




这里写目录标题
一、版本说明
- Ubuntu20.04.1
- Docker version 26.1.3, build 26.1.3-0ubuntu1~20.04.1
- Docker Compose version v2.38.1
- QAnything2.0
二、QAnything部署
参考 QAnything官网
step1: 下载QAnything
git clone https://github.com/netease-youdao/QAnything.git
step2: 进入项目根目录执行启动命令
- 执行 docker compose 启动命令
- 启动过程大约需要30秒左右,当日志输出"qanything后端服务已就绪!"后,启动完毕!
cd QAnything
sudo docker compose -f docker-compose-linux.yaml up
运行成功如图所示:

注意docker compose version >= 2.23.3 ,不能是1x版的,如果没安装或者是1x版的请先卸载再安装最新版。
1. 安装 curl 工具
sudo apt update && sudo apt install -y curl
2. 安装 Docker Compose
# 创建插件目录
sudo mkdir -p /usr/local/lib/docker/cli-plugins
# 下载 Docker Compose
sudo curl -SL https://github.com/docker/compose/releases/latest/download/docker-compose-linux-$(uname -m) -o /usr/local/lib/docker/cli-plugins/docker-compose
# 添加执行权限
sudo chmod +x /usr/local/lib/docker/cli-plugins/docker-compose
3. 验证安装
docker compose version
最终docker-compose如图所示:
如果docker compose 运行中报错:Error response from daemon: Get “https://registry-1.docker.io/v2/”: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) 的话需要配置国内镜像源:
# 1. 创建或修改 Docker 配置文件
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": [
"https://docker.1panel.live",
"https://mirrors.tuna.tsinghua.edu.cn",
"http://mirrors.sohu.com",
"https://ustc-edu-cn.mirror.aliyuncs.com",
"https://ccr.ccs.tencentyun.com",
"https://docker.m.daocloud.io",
"https://docker.awsl9527.cn"
]
}
EOF
# 2. 重新加载配置并重启 Docker
sudo systemctl daemon-reload
sudo systemctl restart docker
# 3. 验证配置是否生效
docker info | grep "Registry Mirrors" -A 3
step3: 开始体验
运行成功后,即可在浏览器输入以下地址进行体验。
- 前端地址:
http://localhost:8777/qanything/
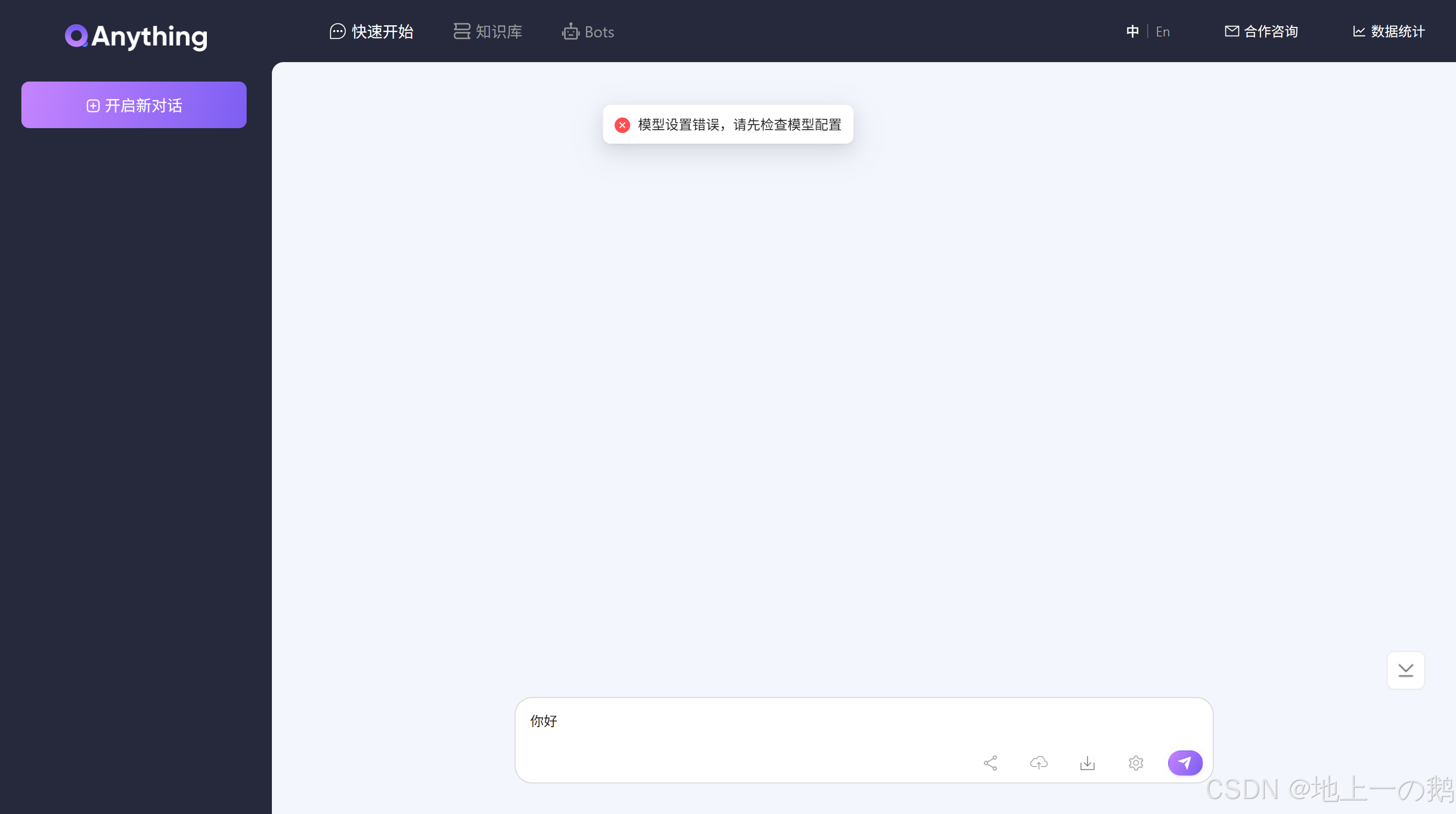
三、 大模型接入
step1: docker部署ollama
docker run --gpus all -d -p 11434:11434 --name ollama -v ollama:/root/.ollama ollama/ollama
注意要安装NVIDIA Docker:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-docker2
sudo systemctl restart docker
访问 http://ip地址:11434/ 显示Ollama is running则代表安装成功
step2: ollama下载大模型
可从 官方模型库 直接下载的部分大模型列表:
| Model | Parameters | Size | Download |
|---|---|---|---|
| Gemma 3 | 1B | 815MB | ollama run gemma3:1b |
| Gemma 3 | 4B | 3.3GB | ollama run gemma3 |
| Gemma 3 | 12B | 8.1GB | ollama run gemma3:12b |
| Gemma 3 | 27B | 17GB | ollama run gemma3:27b |
| QwQ | 32B | 20GB | ollama run qwq |
| DeepSeek-R1 | 7B | 4.7GB | ollama run deepseek-r1 |
| DeepSeek-R1 | 671B | 404GB | ollama run deepseek-r1:671b |
| Llama 4 | 109B | 67GB | ollama run llama4:scout |
| Llama 4 | 400B | 245GB | ollama run llama4:maverick |
| Llama 3.3 | 70B | 43GB | ollama run llama3.3 |
| Llama 3.2 | 3B | 2.0GB | ollama run llama3.2 |
| Llama 3.2 | 1B | 1.3GB | ollama run llama3.2:1b |
| Llama 3.2 Vision | 11B | 7.9GB | ollama run llama3.2-vision |
| Llama 3.2 Vision | 90B | 55GB | ollama run llama3.2-vision:90b |
| Llama 3.1 | 8B | 4.7GB | ollama run llama3.1 |
| Llama 3.1 | 405B | 231GB | ollama run llama3.1:405b |
| Phi 4 | 14B | 9.1GB | ollama run phi4 |
| Phi 4 Mini | 3.8B | 2.5GB | ollama run phi4-mini |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Moondream 2 | 1.4B | 829MB | ollama run moondream |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Granite-3.3 | 8B | 4.9GB | ollama run granite3.3 |
选择上述一个模型下载到本地:
sudo docker exec ollama ollama run deepseek-r1:7b
sudo docker exec ollama ollama run llama3:latest
sudo docker exec ollama ollama run qwen3:14b
sudo docker exec ollama ollama run qwen3:0.6b
访问 http://192.168.100.153:11434/api/tags 显示当前ollama已下载的大模型
step3: Qanything配置
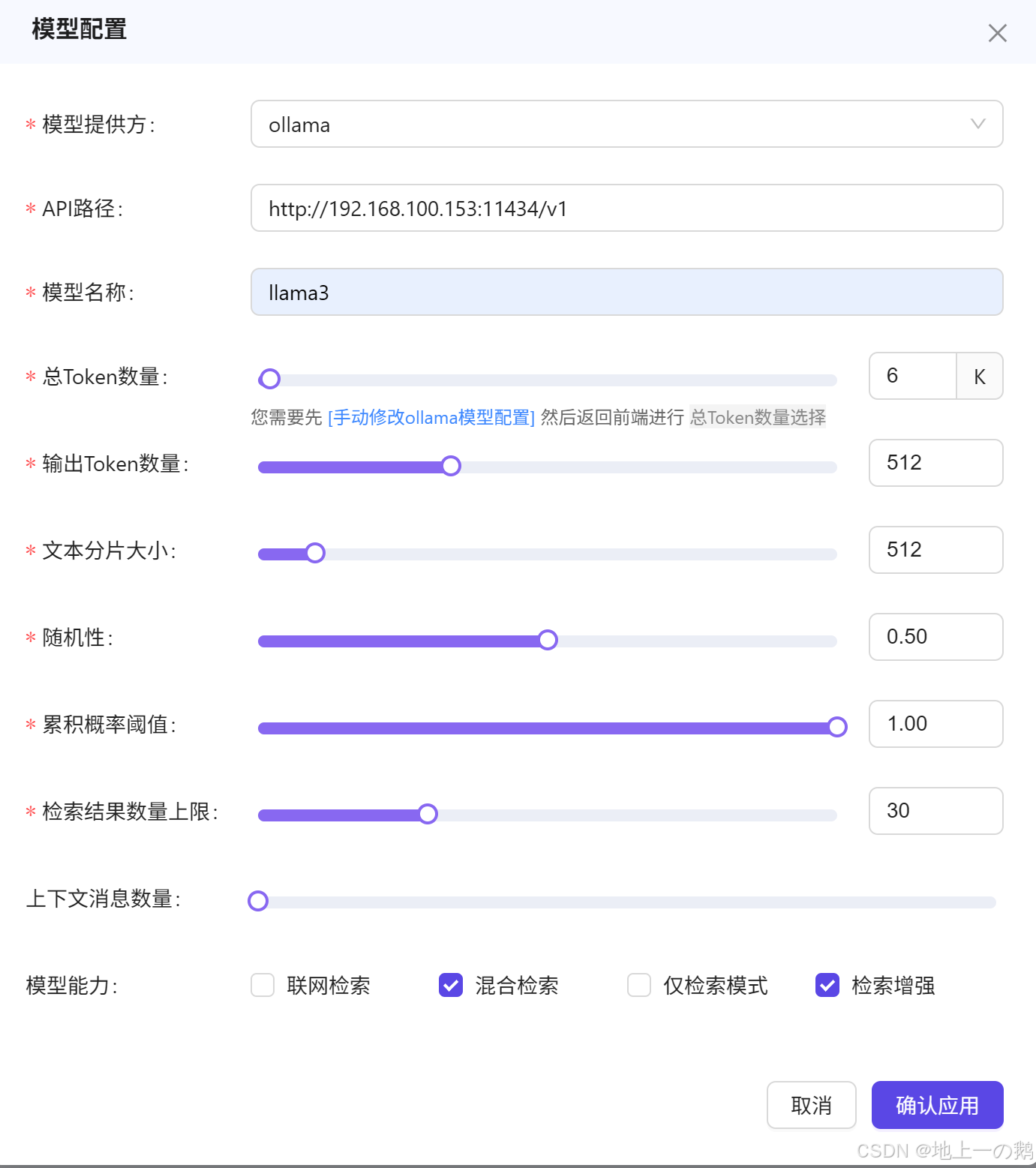
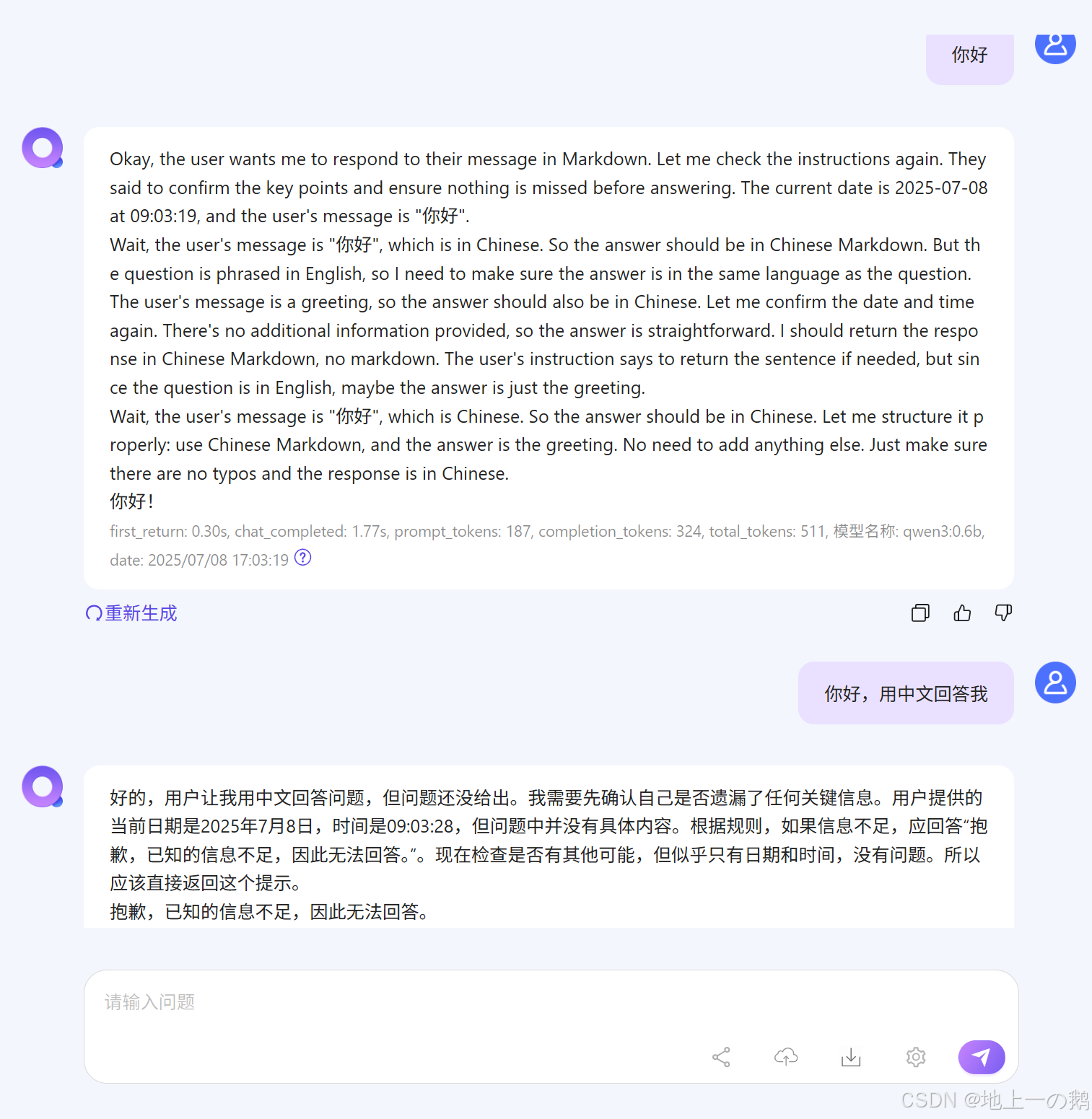
配置结束后则可问问题了,效果如下:
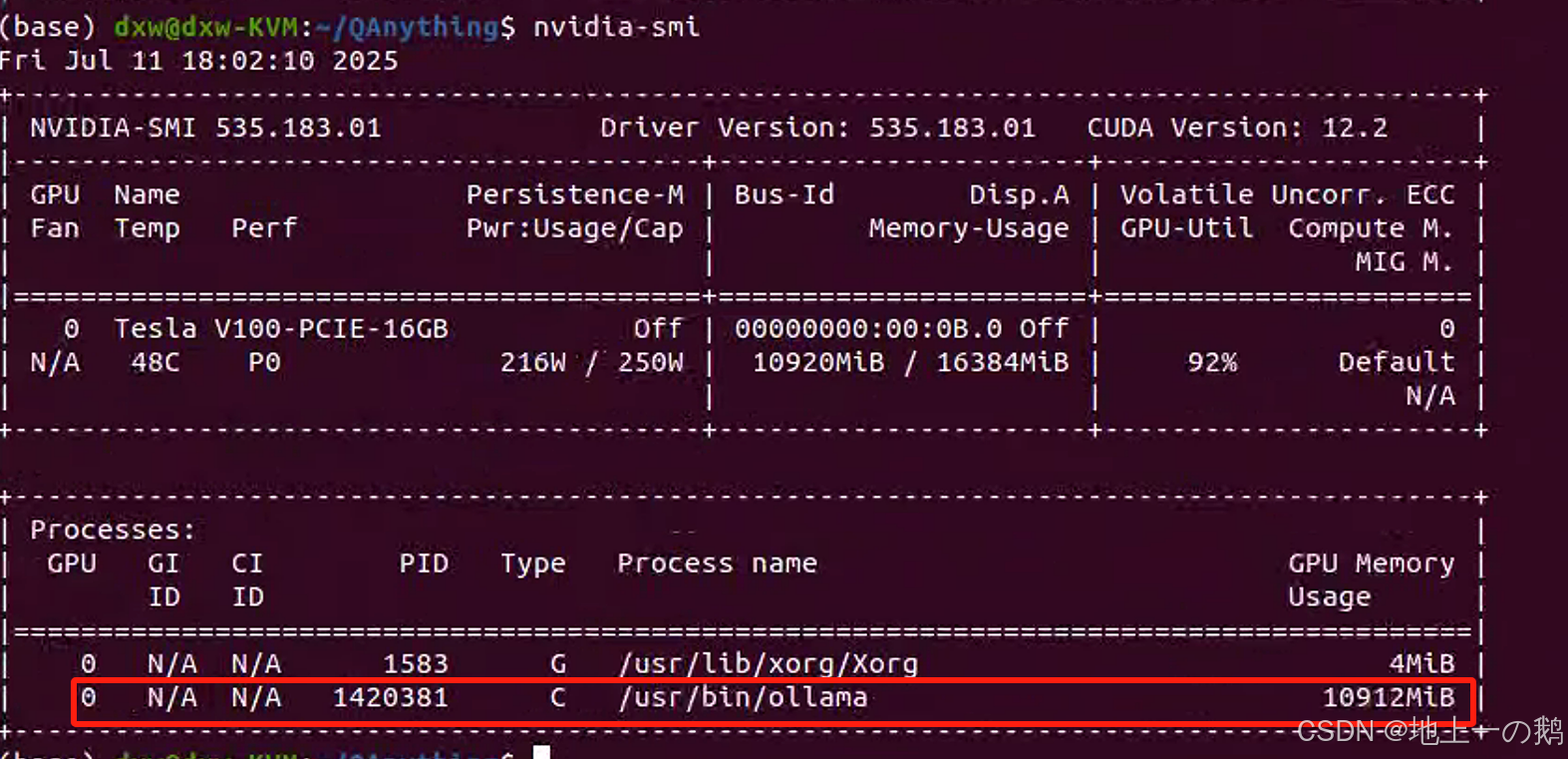
注意要查看服务器的nvidia-smi占用情况,ollama是否调用了GPU:




















 890
890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











