







机器学习实例
数据来源:
链接: https://pan.baidu.com/s/144ASMnonil7xF7u6mTWPRA
提取码: fnhb
数据不是真实的嗷,只是单纯练习
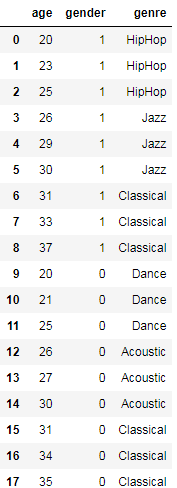
数据描述 gender:1代表男人,2代表女人
20-25岁的男人喜欢hiphop
20-25岁的女人喜欢dance 同理
#导入数据
import pandas as pd
#决策树
from sklearn.tree import DecisionTreeClassifier
music_data = pd.read_csv('music.csv')
#所有行和列都有值 不清理数据
#分割数据
#输入集
X = music_data.drop(columns=['genre'])
y = music_data['genre']
#建立模型
model = DecisionTreeClassifier()
model.fit(X, y)
predictions = model.predict([ [21,1] , [22, 0] ])
predictions
输出结果

测试模型准确性
import pandas as pd
#决策树
from sklearn.tree import DecisionTreeClassifier
#测量准确性
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
#导入数据
music_data = pd.read_csv('music.csv')
#所有行和列都有值 不清理数据
#分割数据
#输入集
X = music_data.drop(columns=['genre'])
y = music_data['genre']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
#建立模型
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
predictions = model.predict(X_test)
score = accuracy_score(y_test, predictions)
score
输出结果:不唯一
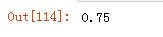
模型持久化
import pandas as pd
#决策树
from sklearn.tree import DecisionTreeClassifier
from sklearn.externals import joblib
music_data = pd.read_csv('music.csv')
#所有行和列都有值 不清理数据
#分割数据
#输入集
X = music_data.drop(columns=['genre'])
y = music_data['genre']
model = DecisionTreeClassifier()
model.fit(X, y)
joblib.load(model, 'music-recommender.joblib')
可视化一个决策树
import pandas as pd
#决策树
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
music_data = pd.read_csv('music.csv')
#所有行和列都有值 不清理数据
#分割数据
#输入集
X = music_data.drop(columns=['genre'])
y = music_data['genre']
model = DecisionTreeClassifier()
model.fit(X, y)
tree.export_graphviz(model, out_file='music-recommender.dot',
feature_names=['age','gender'],
class_names=sorted(y.unique()),
label='all',
rounded=True,
filled=True)
需要安装dot插件
















 300
300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









