






通过调用api接口的方式导入
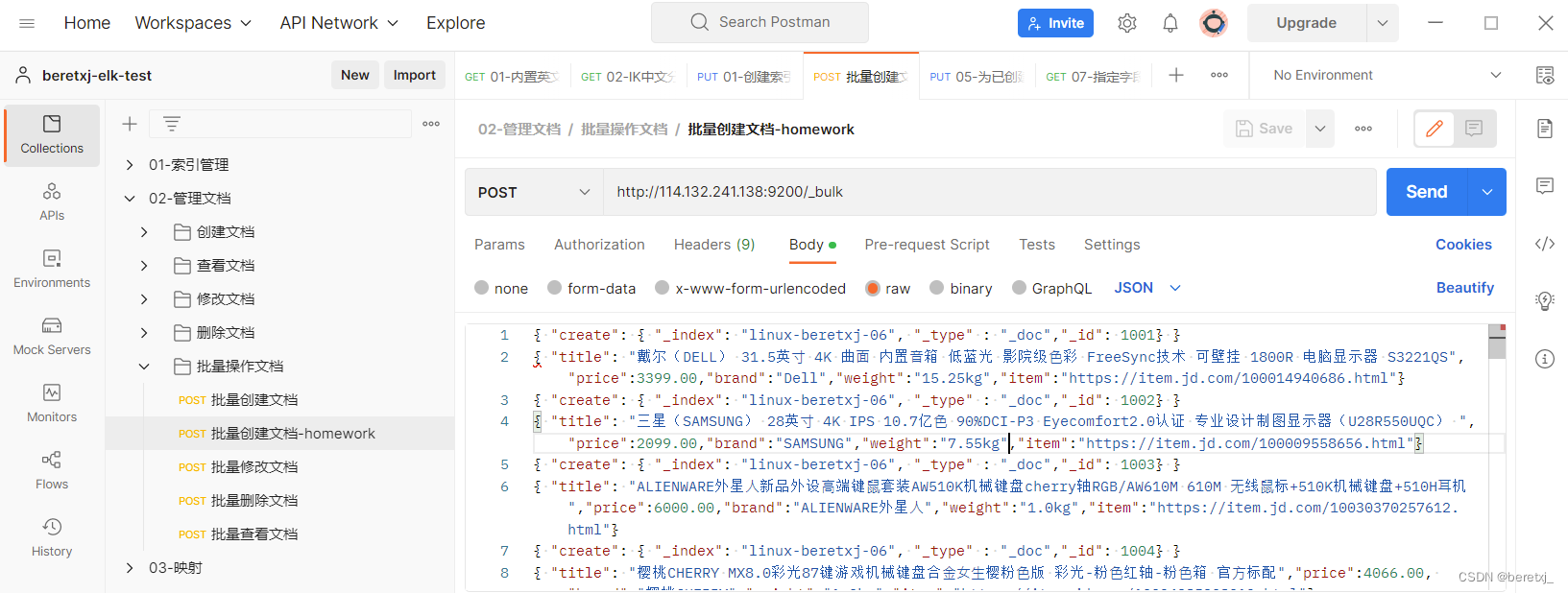
使用postman调用_bulk接口导入
使用python脚本
#!/usr/bin/env python3
# _*_coding:utf-8_*_
import sys
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
# 设置字符集,兼容Python2
reload(sys)
sys.setdefaultencoding('utf-8')
es = Elasticsearch(['10.0.10.20:9200'])
arr = []
with open(r'/data/json-file/shopping.json') as f:
for i in f:
arr.append(i.strip())
write_number, _ = bulk(es, arr, index="web-shopping")
print(write_number)
es.close()使用filebeat导入
因为文件本身已经是json格式,所以可以直接使用filebeat来导入
#filebeat配置文件
[root@VM-20-10-centos filebeat]# egrep -v "^ *#|^$" filebeat_2_es.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /data/json-file/shopping.json
json.keys_under_root: true
json.overwrite_keys: true
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
setup.kibana:
setup.template.name: "manual_shopping"
setup.template.pattern: "manual_shopping_"
output.elasticsearch:
hosts: ["10.0.20.10:9200"]
index: "manual_shopping_%{+yyyy.MM.dd}"
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~然后通过指定配置文件的方式,一次性启动
#需要指定--path.data参数,因为本机已经启动一个filebeat
[root@VM-20-10-centos filebeat]# /usr/share/filebeat/bin/filebeat -e -c ./filebeat_2_es.yml --path.data /tmp/filebeat
查看日志无异常报错则处理成功
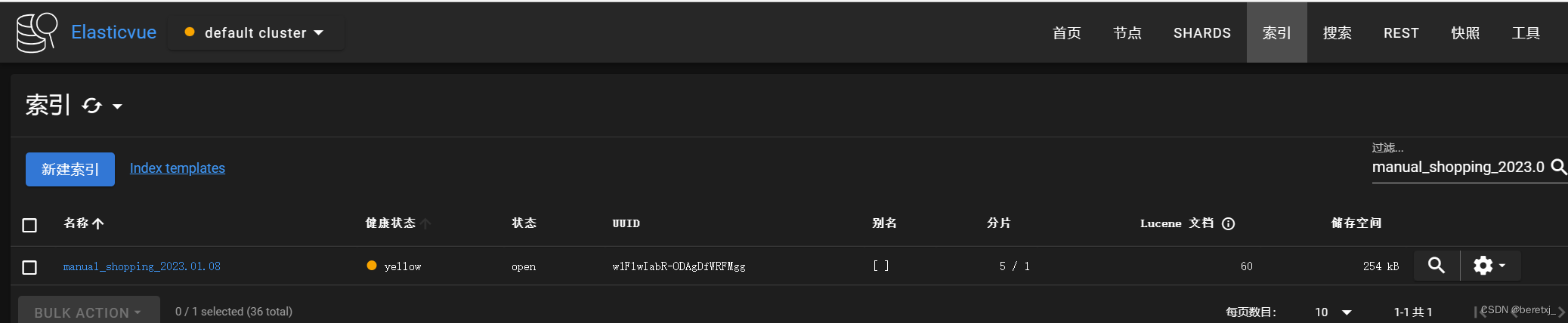
通过浏览器插件查看,已经写入成功














 4801
4801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









