









TextCNN的模型理论与应用实战
(一)说明
本文从理论与实践入手对TextCNN进行模型讲解与模型应用实战,理论方面对TextCNN进行模型解读,14年论文《Convolutional Neural Networks for Sentence Classification》给出了模型的基本结构,16年论文《A Sensitivity Analysis of (and Practitioner Guide to) Convolutional Neural Networks for Sent》中进行了大量的调参实验,给出了TextCNN进行文本分类时的相关建议。本文在这里不对论文进行详细解读,相关内容请查看目录2.5参考文献。实战方面将利用pytorch实现中文文本分类(参考),现附论文及项目链接。
1.《Convolutional Neural Networks for Sentence Classification》
2.《A Sensitivity Analysis of (and Practitioner Guide to) Convolutional Neural Networks for Sent》
3. pytorch实现TextCNN中文文本分类
(二)模型解读
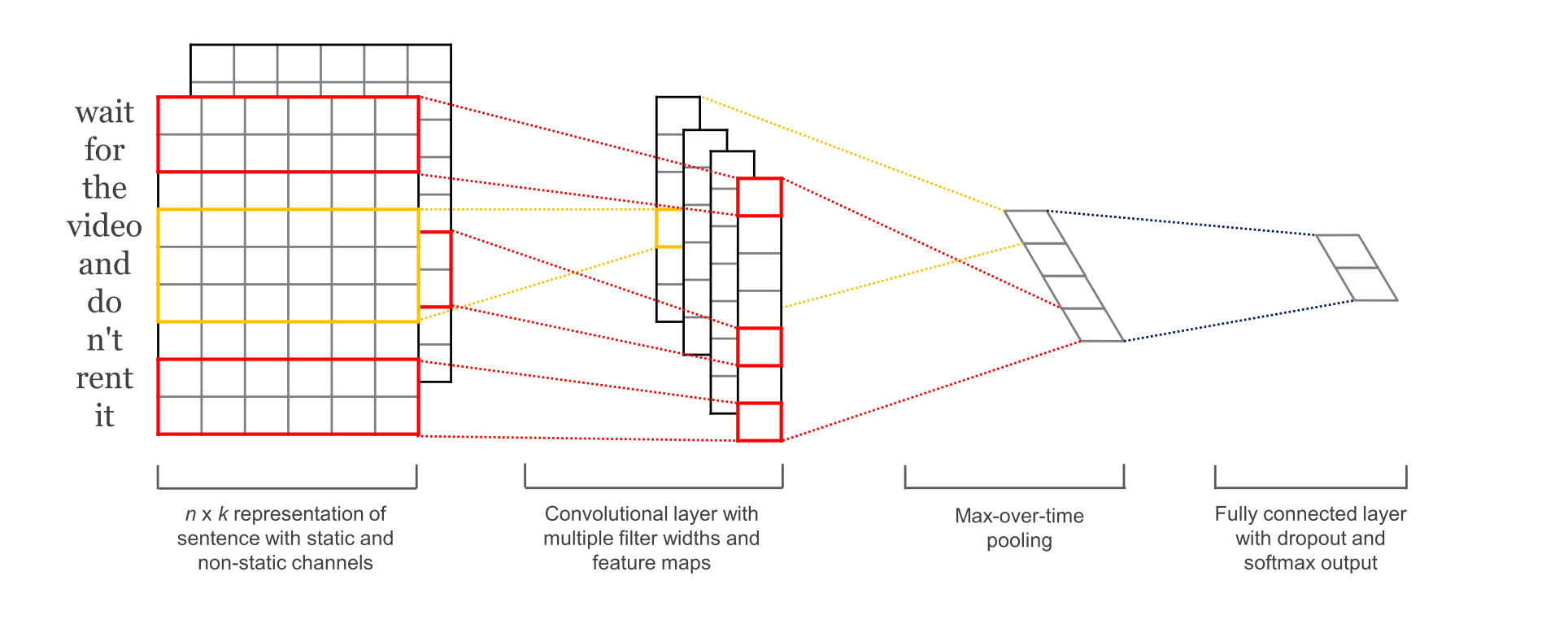 图1:来自《Convolutional Neural Networks for Sentence Classification》
图1:来自《Convolutional Neural Networks for Sentence Classification》

图2:来自《A Sensitivity Analysis of (and Practitioner Guide to) Convolutional Neural Networks for Sent》
模型结构示意图如上所示,整个模型结构可分为4层,输入层(嵌入层)、卷积层、最大池化层及全连接层,图2更为直观。
2.1输入层
如上图所示,模型的输入是由每个句子中词的词向量构成的矩阵所组成,矩阵的shape为N*K,其中K为词向量的长度,N为句子的长度。模型根据词向量的不同分为4种,CNN-rand、CNN-static、CNN-non-static、CNN-multichannel。
CNN-rand:所有的词向量都是随机初始化的,在训练过程中更新。
CNN-static:词向量用word2vec得出的结果,在整个train process中所有的words保持不变,只学习其他参数。
CNN-non-static:预训练的词向量在训练过程中要被微调。
CNN-multichannel:初始化时两个channel都直接赋值word2vec得出的结果,每个filter也会分别applied到两个channel,但是训练过程中只有一个channel会进行BP,即一组保持词向量不变,一组进行词向量微调。
对于没有出现在训练好的词向量表中的词(未登录词)的词向量,论文实验中采取的是使用随机初始化为0或者偏小的正数表示。
2.2卷积层
在卷积层中,使用Filter进行卷积操作得到Feature Map。实验中使用的3种类型大小的Filter,宽度分别是3,4,5,长度为词向量的维度大小。其中每种类型大小的Filter 有100个含有不同值的Filter。每一个Filter能从输入的矩阵中抽取出一个Feature Map。
从模型结构图中,第二层有4个Feature Map(经过卷积之后的结果),4个Feature Map是分别经过4个Filter卷积之后的结果,两个2*wordVector_dim(词向量维度)的Filter和两个3*wordVector_dim的Filter。每一个Filter分别作用于每个通道,并将结果相加进行卷积运算。
2.3池化层
池化采用1-max pooling,即将每个Feature Map向量中最大的一个值抽取出来,所有最大值组成一个一维向量。

更多关于Max Pooling(转载自张俊林博客)
2.4全连接层
池化操作后形成的一维向量作为全连接层的输入,再加上Dropout层防止过拟合。并在全连接层上添加l2正则化参数,经过SoftMax层作为输出层,进行分类。对于多分类问题可以使用SoftMax层,对于二分类问题可以使用一个含有sigmod激活函数的神经元作为输出层,实验中采用的是SoftMax层。
2.5参考文献
【1】《Convolutional Neural Networks for Sentence Classification》论文解读(推荐阅读:包含了作者对论文的认识并给出了论文翻译)
【2】论文笔记:A Sensitivity Analysis of Convolutional Neural Networks for Sentence Classification
【3】深度学习:TextCNN
(三)应用实战
掌握理论后,接下来就是利用模型跑个实验,项目使用pytorch实现,项目代码完全借鉴自TextCNN Pytorch实现 中文文本分类 情感分析(作为NLP小白,现阶段要好好研读别人的代码…),所以在后文给出的代码中,我会给出略为详细的注释,方便更好的理解代码,后文截取了些主要的代码段,并不是完整代码,完整代码请看github。
3.1工具包
- torchtext:在数据处理阶段,项目采用torchtext进行数据预处理,torchtext是一文本处理神器,可以方便的对文本进行预处理,例如截断补长、构建词表等,使用pip install torchtext可直接进行安装,关于torchtext的文档与教程附在这里。
torchtext文档
[TorchText]使用
pytorch学习笔记(十九):torchtext - jieba:jieba是中文分词工具,需要给句子进行分词操作,pip install jieba可进行安装。
- 预训练的中文词向量:CNN-static和CNN-multichannel需要使用预训练的中文词向量,项目使用Zhihu_QA 知乎问答(点击直接下载)训练出来的word Word2vec
3.2数据预处理
数据集在data文件里已经给出,要用到train.tsv和dev.tsv

使用torchtext对数据集进行处理:
- 设定text_field和label_field两个field。定义以及参数含义看上面的文档或教程。
import torchtext.data as data
print('Loading data...')
//使用torchtext.data
text_field = data.Field(lower=True)
label_field = data.Field(sequential=False)
train_iter, dev_iter = load_dataset(text_field, label_field, args, device=-1, repeat=False, shuffle=True)
- load_dataset数据加载函数,load_word_vectors词向量加载函数。
from torchtext.vocab import Vectors
//加载预训练的词向量
def load_word_vectors(model_name, model_path):
//使用torchtext.vocab的Vectors
vectors = Vectors(name=model_name, cache=model_path)
return vectors
//加载数据:args接收命令行参数,**kwargs接收键值对: device=-1, repeat=False, shuffle=True
def load_dataset(text_field, label_field, args, **kwargs):
//1、加载数据语料
train_dataset, dev_dataset = dataset.get_dataset('data', text_field, label_field)
// 查看dataset长什么样子
// for i in range(0,3):
// print(dev_dataset[i].text)
// print(dev_dataset[i].label)
// print('=======')
//2、构建词表,根据命令行参数判断是否使用预训练词向量,True的话则加载词向量
if args.static and args.pretrained_name and args.pretrained_path:
vectors = load_word_vectors(args.pretrained_name, args.pretrained_path)
text_field.build_vocab(train_dataset,dev_dataset,vectors=vectors)
// 查看text_field词汇表
// print(text_field.vocab.stoi)
else:
text_field.build_vocab(train_dataset, dev_dataset)
label_field.build_vocab(train_dataset, dev_dataset)
//3、构建迭代器
train_iter, dev_iter = data.Iterator.splits(
(train_dataset, dev_dataset),
batch_sizes=(args.batch_size, len(dev_dataset)),
sort_key=lambda x: len(x.text),
**kwargs)
// 查看batch啥样
// batch = next(iter(train_iter))
// print(batch)
// print("batch_text:",batch.text)
// print("batch_label:",batch.label)
return train_iter, dev_iter
- get_dataset加载数据语料。
//正则匹配非中文和字母数字
regex = re.compile(r'[^\u4e00-\u9fa5aA-Za-z0-9]')
def word_cut(text):
//将非中文和字母及数字的字符替换为空格
text = regex.sub(' ', text)
//对句子进行分词,空格字符不要
return [word for word in jieba.cut(text) if word.strip()]
def get_dataset(path, text_field, label_field):
//torchtext的用法tokenize 表示如何对文本进行分割
text_field.tokenize = word_cut
//通过 torchtext.data.Dataset 的类方法 splits 加载我们的数据语料
train, dev = data.TabularDataset.splits(
path=path, format='tsv', skip_header=True,// 如果tsv有表头, 确保这个表头不会作为数据处理
train='train.tsv', validation='dev.tsv',
fields=[
('index', None),
('label', label_field),
('text', text_field)
]
)
return train, dev
3.3模型定义
模型构建过程中,max-pooling直接在foward中使用,注释标出了tensor流动时的shape以及一些函数的作用。
import torch
import torch.nn as nn
import torch.nn.functional as F
//模型参数:
//batch-size:128
//dropout:0.5
//embedding-dim:300
//filter-num:100
//filter-size:345
class TextCNN(nn.Module):
def __init__(self, args):
super(TextCNN, self).__init__()
self.args = args
//label数量
class_num = args.class_num
chanel_num = 1
filter_num = args.filter_num
filter_sizes = args.filter_sizes
vocabulary_size = args.vocabulary_size
embedding_dimension = args.embedding_dim
//输入层
self.embedding = nn.Embedding(vocabulary_size, embedding_dimension)
if args.static:
// 加载预训练的词向量,freeze使词向量不更新
self.embedding = self.embedding.from_pretrained(args.vectors, freeze=not args.non_static)
if args.multichannel:
//加一个通道,此通道可更新权重
self.embedding2 = nn.Embedding(vocabulary_size, embedding_dimension).from_pretrained(args.vectors)
chanel_num += 1
else:
self.embedding2 = None
//卷积层
self.convs = nn.ModuleList(
[nn.Conv2d(chanel_num, filter_num, (size, embedding_dimension)) for size in filter_sizes])
self.dropout = nn.Dropout(args.dropout)
//全连接层
self.fc = nn.Linear(len(filter_sizes) * filter_num, class_num)
def forward(self, x):
//x的shape为128*L,即batch-size*L,L为序列长度
//embedding之后 变为128*L*300
if self.embedding2:
//此时x的shape为128*2*L*300,stack将两个序列合并
x = torch.stack([self.embedding(x), self.embedding2(x)], dim=1)
else:
// x:128*L*300
x = self.embedding(x)
//x:128*1*L*300
x = x.unsqueeze(1)
//conv输入:[ batch_size, channels, L, Dim ]
x = [F.relu(conv(x)).squeeze(3) for conv in self.convs] //x:len(Ks)*(batch_size,channels,L1)
// (因为卷积核的维度与词向量一样所以最后一维会变成1,用squeeze将其去掉,此时L1是卷积之后向量的长度)
x = [F.max_pool1d(item, item.size(2)).squeeze(2) for item in x] //x: len(Ks)*(batch_size,channels)
//将不同size池化后的结果拼接在一起
x = torch.cat(x, 1) //(batch_size,channels*len(Ks))
x = self.dropout(x)
logits = self.fc(x)
return logits
【torch.stack()用法】
【torch.cat()用法】
【torch.nn.Conv2d()函数详解】
3.4训练与评估
def train(train_iter, dev_iter, model, args):
if args.cuda:
model.cuda()
optimizer = torch.optim.Adam(model.parameters(), lr=args.lr)
steps = 0
best_acc = 0
last_step = 0
model.train()
for epoch in range(1, args.epochs + 1):
for batch in train_iter:
//feature:len*128(L*batch)
// target:1*128
feature, target = batch.text, batch.label
//feature:128*len
feature.data.t_(), target.data.sub_(1)
if args.cuda:
feature, target = feature.cuda(), target.cuda()
optimizer.zero_grad()
logits = model(feature)
//cross_entropy target为样本标签
loss = F.cross_entropy(logits, target)
loss.backward()
optimizer.step()
steps += 1
if steps % args.log_interval == 0:
corrects = (torch.max(logits, 1)[1].view(target.size()).data == target.data).sum()
train_acc = 100.0 * corrects / batch.batch_size
sys.stdout.write(
'\rBatch[{}] - loss: {:.6f} acc: {:.4f}%({}/{})'.format(steps,
loss.item(),
train_acc,
corrects,
batch.batch_size))
if steps % args.test_interval == 0:
dev_acc = eval(dev_iter, model, args)
if dev_acc > best_acc:
best_acc = dev_acc
last_step = steps
if args.save_best:
print('Saving best model, acc: {:.4f}%\n'.format(best_acc))
save(model, args.save_dir, 'best', steps)
else:
if steps - last_step >= args.early_stopping:
print('\nearly stop by {} steps, acc: {:.4f}%'.format(args.early_stopping, best_acc))
raise KeyboardInterrupt
def eval(data_iter, model, args):
model.eval()
corrects, avg_loss = 0, 0
for batch in data_iter:
feature, target = batch.text, batch.label
feature.data.t_(), target.data.sub_(1)
if args.cuda:
feature, target = feature.cuda(), target.cuda()
logits = model(feature)
loss = F.cross_entropy(logits, target)
avg_loss += loss.item()
corrects += (torch.max(logits, 1)
[1].view(target.size()).data == target.data).sum()
size = len(data_iter.dataset)
avg_loss /= size
accuracy = 100.0 * corrects / size
print('\nEvaluation - loss: {:.6f} acc: {:.4f}%({}/{}) \n'.format(avg_loss,
accuracy,
corrects,
size))
return accuracy
模型保存:
def save(model, save_dir, save_prefix, steps):
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
save_prefix = os.path.join(save_dir, save_prefix)
save_path = '{}_steps_{}.pt'.format(save_prefix, steps)
torch.save(model.state_dict(), save_path)
3.5结果
CNN-rand:

CNN-static:

CNN-non-static:

CNN-multichannel:

(四)总结
博主是NLP小白,这也是第一次写博客,想通过理论+实战的方法更好的理解模型,学习模型。之前一直不喜欢写博客,觉得很浪费时间…其实现在知道这些记录和归纳是必要的,希望自己再接再厉吧。















 474
474











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









