






Atlas2.1.0兼容CDH6.2.0部署
1. CDH组件版本
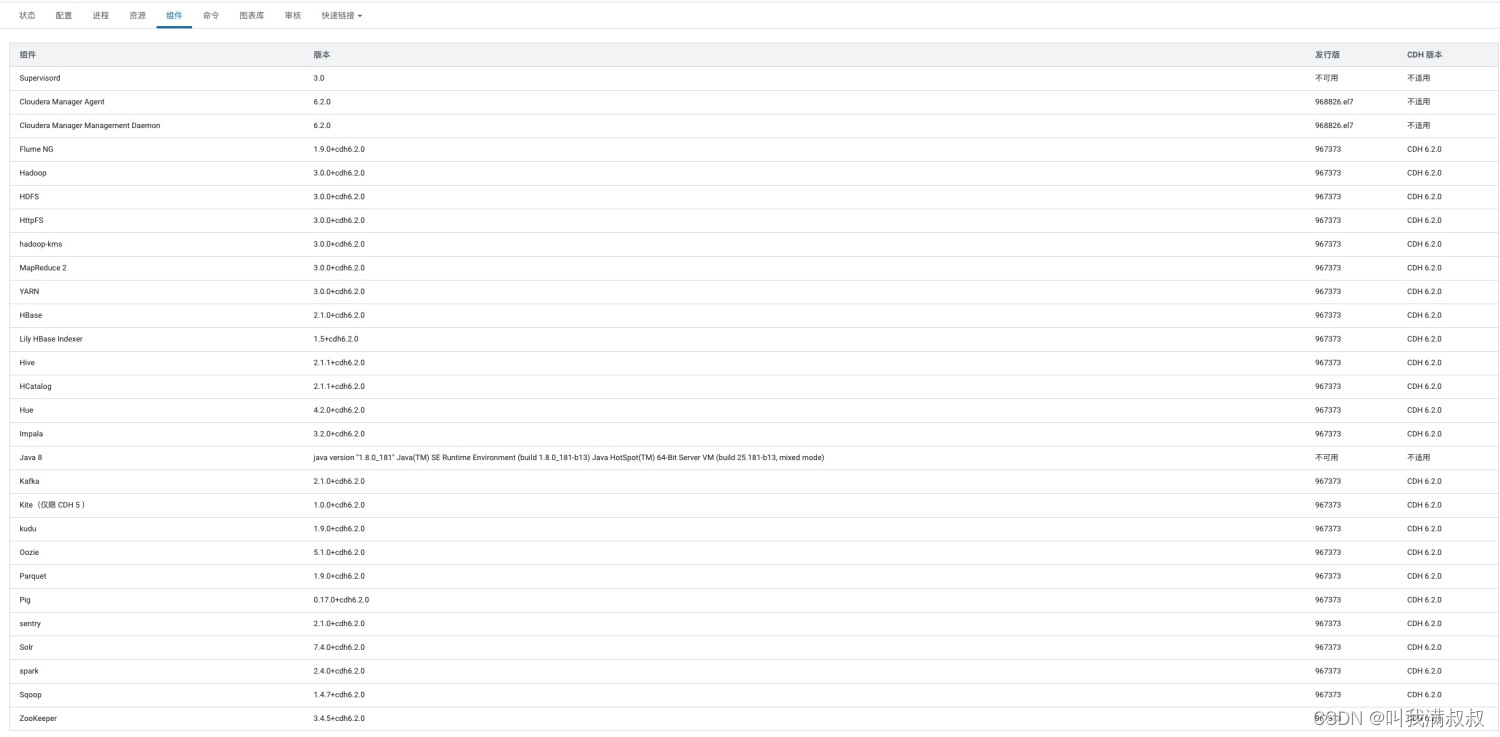
2. 配置
#下载
wget https://dlcdn.apache.org/atlas/2.1.0/apache-atlas-2.1.0-sources.tar.gz --no-check-certificate
#pom.xml
<hadoop.version>3.0.0-cdh6.2.0</hadoop.version>
<hbase.version>2.1.0-cdh6.2.0</hbase.version>
<solr.version>7.4.0-cdh6.2.0</solr.version>
<hive.version>2.1.1-cdh6.2.0</hive.version>
<kafka.version>2.1.0-cdh6.2.0</kafka.version>
<zookeeper.version>3.4.5-cdh6.2.0</zookeeper.version>
<sqoop.version>1.4.7-cdh6.2.0</sqoop.version>
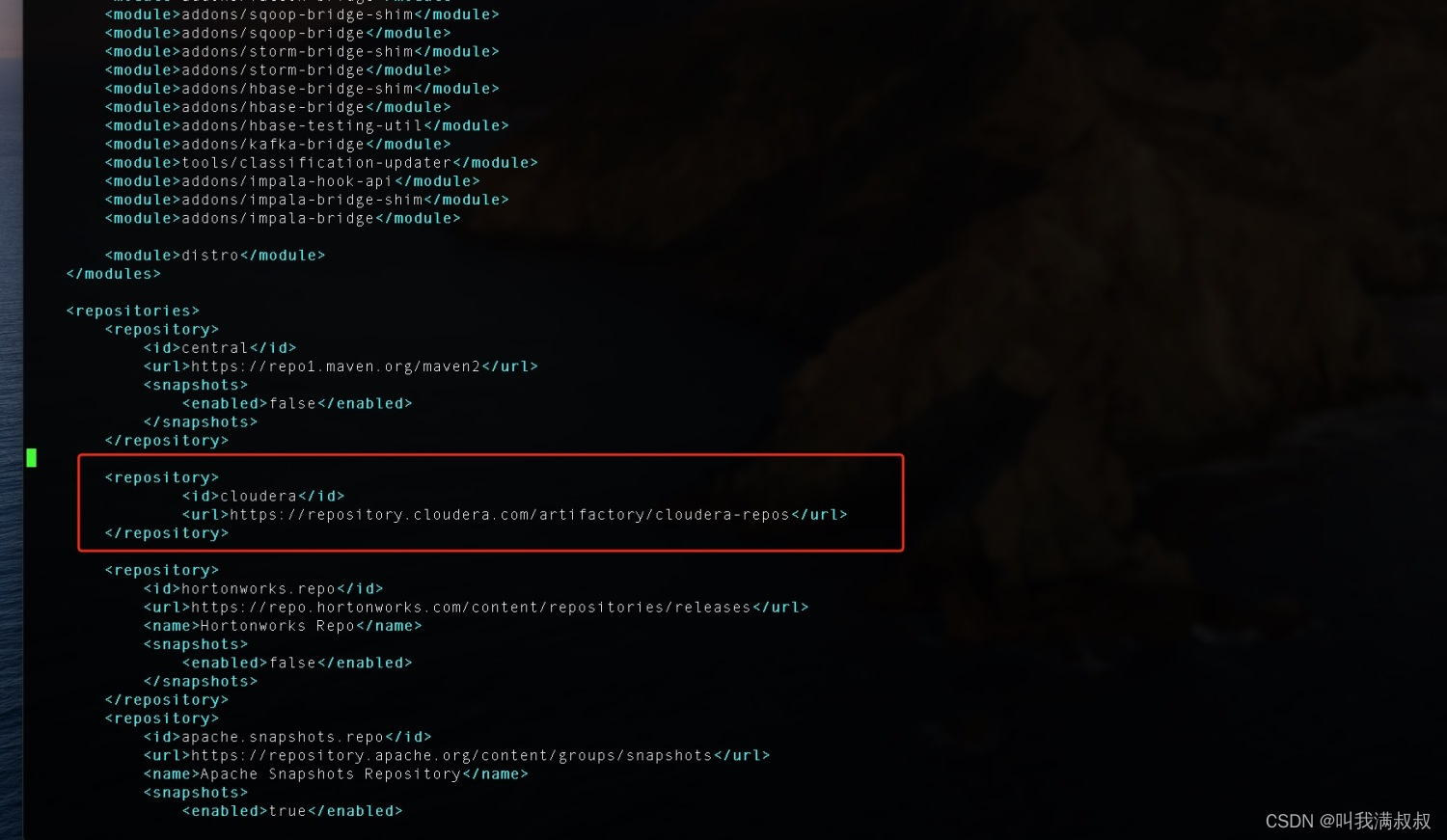
#镜像
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos</url>
</repository>
#注意:pom.xml修改的内容要与cdh集群中的版本一致

3. 兼容hive2.1.1-cdh6.2.0 修改源码
注意: 不做兼容编译打包会失败
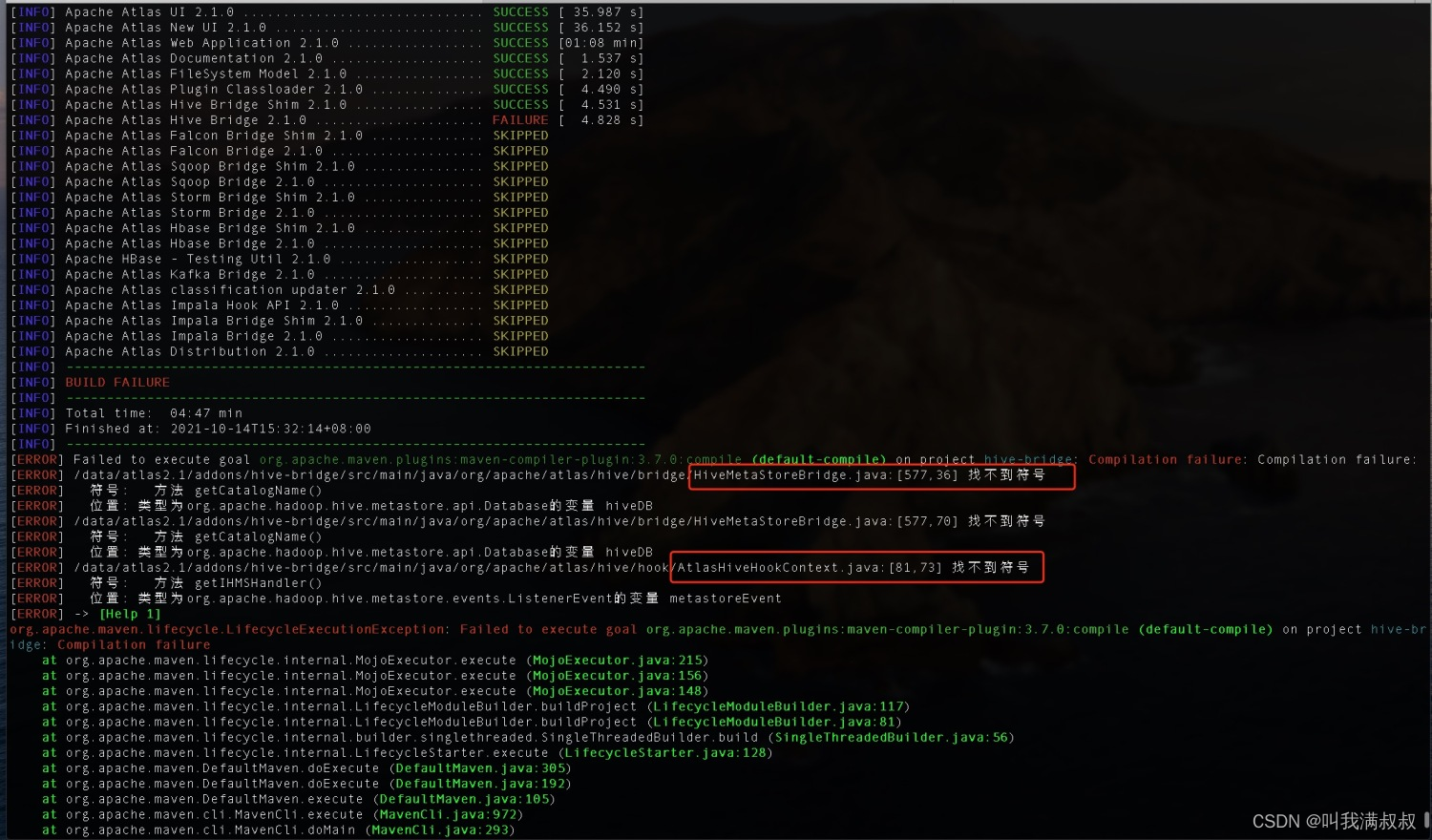
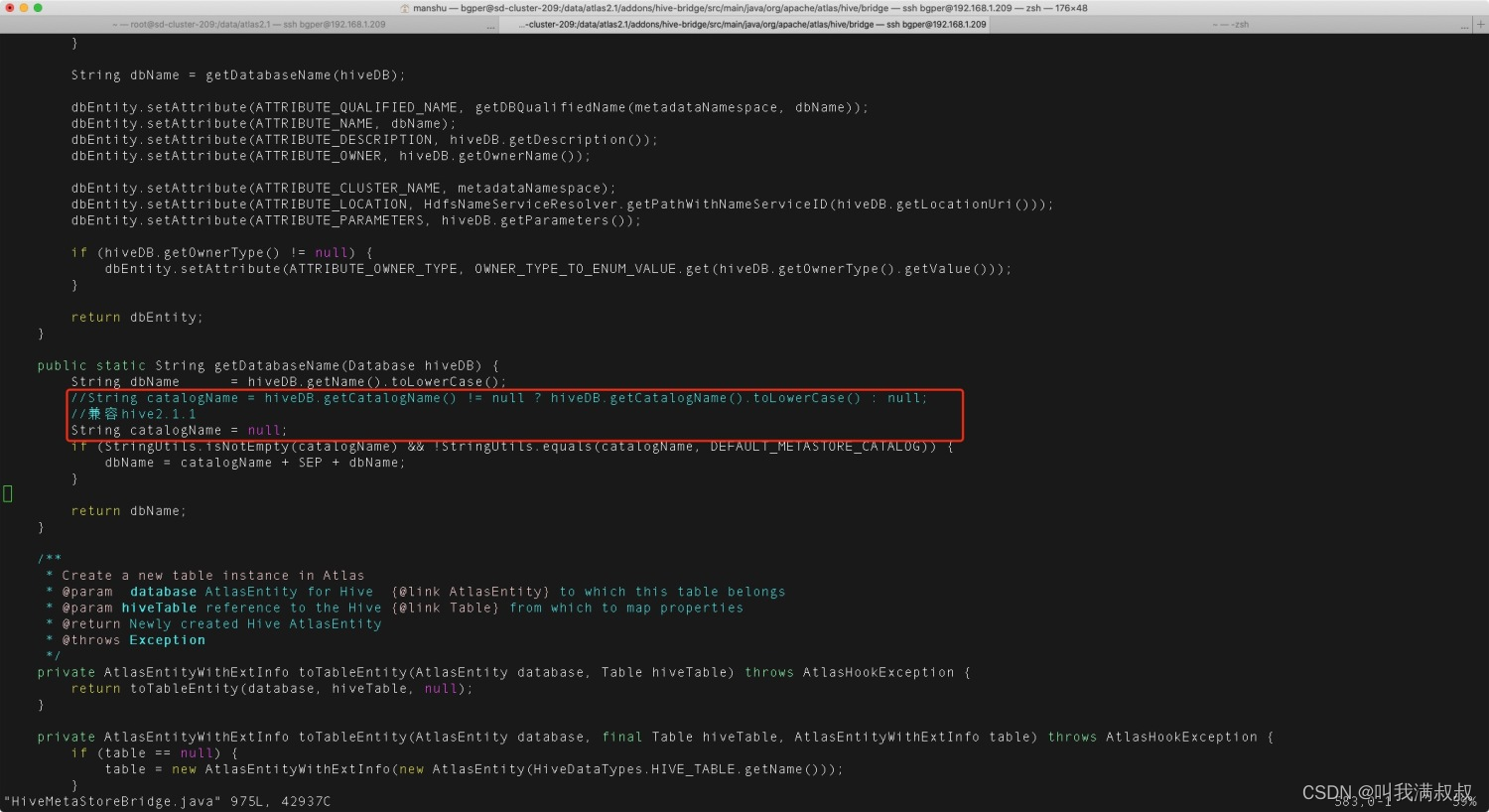
#子工程apache-atlas-sources-2.1.0\addons\hive-bridge
#org/apache/atlas/hive/bridge/HiveMetaStoreBridge.java
String catalogName = hiveDB.getCatalogName() != null ? hiveDB.getCatalogName().toLowerCase() : null;
改为
String catalogName = null;
#org/apache/atlas/hive/hook/AtlasHiveHookContext.java
this.metastoreHandler = (listenerEvent != null) ? metastoreEvent.getIHMSHandler() : null;
改为
this.metastoreHandler = null;
4.编译打包
export MAVEN_OPTS="-Xms2g -Xmx2g"
sudo mvn clean -DskipTests install [ -X(查看debug信息)]
sudo mvn clean -DskipTests package -Pdist
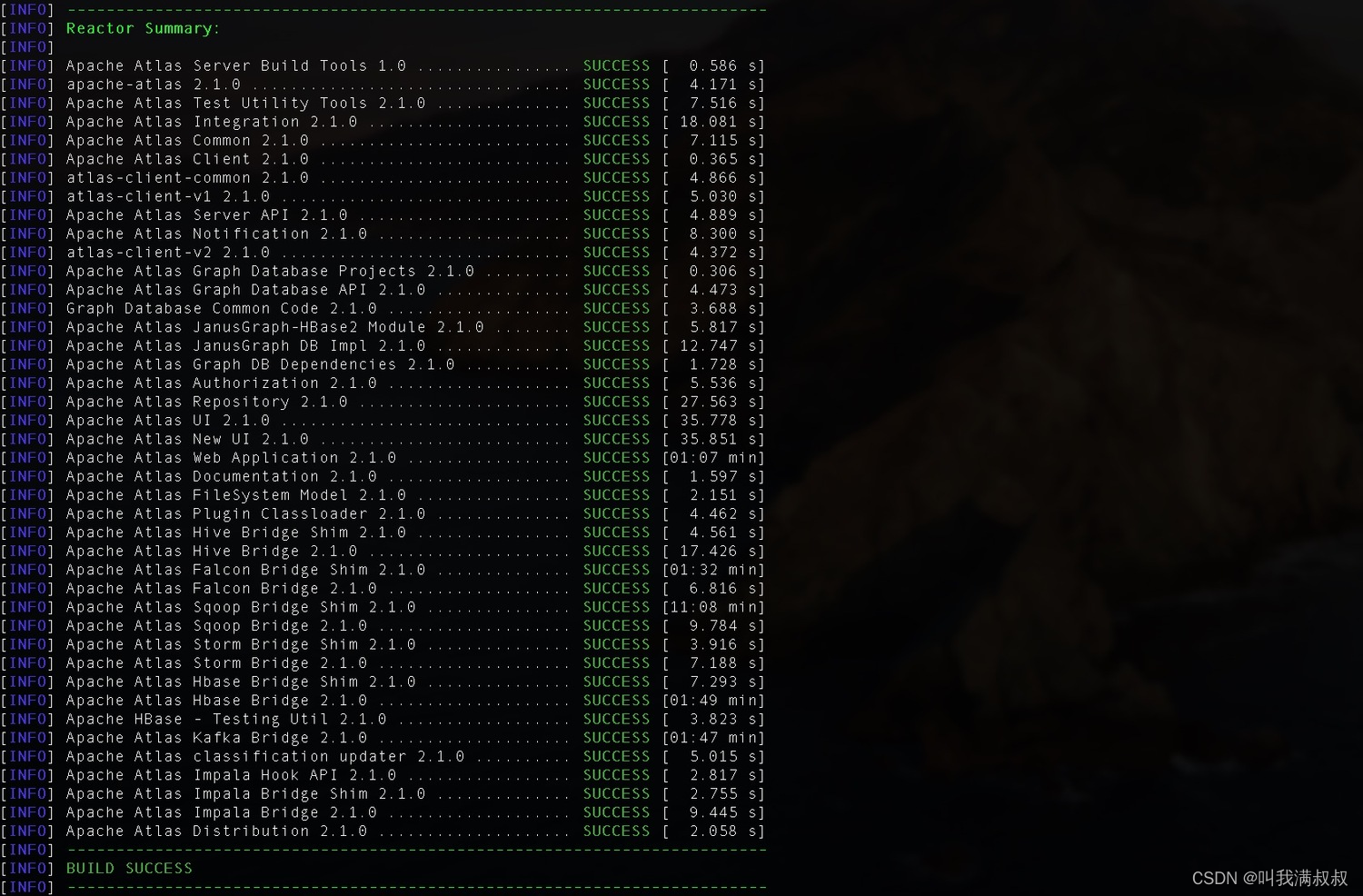
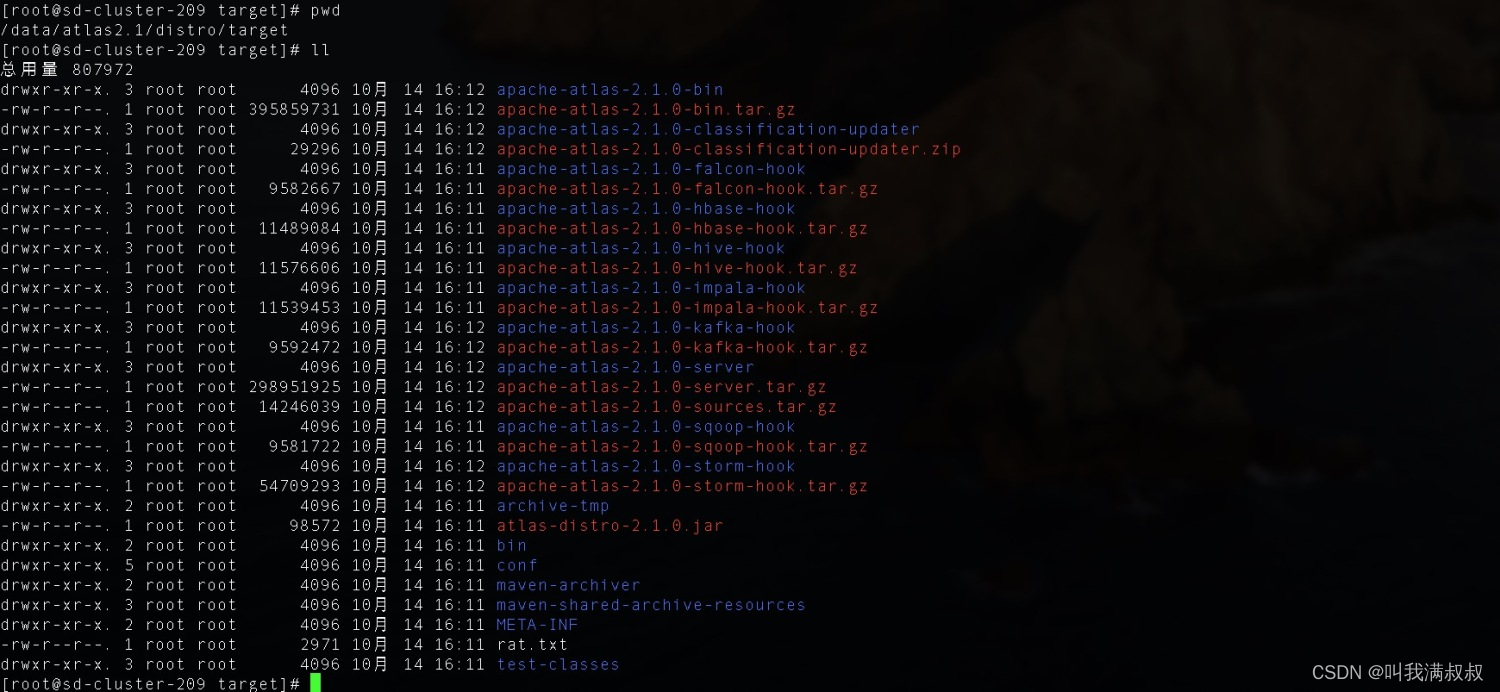
5.Atlas安装
# 将安装包移动至/data/app下 并改名为atlas2.1
cp -r apache-atlas-2.1.0/ /data/app/
mv apache-atlas-2.1.0/ atlas2.1
# 配置文件
vim /data/app/atlas2.1/conf/atlas-application.properties
# 配置项
######### Server Properties #########
atlas.rest.address=http://192.168.1.209:21000
## Server port configuration
atlas.server.http.port=21000
6.集成CDH组件
6.1集成kafka
# 配置文件
vim /data/app/atlas2.1/conf/atlas-application.properties
# 配置项
atlas.notification.embedded=false(如果要使用内嵌的kafka,则改为true)
atlas.kafka.zookeeper.connect=sd-cluster-207:2181,sd-cluster-208:2181,sd-cluster-209:2181
atlas.kafka.bootstrap.servers=sd-cluster-207:9092,sd-cluster-208:9092,sd-cluster-209:9092
atlas.kafka.zookeeper.session.timeout.ms=4000
atlas.kafka.zookeeper.connection.timeout.ms=2000
atlas.kafka.enable.auto.commit=true
atlas.kafka.offsets.topic.replication.factor=3
kafka-topics --zookeeper sd-cluster-209:2181 --create --replication-factor 3 --partitions 3 --topic _HOATLASOK
kafka-topics --zookeeper sd-cluster-209:2181 --create --replication-factor 3 --partitions 3 --topic ATLAS_HOOK
kafka-topics --zookeeper sd-cluster-209:2181 --create --replication-factor 3 --partitions 3 --topic ATLAS_ENTITIES
kafka-topics.sh --list --zookeeper sd-cluster-209:2181
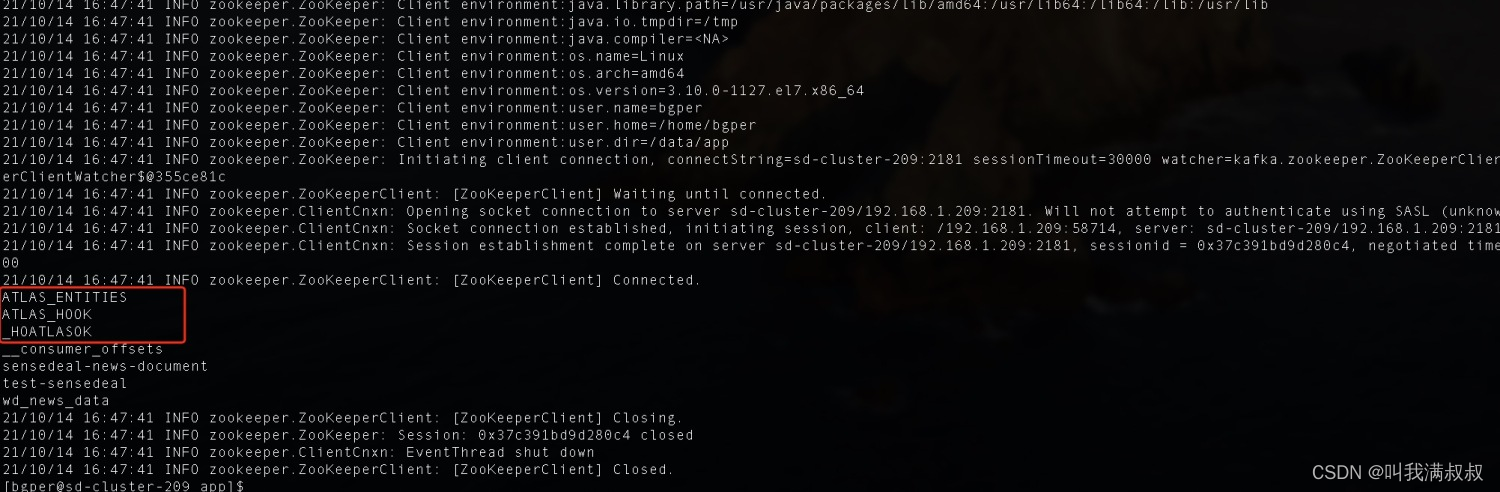
6.2集成Hbase
# 配置文件
vim /data/app/atlas2.1/conf/atlas-application.properties
#配置项
atlas.graph.storage.hostname=sd-cluster-207:2181,sd-cluster-208:2181,sd-cluster-209:2181
# 将hbase的配置文件软链接到Atlas的conf/hbase目录下
ln -s /etc/hbase/conf/ /data/app/atlas2.1/conf/hbase/
# 配置文件
vim /data/app/atlas2.1/conf/atlas-env.sh
export HBASE_CONF_DIR=//data/app/atlas2.1/conf/hbase/conf
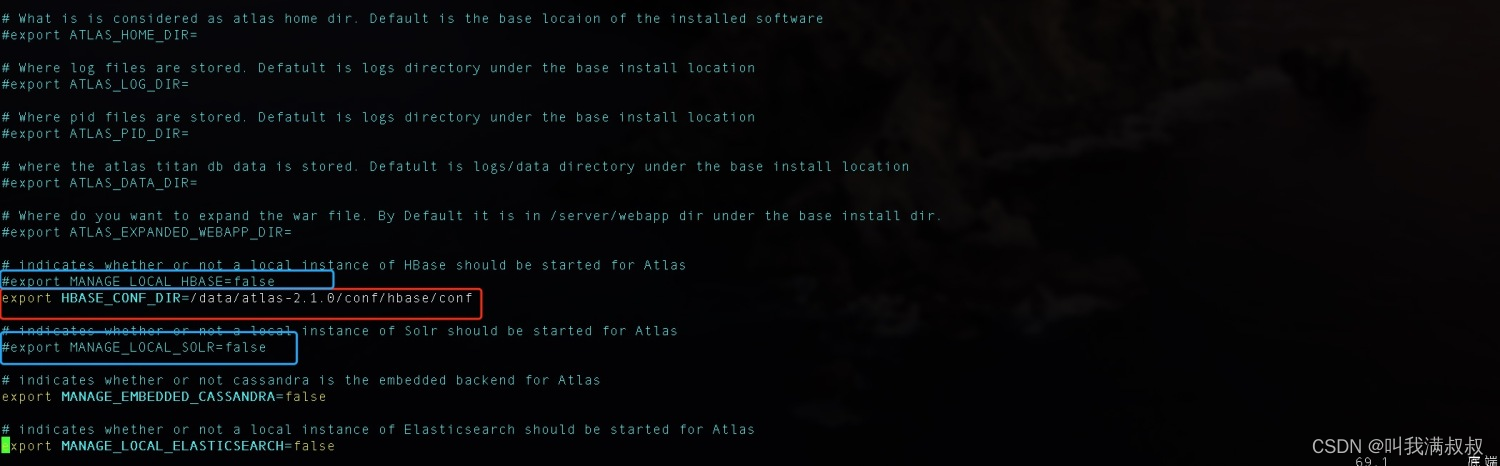
6.3集成Solr
# 配置文件
vim /data/app/atlas2.1/conf/atlas-application.properties
#配置项
atlas.graph.index.search.solr.zookeeper-url=sd-cluster-207:2181/solr,sd-cluster-208:2181/solr,sd-cluster-209:2181/solr
# 将Atlas的conf目录下Solr文件夹同步到Solr的目录下并更名
cp -r /data/app/atlas2.1/conf/solr/ /opt/cloudera/parcels/CDH/lib/solr/atlas_solr
#同步到其他节点 sd-cluster-207、sd-cluster-208 /opt/cloudera/parcels/CDH/lib/solr/atlas_solr
#修改用户组
chown -R solr:solr /opt/cloudera/parcels/CDH/lib/solr/
#切换用户
su solr
# Solr创建collection
/opt/cloudera/parcels/CDH/lib/solr/bin/solr create -c vertex_index -d /opt/cloudera/parcels/CDH/lib/solr/atlas_solr -force -shards 3 -replicationFactor 3
/opt/cloudera/parcels/CDH/lib/solr/bin/solr create -c edge_index -d /opt/cloudera/parcels/CDH/lib/solr/atlas_solr -force -shards 3 -replicationFactor 3
/opt/cloudera/parcels/CDH/lib/solr/bin/solr create -c fulltext_index -d /opt/cloudera/parcels/CDH/lib/solr/atlas_solr -force -shards 3 -replicationFactor 3
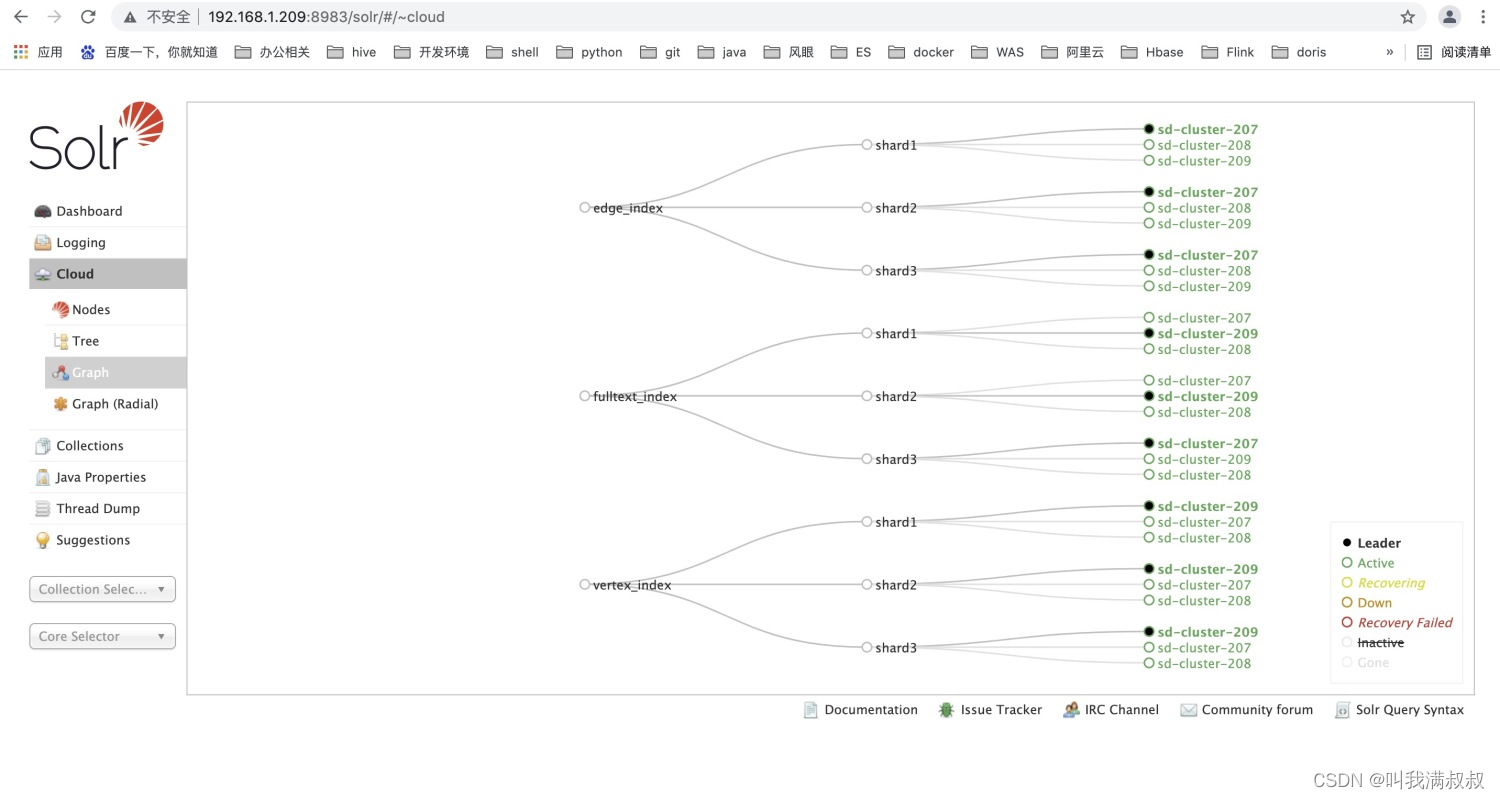
6.4Atlas启动
/data/app/atlas2.1/bin/atlas_start.py
http://192.168.1.209:21000/
默认用户名和密码为:admin

6.5集成Hive
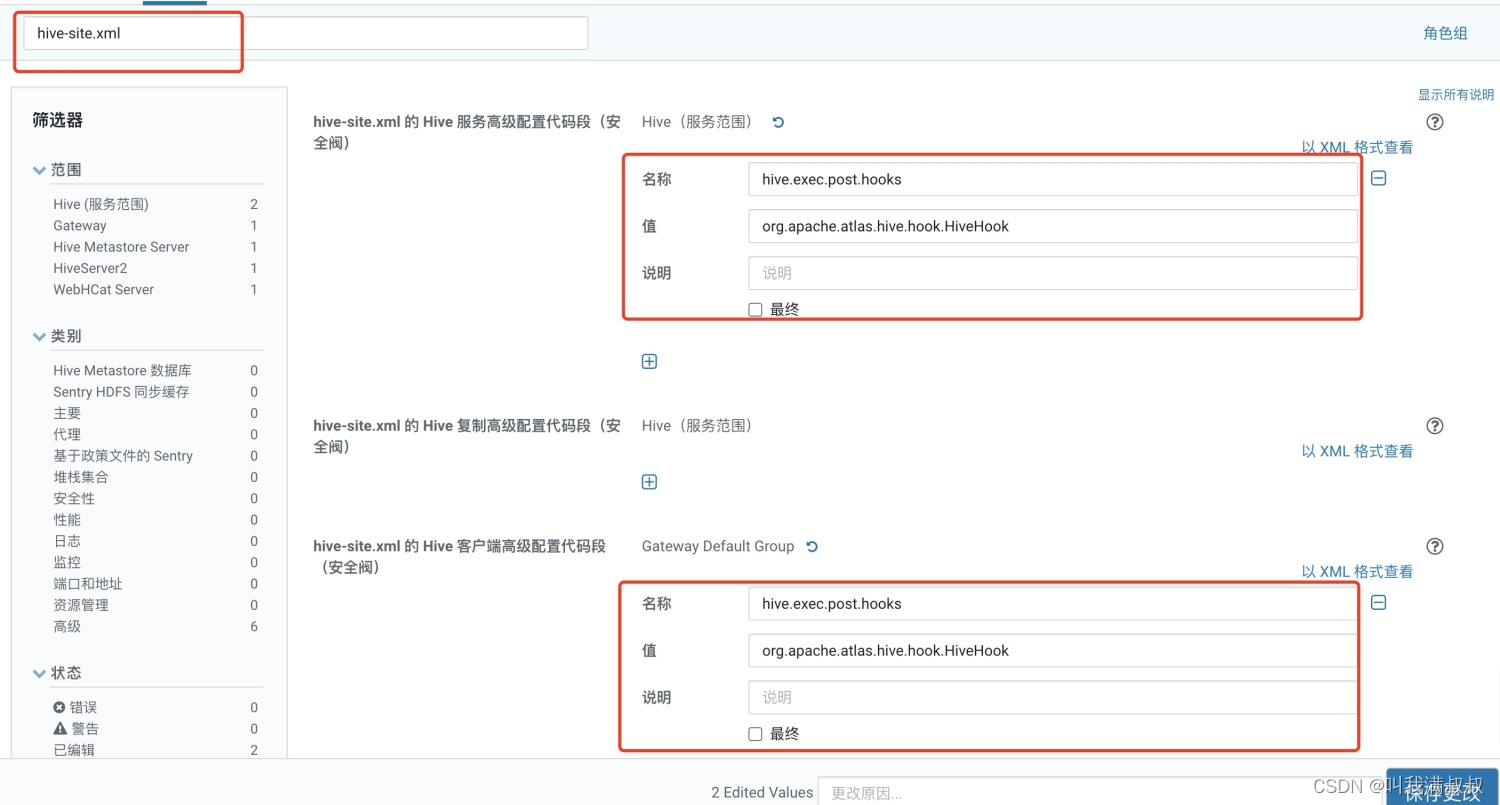
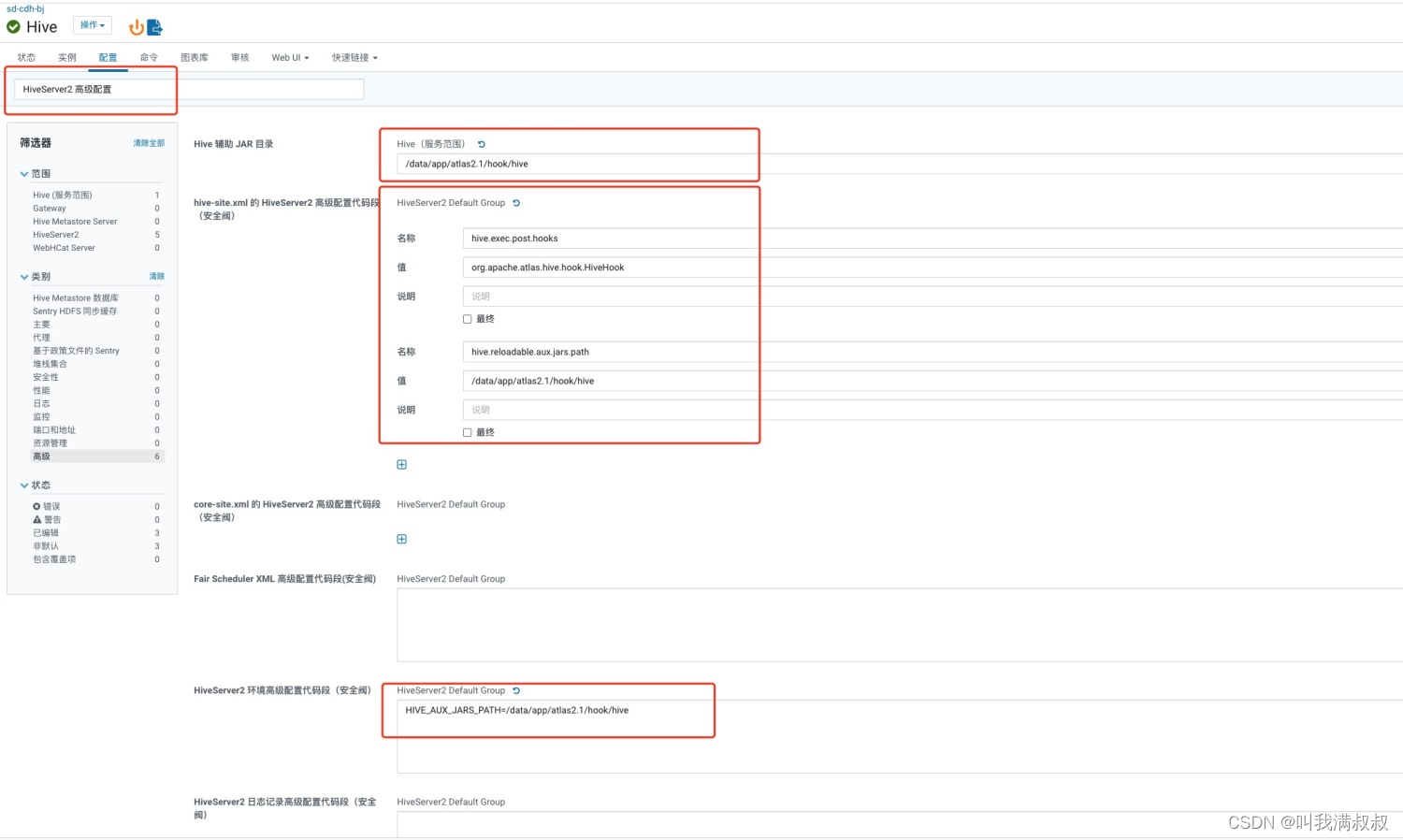
修改【hive-site.xml的Hive服务高级代码段(安全阀)】
名称:hive.exec.post.hooks
值:org.apache.atlas.hive.hook.HiveHook
修改【hive-site.xml的Hive客户端高级代码段(安全阀)】
名称:hive.exec.post.hooks
值:org.apache.atlas.hive.hook.HiveHook,org.apache.hadoop.hive.ql.hooks.LineageLogger
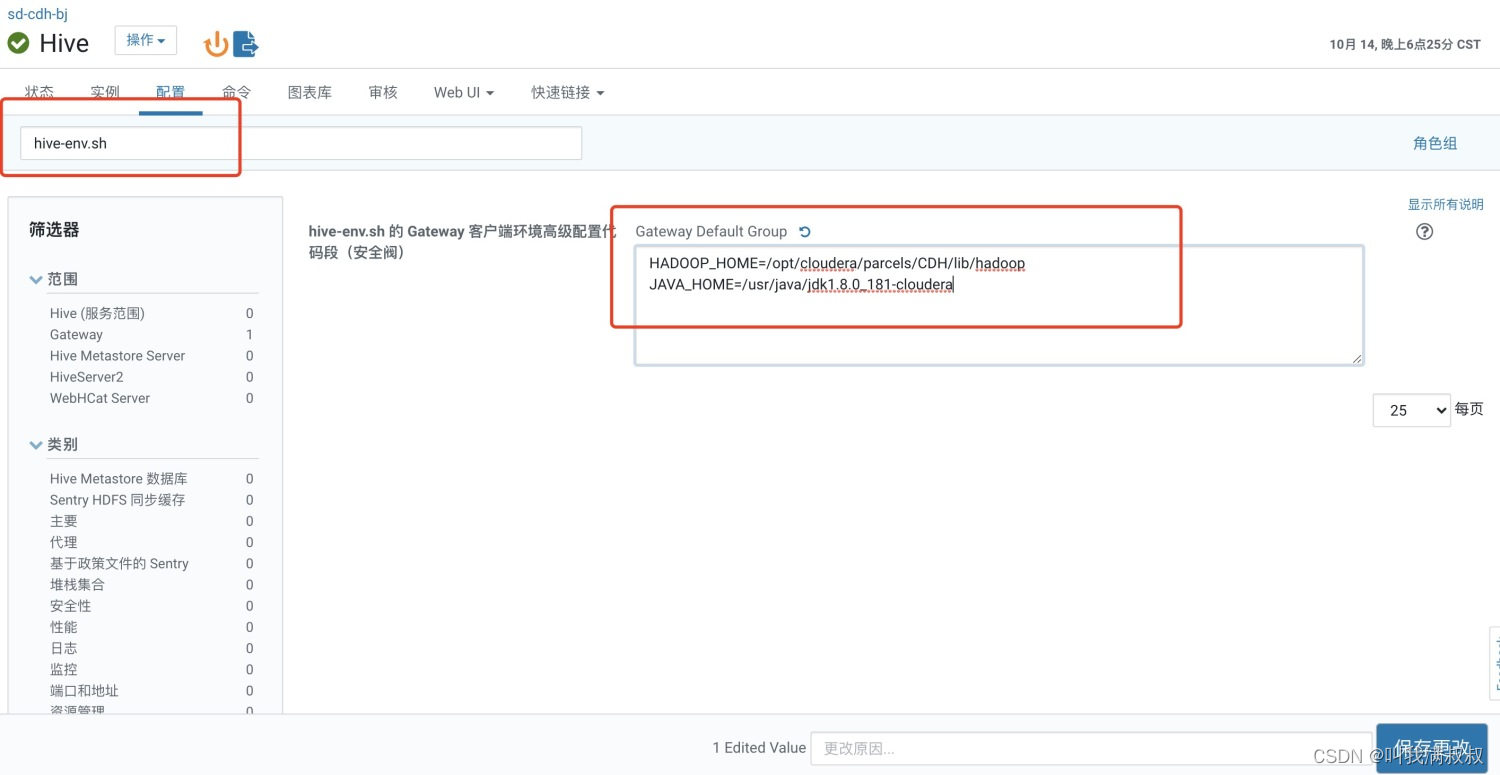
修改 【hive-env.sh 的 Gateway 客户端环境高级配置代码段(安全阀)】
HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop
JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera
修改【Hive 辅助 JAR 目录】
值:/data/app/atlas2.1/hook/hive
修改 【hive-site.xml 的 HiveServer2 高级配置代码段(安全阀)】
名称:hive.exec.post.hooks
值:org.apache.atlas.hive.hook.HiveHook,org.apache.hadoop.hive.ql.hooks.LineageLogger
名称:hive.reloadable.aux.jars.path
值:/data/app/atlas2.1/hook/hive
修改 【HiveServer2 环境高级配置代码段(安全阀)】
HIVE_AUX_JARS_PATH=/data/app/atlas2.1/hook/hive
将配置文件atlas-application.properties添加到atlas2.1/hook/hive的atlas-plugin-classloader-2.1.0.jar
# 切换到Atlas的conf目录下
cd /data/atlas-2.1.0/conf
# 添加
zip -u /data/app/atlas2.1/hook/hive/atlas-plugin-classloader-2.1.0.jar atlas-application.properties
# 将配置文件添加到hive的配置目录下
sudo cp atlas-application.properties /etc/hive/conf
#scp到其他主机hive配置下
scp atlas-application.properties sd-cluster-207、sd-cluster-207:/etc/hive/conf
#集成sqoop
zip -u /data/app/atlas2.1/hook/sqoop/atlas-plugin-classloader-2.1.0.jar atlas-application.properties
scp hook/sqoop/*.jar /opt/cloudera/parcels/CDH/lib/sqoop/lib
cd /opt/cloudera/parcels/CDH/lib/hive/lib && rm -rf jackson-core-2.9.9.jar && rm -rf jackson-annotations-2.9.9.jar && rm -rf jackson-databind-2.10.0.jar
将hive元数据导入Atlas
cd /data/app/atlas2.1/bin
./import-hive.sh

登录Atlas查看hive相关元数据
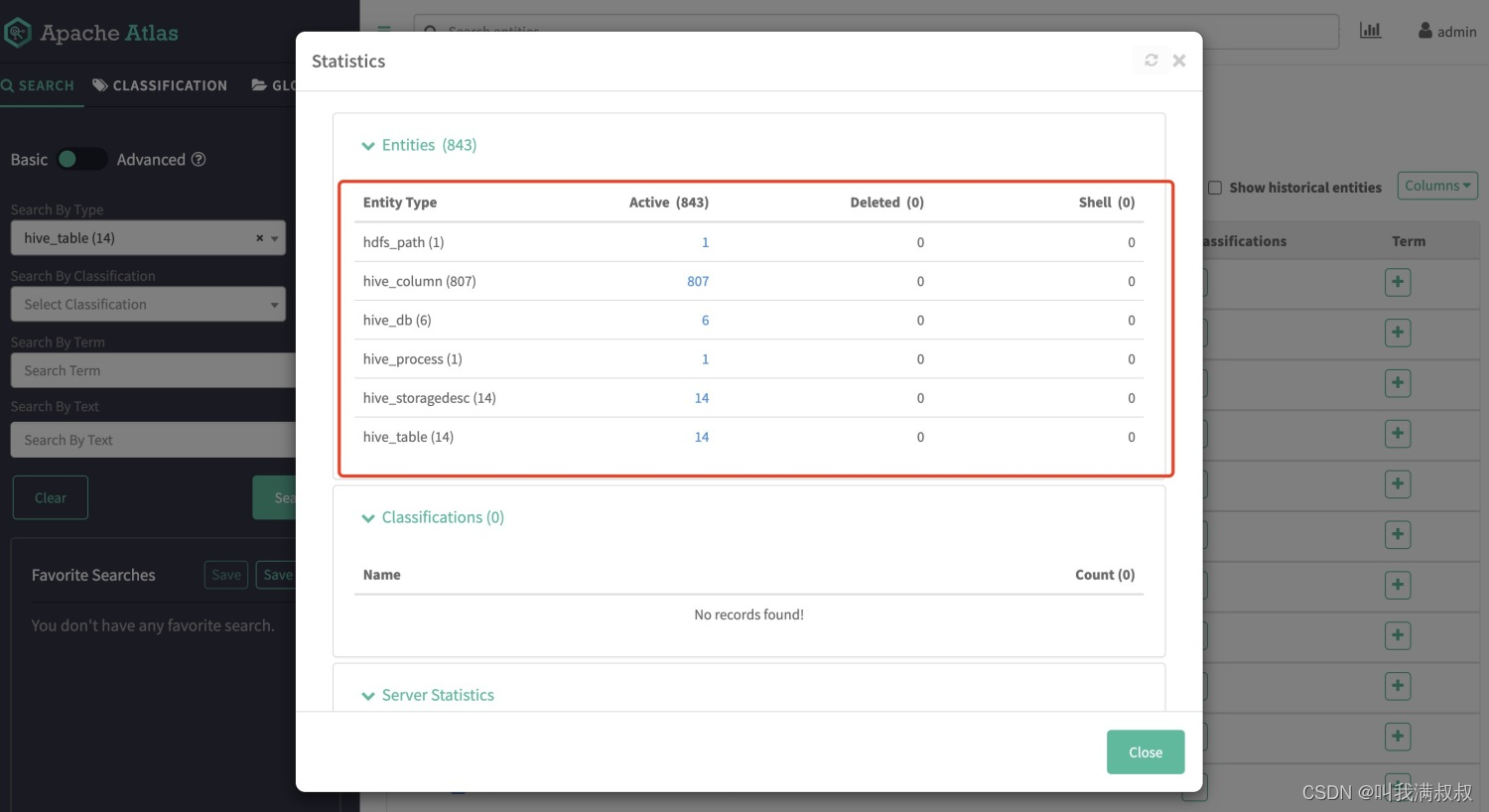
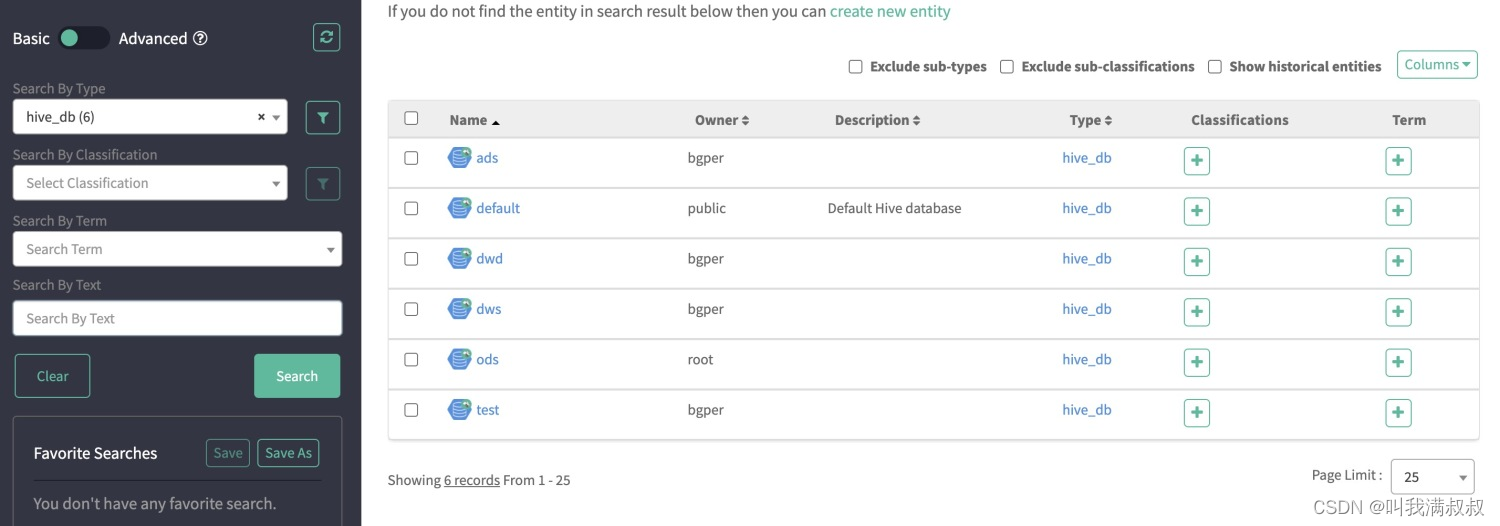
7.验证分析
建表
create table test.atlas1 as select '1' as id,'wangman' as name;
create table test.atlas2 as select '1' as id,'jilin' as address;
create table test.atlas3 as
select a.id as id_x,a.name as name_x,b.address as address_x from test.atlas1 a left join test.atlas2 b on a.id=b.id
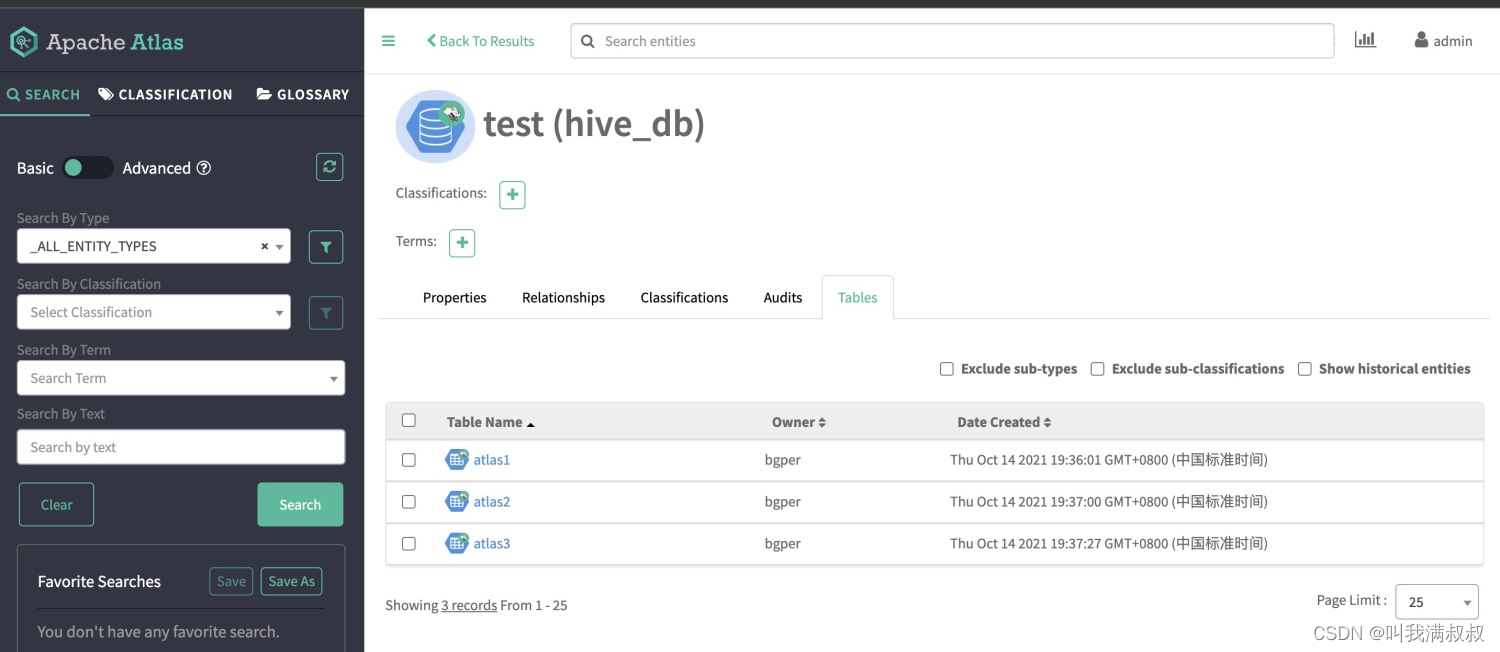
表血缘
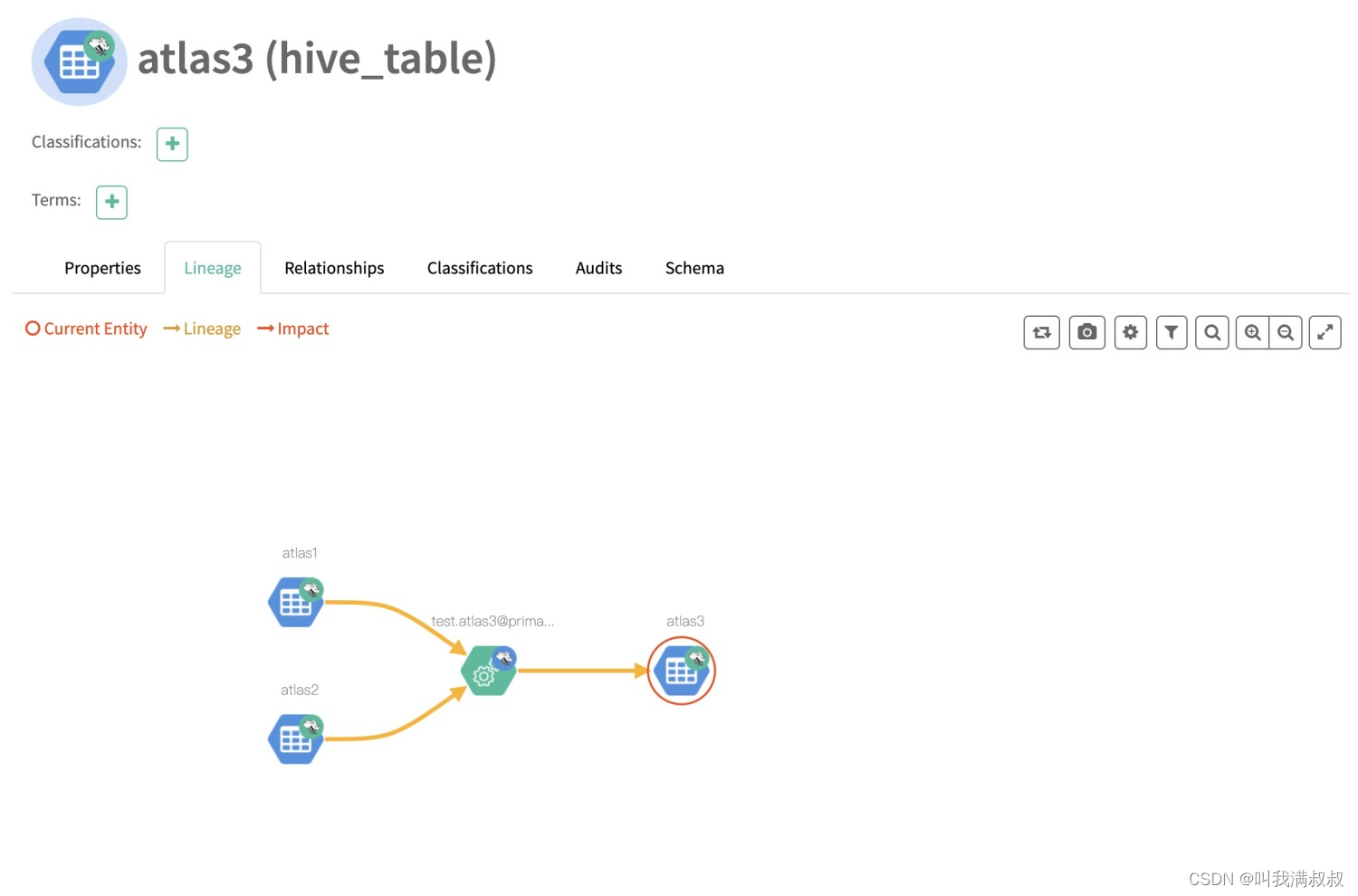
字段血缘
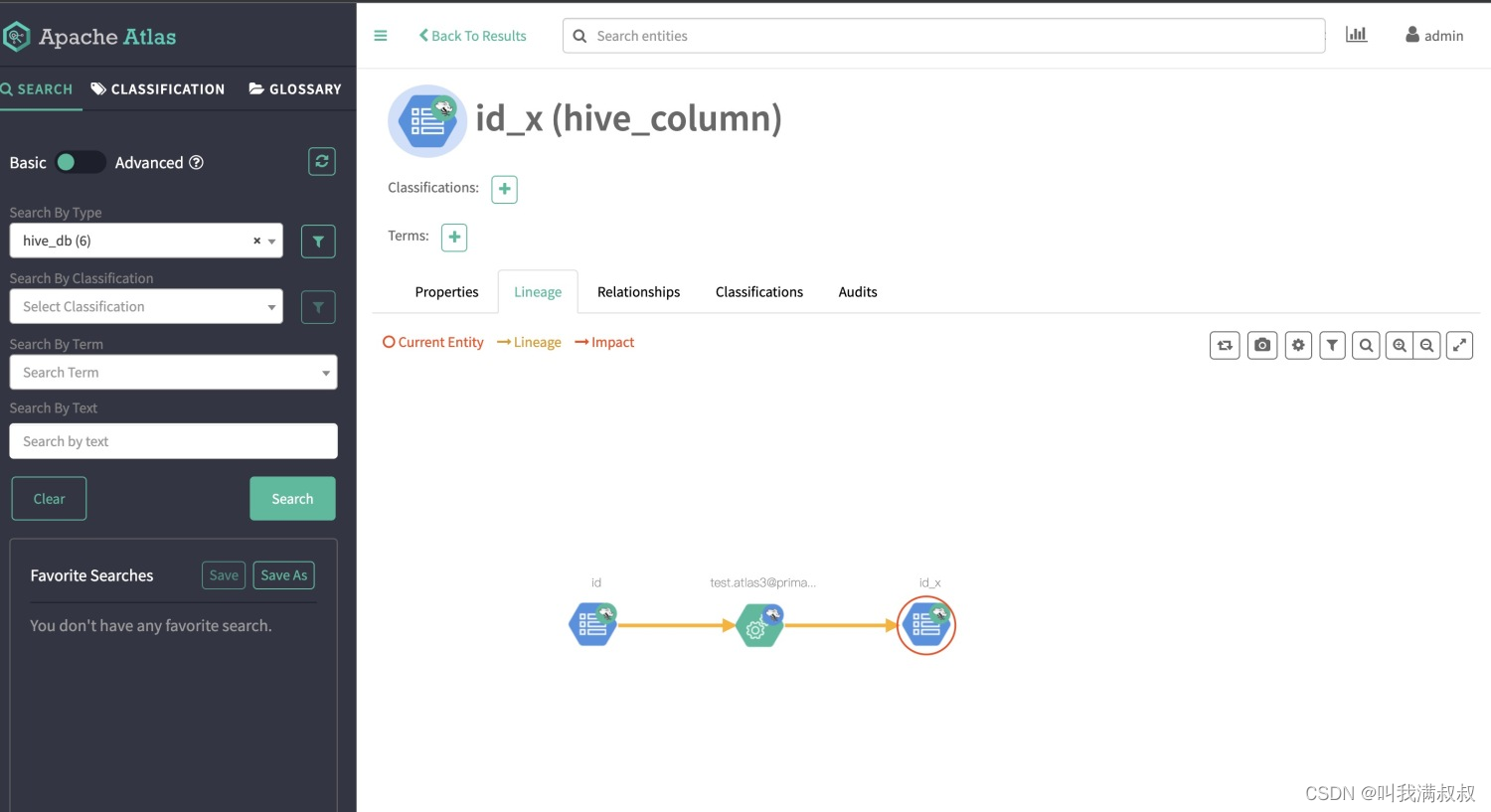
8.Hive comment乱码
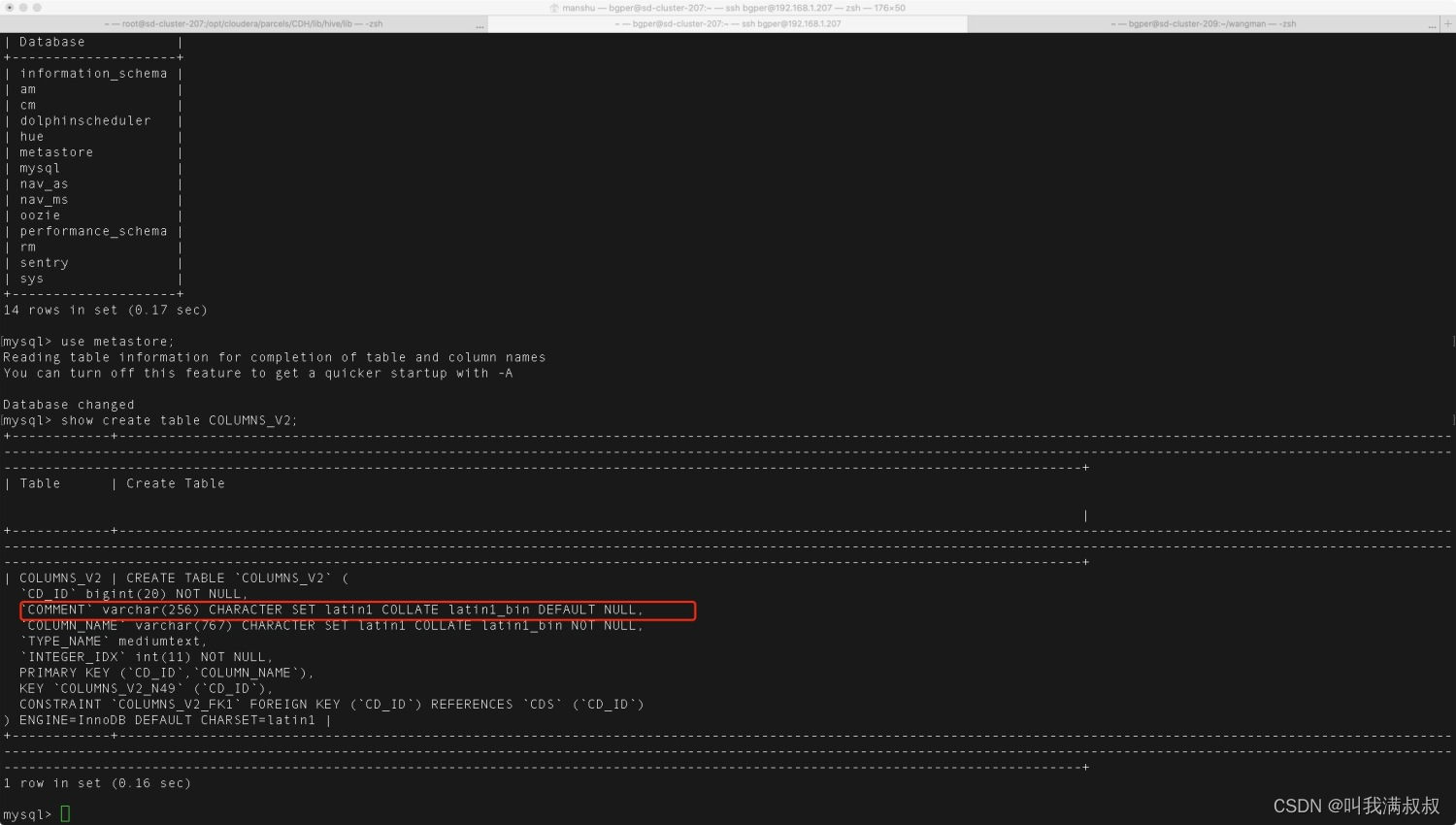
use metastore;
show create table COLUMNS_V2; --查看字符集
#修改字符集为utf-8
#修改表字段注解和表注解
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
#修改分区字段注解
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
#修改索引注解
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
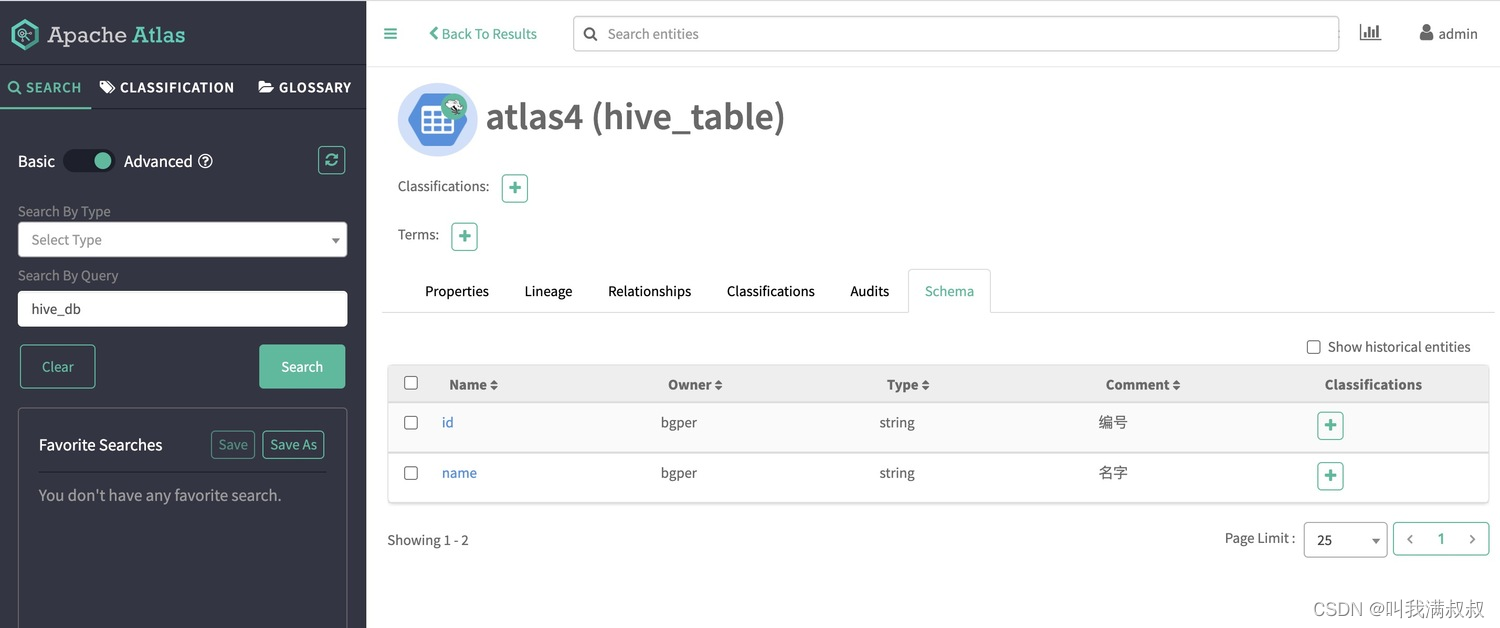
验证
CREATE TABLE `atlas4`(
`id` string comment '编号',
`name` string comment '名字')
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'

















 2576
2576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











