目录
前言
课题背景和意义
实现技术思路
一、基于机器学习的入侵检测模型
二、基于梯度下降树不同粒度特征的入侵检测
实现效果图样例
最后
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于机器学习的入侵检测技术研究
课题背景和意义
机器学习作为人工智能的核心,是赋予计算机智能的根本途径。机器学习模拟人类的学习行为,能够通过学习已有的知识并重新组织已有的知识结构来不断改善自身的学习能力,从而更高效地学习新的知识。在如今的大数据时代,机器学习应用在人工智能的各个领域,计算机安全领域当然也不例外。随着互联网的飞速发展与广泛普及,网络入侵的种类和数量同样与日俱增, 入侵检测作为计算机系统和网络安全领域的重要组成部分,已经成为当今信息时代的研究热点。
入侵检测的本质是一个分类问题,而机器学习能较好地完成各种分类任务。入侵检测首先要提取计算机系统和网络中的重要特征,然后对这些特征与正常特征以及已知入侵特征加以对比分析,在入侵行为对计算机系统和网络造成负面影响之前就提前发现它,从而找出计算机系统和网络中遭受的入侵行为并采取相应的安全措施消除入侵威胁。然而,传统的入侵检测技术已经难以完成越来越复杂的入侵检测任务,传统的防火墙、用户认证以及数据加密技术,在一定程度上不仅缺乏检测入侵的智能,而且检测效率也较低。因此,我们需要将更智能更高效的技术应用于入侵检测中。
实现技术思路
一、基于机器学习的入侵检测模型
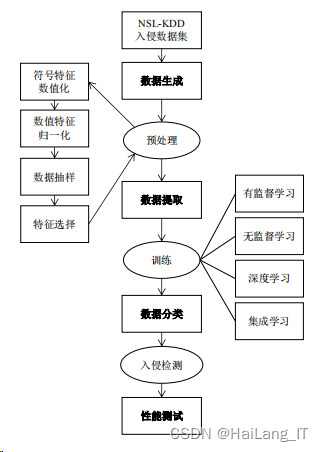
为了达到当今复杂多样的入侵检测要求,国际互联网工程任务组(IETF)针对于入侵检测系统的模型制定,成立了一个专门的小组 IDWG(Intrusion Detection Working Group)。IDWG 制定了一个通用的入侵检测系统模型,这个模型叫做通用入侵检测框架(CIDF),在 CIDF 的基础框架之上,将机器学习算法应用到入侵检测模型的构建中,共包含数据生成、数据提取、数据分类以及性能测试四个阶段。
基于有监督学习的入侵检测
在入侵检测中,有监督意味着可以用已经标记的训练数据调整算法的参数,增强算法对未知入侵类别的检测率。最重要的有监督学习算法有 K 最近邻(K-Nearest
Neighbor, KNN)、朴素贝叶斯(
Naive Bayes, NB
)、支持向量机(
Support Vector Machines, SVM)、决策树(
Decision Trees
)以及人工神经网络(
Artificial Neural Network, ANN)算法。
1)KNN 算法
KNN
算法的基本思想如下:如果一个样本在特征空间中的
K
个最近邻样本大多数属于相同类别,则判定该样本也属于这种类别,即类似于“近朱者赤,近墨者黑”的思想。
KNN
算法具体流程如下。
输入:测试集样本,训练集样本,参数
K
。
输出:测试集样本的预测分类。
①计算当前测试集样本和全部训练集样本之间的距离;
②从小到大的排列这些距离;
③选取与当前样本距离最近的
K
个点;
④计算距离最近的
K
个点所属类别的出现频率;
⑤返回出现频率最高的类别(即当前测试样本的预测类别)。
2)
SVM算法
SVM
是建立在统计学习理论中
VC
维理论和结构风险最小化准则
(Structural Risk Minimization,
SRM
)基础之上的,
要深入理解SVM,首先要引入
统计学习理论。
①统计学习理论
统计学习理论是在样本有限的情况下基于数据的机器学习特例,是研究样本有限的条件下机器学习规律的学科。设训练集𝑆 = {(𝑥𝑖 , 𝑦𝑖)}𝑖=1 𝑚 ,所有的样本(𝑥𝑖 , 𝑦𝑖)独立同分布(Independent and Identical Distribution),则首先定义分类器ℎ𝜃 在训练集上的误差经验风险(Empirical Risk)为R1(ℎ𝜃):
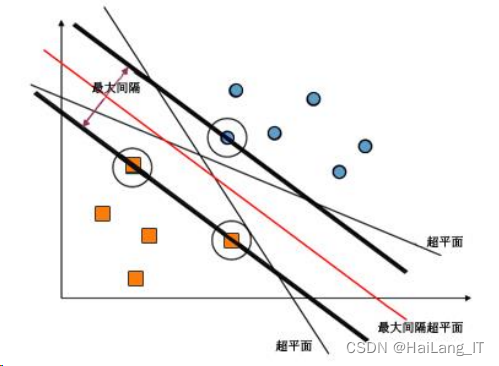
②最大间隔超平面
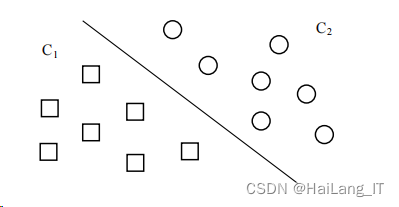
首先引入一个线性二分问题,训练样本集
𝑆 = {(𝑥
𝑖
, 𝑦
𝑖
)}𝑖=1 𝑚 ,𝑦𝑖
∈ {−1,1} 我们要找到一条直线来将 C1
,
C2
两种类别完全分开,如图:
在图中的二维空间,该直线就是线性分类函数,如扩展到 3 维空间,线性分类函数就是一个平面,扩展到多维空间,我们就把这个线性分类函数叫做超平面,由二维平面的分类可以得知,存在无数条能够分开 C1,C2 的超平面,但图中的直线距离两类的样本间隔最大,分割效果最好,将这个最大间隔超平面用函数f(x) = 𝜔 𝑇𝑥 + 𝑏 来表示
凸优化问题
是确定凸集中凸函数的最小化问题,局部最优解和全局最优解一致。 因此为了避免陷入局部最优,尽量选用凸函数作为优化问题的目标函数
首先为目标函数的每一个约束条件添加一个拉格朗日乘子,重新定义一个新的拉格朗日函数,通过该函数将约束条件融合到目标函数中,这样就可以仅用一个包含约束条件的目标函数来说明问题。
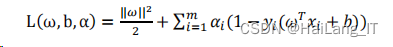
然后讨论优化问题中的
KKT
条件(
Kuhn-Tucker conditions
)。约束条件包含等式约束和不等式约束。等式约束条件下求目标函数的极值点即是符合约束条件下的极值点。
一般地,最优化模型可表示为:
其中
ℎ
𝑖
(𝑥)
表示等式约束,
𝑔
𝑗
(𝑥)
表示不等式约束,p,q 分别表示约束的数量
④核函数
若为非线性数据,
SVM
选择了一种核函数(Kernel Function
)将原始数据映射到高维空间,使得数据在高 维空间线性可分。
SVM
首先在低维原始空间中完成简单的计算,随后利用核函数将低维空间映射到高维空间,最后将分类结果体现在高维特征空间中,构建出最优分离超平面,从而成功划分处于低维空间上的非线性数据。
朴素贝叶斯算法
朴素贝叶斯算法是经典的基于概率的有监督学习算法,也是基于贝叶斯定理和特征条件独立假设的分类方法。
假设样本集
X
包含
n
个特征,X = {𝑥1, 𝑥2 , … , 𝑥𝑛};一共被分为 m 类,类集 Y = {𝑦1, 𝑦2 , … 𝑦𝑚}。面对一个分类问题,根据贝叶斯定理,Y 的后验概率为:
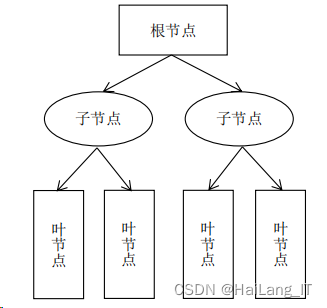
决策树
决策树是通过对样本特征和样本类别之间关系的分析而建立的一种树形结构,如图。在机器学习中,从数据特征内部生成决策树的学习算法称为决策树学习算法,简称决策树。
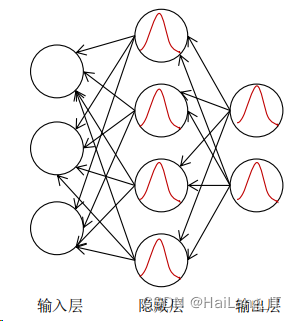
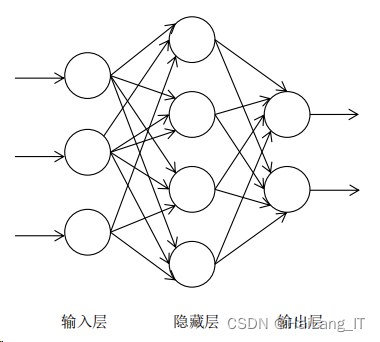
人工神经网络
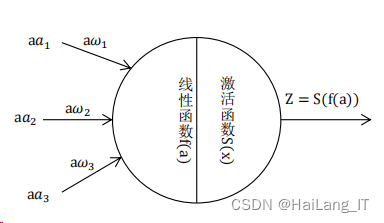
神经网络通过模拟人脑神经元的工作原理建立模型,以神经元为网络中的 基本单位,按照不同的连接方式组成各种结构的网络,它通过调整内部节点之前的相互关系达到并行处理信息的目的。其网络基本结构如图:
在采用线性函数对所有输入数据进行加权求和后,神经元还需要一个非线性函数对数据进行训练,称该非线性函数为激活函数。有了激活函数,就可以为一个神经元进行完整的建模。
在神经网络模型中,由于模型复杂节点繁多,计算梯度的复杂度很高,因此我们利用神经网络的结构,从网络的输出层开始依次求得参数的梯度,根据链锁规则以及隐式求导规则给出损失项之间的迭代公式,从输出层反向传播到输入层,求得每个节点的损失,再求得参数的更新值更新权重。
基于无监督学习的入侵检测
1)K-means
算法
K-means 在原理 上和 KNN 有相似之处。k 均值聚类算法(k-means clustering algorithm)是一种迭代求解的划分聚类算法。
K-means
算法具体流 程如下
输入:包含
n
个样本点的样本集
D
,聚类中心数
K
,停止条件
ε
。
输出:样本集
D
的
K
个聚类中心。
①在样本集
D
中随机选择
K
个样本点作为初始聚类中心;
②分别计算 n 个样本点到 K 个聚类中心的欧氏距离;
③将每个样本点划分到欧氏距离最小的聚类中心类别中;
④分别计算 K 个聚类中心类别中所含样本点的均值;
⑥迭代计算以上步骤直到聚类中心变化小于ε,返回 K 个聚类中心。
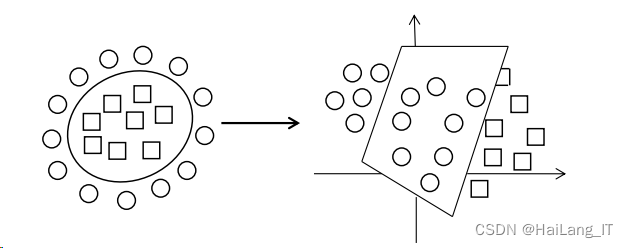
2)DBSCAN
算法
DBSCAN
算法全称为
Density Based Spatial Clustering of Applications with Noise,属于基于密度聚类算法中的代表算法。
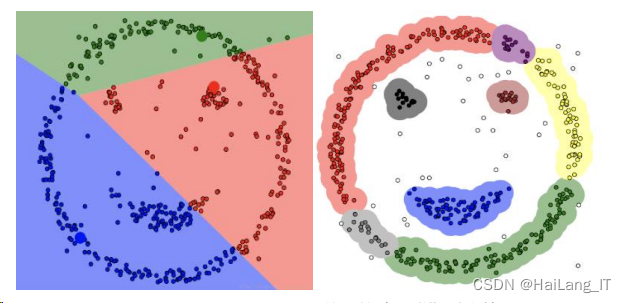
K-Means 和 DBSCAN 分别对“笑脸数据”进行聚类的结果如图:
3)EM 算法
EM
(
Expectation Maximization algorithm, 最大期望算法)算法一种基于高斯混合模型(Gaussian Mixture Model),通过迭代进行极大似然估计的聚类算法。EM 算法计算概率,将每种聚类当作成一个高斯模型,采用这种多元高斯概率分布模型来预测样本中任意样本点属于某种聚类的概率。
二、基于梯度下降树不同粒度特征的入侵检测
GBDT
梯度下降树,即
GBDT
(
Gradient Boosting Decision Tree
),在
2001 年由Friedman提出,属于一种基于决策树的梯度提升方法。GBDT 是采用加法模型 (即弱分类器的线性组合),通过不断减小训练过程中产生的误差来达到将数据分类或者回归的算法。
特征工程
理想的数据和特征是机器学习要达成的最终目标,而模型和算法不过仅是为 了接近最终目标而采用的方法。特征工程的本质就是更好地从原始数据中提取特征,并应用于合适的算法和模型。
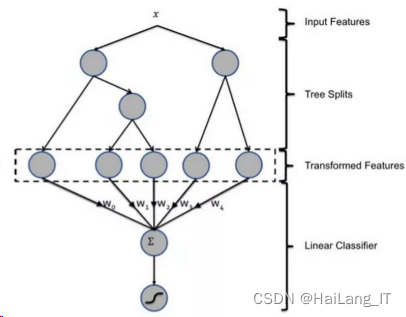
GBDT 特征构造原理
GBDT
是一种常用的非线性模型,基于集成学习中
boosting
的思想, GBDT 本身能够寻找到多种特征组合,因此省略了手动寻找特征和特征组合的步骤。
GBDT
特征构造原理如图 :
基于 NSL-KDD 的 GBDT 特征构造
1)数据整理
①符号特征数值化
首先要将字符型数据转化为数值型数据。对于离散型的字符数据,采用标签编码(Label Encoder)的方法将其转化为连续的数值型数据。
②数值特征归一化
原始数据集中的 38 种数值特征其取值范围各不相同,因此在训练特征前需要对所有特征实施归一化处理。
2)GBDT 的训练过程
GBDT 的训练过程如图 :
GBDT 通过多轮迭代,每一轮都生成一个弱分类器,同时基于前一轮分类器的残差进行训练。弱分类器的结构通常比较简单,并且具有低方差、高偏差的特点。
基于
GBDT
不同粒度特征的入侵检测
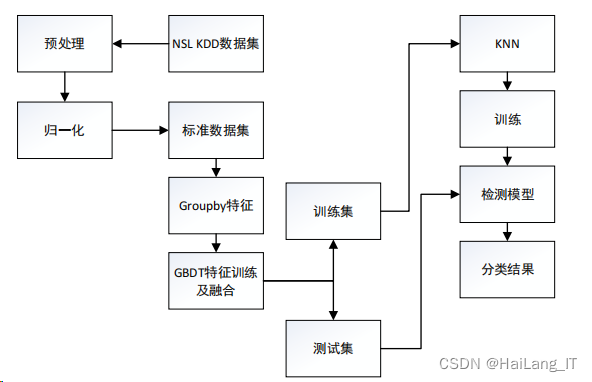
基于
GBDT
不同粒度特征的入侵检测示意图如图:
实现效果图样例
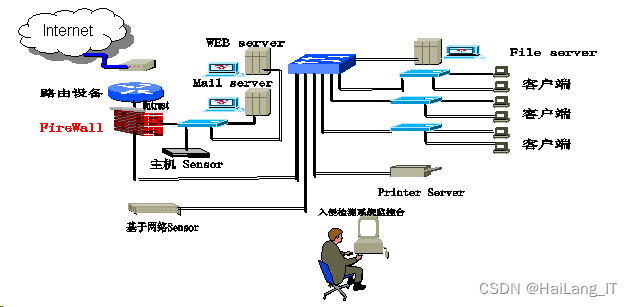
用于入侵检测系统的快速字符串匹配算法:
我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!
最后











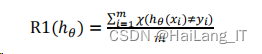
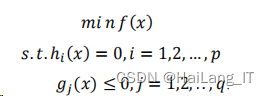
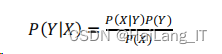


















 1298
1298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









