



翻页爬取腾讯课堂课程用户昵称和评论
爬取过程:
1.找到目标的url
2.构造请求头参数
3.发送请求,获取响应
4.解析数据
5.保存数据
下面会对其中的细节进行讲解
本次案例需要注意的点
1.我们发现在请求头部分只添加User-Agent是无法完成的,因此我们需要将Referer和Cookie添加上(毕竟是腾讯课堂,爬取数据需要尊重一下)
2.解析数据时,可以把响应的json数据放在JSON在线解析中,查看目的数据所在的节点,从而使用jsonpath的语法提取。
3.保存数据时,将多条数据写入到文件中的方式为“a追加”的方式。
开始爬取的步骤:
首先找到目标的url,这里英语好的同学可以看到course_commet_state这个选项,对应的就是评论的url。
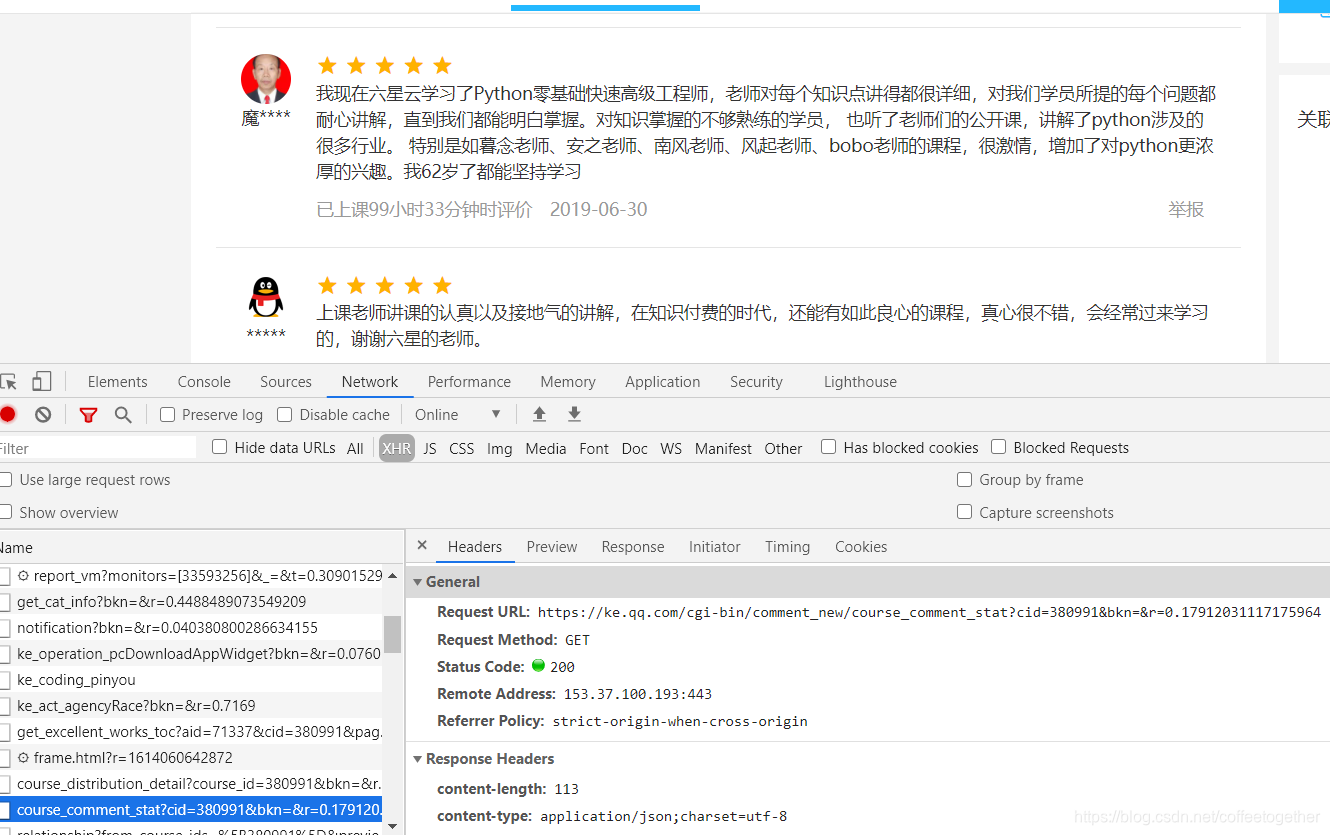
检查响应是否为我们需要的数据:
寻找不同页的url的规律(这里是前三页的url):



我们拿前三页的url进行比较,可以得出不同页的url差别在于参数page和r的不同。
url参数分析:
参数page:第一页的page=0;第二页的page=1,第三页的page=2,因此我们for循环的翻页规律也就显而易见,我们直接令page = i 即可(因为for循环i是从0开始的)
参数r:通过尝试我发现r的值对于获取响应没有影响,因此我们可以将参数r删去
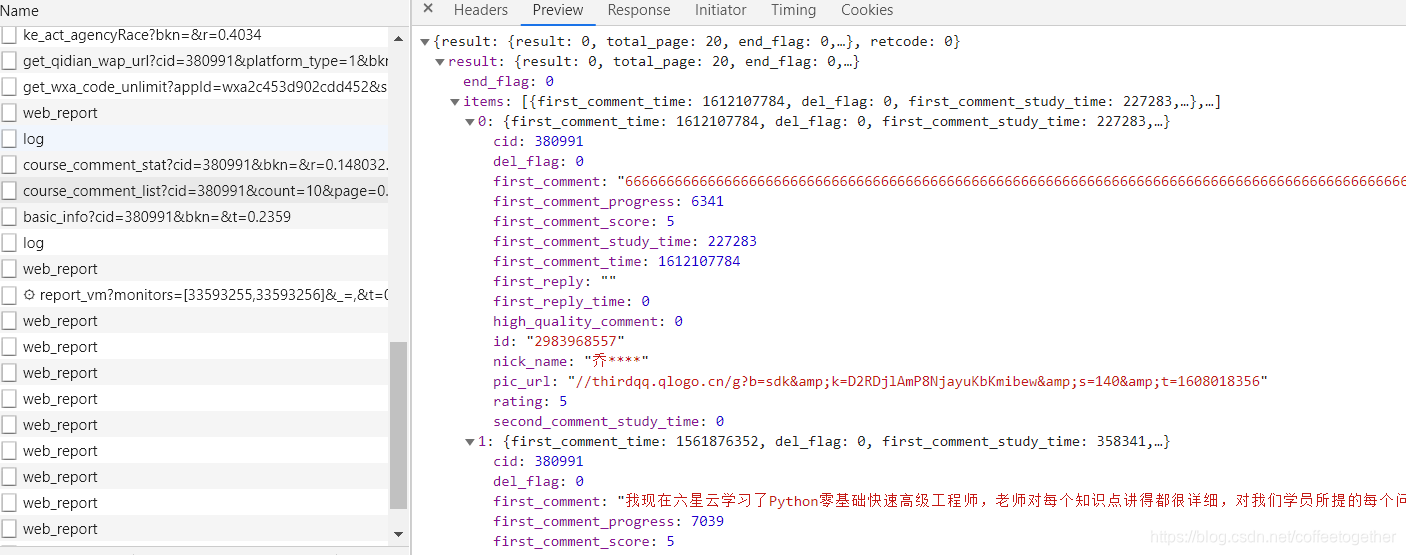
通过JSON解析,找到昵称和评论所在的节点:

翻页规律和解析方法已经明确,开始我们的代码:
import requests
import jsonpath
import json
if __name__ == '__main__':
# 输入要爬取的页数
pages = int(input('请输入要爬取的页数:'))
for i in range(pages):
page = i
# 确认目标的url
url = f'https://ke.qq.com/cgi-bin/comment_new/course_comment_list?cid=380991&count=10&page={page}&filter_rating=0&bkn='
# 构造请求头参数
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36',
'Referer':'https://ke.qq.com/course/380991?taid=3687813539549247',
'Cookie':'ts_refer=www.baidu.com/link; pgv_pvid=3055310294; ts_uid=2118064280; _pathcode=0.6180368297569794; tdw_auin_data=-; tdw_data_testid=; tdw_data_flowid=; iswebp=1; tdw_first_visited=1; pgv_info=ssid=s8062796281; Hm_lvt_0c196c536f609d373a16d246a117fd44=1613135091,1613135096,1614057330; ts_last=ke.qq.com/course/380991; tdw_data={"ver4":"www.baidu.com","ver5":"","ver6":"","refer":"www.baidu.com","from_channel":"","path":"ah-0.6180368297569794","auin":"-","uin":"","real_uin":""}; Hm_lpvt_0c196c536f609d373a16d246a117fd44=1614057466; tdw_data_new_2={"auin":"-","sourcetype":"","sourcefrom":"","uin":"","visitor_id":"5804772510395988"}'
}
# 发送请求,获取响应
response = requests.get(url,headers=headers)
# 将json数据转换成py数据
py_data = response.json()
# 提取目标数据:1.用户昵称,2.用户评论
nick_name_list = jsonpath.jsonpath(py_data,'$..nick_name')
comment_list = jsonpath.jsonpath(py_data,'$..first_comment')
# 将数据放入字典,然后转换成json格式保存
for i in range(len(nick_name_list)):
dict_ = {}
dict_[nick_name_list[i]] = comment_list[i]
# 将字典转换成json格式
json_data = json.dumps(dict_,ensure_ascii=False)+',\n'
# 将数据保存到本地
with open('翻页爬取腾讯课堂课程评论.json','a',encoding='utf-8')as f:
f.write(json_data)
检查一下结果:我们爬取了3页评论(共30条)

这次案例与我上次写的一篇"翻页爬取豆瓣电影名称和评分"相类似,大家可以参考一下。


















 3409
3409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











