







来自:http://blog.csdn.net/stdcoutzyx/article/details/41596663
概述
起源
卷积网络最初是受视觉神经机制的启发而设计的,是为识别二维形状而设计的一个多层感知器,这种网络结构对平移、比例缩放、倾斜或者共他 形式的变形具有高度不变性。
1962年Hubel和Wiesel通过对猫视觉皮层细胞的研究,提出了感受野(receptive field)的概念,1984年日本学者Fukushima 基于感受野概念提出的神经认知机(neocognitron)模型,它可以看作是卷积神经网络的第一个实现网络,也是感受野概念在人工神经网络领域的首次应用。
神经认知机将一个视觉模式分解成许多子模式(特征),然后进入分层递阶式相连的特征平面进行处理,它试图将视觉系统模型化,使其能够在即使物体有 位移或轻微变形的时候,也能完成识别。神经认知机能够利用位移恒定能力从激励模式中学习,并且可识别这些模式的变化形。在其后的应用研究中,Fukushima 将神经认知机主要用于手写数字的识别。随后,国内外的研究人员提出多种卷积神经网络形式,在邮政编码识别(Y. LeCun etc)、车牌识别和人脸识别等方面 得到了广泛的应用。
CNN的结构
主要特点
卷积神经网络是一种特殊的深层的神经网络模型,它的特殊性体现在两个方面,一方面它的神经元间的连接是非全连接的, 另一方面同一层中某些神经元之间的连接的权重是共享的(即相同的)。它的非全连接和权值共享的网络结构使之更类似于生物神经网络,降低了网络模型的复杂度(对于很难学习的深层结构来说,这是非常重要的),减少了权值的数量。
局部连接
回想一下BP神经网络。BP网络每一层节点是一个线性的一维排列状态,层与层的网络节点之间是全连接的。这样设想一下,如果BP网络中层与层之间的节点连接不再是全连接,而是局部连接的。这样,就是一种最简单的一维卷积网络。如果我们把上述这个思路扩展到二维,这就是我们在大多数参考资料上看到的卷积神经网络。
根据BP网络信号前向传递过程,我们可以很容易计算网络节点的输出。例如,对于上图中被标注为红色节点的净输入,就等于所有与红线相连接的上一层神经元节点值与红色线表示的权值之积的累加。这样的计算过程,很多书上称其为卷积。
事实上,对于数字滤波而言,其滤波器的系数通常是对称的。否则,卷积的计算需要先反向对折,然后进行乘累加的计算。上述神经网络权值满足对称吗?我想答案是否定的!所以,上述称其为卷积运算,显然是有失偏颇的。但这并不重要,仅仅是一个名词称谓而已。只是,搞信号处理的人,在初次接触卷积神经网络的时候,带来了一些理解上的误区。(这是我在网络上看到的人说的,我觉得他说的有那么点问题)
权值共享
卷积神经网络另外一个特性是权值共享,即同一个特征映射上的神经元使用相同的卷积核
上面描述的只是单层网络结构,前A&T Shannon Lab 的 Yann LeCun等人据此提出了基于卷积神经网络的一个文字识别系统 LeNet-5。该系统90年代就被用于银行手写数字的识别。
形式约束
刚才说到了卷积网络的特点,如,局部不变性:对平移、比例缩放、倾斜或者共他形式的变形具有高度不变性等。这些特性是网络在有监督方式下学会的。
这种网络结构是为识别二维形状而特殊设计的一个多层感知器,除了有上文所说的稀疏连接和权值共享两个特点外,还包括如下形式的约束:
1、 特征提取。每一个神经元从上一层的局部接受域得到突触输人,因而迫使它提取局部特征。一旦一个特征被提取出来, 只要它相对于其他特征的位置被近似地保留下来,它的精确位置就变得没有那么重要了。
2 、特征映射。网络的每一个计算层都是由多个特征映射组成的,每个特征映射都是平面形式的。平面中单独的神经元在约束下共享相同的突触权值集,这种结构形式具有如下的有益效果:a.平移不变性。b.自由参数数量的缩减(通过权值共享实现)。
3、子抽样。每个卷积层后面跟着一个实现局部平均和子抽样的计算层,由此特征映射的分辨率降低。这种操作具有使特征映射的输出对平移和其他形式的变形的敏感度下降的作用。
结构图
卷积神经网络是一个多层的神经网络,每层由多个二维平面组成,而每个平面由多个独立神经元组成。
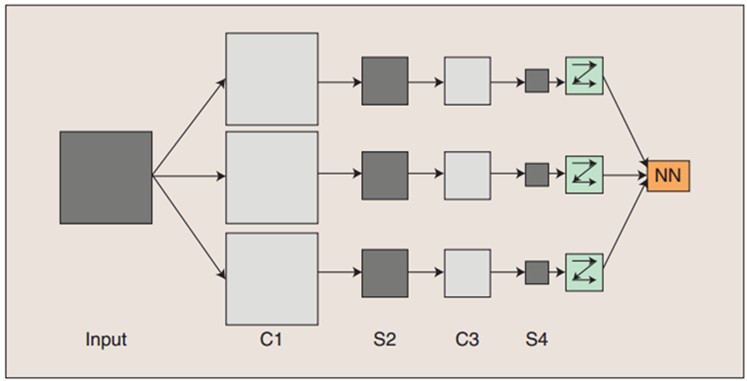
图:卷积神经网络的概念示范
- 输入图像通过和三个可训练的滤波器(卷积核)和可加偏置进行卷积,卷积后在C1层产生三个特征映射图。
- C1特征映射图中每组的四个像素再进行求和,加权值,加偏置,通过一个Sigmoid函数得到三个S2层的特征映射图
- S2映射图再进过滤波得到C3层。这个层级结构再和S2一样产生S4。
- 这些像素值被光栅化,并连接成一个向量输入到传统的神经网络,得到输出。
卷积神经网络是一个多层的神经网络,每层由多个二维平面组成,而每个平面由多个独立神经元组成。
网络中包含一些简单元和复杂元,分别记为S-元 和C-元。S-元聚合在一起组成S-面,S-面聚合在一起组成S-层,用Us表示。C-元、C-面和C-层(Uc)之间存在类似的关系。
网络的任一中间级由S-层与C-层 串接而成,而输入级只含一层,它直接接受二维视觉模式,样本特征提取步骤已嵌入到卷积神经网络模型的互联结构中。
一般地,C层为特征提取层,每个神经元的输入与前一层的局部感受野相连,并提取该局部的特征,一旦该局部特征被提取后,它与其他特征间的位置关系也随之确定下来.
S层是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射为一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。
此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数,降低了网络参数选择的复杂度。 卷积神经网络中的每一个特征提取层(C-层)都紧跟着一个用来求局部平均与二次提取的计算层(S-层),这种特有的两次特征提取结构使网络在识别时对输入样本有较高的畸变容忍能力。
稀疏连接(Sparse Connectivity)
卷积网络通过在相邻两层之间强制使用局部连接模式来利用图像的空间局部特性,在第m层的隐层单元只与第m-1层的输入单元的局部区域有连接,第m-1层的这些局部区域被称为空间连续的接受域。我们可以将这种结构描述如下:
设第m-1层为视网膜输入层,第m层的接受域的宽度为3,也就是说该层的每个单元与且仅与输入层的3个相邻的神经元相连,第m层与第m+1层具有类似的链接规则,如下图所示。
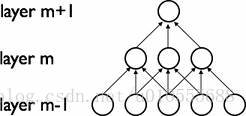
可以看到m+1层的神经元相对于第m层的接受域的宽度也为3,但相对于输入层的接受域为5,这种结构将学习到的过滤器(对应于输入信号中被最大激活的单元)限制在局部空间 模式(因为每个单元对它接受域外的variation不做反应)。从上图也可以看出,多个这样的层堆叠起来后,会使得过滤器(不再是线性的)逐渐成为全局的(也就是覆盖到了更 大的视觉区域)。例如上图中第m+1层的神经元可以对宽度为5的输入进行一个非线性的特征编码。
权值共享(Shared Weights)
在卷积网络中,每个稀疏过滤器hi通过共享权值都会覆盖整个可视域,这些共享权值的单元构成一个特征映射,如下图所示。
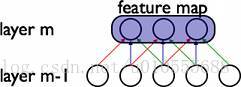
在图中,有3个隐层单元,他们属于同一个特征映射。同种颜色的连接权值是相同的.我们仍然可以使用梯度下降的方法来学习这些权值,只需要对原始算法做一些小的改动,这里共享权值的梯度是所有共享参数的梯度的总和。
我们不禁会问为什么要权重共享呢?一方面,重复单元能够对特征进行识别,而不考虑它在可视域中的位置。另一方面,权值 共享使得我们能更有效的进行特征抽取,因为它极大的减少了需要学习的自由变量的个数。通过控制模型的规模,卷积网络对视觉问题可以具有很好的泛化能力。
1. 神经网络
首先介绍神经网络,这一步的详细可以参考资源1。简要介绍下。神经网络的每个单元如下:

其对应的公式如下:

其中,该单元也可以被称作是Logistic回归模型。当将多个单元组合起来并具有分层结构时,就形成了神经网络模型。下图展示了一个具有一个隐含层的神经网络。

其对应的公式如下:

比较类似的,可以拓展到有2,3,4,5,…个隐含层。
神经网络的训练方法也同Logistic类似,不过由于其多层性,还需要利用链式求导法则对隐含层的节点进行求导,即梯度下降+链式求导法则,专业名称为反向传播。关于训练算法,本文暂不涉及。
2 卷积神经网络
在图像处理中,往往把图像表示为像素的向量,比如一个1000×1000的图像,可以表示为一个1000000的向量。在上一节中提到的神经网络中,如果隐含层数目与输入层一样,即也是1000000时,那么输入层到隐含层的参数数据为1000000×1000000=10^12,这样就太多了,基本没法训练。所以图像处理要想练成神经网络大法,必先减少参数加快速度。就跟辟邪剑谱似的,普通人练得很挫,一旦自宫后内力变强剑法变快,就变的很牛了。
2.1 局部感知
卷积神经网络有两种神器可以降低参数数目,第一种神器叫做局部感知野。一般认为人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。网络部分连通的思想,也是受启发于生物学里面的视觉系统结构。视觉皮层的神经元就是局部接受信息的(即这些神经元只响应某些特定区域的刺激)。如下图所示:左图为全连接,右图为局部连接。

在上右图中,假如每个神经元只和10×10个像素值相连,那么权值数据为1000000×100个参数,减少为原来的万分之一。而那10×10个像素值对应的10×10个参数,其实就相当于卷积操作。
2.2 参数共享
但其实这样的话参数仍然过多,那么就启动第二级神器,即权值共享。在上面的局部连接中,每个神经元都对应100个参数,一共1000000个神经元,如果这1000000个神经元的100个参数都是相等的,那么参数数目就变为100了。
怎么理解权值共享呢?我们可以这100个参数(也就是卷积操作)看成是提取特征的方式,该方式与位置无关。这其中隐含的原理则是:图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。
更直观一些,当从一个大尺寸图像中随机选取一小块,比如说 8x8 作为样本,并且从这个小块样本中学习到了一些特征,这时我们可以把从这个 8x8 样本中学习到的特征作为探测器,应用到这个图像的任意地方中去。特别是,我们可以用从 8x8 样本中所学习到的特征跟原本的大尺寸图像作卷积,从而对这个大尺寸图像上的任一位置获得一个不同特征的激活值。
如下图所示,展示了一个3×3的卷积核在5×5的图像上做卷积的过程。每个卷积都是一种特征提取方式,就像一个筛子,将图像中符合条件(激活值越大越符合条件)的部分筛选出来。

2.3 多卷积核
上面所述只有100个参数时,表明只有1个10*10的卷积核,显然,特征提取是不充分的,我们可以添加多个卷积核,比如32个卷积核,可以学习32种特征。在有多个卷积核时,如下图所示:

上图右,不同颜色表明不同的卷积核。每个卷积核都会将图像生成为另一幅图像。比如两个卷积核就可以生成两幅图像,这两幅图像可以看做是一张图像的不同的通道。如下图所示,下图有个小错误,即将w1改为w0,w2改为w1即可。下文中仍以w1和w2称呼它们。
下图展示了在四个通道上的卷积操作,有两个卷积核,生成两个通道。其中需要注意的是,四个通道上每个通道对应一个卷积核,先将w2忽略,只看w1,那么在w1的某位置(i,j)处的值,是由四个通道上(i,j)处的卷积结果相加然后再取激活函数值得到的。


所以,在上图由4个通道卷积得到2个通道的过程中,参数的数目为4×2×2×2个,其中4表示4个通道,第一个2表示生成2个通道,最后的2×2表示卷积核大小。
2.4 Down-pooling
在通过卷积获得了特征 (features) 之后,下一步我们希望利用这些特征去做分类。理论上讲,人们可以用所有提取得到的特征去训练分类器,例如 softmax 分类器,但这样做面临计算量的挑战。例如:对于一个 96X96 像素的图像,假设我们已经学习得到了400个定义在8X8输入上的特征,每一个特征和图像卷积都会得到一个 (96 − 8 + 1) × (96 − 8 + 1) = 7921 维的卷积特征,由于有 400 个特征,所以每个样例 (example) 都会得到一个 7921 × 400 = 3,168,400 维的卷积特征向量。学习一个拥有超过 3 百万特征输入的分类器十分不便,并且容易出现过拟合 (over-fitting)。
为了解决这个问题,首先回忆一下,我们之所以决定使用卷积后的特征是因为图像具有一种“静态性”的属性,这也就意味着在一个图像区域有用的特征极有可能在另一个区域同样适用。因此,为了描述大的图像,一个很自然的想法就是对不同位置的特征进行聚合统计,例如,人们可以计算图像一个区域上的某个特定特征的平均值 (或最大值)。这些概要统计特征不仅具有低得多的维度 (相比使用所有提取得到的特征),同时还会改善结果(不容易过拟合)。这种聚合的操作就叫做池化 (pooling),有时也称为平均池化或者最大池化 (取决于计算池化的方法)。

至此,卷积神经网络的基本结构和原理已经阐述完毕。
2.5 多层卷积
在实际应用中,往往使用多层卷积,然后再使用全连接层进行训练,多层卷积的目的是一层卷积学到的特征往往是局部的,层数越高,学到的特征就越全局化。
3 ImageNet-2010网络结构
ImageNet LSVRC是一个图片分类的比赛,其训练集包括127W+张图片,验证集有5W张图片,测试集有15W张图片。本文截取2010年Alex Krizhevsky的CNN结构进行说明,该结构在2010年取得冠军,top-5错误率为15.3%。值得一提的是,在今年的ImageNet LSVRC比赛中,取得冠军的GoogNet已经达到了top-5错误率6.67%。可见,深度学习的提升空间还很巨大。
下图即为Alex的CNN结构图。需要注意的是,该模型采用了2-GPU并行结构,即第1、2、4、5卷积层都是将模型参数分为2部分进行训练的。在这里,更进一步,并行结构分为数据并行与模型并行。数据并行是指在不同的GPU上,模型结构相同,但将训练数据进行切分,分别训练得到不同的模型,然后再将模型进行融合。而模型并行则是,将若干层的模型参数进行切分,不同的GPU上使用相同的数据进行训练,得到的结果直接连接作为下一层的输入。

上图模型的基本参数为:
- 输入:224×224大小的图片,3通道
- 第一层卷积:11×11大小的卷积核96个,每个GPU上48个。
- 第一层max-pooling:2×2的核。
- 第二层卷积:5×5卷积核256个,每个GPU上128个。
- 第二层max-pooling:2×2的核。
- 第三层卷积:与上一层是全连接,3*3的卷积核384个。分到两个GPU上个192个。
- 第四层卷积:3×3的卷积核384个,两个GPU各192个。该层与上一层连接没有经过pooling层。
- 第五层卷积:3×3的卷积核256个,两个GPU上个128个。
- 第五层max-pooling:2×2的核。
- 第一层全连接:4096维,将第五层max-pooling的输出连接成为一个一维向量,作为该层的输入。
- 第二层全连接:4096维
- Softmax层:输出为1000,输出的每一维都是图片属于该类别的概率。
4 DeepID网络结构
DeepID网络结构是香港中文大学的Sun Yi开发出来用来学习人脸特征的卷积神经网络。每张输入的人脸被表示为160维的向量,学习到的向量经过其他模型进行分类,在人脸验证试验上得到了97.45%的正确率,更进一步的,原作者改进了CNN,又得到了99.15%的正确率。
如下图所示,该结构与ImageNet的具体参数类似,所以只解释一下不同的部分吧。

上图中的结构,在最后只有一层全连接层,然后就是softmax层了。论文中就是以该全连接层作为图像的表示。在全连接层,以第四层卷积和第三层max-pooling的输出作为全连接层的输入,这样可以学习到局部的和全局的特征。
5 参考资源
- [1] http://deeplearning.stanford.edu/wiki/index.php/UFLDL%E6%95%99%E7%A8%8B 栀子花对Stanford深度学习研究团队的深度学习教程的翻译
- [2] http://blog.csdn.net/zouxy09/article/details/14222605 csdn博主zouxy09深度学习教程系列
- [3] http://deeplearning.net/tutorial/ theano实现deep learning
- [4] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C]//Advances in neural information processing systems. 2012: 1097-1105.
- [5] Sun Y, Wang X, Tang X. Deep learning face representation from predicting 10,000 classes[C]//Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on. IEEE, 2014: 1891-1898















 6879
6879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









