










这篇文章发表在2011的CGO上, 该文章提出的技术是利用两阶段分析完成对百万行代码的流敏感指针分析技术。
核心技术要点为:
- 分阶段分析: 利用一个快速且保守的流不敏感指针分析,启用一个流敏感指针分析。
- 稀疏分析: 加速数据流分析
(即: 构造MemorySSA,在此之上进行稀疏指针分析)
该文章提出的指针分析技术是流敏感,上下文不敏感的。
1. 解决什么问题
(1) 已有的分析大多都是流不敏感,上下文不敏感的。作者想做流敏感指针分析,提升精度的同时,性能也不会有太大的问题 (标题的含义:Flow-Sensitive的同时,scale到百万行代码)
(2) 已有的流敏感分析方法是稠密分析(dense),即沿着cfg节点transfer IN/OUT数据流信息。稠密分析速度不够,作者想利用稀疏分析,加速流敏感指针分析。(稀疏分析在传播数据流信息的时候能够跳过不相关的节点,从而加速分析)
(3) 然而LLVM IR并没有提供足够的稀疏IR(LLVM IR是partial SSA),并不能够直接做完全稀疏的指针分析。在partial SSA只能够对top-level变量做稀疏分析,而对address-token变量做稠密的迭代数据流分析,这也叫半稀疏(·semi-sparse·)指针分析[1]。作者希望做完全稀疏的指针分析。
(1)(2)(3)实际上都是为了达成流敏感,稀疏指针分析的目标。其中流敏感可以提升分析精度,稀疏可以提升分析速度。
1.1 partial SSA简要
LLVM IR是partial SSA,即将变量分为两组:一组是top-level变量,另一组是address-token变量。在进行SSA构造的时候只考虑top-level变量。
它基于这样的一个事实:如果一个变量被取地址了,那么就保守地认为它可能会被某些指针间接的修改,于是不将它转换为SSA形式,这种分组方法是保守且安全的(毕竟追踪那个引用该变量地址的指针开销会比较大,干脆可以直接保守地认为它可能会被间接修改,所以不将其划为SSA变量)。
所以针对下图的代码,可以扫描一遍直接找到address-token变量{a, b, c, d}:

2. 怎么解决
2.1 大的框架
如下图所示,是作者大的框架
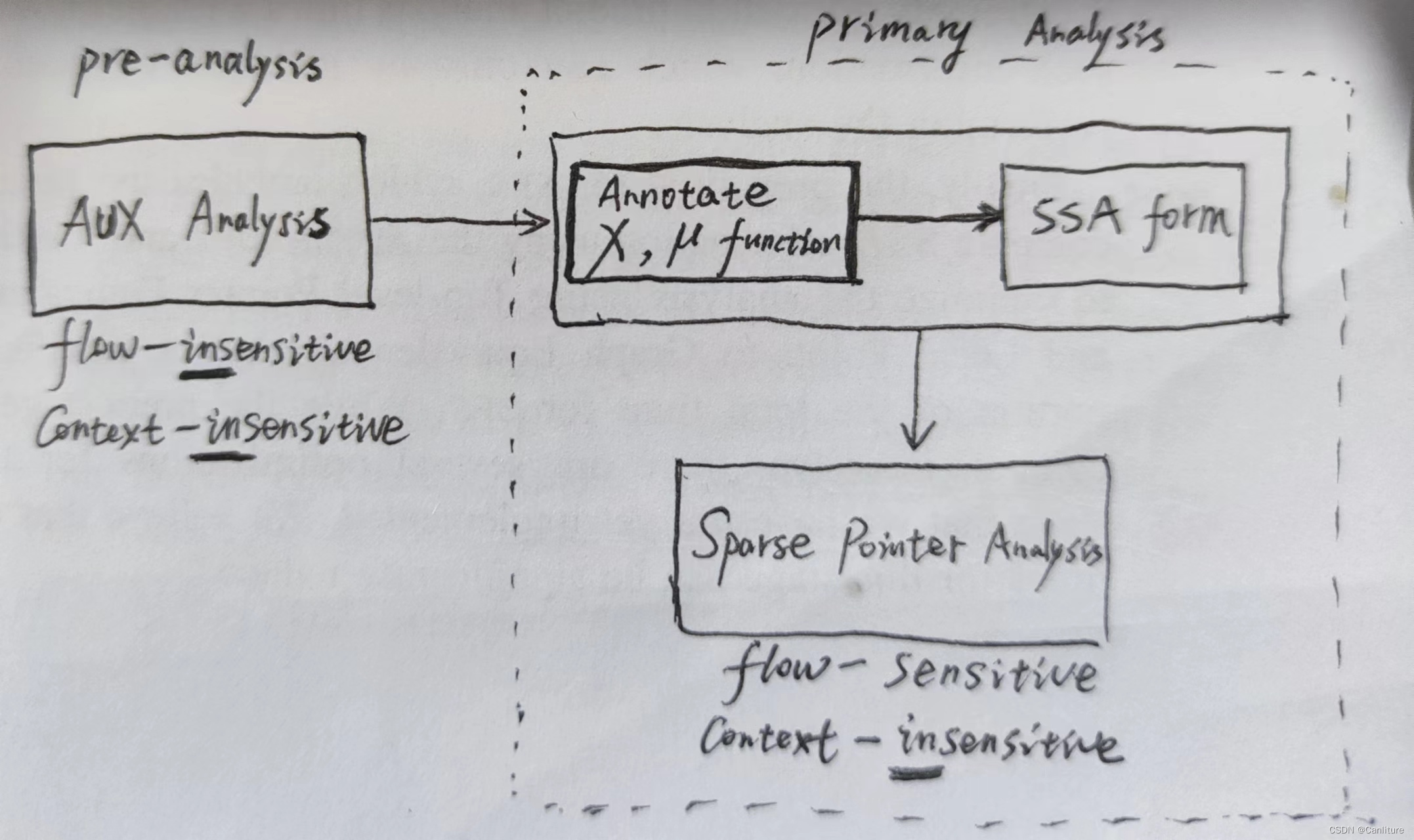
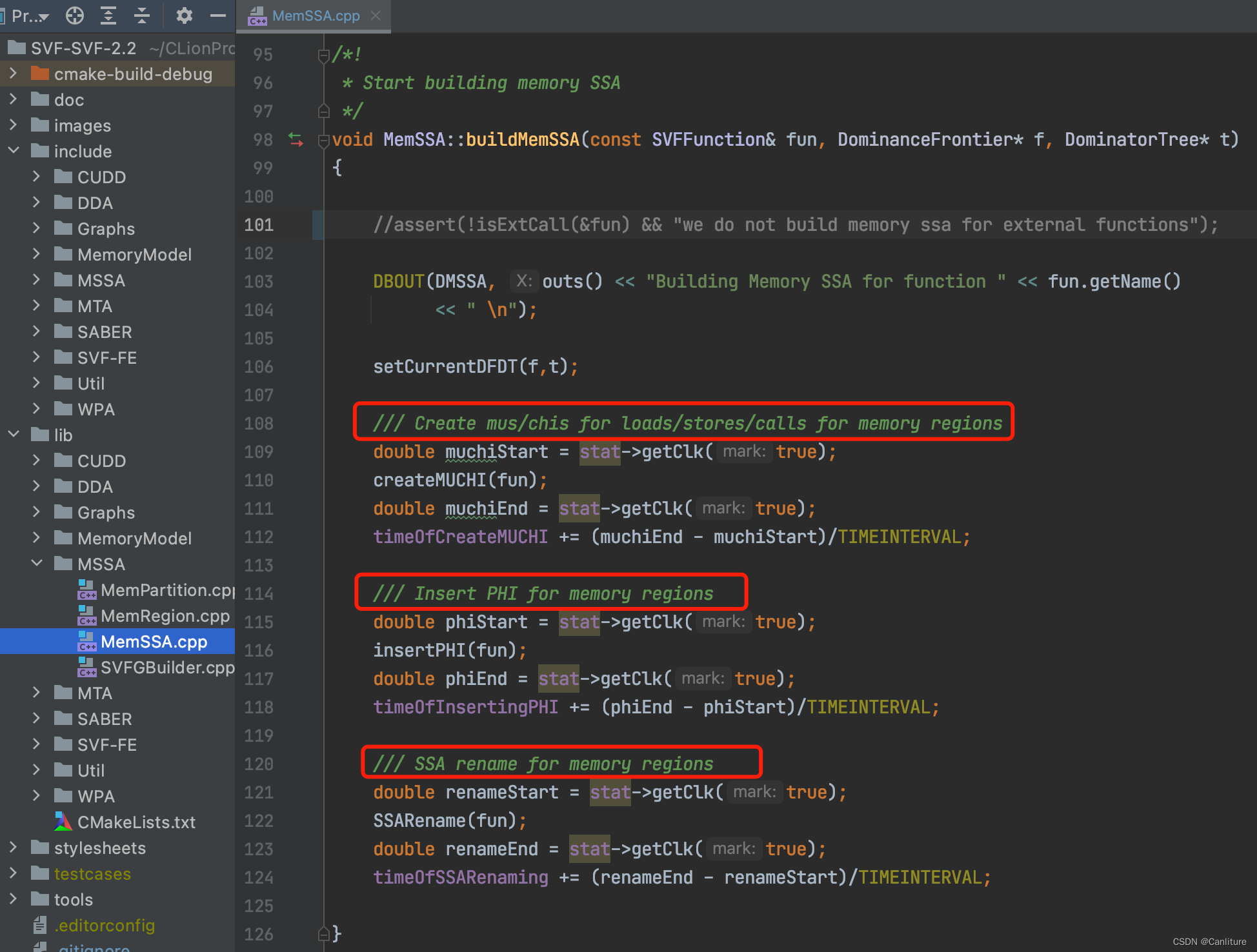
AUX Analysis, Annotate chi/mu functions, SSA form实际上就是构造MemorySSA。使得IR是full-sparse的。可参考SVF的代码:
首先AUX Analysis是跑一个预分析/辅助分析,通过这个指针分析,可以知道LLVM IR中每条load/store到底may use/may def了哪些变量。
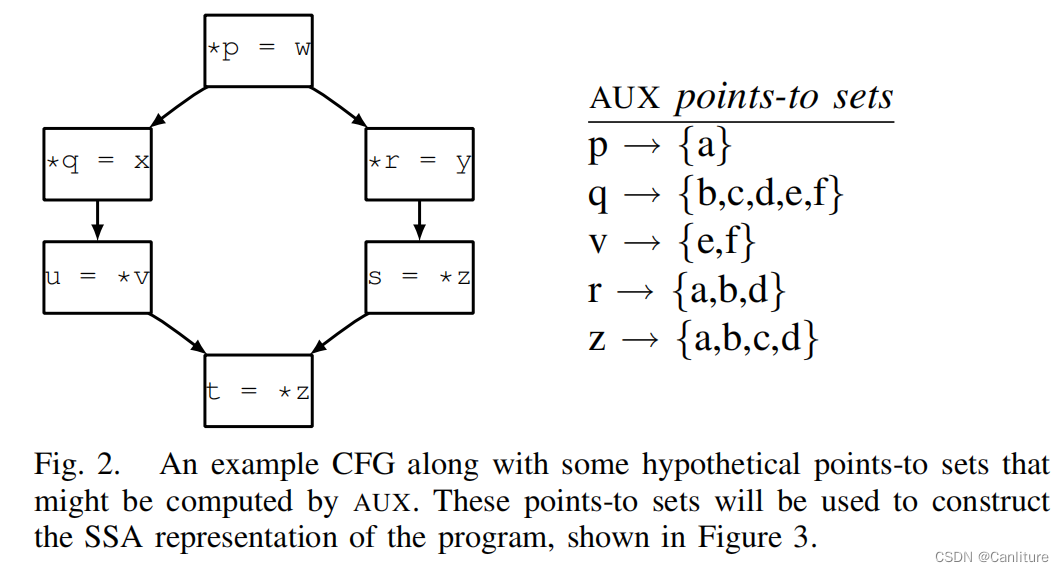
下面通过一个图来理解如何构造Memory SSA;给定如下代码,右侧AUX是通过一个快速/保守的流敏感/上下文不敏感指针分析得到的指向集。
针对store指令的may def,插入一条chi语句,例如may def v变量,则插入v = χ(v);这条语句def并且use v
针对load指令的may use,插入一条mu语句,例如mary use v变量,则插入µ(v);这条语句use了v。[2]
所以上述cfg变成如下的中间状态:
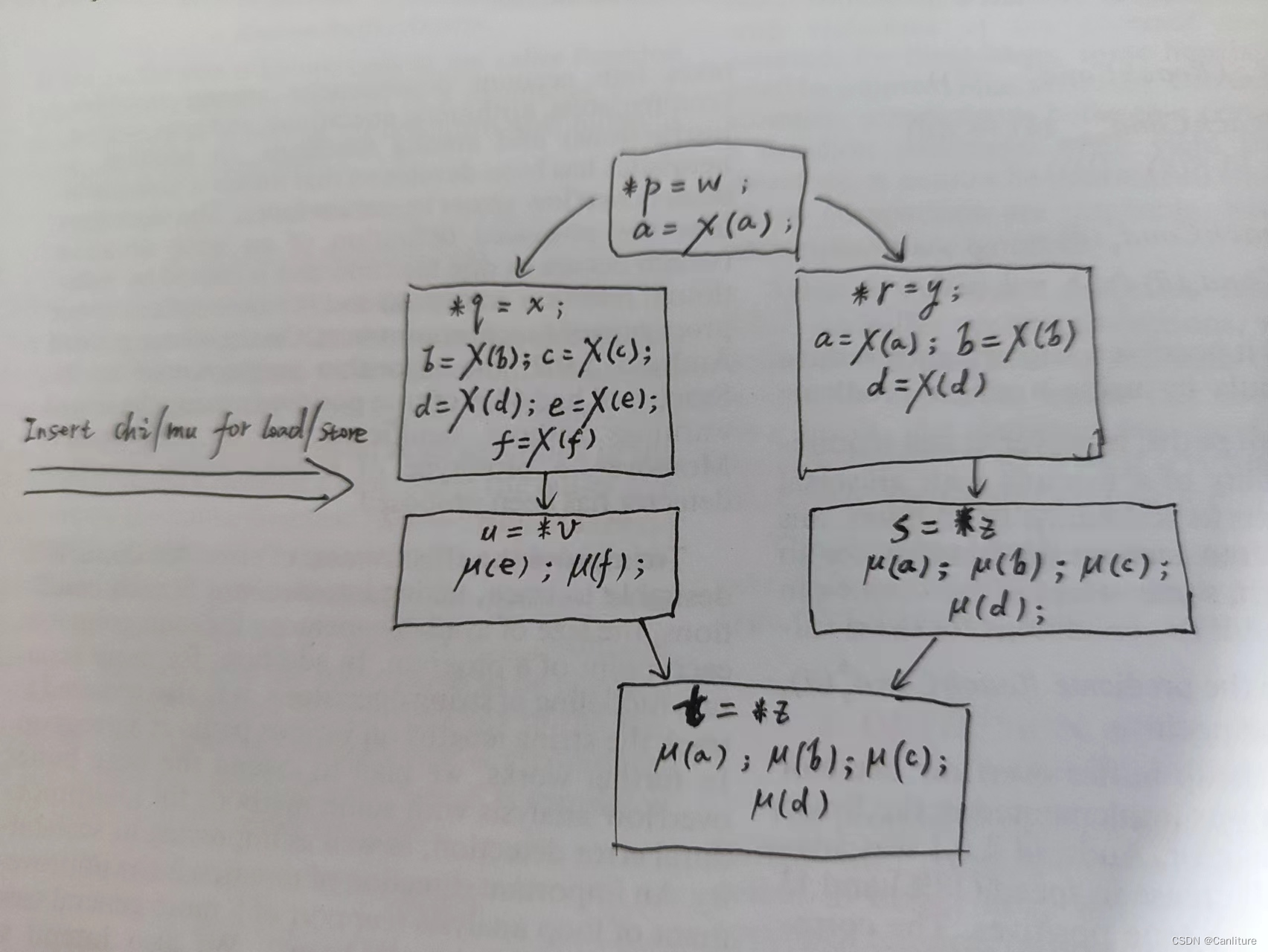
再跑一遍编译原理教材上的SSA构造算法,place phi, rename,得到如下的full-SSA/memory SSA形式:
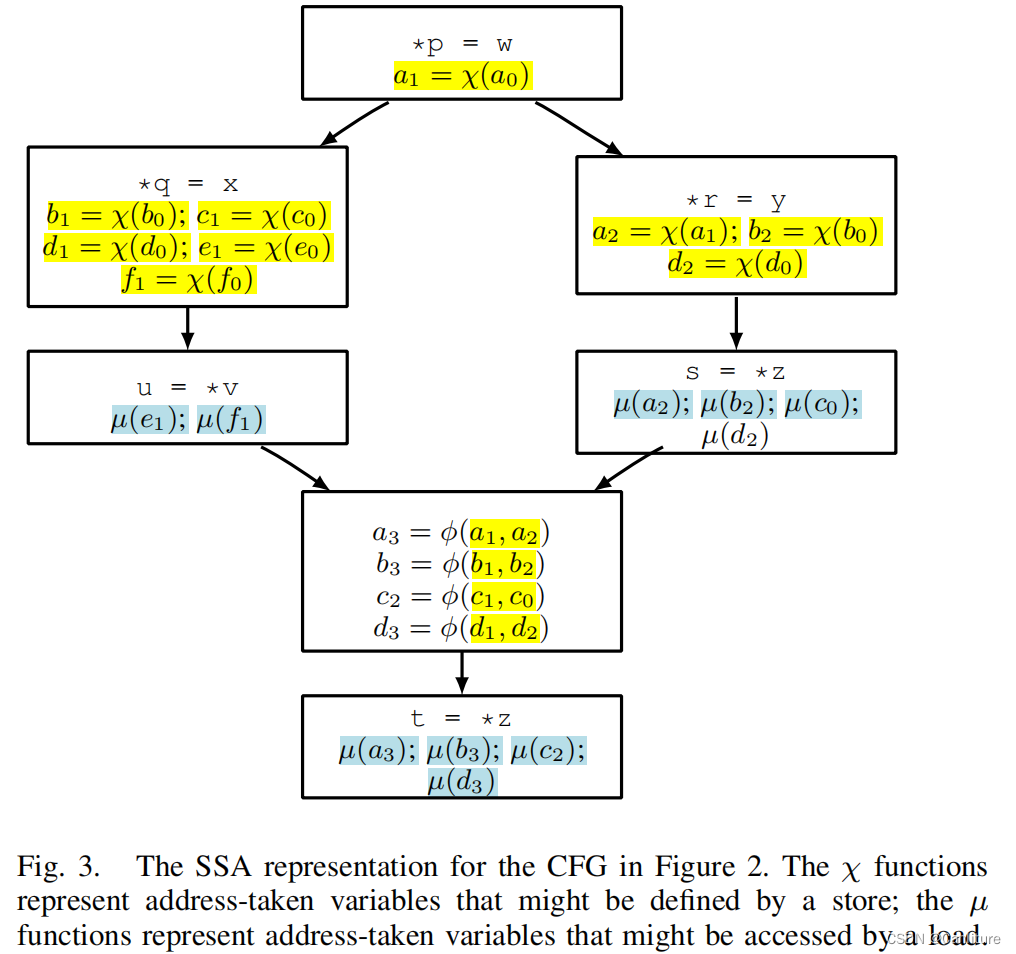
2.2 Def-Use Graph
由于full-SSA的构造,可以很容易地构造如下Def-Use Graph (DUG):
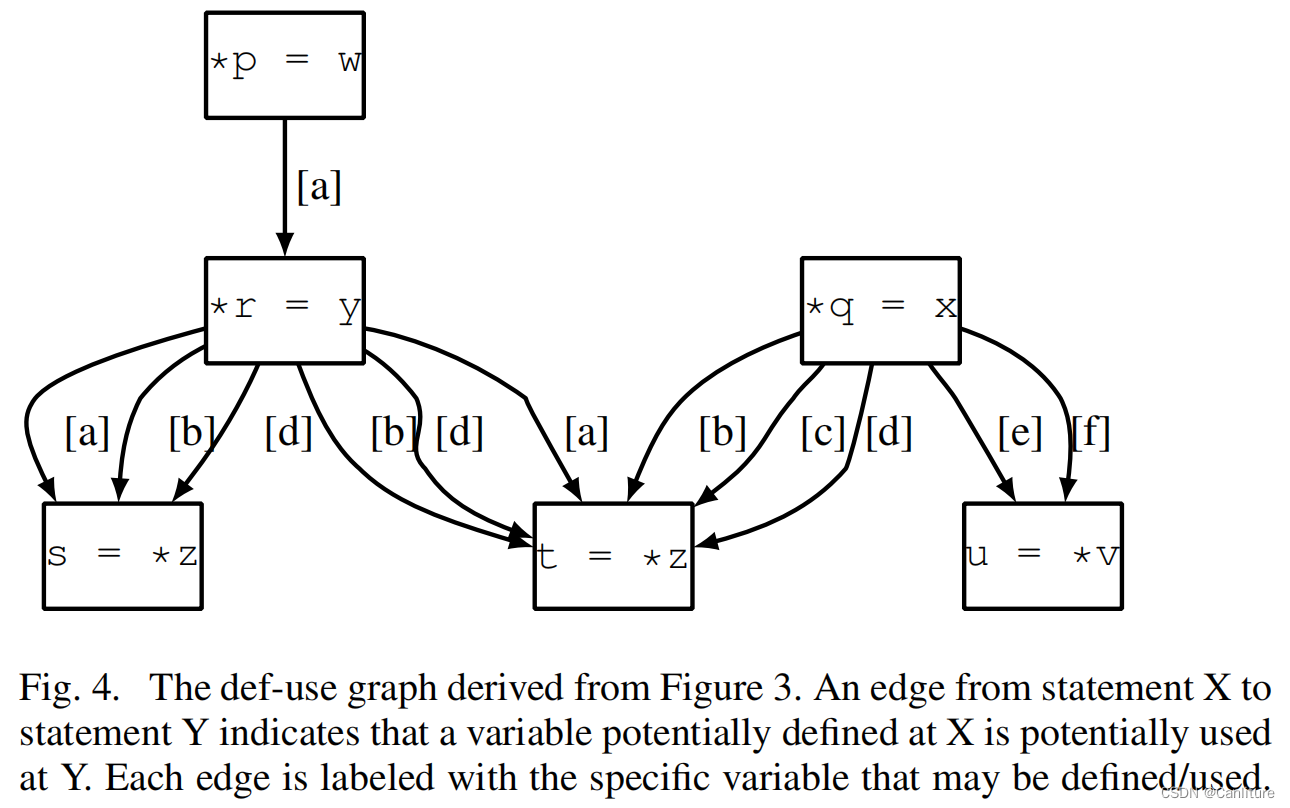
在分析大规模程序时,DUG上的边可能非常多,为了减少边的的数量,紧凑地表示Def-Use边上的信息,作者提出Access Equivalence的概念。
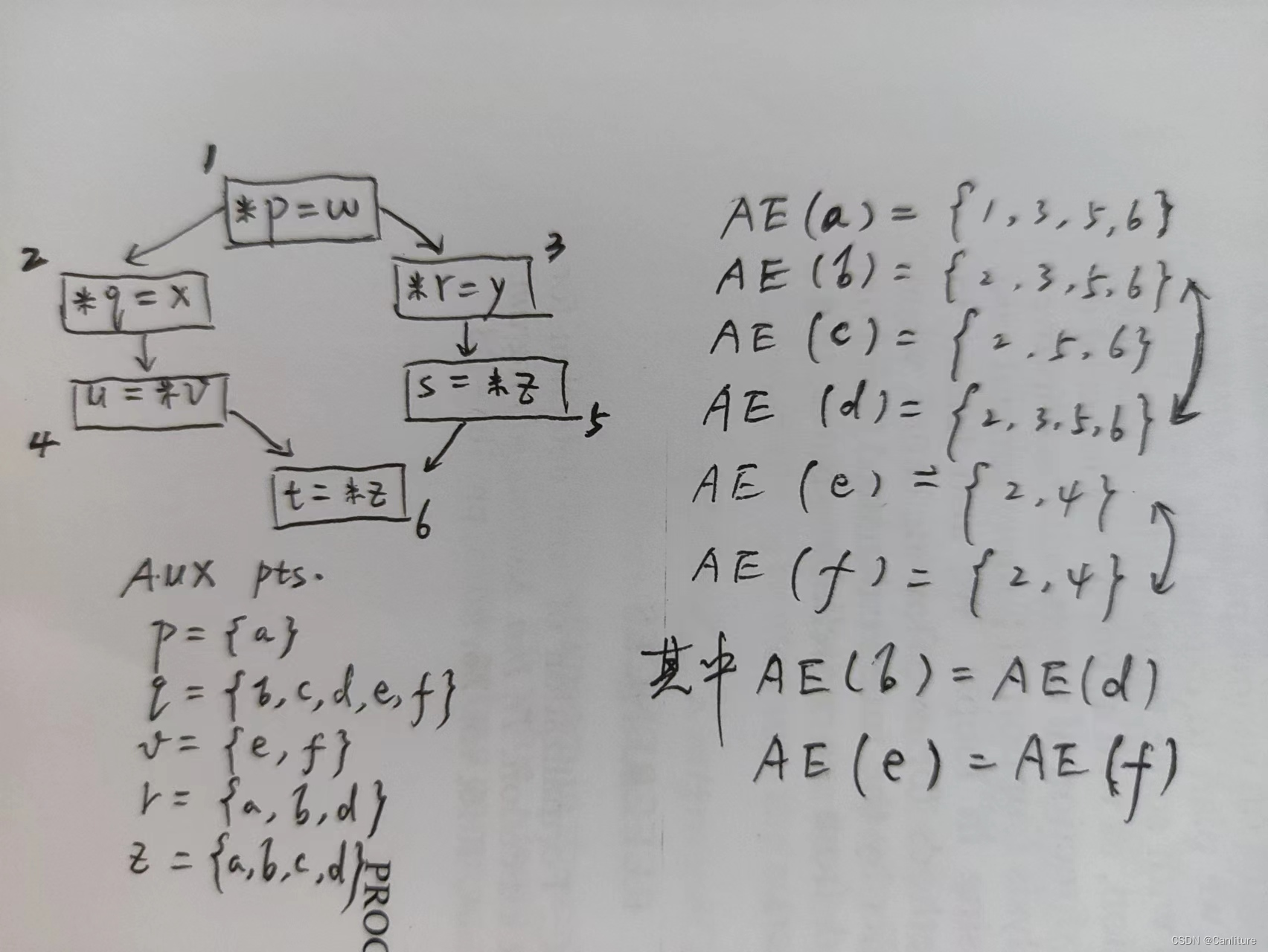
实际上Access Equivalence就是表示:address-token变量被相同的指令进行load/store。b对一个指令进行load/store,那么e也会被进行load/store。那么我们似乎可以把b和d看成是同一个东西(Memory Region)。
于是很容易得到:任意Store指令定义的某个变量,一定也会定义所有的access equivalent变量。Load类似。
于是上述DUG可以简化:
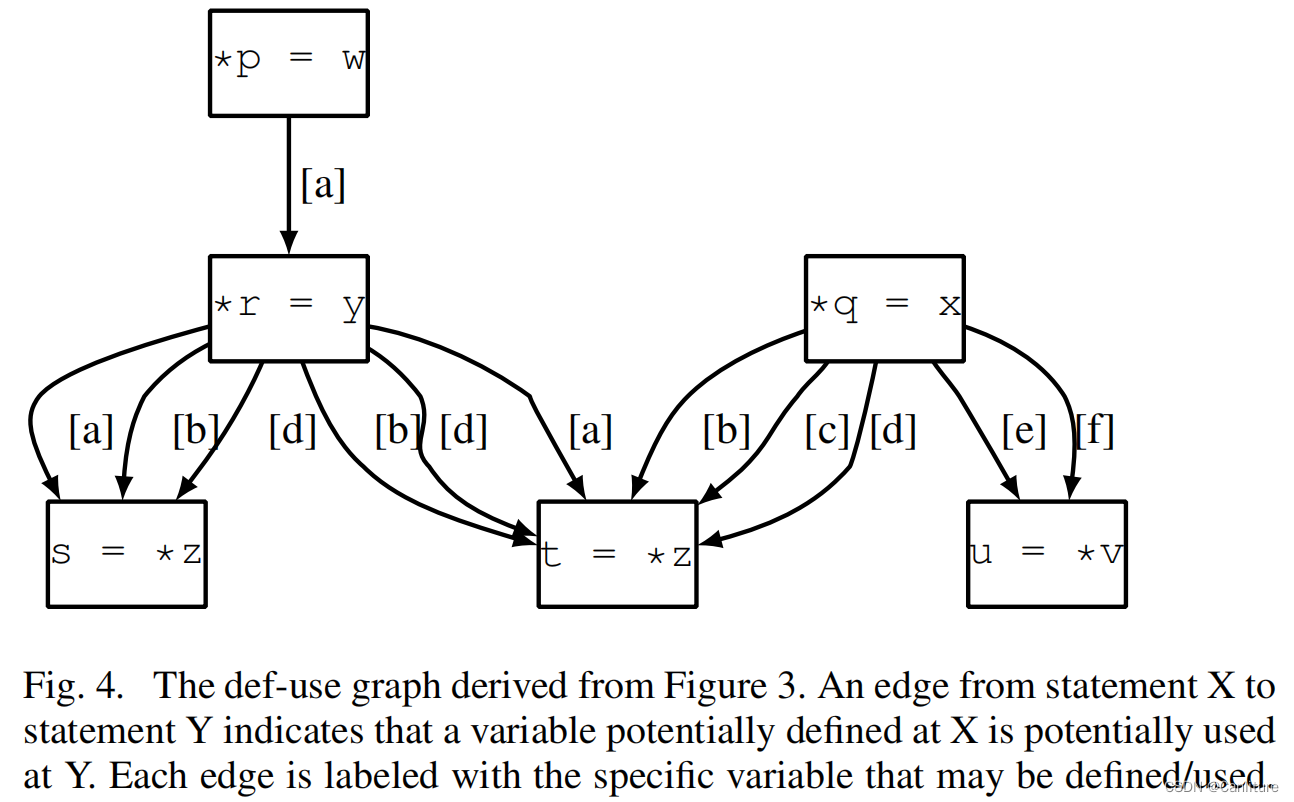
需要注意的是:AE只是减少边的数量,实际在后续作流敏感稀疏分析的时候,沿着Def-Use边传播数据流的时候,仍然是对单个变量进行传递。例如{b, d}为一组Access Equivence,则分别传播b和d的数据流分析到后继节点。
2.3 Strong/Weak Update
在做流敏感指针分析的时候,由于从AUX得到的指针信息是流不敏感且保守的,在流敏感分析时,针对Store指令:*x = y,需要有选择地进行Strong Update/Weak Update,以提升分析精度。
具体而言,对*x = y标记的chi语句 v m = X ( v n ) v_m = X(v_n) vm=X(vn),分3种情况:
(1) 流敏感分析时,x不指向v。 v ∉ p t s ( x ) v \notin pts(x) v∈/pts(x)。将该chi语句当作copy指令对待 v m = v n ; p t s ( v m ) ⊇ p t s ( v n ) v_m = v_n;\ pts(v_m) \supseteq pts(v_n) vm=vn; pts(vm)⊇pts(vn),即跟y无关
(2) 流敏感分析时,x只指向v。
{
v
}
=
p
t
s
(
x
)
\{v\} = pts(x)
{v}=pts(x)。强更新,将chi语句当作copy指令对待
v
m
=
y
;
p
t
s
(
v
m
)
⊇
p
t
s
(
y
)
v_m = y;\ pts(v_m) \supseteq pts(y)
vm=y; pts(vm)⊇pts(y),即跟
v
n
v_n
vn无关
(3) 流敏感分析时,x指向集包含v且指向集大于1。$v \in pts(x) \ \land \ |pts(x)| > 1 $ ,弱更新,等效于$pts(v_n) \supseteq pts(v_m);\ pts(v_n) \supseteq pts(y) $
2.3 稀疏分析算法
下面是核心算法,前文已经描述清楚了。
唯一注意的就是worklist在传播数据流信息的时候,是沿着Def-Use边传递的: k → n ∈ E k \rightarrow n \in E k→n∈E 。
这是稀疏分析的关键,相比稠密分析,跳过不相关的控制流节点,以达到加速分析的目的。

3. 实验数据
测试集:
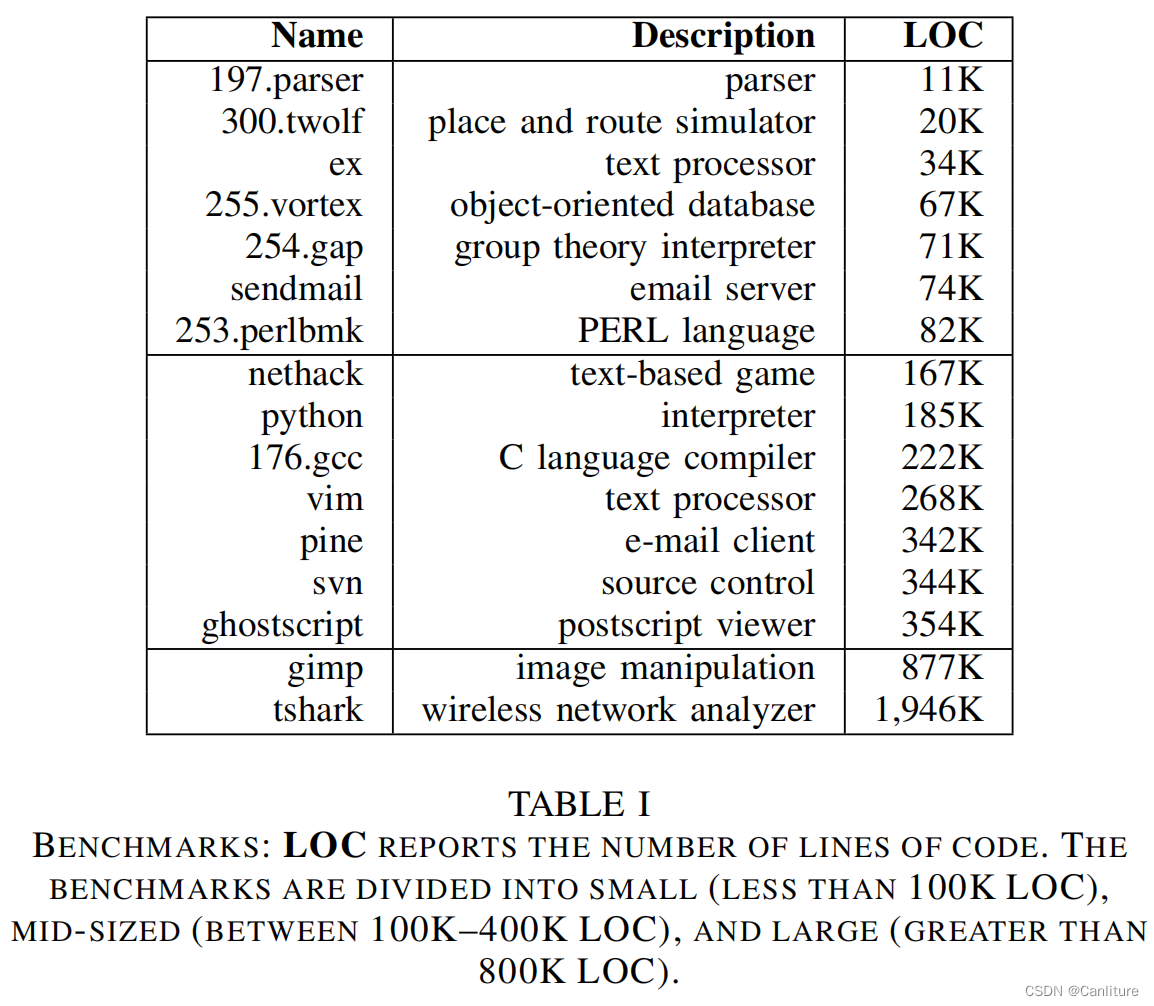
对比实验:
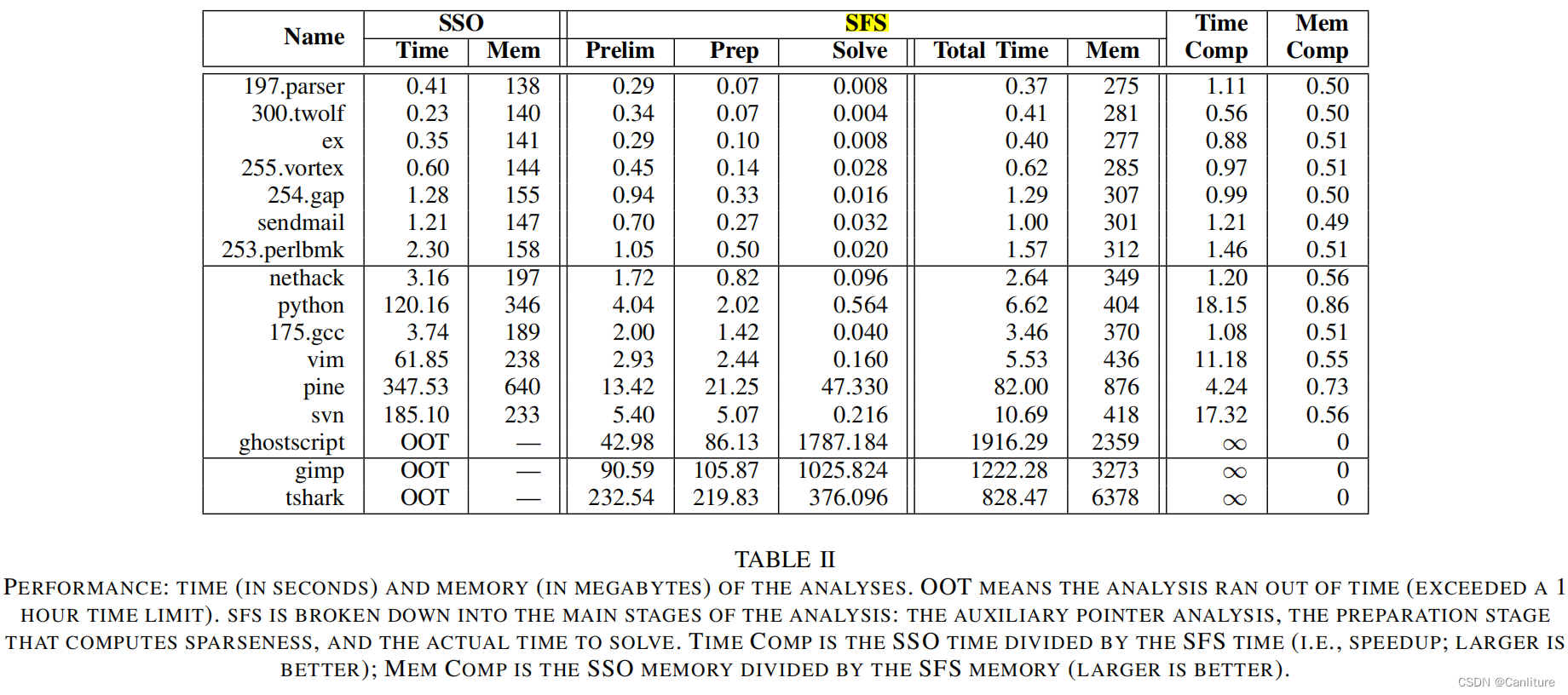
具体实验数据分析,可详细参考论文
4. 参考文献
[1] B. Hardekopf and C. Lin. Semi-sparse flow-sensitive pointer analysis.In Symposium on Principles of Programming Languages (POPL), 2009.
[2] F. Chow, S. Chan, S.-M. Liu, R. Lo, and M. Streich. Effective representation of aliases and indirect memory operations in SSA form.In Compiler Construction (CC), 1996.
















 2363
2363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









