






1 数据准备:
def read_files(filetype):
all_labels = [1]*12500 + [0]*12500
all_texts = []
file_list = []
path = r'./aclImdb/'
# 读取正面文本名
pos_path = path + filetype + '/pos/'
for file in os.listdir(pos_path):
file_list.append(pos_path+file)
# 读取负面文本名
neg_path = path + filetype + '/neg/'
for file in os.listdir(neg_path):
file_list.append(neg_path+file)
# 将所有文本内容加到all_texts
for file_name in file_list:
with open(file_name, encoding='utf-8') as f:
all_texts.append(rm_tags(" ".join(f.readlines())))
return all_texts, all_labels
2 数据处理:
通过keras的tokenizer建立一个包含数据集中所有单词的索引,例如数据集中包含单词(‘中国’,‘美国’,‘中国’,‘英国’,‘日本’,‘法国’,’比‘,’厉害‘),通过tokenizer生成{‘中国’:1,‘美国’:2,‘英国’:3,‘日本’:4,‘法国’:5,’比‘:6,’厉害‘:7},在文本出现次数越多的词语 越靠前(其实就是用一个数字来代表原来的词语,方便计算)
tokenizer = Tokenizer(num_words=2000) # 建立一个2000个单词的字典
tokenizer.fit_on_texts(train_texts) x_train_seq = tokenizer.texts_to_sequences(train_texts)
x_test_seq = tokenizer.texts_to_sequences(test_texts)大家可能已经发现了序列化后,由于每句话的词语个数不一样,所以每一个序列都不等长,这样神经网络的输入边无法确定,所以人们经常用包含词语数目最多的句子长度作为输入长度maxlen,其他不够输入长度的默认自动补0,形成shape为(句子数目,maxlen)的矩阵
x_train = sequence.pad_sequences(x_train_seq, maxlen=150)
x_test = sequence.pad_sequences(x_test_seq, maxlen=150)3 textcnn模型
我所理解的各种模型都是通过cnn rnn(lstm)等基本模型组合起来,参数也不一样,构建一个新的模型,达到了较好的结果。本文主要介绍textcnn模型
def text_cnn(maxlen=150, max_features=2000, embed_size=32):
# Inputs
comment_seq = Input(shape=[maxlen], name='x_seq') #定义输入层 一般输入为一个句子的词语数目,即一个样本序列的长度
# Embeddings layers
emb_comment = Embedding(max_features, embed_size)(comment_seq) #嵌入层 下文做详细介绍
# conv layers
convs = []
filter_sizes = [2, 3, 4, 5] #不同卷积核的大小
for fsz in filter_sizes:
l_conv = Conv1D(filters=100, kernel_size=fsz, activation='relu')(emb_comment) #现长度 = 1+(原长度-卷积核大小+2*填充层大小) /步长 卷积核的形状(fsz,embedding_size)
l_pool = MaxPooling1D(maxlen - fsz + 1)(l_conv) # 这里面最大的不同 池化层核的大小与卷积完的数据长度一样
l_pool = Flatten()(l_pool) #一般为卷积网络最近全连接的前一层,用于将数据压缩成一维
convs.append(l_pool)
merge = concatenate(convs, axis=1)
out = Dropout(0.5)(merge)
output = Dense(32, activation='relu')(out)
output = Dense(units=1, activation='sigmoid')(output)
model = Model([comment_seq], output)
# adam = optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0)
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=['accuracy'])
return model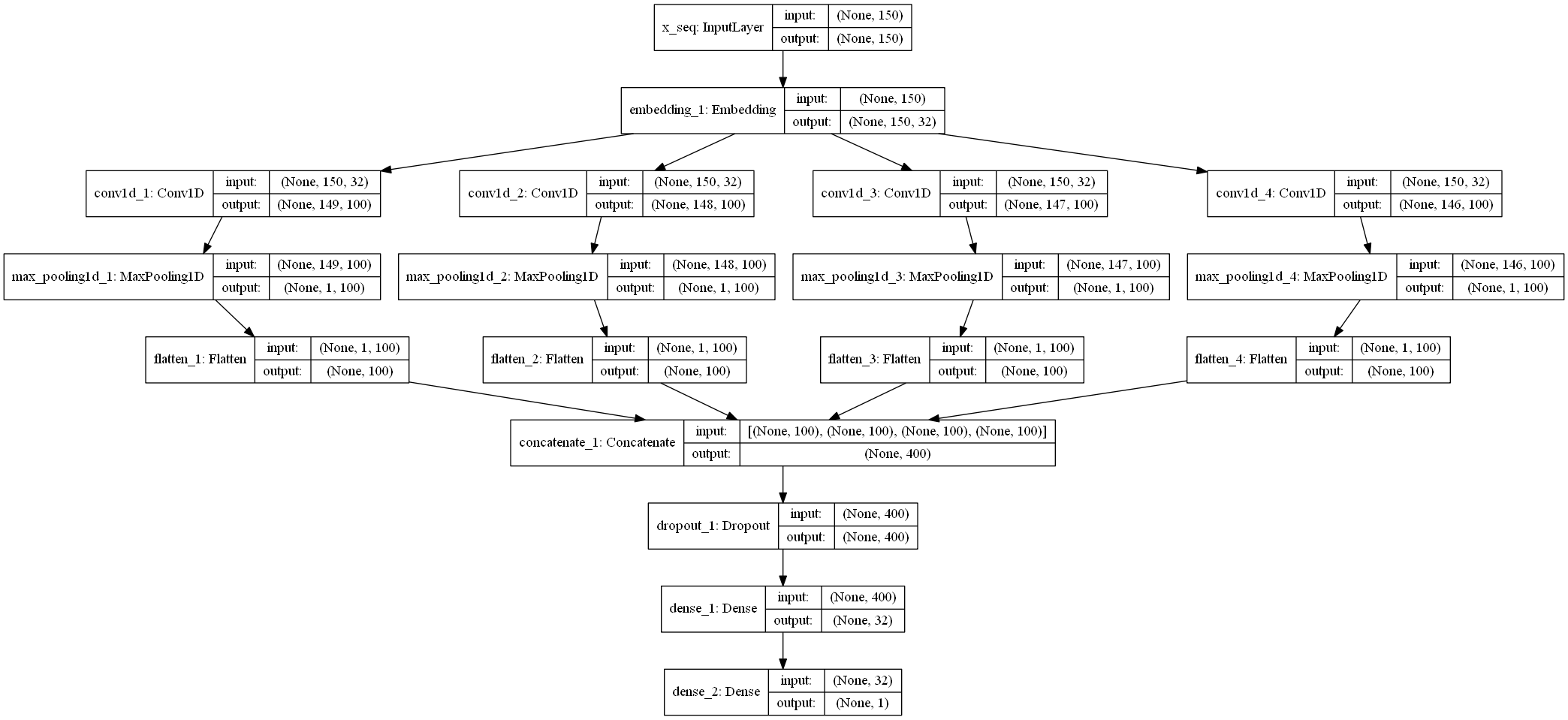
模型结构如上图所示
textcnn运行图:

最后解释下embedding层 前面已知 中国比美国厉害 的序列为【1,6,2,7】,embedding层将1用一个32维的向量表示,所以中国比美国厉害最后的数据形状为(4,32),这层其实就相当与一个word2vec,将一个one-hot编码的数据输入,得到一个包含32个神经元的隐藏层,输出该输入周围窗口的词语的one-hot编码
最终准确率:
















 1454
1454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









