







 本文讲述了作者为了了解在线教育课程质量,尝试爬取腾讯课堂IT互联网类别下的课程评论。通过解析网页结构,逐步解析学习方向、课程分类和评论,最终成功获取动态加载的评论数据。
本文讲述了作者为了了解在线教育课程质量,尝试爬取腾讯课堂IT互联网类别下的课程评论。通过解析网页结构,逐步解析学习方向、课程分类和评论,最终成功获取动态加载的评论数据。
最近想了解一下在线教育的课程的如何去选择,课程的质量如何?所以试着去爬了一下腾讯课堂,只爬了IT互联网这一项。
通过分析发现要想爬取到评论需要是个步骤:

通过开发者工具审查元素,发现标签在<dl class="sort-menu sort-menu1 clearfix">下
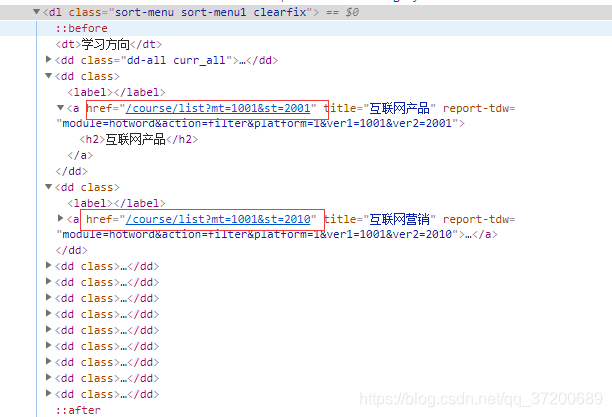
然后去写解析代码:
· # _pattern表示解析href的正则表达式
def get_menu_link(self, url, _pattern):
headers = {
'user-agent': self.round_header()
}
start = time.perf_counter()
res = self.s.get(url, headers=headers)
if res is None:
return
content = res.text
menu_pattern = re.compile(r'<dl class="sort-menu sort-menu1 clearfix">(.*?)</dl>', re.S)
menu = re.findall(menu_pattern, content)
link_paternt = re.compile(_pattern, re.S | re.M)
if len(menu) != 0:
links = re.findall(link_paternt, menu[0])
end = time.perf_counter()
_time = end - start
print('{0}解析成功,共耗时:{1:f}s'.format(url, _time))
for item in links:
item = item.replace('&', '&')
link = 'https://ke.qq.com{0}'.format(item)
yield link
else:
end = time.perf_counter()
_time = end - start
print('{0}解析失败!!!,共耗时:{1:f}s'.format(url, _time))
return None
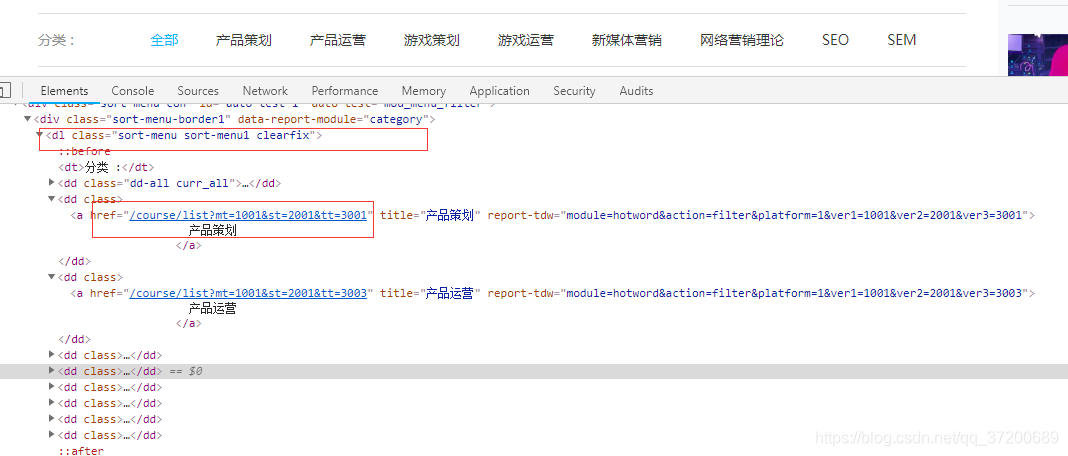
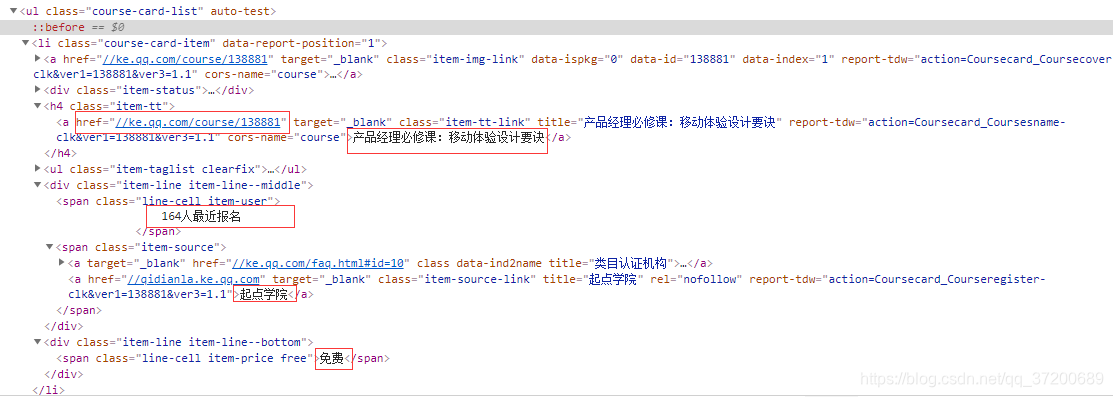
解析代码如下:
def get_course_list(self, url):
headers = {
'user-agent': self.round_header()
}
start = time.perf_counter()
res = self.s.get(url, headers=headers)
if res is None:
return
content = res.text
course_card_list_pattern = re.compile(r'<ul class="course-card-list.+?">\s+(.+)\s+</ul>', re.S)
course_card_list = re.findall(course_card_list_pattern, content)
course_list_pattern = re.compile(r'<li class= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2267
2267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









