









 本文介绍了元学习方法在小样本图像分类中的应用,探讨了度量学习与MAML等算法原理及其实现思路。
本文介绍了元学习方法在小样本图像分类中的应用,探讨了度量学习与MAML等算法原理及其实现思路。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着准备考研,考公,考教资或者实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
本次分享的课题是
🎯小样本学习中的元学习方法:图像分类的新视角
课题背景与意义
在深度学习快速发展的背景下,图像分类任务的训练通常需要大量标注数据。然而,现实中获取标注数据的成本高昂且耗时,限制了模型的应用。小样本学习正是为了解决这一问题而提出的,通过利用已有知识在少量样本上进行有效学习。元学习方法为小样本学习提供了一种新的视角,通过学习如何学习,可以快速适应新的任务。在图像分类领域,这种方法能够显著降低对标注数据的依赖,提高模型在新任务上的泛化能力,具有重要的理论和实际意义。
技术思路
小样本图像分类任务旨在基于已有的支持集,对查询集中未知图像进行准确分类。具体而言,这类任务通常被称为N-way K-shot图像分类任务,当K值较小(一般为K<10)时,则为小样本图像分类,而K=1时则称为单样本图像分类。以图示为例,若支持集中包含N=3类,每类K=2张图像,目标是将查询集中的Q=4张狗的图像标记为对应的三种犬类。尽管人类在未见过某些犬种的情况下也能轻松完成此任务,但对于人工智能系统而言,这需要借助元学习的方法来提升模型的学习能力。
元学习的核心在于通过学习一系列任务来提高算法在新任务上的表现。根据Thrun和Pratt的定义,元学习不仅关注如何解决特定任务,而是通过不断学习不同任务来逐步提升解决新任务的能力。在小样本图像分类中,元学习模型通过在多种犬种的图像中进行训练,积累经验并优化性能。训练数据集可以是像斯坦福Dogs Dataset这样的图像集,模型在每个episode中选择不同的支持集和查询集进行训练,并通过反向传播更新参数。这种方法使得模型能够有效学习“支持集到查询集标签”的映射关系,从而在面对新任务时表现出更好的分类能力。
元学习模型如何有效解决小样本分类任务是一个关键问题。常用的方法之一是度量学习(Metric Learning),其核心思想在于学习样本之间的距离函数,从而在小样本分类任务中实现良好的效果。度量学习算法通过比较查询集图像与已标记的支持集图像之间的距离来进行分类。具体而言,首先从支持集和查询集中提取图像的特征向量(embeddings),通常使用卷积神经网络(CNN)进行特征提取。接下来,根据查询图像与支持集图像的距离进行分类,常用的距离函数包括欧几里得距离和KNN算法。在每个训练episode结束后,CNN的参数会通过反向传播和损失函数更新,从而逐步优化模型。
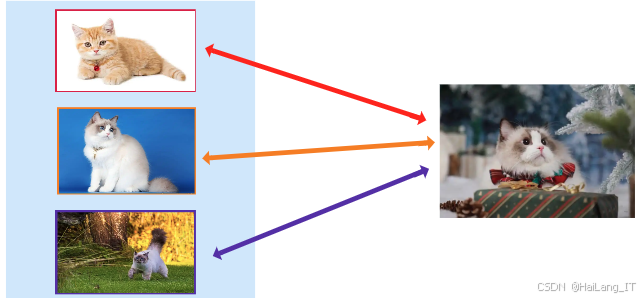
在实际操作中,度量学习算法能够取得显著的分类效果。以匹配网络(Matching Networks)为例,这是第一个运用元学习的度量学习模型,由Oriol Vinyals等人提出。该模型在特征提取方面采用不同的算法,通过余弦相似度比较相似性,并最终使用softmax进行分类。该模型利用LSTM提取图像特征,以全上下文嵌入(Full Context Embedding)的方式,让模型能够自动选择合适的特征进行度量,虽然效果优于传统方法,但对训练时间和计算资源的需求也更高。
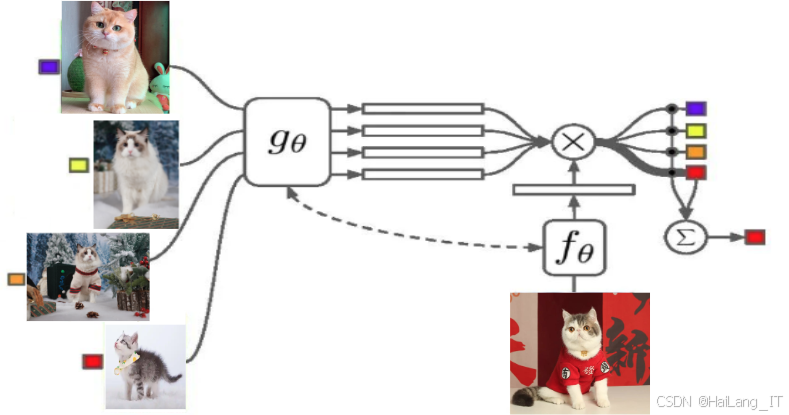
原型网络(Prototypical Networks)则是一个更为简化且高效的度量学习方法。在该网络中,通过提取特征并计算每个类别的原型,即各类图像嵌入的平均值,进行分类时仅需计算查询图像嵌入到原型的欧式距离。这一方法虽然简单,但却能产生SOTA(state-of-the-art)的结果,证明了原型概念在小样本分类任务中的有效性。此后,尽管其他更复杂的度量学习网络不断涌现,原型网络的理念仍被认为是小样本图像分类领域中最具价值的创新之一,极大地推动了该领域的发展。
与模型无关的元学习(MAML)是一种优雅且前景广阔的元学习算法,其核心思想是训练一个神经网络,使其能够在少量训练样本的情况下,快速适应新的分类任务。MAML通过神经网络进行两级反向传播,其训练过程可以简化为四个步骤:首先,创建神经网络的副本并用初始化参数进行设置;接着,在支持集上对网络进行快速微调(fine-tuning),仅需几次梯度下降;然后,将经过微调的网络应用于查询集;最后,通过计算损失函数对原始网络进行反向传播,并更新参数。这一过程在每个episode中重复进行,以便模型能够不断提高适应新任务的能力。
import torch
import torch.nn as nn
import torch.optim as optim
class MAMLModel(nn.Module):
def __init__(self):
super(MAMLModel, self).__init__()
self.fc1 = nn.Linear(784, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = torch.relu(self.fc1(x))
return self.fc2(x)
def maml_train(meta_model, support_set, query_set, num_iterations, inner_lr, outer_lr):
for iteration in range(num_iterations):
# Step 1: Create a copy of the meta-model
model_copy = meta_model.clone() # Assuming a clone method is defined
# Step 2: Fine-tune on the support set
for data, target in support_set:
output = model_copy(data)
loss = nn.CrossEntropyLoss()(output, target)
model_copy.zero_grad()
loss.backward()
for param in model_copy.parameters():
param.data -= inner_lr * param.grad.data # Gradient descent
# Step 3: Evaluate on the query set
query_loss = 0
for data, target in query_set:
output = model_copy(data)
query_loss += nn.CrossEntropyLoss()(output, target)
# Step 4: Update the meta model
meta_model.zero_grad()
query_loss.backward()
for param in meta_model.parameters():
param.data -= outer_lr * param.grad.data # Meta gradient descent
# Define the model and training parameters
meta_model = MAMLModel()
maml_train(meta_model, support_set, query_set, num_iterations=1000, inner_lr=0.01, outer_lr=0.001)尽管MAML在理论上具有强大的适应能力,但在实际应用中,其性能往往不如度量学习。这是由于MAML的两级训练过程导致训练难度加大,超参数搜索复杂,且元反向传播需要计算梯度的梯度,通常只能通过近似值进行训练。因此,在实际应用中,研究者们可能更倾向于使用度量学习算法。然而,MAML的最大优点在于其模型无关性,这意味着该方法可以应用于任何神经网络和任务,使得训练的灵活性大大增强。MAML的开发者Chelsea Finn和Sergey Levine已经成功将其应用于有监督的小样本分类、有监督的回归和强化学习等任务。
🚀海浪学长的作品示例:
大数据算法项目

机器视觉算法项目


微信小程序项目

Unity3D游戏项目

最后💯
🏆为帮助大家节省时间,如果对开题选题,或者相关的技术有不理解,不知道毕设如何下手,都可以随时来问学长,我将根据你的具体情况,提供帮助。

















 5572
5572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









