







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的电梯电动车异常行为识别
课题背景和意义
电梯作为现代建筑中不可或缺的垂直交通工具,其安全性和可靠性直接关系到人们的生命财产安全。电梯电动车是电梯核心的驱动部件,其故障可能导致电梯停运甚至安全事故。因此,及时、准确地检测电梯电动车的运行状态与故障情况显得尤为重要。传统的电梯电动车检测方法往往依赖人工巡检,存在效率低、漏检和误检等问题。通过构建自制数据集并应用深度学习算法,可以显著提高电梯电动车故障检测的准确性与实时性,从而为电梯的安全运行提供有力的技术支持。
实现技术思路
一、算法理论基础
1.1 卷积神经网络
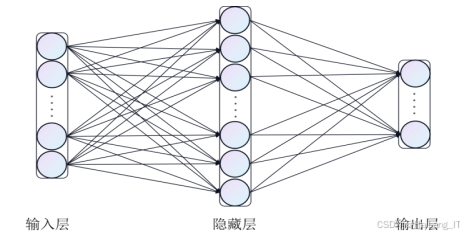
卷积神经网络是深度学习的重要组成部分,在计算机视觉领域得到广泛应用。其主要结构由输入层、卷积层、池化层、全连接层及输出层构成。卷积层通常由卷积模块、批归一化层和激活函数三部分组成。当一张图像输入网络时,卷积层与池化层作为特征提取器,通过多次堆叠的卷积和池化操作提取图像中的特征信息,随后输入到全连接层以完成分类、检测、分割等任务。以下介绍卷积神经网络的基本组件及其作用。
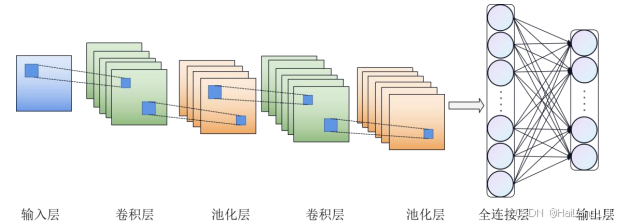
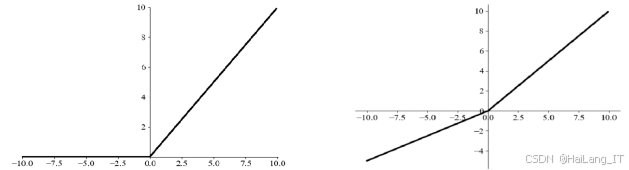
卷积层是卷积神经网络的主体,主要由卷积核尺寸、步长及填充尺寸定义。卷积核中的每个元素都对应一个权重系数和一个偏置量,这些参数通过反向传播算法进行优化。在卷积训练过程中,输入参数不断更新,当前一层参数改变时,后一层输入的分布也在变化。。批归一化层的作用是将网络的输出规范化到合适的分布范围内,降低网络对输入参数的敏感度,有效提升收敛速度,确保网络的稳定性。卷积过程中,权重赋值的操作通常由线性计算主导,因此通过卷积操作得到的输出值相当于线性矩阵乘法,难以有效反映目标类别特征。
池化层的作用是以输出值代表区域特征。常见的池化方式有最大池化和平均池化。最大池化保留每个池化核覆盖区域的最大值,而平均池化计算该区域的平均值。池化层通过对输入特征图进行下采样降维,使网络聚焦有效特征,并将这些代表性特征作为下一层的输入,从而减少模型的参数和计算量。全连接层位于网络末端,综合上述信息,起到“分类器”的作用。在全连接过程中,每个神经元与上一层的神经元相连,能够涉及到输入特征图的每个像素区域,筛选保留前层多次操作得到的深层抽象特征,并将这些特征映射到样本标记空间。
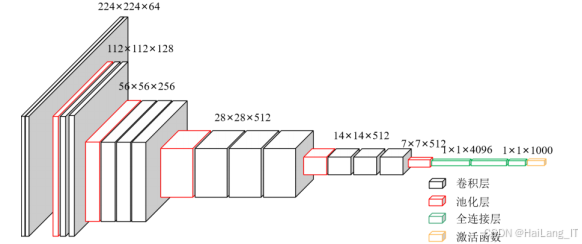
VGG网络是一种深度卷积神经网络模型,其主要贡献在于通过深层网络架构和使用小尺寸卷积核来提高图像分类的性能。VGG网络通常使用3x3的小卷积核,通过连续堆叠多个卷积层来增加网络的深度,同时在每个卷积层后面跟随ReLU激活函数以引入非线性。该网络还使用2x2的最大池化层来逐步减小特征图的尺寸,从而降低计算复杂度。VGG网络的设计理念在于保持一致的结构,使得网络更容易训练并具有更好的泛化能力。
ResNet是一种深度学习模型,专门为解决深度网络训练中的退化问题而设计。ResNet的核心创新在于引入了残差学习的理念,通过添加“跳跃连接”来直接连接输入和输出。这种结构使得信息可以在网络中更有效地传播,减轻了梯度消失的问题,允许网络的深度可以达到更高层次。ResNet的基本单元是残差块,每个残差块包含两个或三个卷积层及一个跳跃连接。通过这种方式,网络可以学习到输入与输出之间的残差,而不是直接学习输出。ResNet使用了多个变体,如ResNet50、ResNet101和ResNet152,数字表示网络的层数。得益于残差结构,ResNet在极深的网络中依然能够保持良好的训练效果,成为了许多计算机视觉任务中的主流选择。
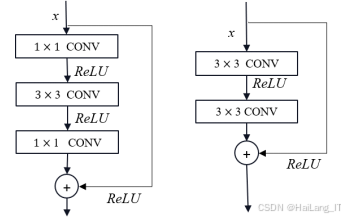
VGG和ResNet在设计理念和架构上存在显著差异。VGG采用了深层次的卷积层堆叠方式,注重使用小卷积核来提取特征,但由于参数量庞大,训练和推理时计算开销较高。相对而言,ResNet通过引入残差连接,增强了深层网络的训练能力,显著改善了梯度传递,允许构建更深的网络。尽管VGG在某些任务中表现优秀,ResNet因其更高的可训练性和较低的计算需求,成为了现代深度学习中的重要网络架构。
1.2 目标检测算法
基于深度学习的目标检测算法主要分为双阶段检测方法和单阶段检测方法。双阶段检测方法借鉴传统目标检测流程,首先进行候选区域的预测,初步筛选目标,然后对候选区域中的目标进行精细检测。这种方法检测速度较慢,难以满足实时检测需求。单阶段检测方法直接根据提取的特征预测目标的类别概率与位置坐标,检测速度较快,能够满足实时检测需求。
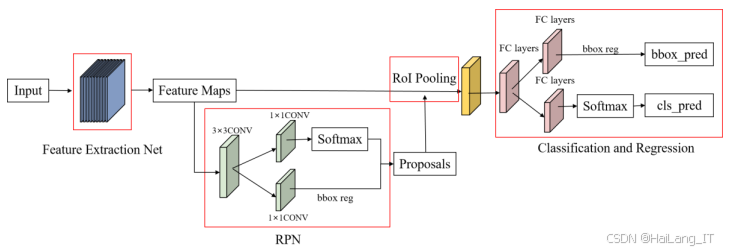
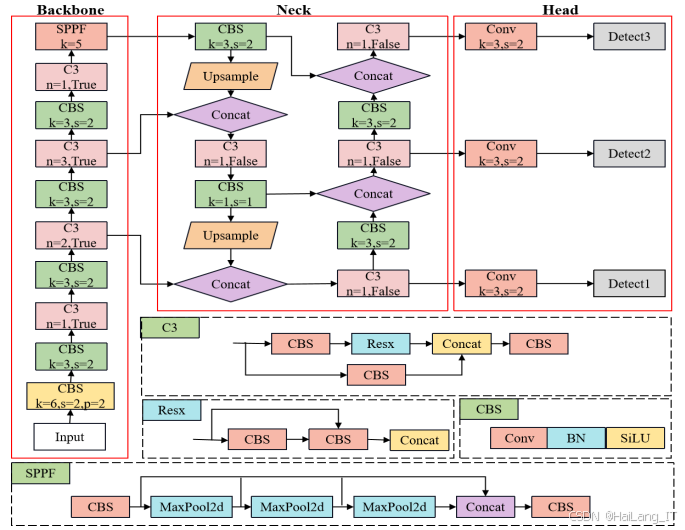
YOLO作为单阶段深度学习模型,能直接从输入图像中检测和定位目标。卷积神经网络提取图像中目标的特征,利用多尺度特征融合结构和多锚框预测来检测和定位目标。YOLO的优势在于其实时性,支持不同图像分辨率,易于部署。YOLOv5是当前YOLO系列中最为稳定和广泛应用的版本,YOLOv5算法由输入端、主干网络、颈部和头部组成,旨在高效进行目标检测。输入端通过Mosaic数据增强、自适应锚框计算和自适应图片缩放进行数据预处理,以改善数据集的多样性和均衡性。在训练过程中,基于预设锚框输出目标预测框,并与真实边框进行比较以更新模型。主干网络使用C3模块和空间金字塔池化快速(SPPF)模块提取特征,降低计算量并提升模型精度。颈部结合FPN和PAN结构,传递语义信息与定位信息,增强模型检测能力。头部通过1×1卷积扩展不同尺度特征图,计算预测框的中心点、宽度、高度和置信度,提供检测结果的可信度。
二、 数据集
2.1 数据集
图像采集可以通过自主拍摄获取真实场景中的电梯及电动车图像,确保数据的真实有效性。此外,还可以利用互联网资源,爬取公开的相关图像,以增加数据的多样性和丰富性。这种结合方式有助于构建一个全面的图像库,涵盖不同电梯环境和电动车外观。使用标注工具(如LabelImg)对采集到的图像进行详细标注。标注的内容主要包括电动车的位置、大小和类别信息。通过精准的标注,可以为后续的模型训练提供高质量的数据支持。

2.2 数据扩充
数据集需要进行划分与扩展。数据集通常会被划分为训练集、验证集和测试集,以便于模型的训练与评估。在划分后,采用数据扩展技术,如随机裁剪、旋转、翻转和颜色抖动等方法,进一步增加数据量。
三、实验及结果分析
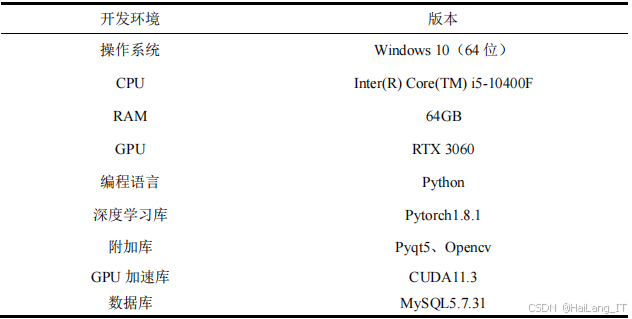
3.1 实验环境搭建
3.2 模型训练
通过自主拍摄和互联网采集相结合的方式,收集电梯内及电动车的图像。自主拍摄确保图像数据在真实场景中的有效性,能够涵盖不同的电梯类型和电动车外观。互联网采集则可以快速获取大量的公开图像,以扩展数据集的多样性。使用如LabelImg等工具,对图像中的电动车进行框选和标注。标注过程包括确定电动车的位置、大小和类别信息,确保标注的准确性和一致性。完成数据标注后,需要对数据集进行划分与扩展。
# 示例:使用Albumentations进行数据扩展
from albumentations import Compose, RandomCrop, HorizontalFlip, ColorJitter
import cv2
# 定义数据扩展的变换
transform = Compose([
RandomCrop(width=640, height=640),
HorizontalFlip(p=0.5),
ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2),
])
# 读取图像
image = cv2.imread('captured_image.jpg')
augmented = transform(image=image)
augmented_image = augmented['image']
# 保存扩展后的图像
cv2.imwrite('augmented_image.jpg', augmented_image)选择合适的目标检测算法,如YOLOv5,进行模型的配置和训练。设置训练参数,如学习率、批处理大小和训练周期等。使用训练集进行模型训练,同时利用验证集监控模型的性能,以防止过拟合。训练过程中,模型会不断调整权重,以提高目标检测的准确性。
# 示例:使用YOLOv5进行模型训练
!python train.py --img 640 --batch 16 --epochs 50 --data custom_data.yaml --weights yolov5s.pt --device 0训练完成后,使用测试集对模型进行评估。通过计算不同IoU阈值下的平均精确度均值(mAP)等指标,评估模型在电梯电动车检测任务中的性能。根据评估结果,可以进一步调整模型结构和超参数,以优化检测效果。
# 示例:使用YOLOv5进行模型评估
!python val.py --weights best.pt --data custom_data.yaml --img 640 --iou-thres 0.5
# 输出mAP及其他评估指标海浪学长项目示例:



最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

















 2688
2688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









