







监督学习
监督学习中的数据集是有标签的,就是说对于给出的样本我们是知道答案的。如果机器学习的目标是通过建模样本的特征x和标签y之间的关系:f(x,theta)或f(y|x,theta),并且训练集中的每个样本中都有标签,成为监督学习。根据标签类型的不同,又可以分为**分类问题和回归问题。**前者是预测某样东西所属的类别,比如给定一个人的身高、年龄、体重等信息,然后判断性别、是否健康等;后者则是预测某个样本所对应的实数输出,比如预测某一地区人的平均身高。常见的监督学习算法有:k-近邻算法、决策树、朴素贝叶斯等。
无监督学习
无监督学习中的数据集是完全没有标签的,依据相似样本在数据空间中一般距离较近这一假设,将样本分类。常见的算法包括:稀疏自编码、K-Means算法等。可以解决关联分析、聚类问题和维度约减。
- 关联分析是指发现不同事物之间同时出现的概率。
- 聚类问题是将相似的样本划分为一个簇,与分类问题不同,聚类问题预先并不知道类别,自然训练数据也没有类别的标签。
- 维度约简是指减少数据维度的同时保证不丢失有意义的信息。利用特征提取方法和特征选择方法,可以达到维度约简的效果。
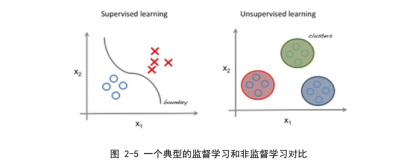
- 由上图知道,左图是对一群有标签数据的分类,而右图是对一群无标签数据的聚类。
半监督学习
半监督学习一般针对的问题是数据量大,但是标签数据少或者说标签数据的获取很难很贵的情况,训练的时候有一部分是有标签的,而有一部分是没有的。两种常见的学习方式是直推学习和归纳学习。
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8948
8948











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









