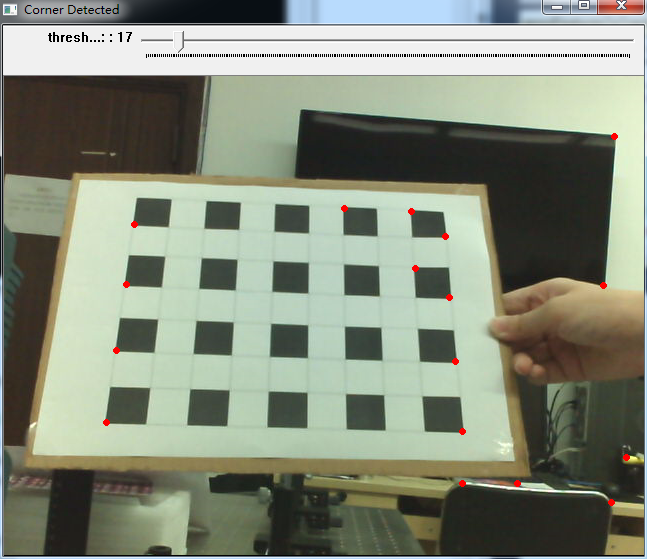
3.源码分析:
goodFeaturesToTrack函数的定义在imgproc文件的featureselect.cpp中,下面给出了goodFeaturesToTrack函数的详细注释。
博主的链接在开头我已给出,大家去帮他点个赞吧!确实很详细
void cv::goodFeaturesToTrack( InputArray _image, OutputArray _corners,
int maxCorners, double qualityLevel, double minDistance,
InputArray _mask, int blockSize,
bool useHarrisDetector, double harrisK )
{
//如果需要对_image全图操作,则给_mask传入cv::Mat(),否则传入感兴趣区域
Mat image = _image.getMat(), mask = _mask.getMat();
CV_Assert( qualityLevel > 0 && minDistance >= 0 && maxCorners >= 0 ); //对参数有一些基本要求
CV_Assert( mask.empty() || (mask.type() == CV_8UC1 && mask.size() == image.size()) );
Mat eig, tmp; //eig存储每个像素协方差矩阵的最小特征值,tmp用来保存经膨胀后的eig
if( useHarrisDetector )
cornerHarris( image, eig, blockSize, 3 ,harrisk ); //blockSize是计算2*2协方差矩阵的窗口大小,sobel算子窗口为3,harrisk是计算Harris角点时需要的值
else
cornerMinEigenVal( image, eig, blockSize, 3); //计算每个像素对应的协方差矩阵的最小特征值,保存在eig中
double maxVal = 0;
minMaxLoc( eig, 0, &maxVal, 0, 0, mask ); //maxVal保存了eig的最大值
threshold( eig, eig, maxVal*qualityLevel, 0, THRESH_TOZERO); //阈值设置为maxVal乘以qualityLevel,大于此阈值的保持不变,小于此阈值的都设为0
//默认用3*3的核膨胀,膨胀之后,除了局部最大值点和原来相同,其他非局部最大值点被
//3*3邻域内的最大值点取代,如不理解,可看一下灰度图像的膨胀原理
dilate( eig, tmp, Mat() ); //tmp中保存了膨胀之后的eig
Size imgsize = image.size();
vector<const float*> tmpCorners; //存放粗选出的角点地址
// collect list of pointers to features - put them into temporary image
for( int y = 1; y < imgsize.height -1; y++)
{
const float* eig_data = (const float*)eig.ptr(y); //获得eig第y行的首地址
const float* tmp_data = (const float*)tmp.ptr(y); //获得tmp第y行的首地址
const uchar* mask_data = mask.data ? mask.ptr(y) : 0;
for( int x =1; x < imgsize.width - 1; x++)
{
float val = eig_data[x];
if( val != 0 && val == tmp_data[x] && (!mask_data || mask_data[x]) ) //val == tmp_data[x], 说明这是局部极大值
tmpCorners.push_back(eig_data + x); //保存其位置
}
}
//--------------此分割线以上是根据特征值粗选出的角点,我们称之为弱角点-----------//
//--------------此分割线以下还要根据minDistance进一步筛选角点,仍然能存活下来的我们称之为强角点------------//
sort( tmpCorners, greaterThanPtr<float>() ); //按特征值降序排列,注意这一步很重要,后面的很多编程思路都是建立在这给降序排列的基础上
vector<Point2f> corners;
size_t i, j, total = tmpCorners.size(), ncorners = 0;
//下面的程序有点稍微理解,需要自己想想
if(minDistance >= 1)
{
//Partition the image into larger grids
int w = image.cols;
int h = image.rows;
const int cell_size = cvRound(minDistance); //向最近的整数取整
//这里根据cell_size构建了一个矩形窗口grid(虽然下卖弄的grid定义的是vector<vector>,而并不是我们这里说的矩形窗口,但是为了便于理解,还是将grid想象成一个grid_width*grid_width的矩形窗口比较好),除以cell_size说明grid窗口里相差一个像素相当于_image里相差minDistance个像素,至于为什么加上cell_size - 1,后面会讲
const int grid_width = (w + cell_size - 1) / cell_size;
const int grid_width = (h + cell_size - 1) / cell_size;
std::vector<std::vector<Point2f> > grid(grid_width*grid_width); //vector里面是vector,grid用来保存获得的强角点坐标
minDistance *= minDistance; //平方,方便后面计算,省的开根号
for( i = 0; i < total; i++)
{
int ofs = (int)((const uchar*)tmpCorners[i] - eig.data); //tmpCorners中保存了角点的地址,eig.data返回了内存块的地址
int y = (int)(ofs / eig.step); //角点在原图像中的行
int x = (int)((ofs - y*eig.step)/sizeof(float)); //在原图像中的列
bool good = true; //先认为当前角点能接收考验,即能被保留下来
int x_cell = x / cell_size; //x_cell, y_cell是角点(y,x)在grid中的坐标
int y_cell = y_cell - 1; //现在知道为什么前面grid_width定义时要加上cell_size - 1了吧,这是为了使得(y,x)在grid中的4邻域像素都存在,也就是说(y_cell, x_cell)不会成为边界像素
int x2 = x_cell + 1;
int y2 = y_cell + 1;
// boundary check,再次确认x1,y1,x2,或y2不会超出grid边界
x1 = std::max(0, x1); //比较0和x1的大小
y1 = std::max(0, y1);
x2 = std::min(grid_width-1, x2);
y2 = std::min(grid_height-1, y2);
//记住grid相差一个像素,相当于_image相差了minDistance个像素
for( int yy = y1; yy <= y2; yy++) //行
{
for( int xx = x1; xx <= x2; xx++)
{
vector <Point2f> &m = grid[yy*grid_width + xx]; //引用
if( m.size() ) //如果(y_cell,x_cell的4邻域像素,也就是(y,x)的minDistance邻域像素中已有被保留的强角点)
{
for(j = 0; j < m.size(); j++) //当前角点周围的强角点都拉出来跟当前角点比一比
{
float dx = x - m[j].x;
float dy = y - m[j].y;
//注意如果(y,x)的minDistance邻域像素中已有被保留的强角点,则说明该强角点是在(y,x)之前就被测试过的,又因为tmpCorners中已按照特征值降序排列(特征值越大说明角点越好),这说明先测试的一定是更好的角点,也就是已保存的角点一定好于当前角点,所以这里只要比较距离,如果距离满足条件,可以立马扔掉当前测试的角点
if( dx*dx + dy*dy < minDistance )
{
good = false;
goto break_out;
}
}
}
} //列
} //行
break_out;
if(good)
{
//printf("%d: %d%d ->%d %d, %d, %d -- %d %d %d %d, %d %d, c=%d\n",
// i,x, y, x_cell, y_cell, (int)minDistance, cell_size,x1,y1,x2,y2,grid_width,grid_height,c);
grid[y_cell*grid_width + x_cell].push_back(Point2f((float)x,(float)y));
corners.push_back(Point2f((float)x, (float)y));
++ncorners;
if(maxCorners > 0 && (int)ncorners == maxCorners ) //用于前面已按降序排列,当ncorners超过maxCorners的时候跳出循环直接忽略tmpCorners中剩下的角点,反正剩下的角点越来越弱
break;
}
}
}
else //除了像素本身,没有哪个邻域像素能与当前像素满足minDistance < 1,因此直接保存粗选的角点
{
for( i = 0; i < total; i++)
{
int ofs = (int)((const uchar*)tmpCorners[i] - eig.data);
int y = (int)(ofs / eig.step); //粗选的角点在原图像中的行
int x = (int)((ofs - y*eig.step)/sizeof(float)); //在图像中的列
corner.push_back(Point2f((float)x, (float)y));
++ncorners;
if( maxCorners > 0 && (int)ncorners == maxCorners )
break;
}
}
Mat(corners).convertTo(_corners, _corners.fixedType() ? _corners.type : CV_32F);
/*
for( i = 0; i < total; i++ )
{
int ofs = (int)((const uchar*)tmpCorners[i] - eig.data);
int y = (int)(ofs / eig.step);
int x = (int)((ofs - y*eig.step)/sizeof(float));
if( minDistance > 0 )
{
for( j = 0; j < ncorners; j++ )
{
float dx = x - corners[j].x;
float dy = y - corners[j].y;
if( dx*dx + dy*dy < minDistance )
break;
}
if( j < ncorners )
continue;
}
corners.push_back(Point2f((float)x, (float)y));
++ncorners;
if( maxCorners > 0 && (int)ncorners == maxCorners )
break;
}
*/
}PS:这套源码我已经手动敲了两遍了,但是理解的还是不够深刻,大家不妨多敲几次
这个版本的解释很清晰,由于代码是一样的,我只是看了,没怎么敲
//GoodFeaturesToTrack关键代码截取
void myGoodFeaturesToTrack( Mat& image, double qualityLevel, double minDistance, int maxCorners )
{
Mat eig;
Mat tmp;
cornerHarris(image, eig, 5, 3, 0.06); //Harris corners;
double maxVal = 0;
minMaxLoc(eig, 0, &maxVal, 0, 0, Mat());
//cout << maxVal << endl << maxVal*255. << endl;
//除去角点响应小于 角点最大响应qualityLevel倍的点
threshold(eig, eig, qualityLevel*maxVal, 0, THRESH_TOZERO); //eig is CV_32F
//normalize(eig, result, 0, 255, NORM_MINMAX, CV_8U); //normalize to show image.
//get corners max in 3*3 if Mat();
//为什么膨胀操作:膨胀的本质是用当前像素周围的最大值替代当前像素值,
//因此,通过膨胀前后比较能取得局部角点响应最大的点。
//第一次是在《OpenCV Programming Cookbook》中看到这种做法,觉得这想法太给力了...
//最后结果存储在tmpCorners中
dilate(eig, tmp, Mat()); //for later operation
vector<const float*> tmpCorners;
Size imageSize = image.size();
{
// HANDLE hSemaphore = CreateSemaphore(NULL, 0, 1, NULL);
// CRITICAL_SECTION g_cs;
//#pragma omp parallel for //【此处并行为什么出错呢???????????????】
for ( int y = 1; y < imageSize.height -1; y++ )
{
float* eig_data = (float*)eig.ptr<float>(y); //角点响应
float* tmp_data = (float*)tmp.ptr<float>(y); // 膨胀之后
//#pragma omp parallel for
for ( int x =1; x < imageSize.width -1; x++ )
{
float val = eig_data[x];
if ( val != 0 && val == tmp_data[x] ) //如果膨胀前后的值不变,说明这个像素点是[3*3]邻域的最大值
{
// #pragma omp atomic //原子操作
// WaitForSingleObject(hSemaphore, NULL);
//EnterCriticalSection(&g_cs);
tmpCorners.push_back(eig_data + x);
//LeaveCriticalSection(&g_cs);
// ReleaseSemaphore(hSemaphore, NULL, NULL);
}
}
}
}
//ShellExecuteEx
//tmpCorners存储角点的地址, 排序操作
sort(tmpCorners, greaterThanPtr<float>());
vector<Point2f> corners;
size_t i, j, total = tmpCorners.size(), ncorners = 0;
if ( minDistance >= 1 ) //如果有角点之间最小距离限制
{
//将图片分为各个grid...每个grid的边长为minDistance
int w = image.cols;
int h = image.rows;
//cvRound :Rounds floating-point number to the nearest integer
const int cell_size = cvRound(minDistance);
const int grid_width = (w + cell_size -1) / cell_size;
const int grid_height = (h + cell_size -1) /cell_size;
//每个grid用一个vector<Point2f> 存储角点
vector<vector<Point2f> > grid(grid_width*grid_height);
minDistance *= minDistance;
for ( i =0; i < total; i++ )
{
//先得到当前点的坐标
int ofs = (int)((const uchar*)tmpCorners[i] - eig.data);
int y = (int)(ofs / eig.step);
int x = (int)((ofs - y*eig.step) / sizeof(float));
bool good = true;
//确定当前点对应哪个grid
int x_cell = x / cell_size;
int y_cell = y / cell_size;
//得到上下,左右[-1,1]范围内grid
int x1 = x_cell - 1;
int y1 = y_cell - 1;
int x2 = x_cell + 1;
int y2 = y_cell + 1;
x1 = max(0, x1);
y1 = max(0, y1);
x2 = min(grid_width-1, x2);
y2 = min(grid_height-1, y2);
//上面说过每个grid用一个vector<Point2f> 存储位于这个区域内的角点
//对当前角点,先得到坐标,然后找到属于哪个grid,并和周围的8(最大是8)个grid中
//的 Point2f 比较距离,如果两点之间的距离小于minDistance则放弃这个角点
//因为我们是按角点响应的降序依次访问的...
for ( int yy = y1; yy <= y2; yy++ )
{
for ( int xx = x1; xx <= x2; xx++ )
{
//m存储对应grid中角点。一个grid中可能有多个角点
vector<Point2f>& m = grid[yy*grid_width + xx];
if ( m.size() )
{
//求当前角点到这个grid内所有角点的距离,若小于当前grid中的某个点,直接跳到break_out,其他
//grid不用再比较,直到周围grid都没有距离小于minstance的值,则将角点push进当前grid中
for ( j =0; j < m.size(); j++ )
{
float dx = x - m[j].x;
float dy = y - m[j].y;
if ( dx*dx + dy*dy < minDistance )
{
good = false;
goto break_out;
}
}
}
}
}
break_out:
if ( good )
{
//将当前角点存入grid中
grid[y_cell*grid_width + x_cell].push_back(Point2f((float)x, (float)y));
circle(image, Point(x, y), 5, Scalar(255), 2);
corners.push_back(Point2f((float)x, (float)y));
++ncorners;
if ( maxCorners > 0 && (int)ncorners == maxCorners )
{
break;
}
}
}
}
else //如果不考虑角点间最小距离限制
{
for ( i = 0; i < total; i++ )
{
//因为eig.step 是Number of bytes each matrix row occupies.
int ofs = (int)((const uchar*)tmpCorners[i] - eig.data);
//通过tmpCorner存储的角点在内存中的地址还原得到图像中的坐标..
int y = (int)(ofs / eig.step);
int x = (int)((ofs - y*eig.step) / sizeof(float));
circle(image, Point(x, y), 5, Scalar(255), 2);
corners.push_back(Point2f((float)x, (float)y));
++ncorners;
if ( maxCorners > 0 && (int)ncorners == maxCorners )
{
break;
}
}
}
imshow("eig", image);昨天的Qt也没更新,今天Kinect又到了,晚上怕是又要折腾一下,OpenCV还有很多有意思的功能也没更新,脑容量也不够。














 993
993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









