








主要参考博客:
1.理解机器学习中的偏差与方差
2.周志华《机器学习》笔记:2、模型评估与选择
3.机器学习模型性能评估方法笔记
比较检验
前面介绍了各种性能度量方式,但是其度量的是模型在测试集下的测试误差的性能状况,虽然其可以近似代替泛化性能,但毕竟与真实的泛化性能有一定的距离,在这里我们介绍通过假设检验的方式,利用测试误差来预估泛化误差从而得到模型的泛化性能情况,即基于假设检验结果我们可以推断出若在测试集上观察到模型A比B好,那么A的泛化性能在统计意义上优于B的概率有多大
一句话:无假设不检验
牵涉到概论的知识太多,尤其是后面的各种分布(都有点忘光了,不做详细介绍)
假设检验
假设检验就是数理统计中依据一定的假设条件,由样本推断总体的一种方法。其步骤如下所示:
1. 根据问题的需要对所研究的总体做某种假设,记为
H0
2. 选取合适的统计量,这个统计量的选取要使得在假设
H0
成立时,其分布是已知的(统计量我们可以视为样本的函数)
3. 由实测的样本计算出统计量的值,根据预先给定的显著性水平进行检验,做出拒绝或接受假设
H0
的判断.根据以上三步我们知道首先我们要对所研究的总体做出某种假设,在我们所研究的问题中就是对模型泛化错误率分布做出某种假设或猜想。通常,测试错误率与泛化误差率的差别很小,因此我们可以通过测试误差率来估计泛化误差率。我们知道泛化误差率为ϵ的模型在m个样本中被测得的测试错误率为ϵ^的概率为
我们可以看到该概率的格式满足二项分布,那么 ϵ 在取什么值的时候,概率P最大?让P对 ϵ 求导后我们可以发现当 ϵ=ϵ^ 的时候,概率值是最大的,二项分布示意图如下所示:
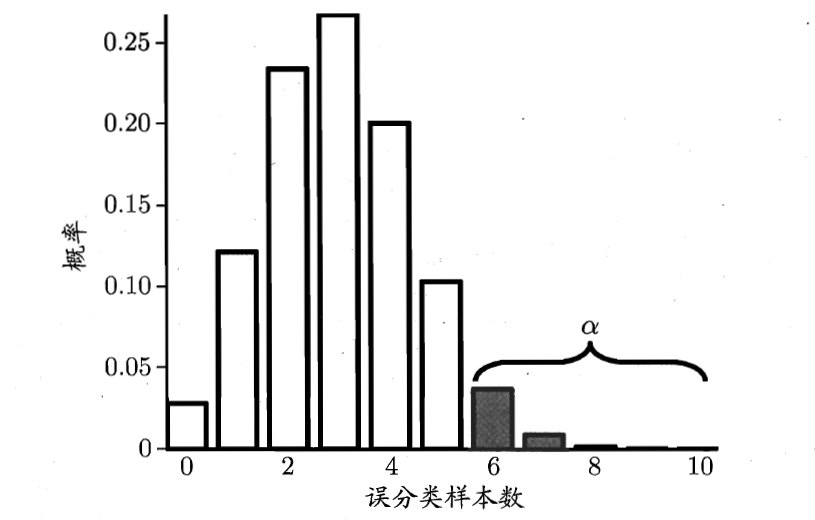
因此,我们可以假设泛化误差率 ϵ≤ϵ0 ,那么在 1−α 的概率内所能观测到的最大错误率可以通过下式计算得到:
大多数情况下,我们会使用多次留出或交叉验证法,因此我们会得到多组测试误差率,此时我们可以使用t检验的方式来进行泛化误差的评估。
即假定我们得到了k个测试误差率, ϵ^1,ϵ^1,...,ϵ^k ,则平均测试错误率 μ 和方差 σ2 为
由于这k个测试误差率可以看做泛化误差率 ϵ0 的独立采样,因此变量 τt=k√(μ−ϵ0)σ 服从自由度为k-1的t分布。对于假设 μ=ϵ0 和显著度 α ,我们可以计算出当前错误率均值为 ϵ0 时,在 1−α 概率内能观测到的最大错误率,即临界值。这样我们就可以对我们的假设做出拒绝或接受。
书中还有介绍诸如交叉验证t检验、McNemar检验、Friendman检验与Nemenyi后续检验等方法,我概论学的差,感兴趣可以自己查找资料看看。
误差方差与偏差
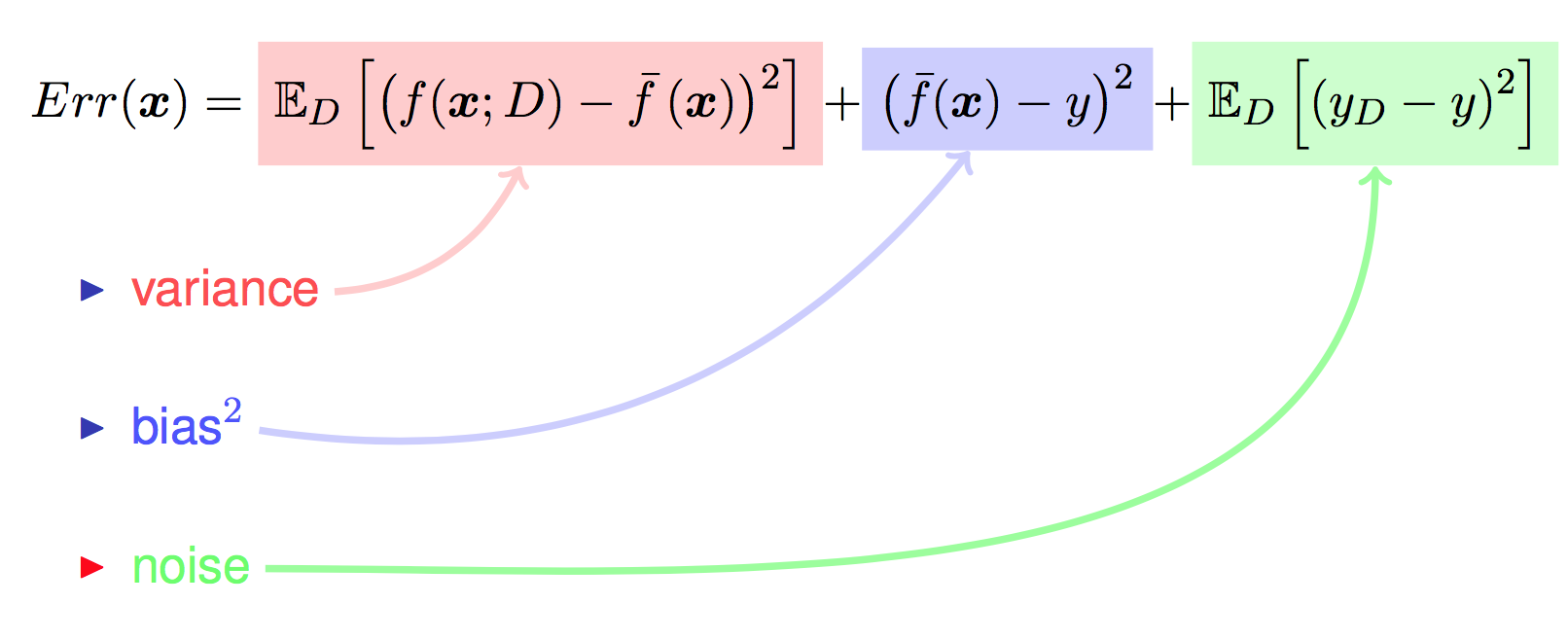
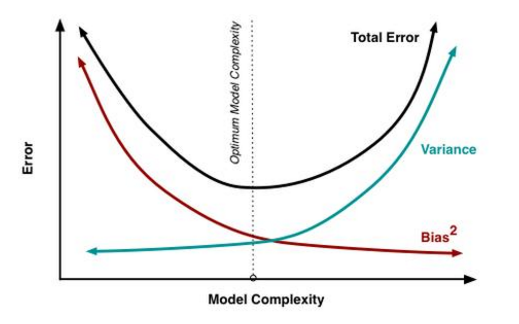
学习算法的预测误差, 或者说泛化误差(generalization error)可以分解为三个部分: 偏差(bias), 方差(variance) 和噪声(noise). 在估计学习算法性能的过程中, 我们主要关注偏差与方差. 因为噪声属于不可约减的误差 (irreducible error).
首先抛开机器学习的范畴, 从字面上来看待这两个词:
偏差
这里的偏指的是 偏离 , 那么它偏离了什么到导致了误差? 潜意识上, 当谈到这个词时, 我们可能会认为它是偏离了某个潜在的 “标准”, 而这里这个 “标准” 也就是真实情况 (ground truth). 在分类任务中, 这个 “标准” 就是真实标签 (label).方差
很多人应该都还记得在统计学中, 一个随机变量的方差描述的是它的离散程度, 也就是该随机变量在其期望值附近的 波动程度 . 取自维基百科一般化的方差定义:如果 X 是一个向量其取值范围在实数空间 Rn ,并且其每个元素都是一个一维随机变量,我我们就称 X 为随机向量。随机向量的方差是一维随机变量方差的自然推广,其定义为
E[(X−μ)(X−μ)T] ,其中 μ=E(X) , XT 是 X 的转置.
来个靶心图:(确实很直观)
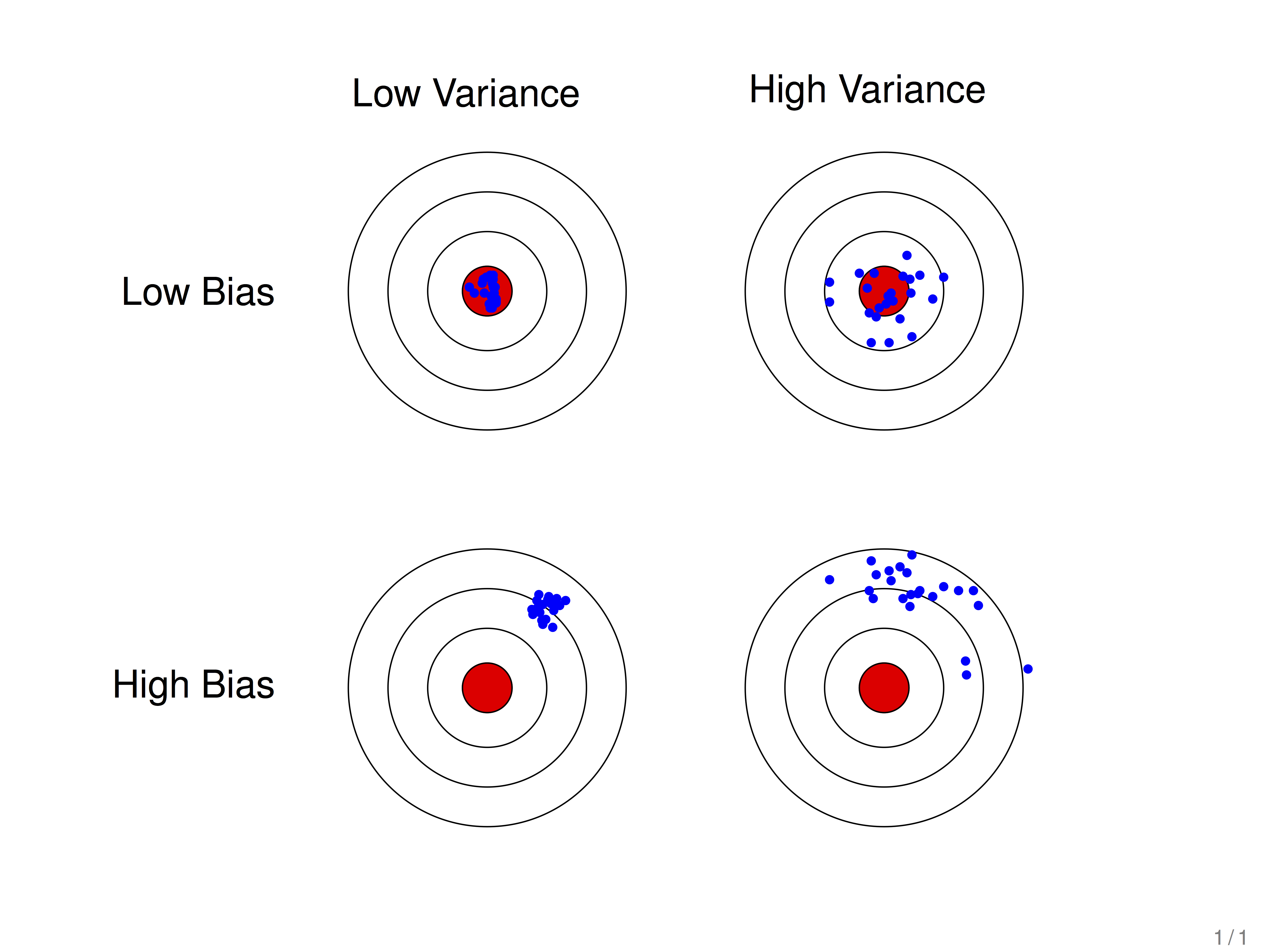
假设红色的靶心区域是学习算法完美的正确预测值, 蓝色点为每个数据集所训练出的模型对样本的预测值, 当我们从靶心逐渐向外移动时, 预测效果逐渐变差.
很容易看出有两副图中蓝色点比较集中, 另外两幅中比较分散, 它们描述的是方差的两种情况. 比较集中的属于方差小的, 比较分散的属于方差大的情况.
再从蓝色点与红色靶心区域的位置关系, 靠近红色靶心的属于偏差较小的情况, 远离靶心的属于偏差较大的情况.
有了直观感受以后, 下面来用公式推导泛化误差与偏差与方差, 噪声之间的关系.
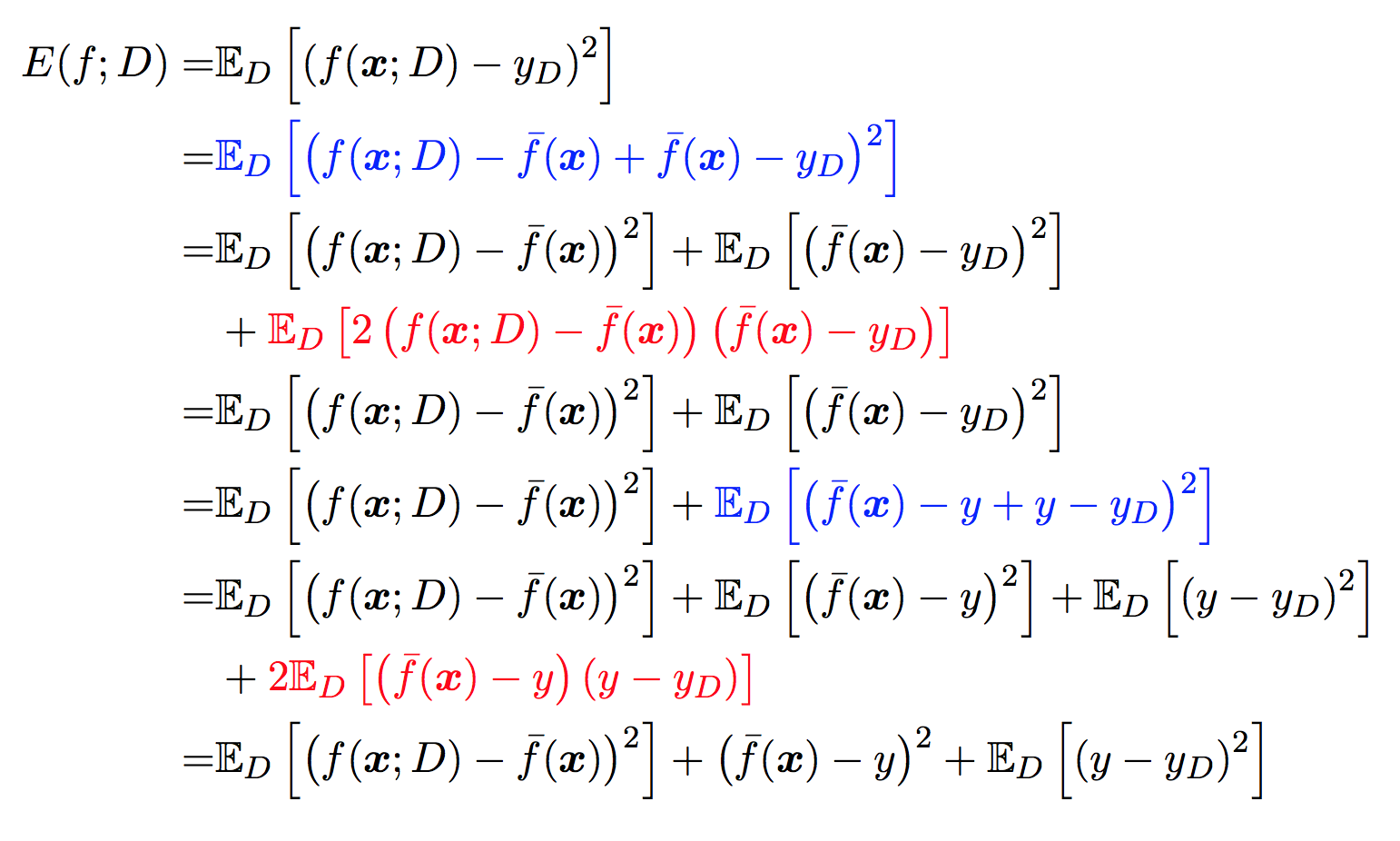
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









