






环境:win11+wsl2+docker,但主要操作在wsl中完成
1.部署
建议创建一个文件夹用于存放后续文件,使用如下命令下载docker-compose.yml和config.json:
curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-pgvector.yml
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json在当前目录运行命令部署:
docker-compose pull
docker-compose up -d
使用浏览器访问localhost:3000验证,若部署成功则会进入fastgpt的登陆界面。
2.开始本地配置
先进入oneapi配置本地大模型接口,访问:localhost:3001,用户名root,密码123456,点击渠道:
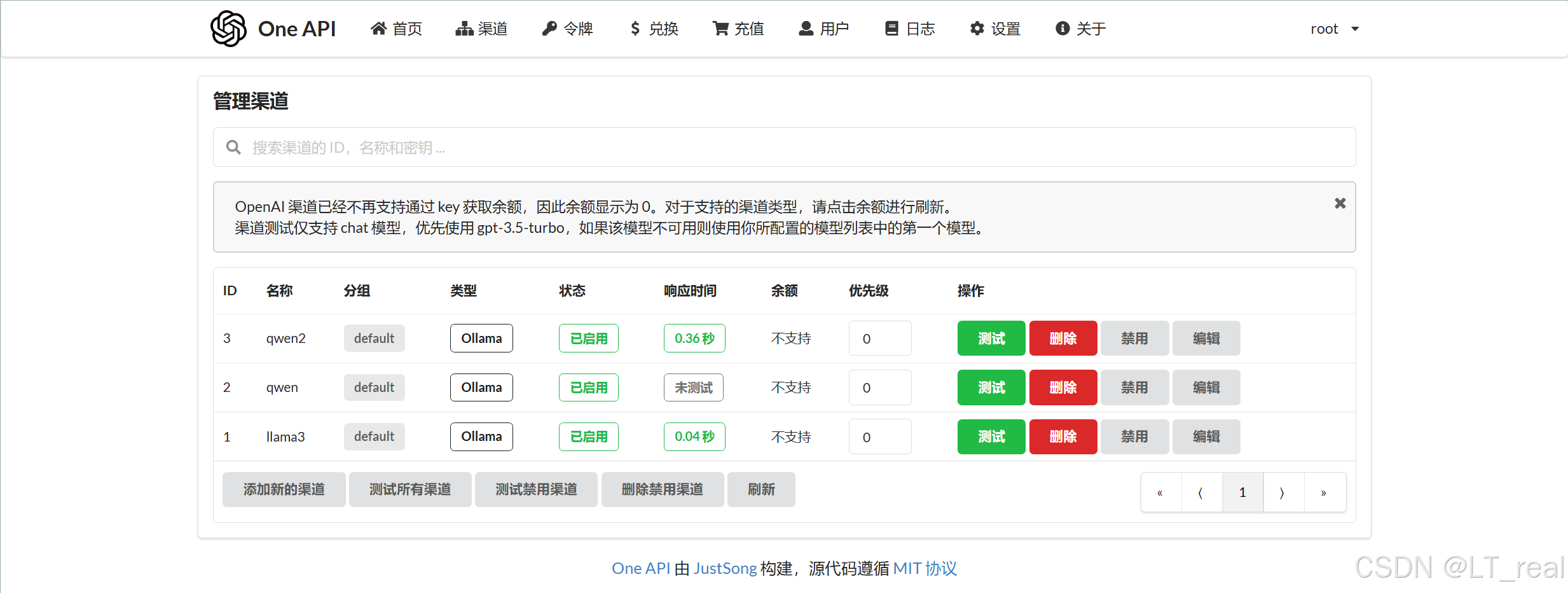
这里我已经导入了一些模型,但一般初始化是空的,我们点击添加渠道,填入自己本地大模型的信息:
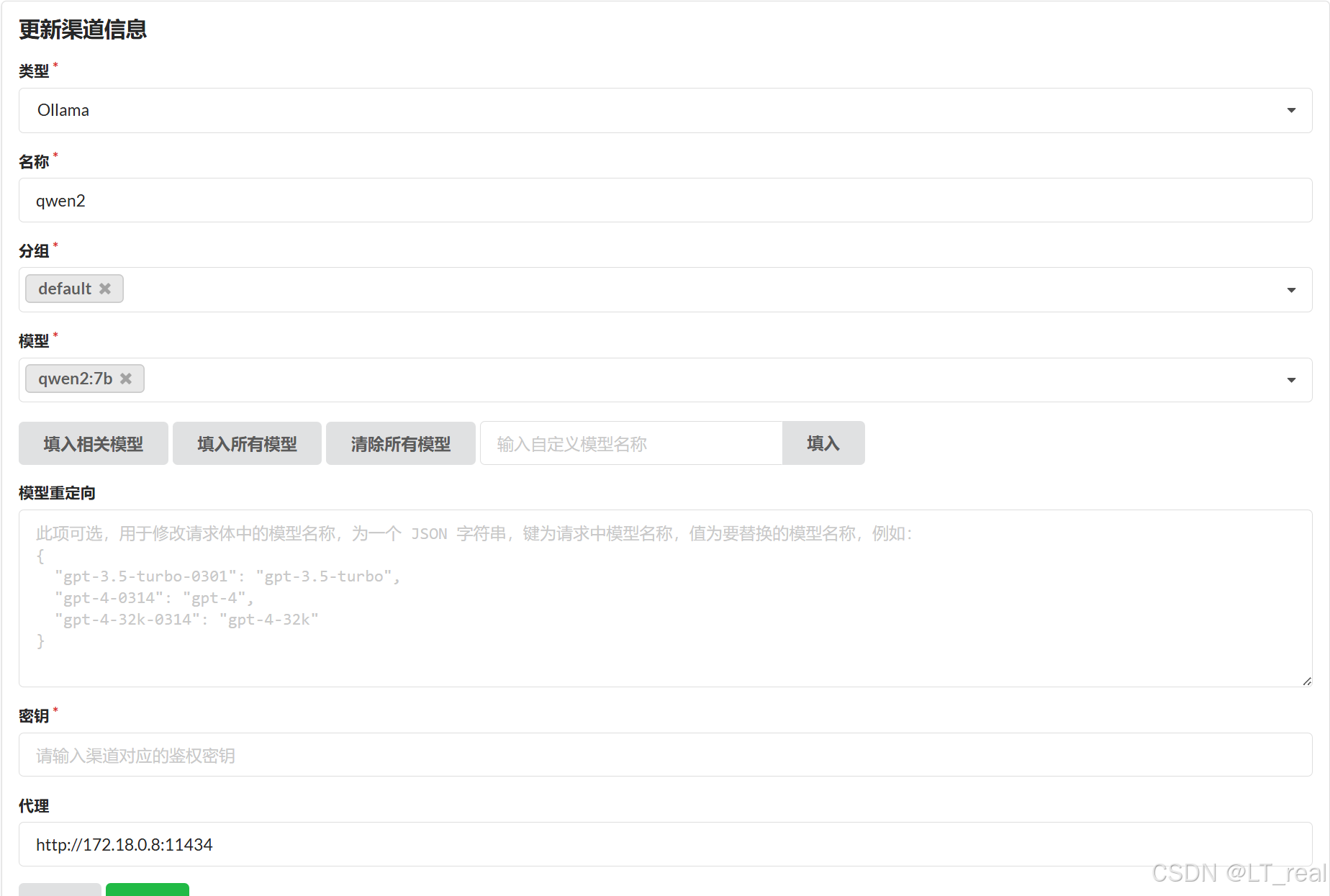
这里就得牵扯到上次本地部署qwen的知识了:使用docker通过ollama本地化部署qwen大模型-CSDN博客
在本地使用docker部署大模型后,ollama容器一般是单独处于一个bridge网络中,我们需要将他添加到fastgpt所在bridge网络:
docker network ls #查看当前所有网络
docker network inspect fastgpt_fastgpt #查看fastgpt所在网络中所有服务
docker network connect fastgpt_fastgpt ollama #将ollama容器加入到这个网络中最后结果如图所示:
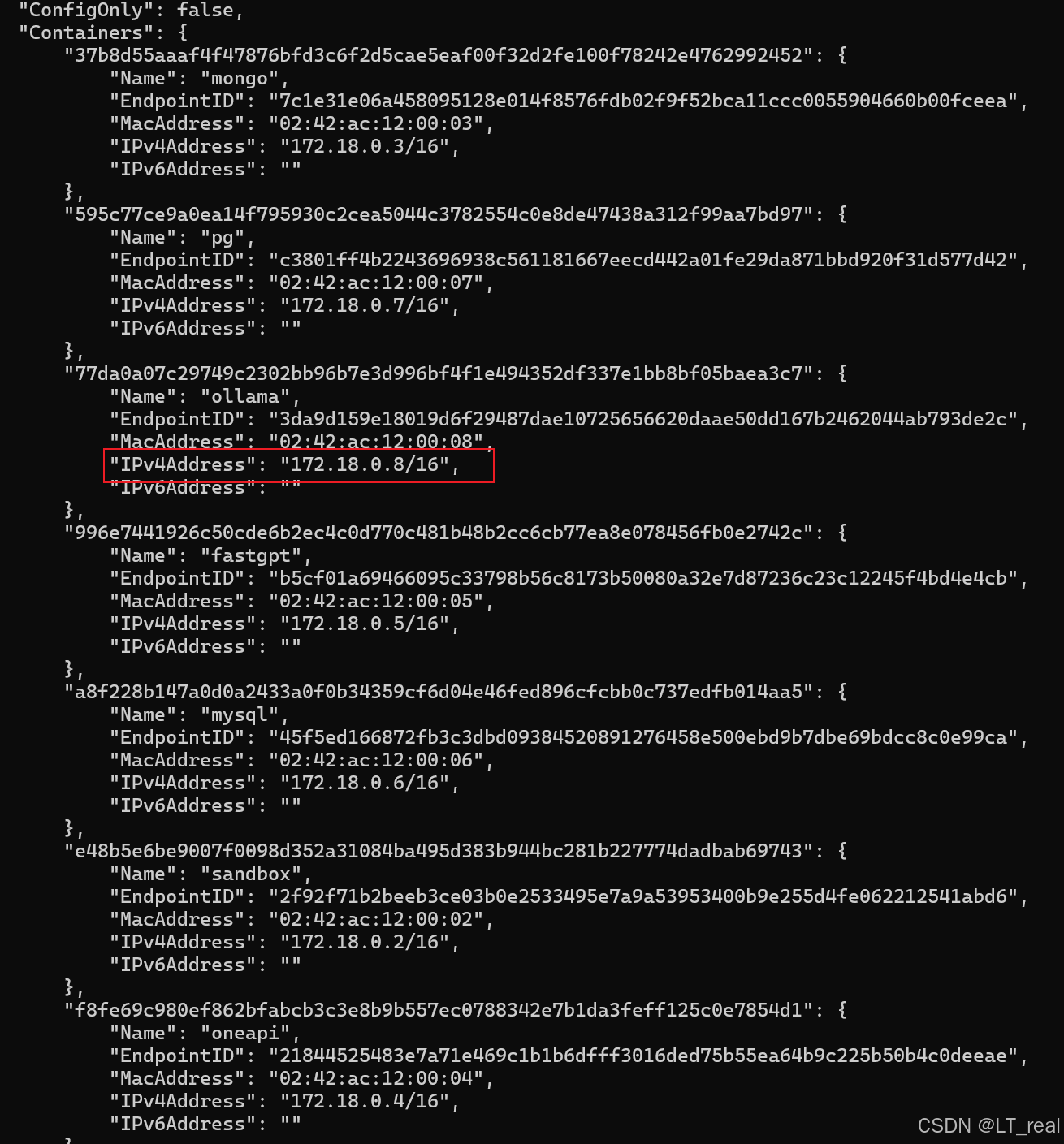
这个ip就是上面oneapi中访问本地大模型所用到的ip,点击测试看看是否工作:
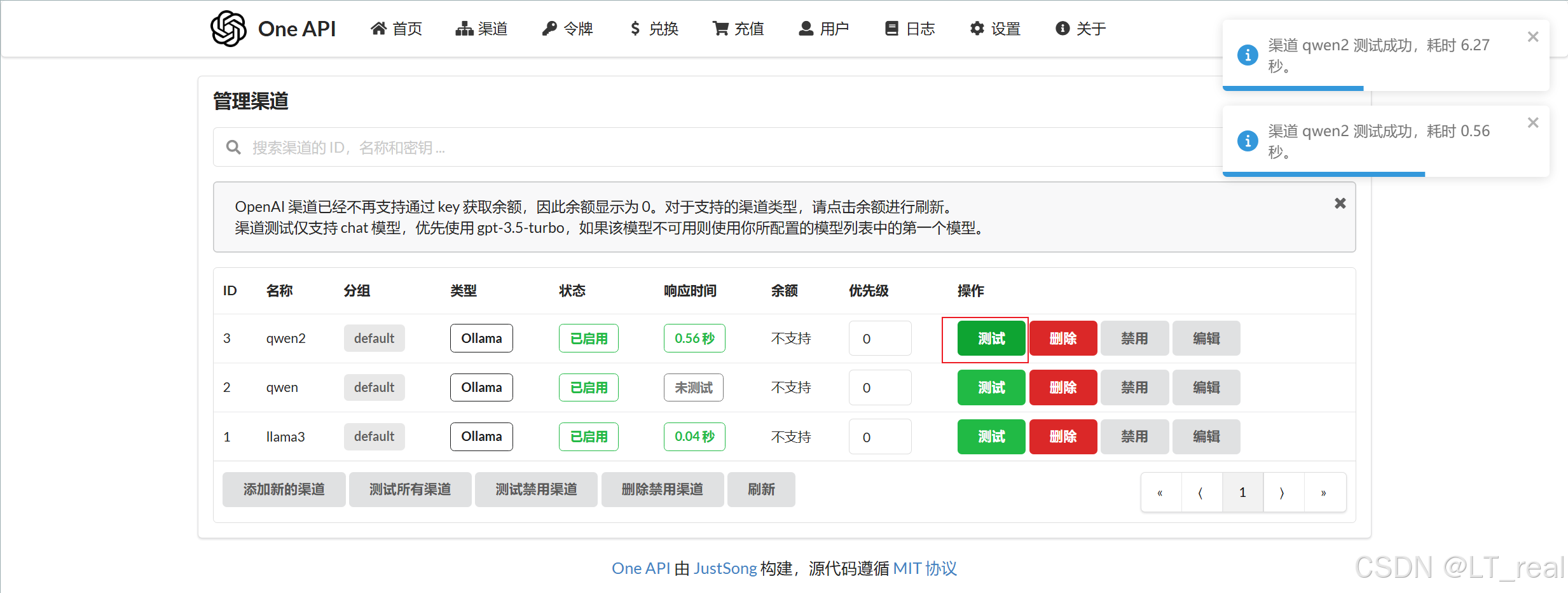
一般第一次会卡一点,后面就快了,现在我们要配置给fastgpt用的接口,点击令牌-添加:
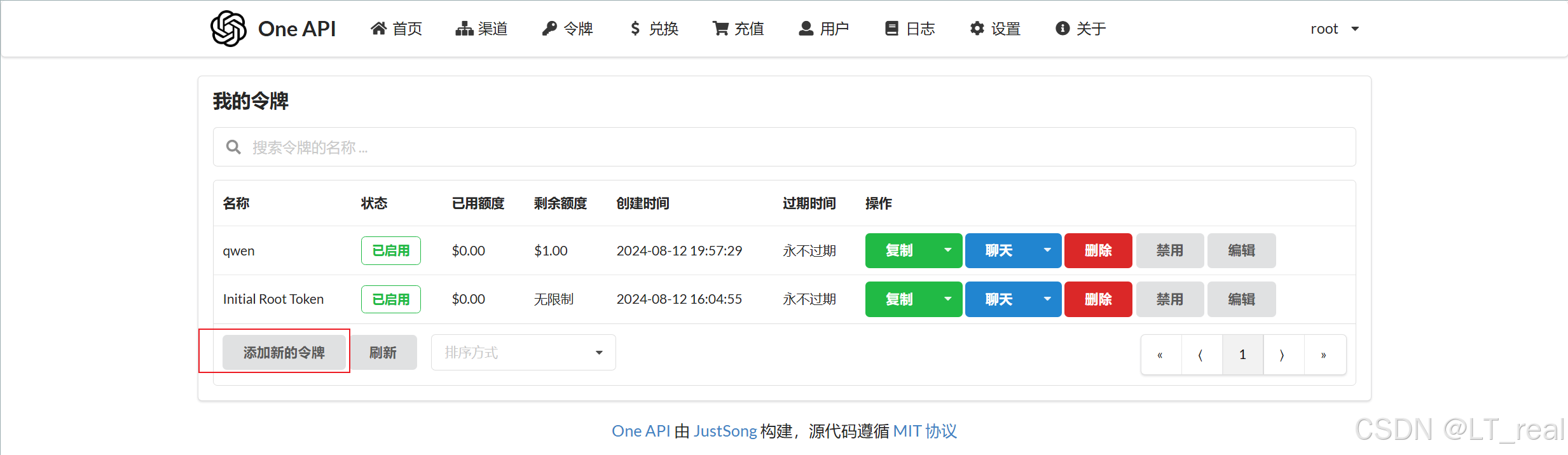
选择自己的本地大模型,我这里是qwen2:7b: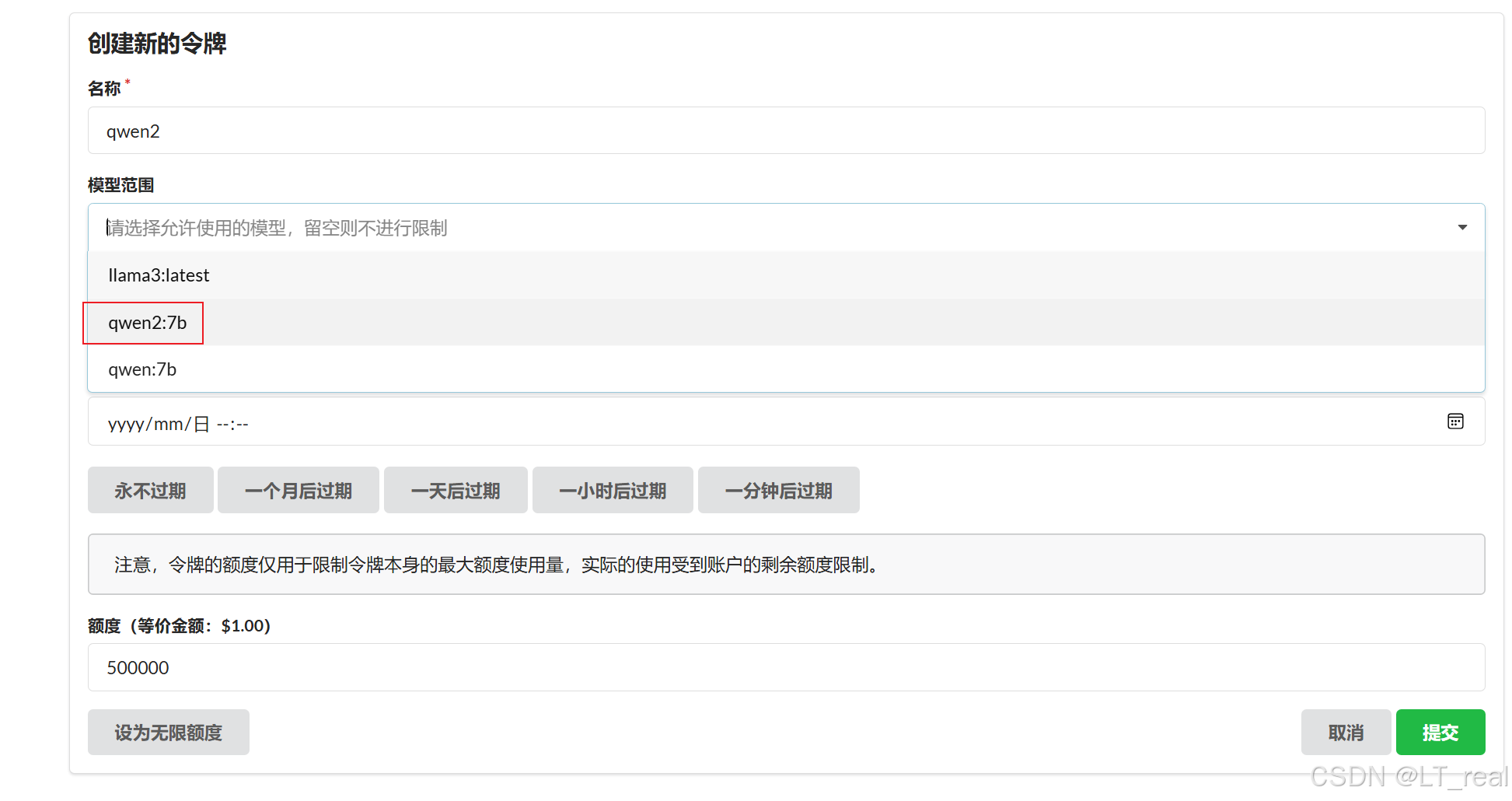
现在只需修改本地文件config.json即可:

一般只用修改这两行为你刚刚填写的模型名即可,使用docker restart重启oneapi、fastgpt。
3.验证
访问本地端口3000,进入fastgpt,创建新应用:
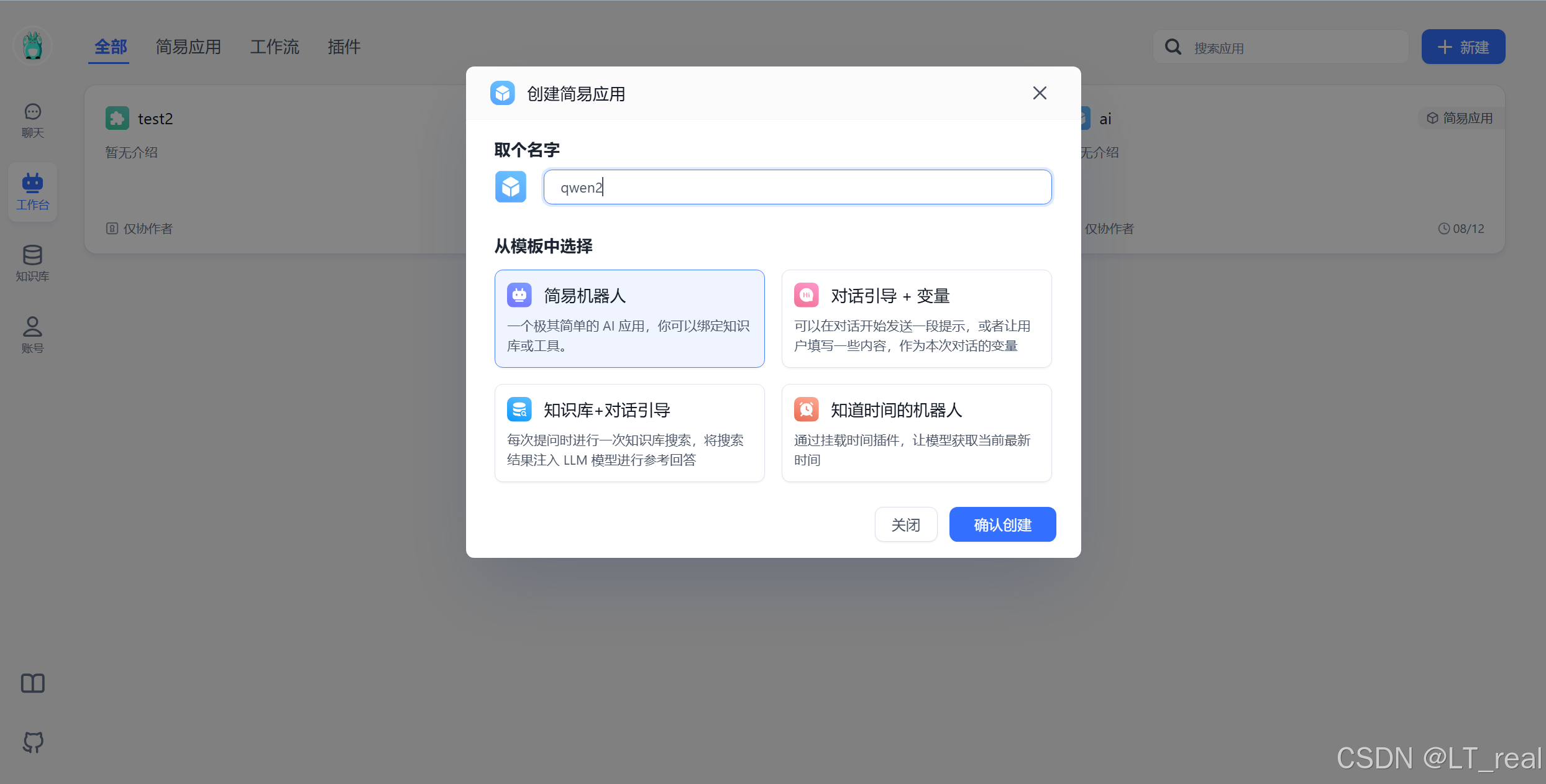
在这里选择你本地部署的大模型,最后发布即可:
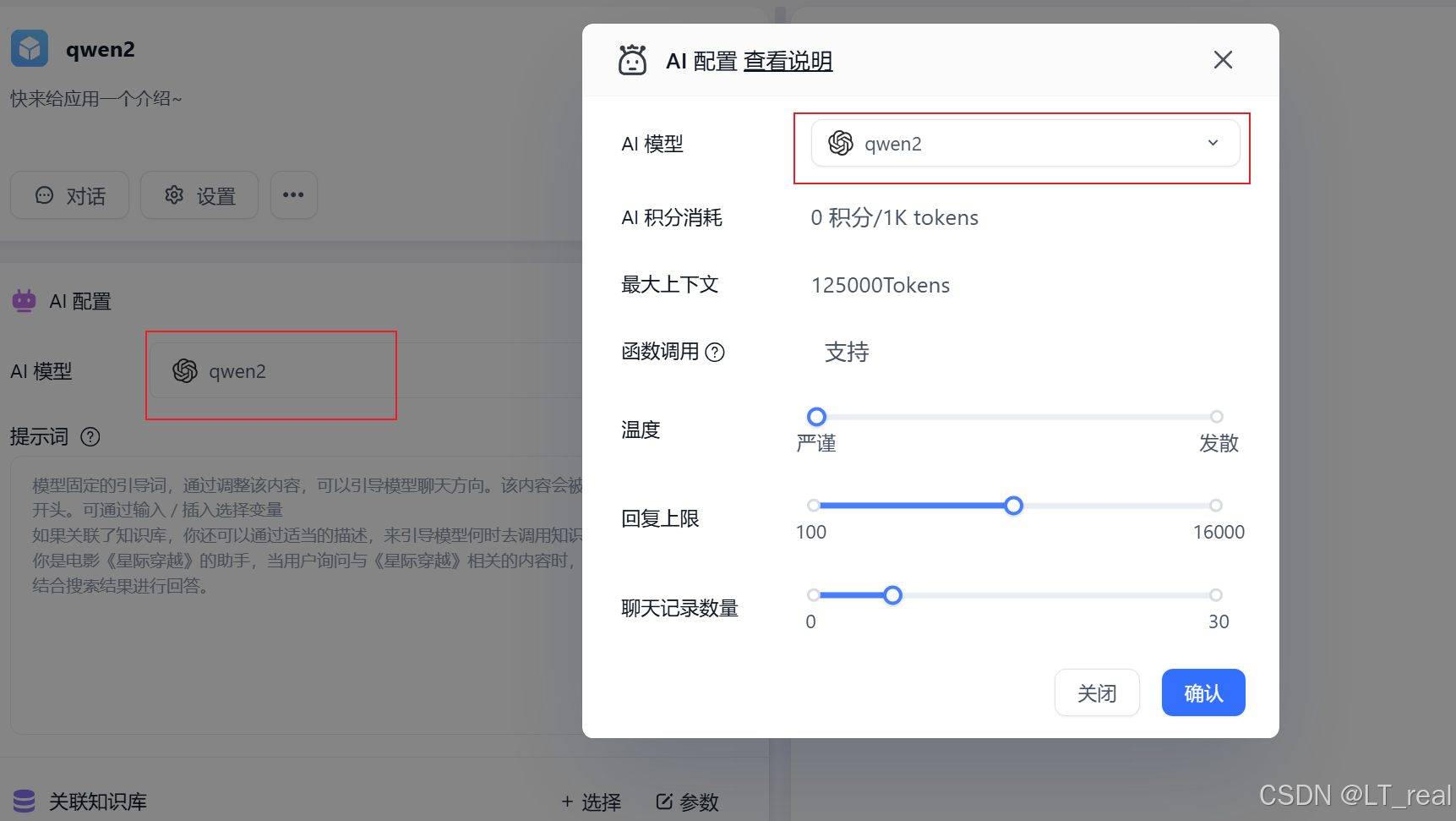
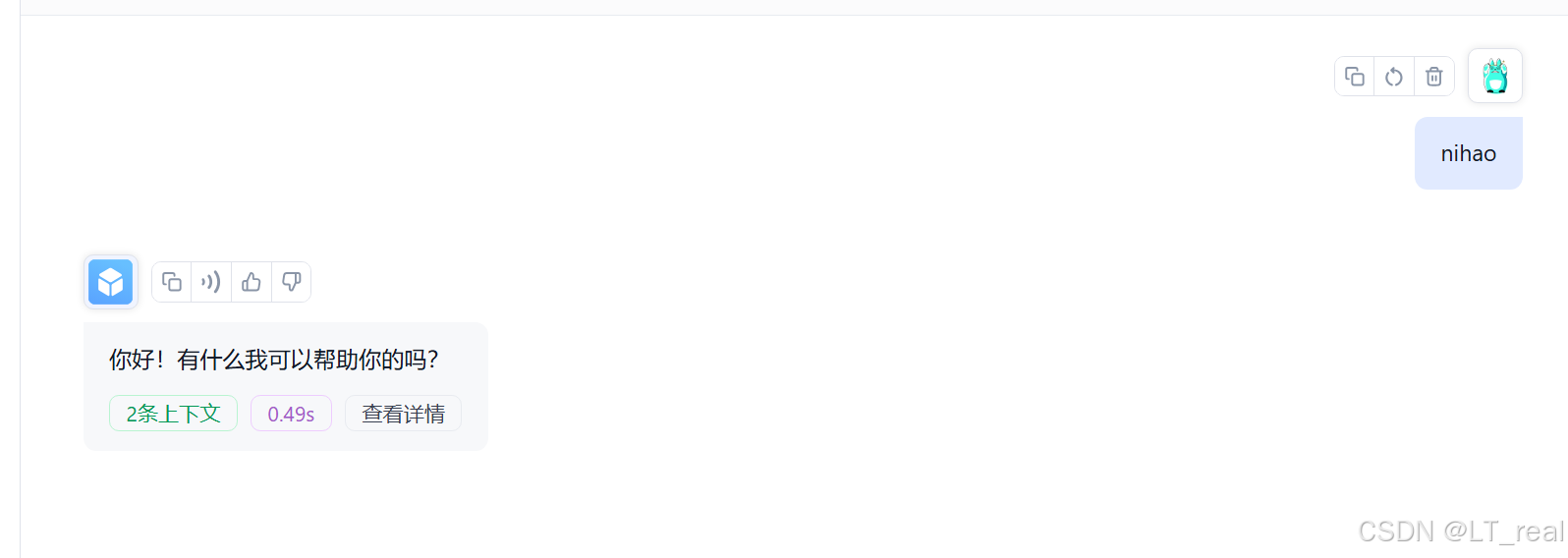
最后便可以在网页中进行对话:
PS
如果有奇怪的错误,可能是电脑内存溢出了(至少我这边大部分情况是,比如 该令牌无权使用模型、地址输入正确却无法访问等错误),建议重启电脑;
如果重启没用,费力调试后也没用,建议全删重装;
fastgpt中config.conf参数tools_choice关闭后,才能一定调用知识库检索。
参考
本地部署大模型?Ollama 部署和实战,看这篇就够了_ollama本地部署大模型-CSDN博客
保姆级教程:FastGPT构建个人本地知识库(Docker compose快速部署)_fastgpt本地部署-CSDN博客
本地部署FastGPT使用在线大语言模型_fastgpt本地部署教程-CSDN博客
ollama + fastgpt搭建本地私有AI大模型智能体工作流(AI Agent Flow)-- windows环境_fastgpt ollama-CSDN博客

















 901
901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









