






数据集:
https://download.csdn.net/download/qq_37401291/87392009
# Import necessary libraries
import numpy as np
import pandas as pd
import seaborn as sns
from pylab import rcParams
import matplotlib.pyplot as plt
from matplotlib import rc
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report
from collections import defaultdict
from textwrap import wrap
# Torch ML libraries
import transformers
from transformers import BertModel, BertTokenizer, AdamW, get_linear_schedule_with_warmup
import torch
from torch import nn, optim
from torch.utils.data import Dataset, DataLoader
# Misc.
import warnings
warnings.filterwarnings('ignore')
import datetime
# 获得计算机当前时间
starttime = datetime.datetime.now()
# Set intial variables and constants
# % config InlineBackend.figure_format='retina'
# Graph Designs
sns.set(style='whitegrid', palette='muted', font_scale=1.2)
HAPPY_COLORS_PALETTE = ["#01BEFE", "#FFDD00", "#FF7D00", "#FF006D", "#ADFF02", "#8F00FF"]
sns.set_palette(sns.color_palette(HAPPY_COLORS_PALETTE))
rcParams['figure.figsize'] = 12, 8
# Random seed for reproducibilty
RANDOM_SEED = 42
np.random.seed(RANDOM_SEED)
torch.manual_seed(RANDOM_SEED)
# Set GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
df = pd.read_csv('D:/2022/code/ai/nlp-learn/reviews.csv')
df.shape
(12495, 12)
df
| reviewId | userName | userImage | content | score | thumbsUpCount | reviewCreatedVersion | at | replyContent | repliedAt | sortOrder | appId | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | gp:AOqpTOEhZuqSqqWnaKRgv-9ABYdajFUB0WugPGh-SG-... | Eric Tie | https://play-lh.googleusercontent.com/a-/AOh14... | I cannot open the app anymore | 1 | 0 | 5.4.0.6 | 2020-10-27 21:24:41 | NaN | NaN | newest | com.anydo |
| 1 | gp:AOqpTOH0WP4IQKBZ2LrdNmFy_YmpPCVrV3diEU9KGm3... | john alpha | https://play-lh.googleusercontent.com/a-/AOh14... | I have been begging for a refund from this app... | 1 | 0 | NaN | 2020-10-27 14:03:28 | Please note that from checking our records, yo... | 2020-10-27 15:05:52 | newest | com.anydo |
| 2 | gp:AOqpTOEMCkJB8Iq1p-r9dPwnSYadA5BkPWTf32Z1azu... | Sudhakar .S | https://play-lh.googleusercontent.com/a-/AOh14... | Very costly for the premium version (approx In... | 1 | 0 | NaN | 2020-10-27 08:18:40 | NaN | NaN | newest | com.anydo |
| 3 | gp:AOqpTOGFrUWuKGycpje8kszj3uwHN6tU_fd4gLVFy9z... | SKGflorida@bellsouth.net DAVID S | https://play-lh.googleusercontent.com/-75aK0WF... | Used to keep me organized, but all the 2020 UP... | 1 | 0 | NaN | 2020-10-26 13:28:07 | What do you find troublesome about the update?... | 2020-10-26 14:58:29 | newest | com.anydo |
| 4 | gp:AOqpTOHls7DW8wmDFzTkHwxuqFkdNQtKHmO6Pt9jhZE... | Louann Stoker | https://play-lh.googleusercontent.com/-pBcY_Z-... | Dan Birthday Oct 28 | 1 | 0 | 5.6.0.7 | 2020-10-26 06:10:50 | NaN | NaN | newest | com.anydo |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 12490 | gp:AOqpTOEQPqib7pb6vFyjMY9JEfsMs_u8WCdqg6mbcar... | Mildred Olima | https://play-lh.googleusercontent.com/a-/AOh14... | I really like the planner, it helps me achieve... | 5 | 0 | 4.5.4 | 2018-12-21 00:13:09 | NaN | NaN | newest | com.appxy.planner |
| 12491 | gp:AOqpTOE1KKOOVVKUfhAfXQs2NfJpoywfucrJCMK3Hmu... | Roaring Grizzly Bear | https://play-lh.googleusercontent.com/a-/AOh14... | 😁****😁 | 5 | 0 | NaN | 2018-12-12 21:52:56 | NaN | NaN | newest | com.appxy.planner |
| 12492 | gp:AOqpTOFEn5UgYYggqiHKauDJVLLN8-16nk1AfZbEhkj... | amirbadang | https://play-lh.googleusercontent.com/-CM2FcrU... | Very useful apps. You must try it | 5 | 0 | 4.5.4 | 2018-12-11 15:49:43 | NaN | NaN | newest | com.appxy.planner |
| 12493 | gp:AOqpTOHOH6YdYLR91qZdYpeIVkMI-LeAE0EwYgrctid... | Emma Stebbins | https://play-lh.googleusercontent.com/-oCj6g6k... | Would pay for this if there were even more add... | 5 | 0 | 4.5.4 | 2018-12-06 04:59:26 | NaN | NaN | newest | com.appxy.planner |
| 12494 | gp:AOqpTOFuJtS1McUdEZuLCnRn7k-UUcGNml7XqxKTSk2... | DAVOR SPASENOSKI | https://play-lh.googleusercontent.com/a-/AOh14... | Sooow good | 5 | 0 | 4.5.4 | 2018-11-26 01:19:13 | NaN | NaN | newest | com.appxy.planner |
12495 rows × 12 columns
df.head()
| reviewId | userName | userImage | content | score | thumbsUpCount | reviewCreatedVersion | at | replyContent | repliedAt | sortOrder | appId | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | gp:AOqpTOEhZuqSqqWnaKRgv-9ABYdajFUB0WugPGh-SG-... | Eric Tie | https://play-lh.googleusercontent.com/a-/AOh14... | I cannot open the app anymore | 1 | 0 | 5.4.0.6 | 2020-10-27 21:24:41 | NaN | NaN | newest | com.anydo |
| 1 | gp:AOqpTOH0WP4IQKBZ2LrdNmFy_YmpPCVrV3diEU9KGm3... | john alpha | https://play-lh.googleusercontent.com/a-/AOh14... | I have been begging for a refund from this app... | 1 | 0 | NaN | 2020-10-27 14:03:28 | Please note that from checking our records, yo... | 2020-10-27 15:05:52 | newest | com.anydo |
| 2 | gp:AOqpTOEMCkJB8Iq1p-r9dPwnSYadA5BkPWTf32Z1azu... | Sudhakar .S | https://play-lh.googleusercontent.com/a-/AOh14... | Very costly for the premium version (approx In... | 1 | 0 | NaN | 2020-10-27 08:18:40 | NaN | NaN | newest | com.anydo |
| 3 | gp:AOqpTOGFrUWuKGycpje8kszj3uwHN6tU_fd4gLVFy9z... | SKGflorida@bellsouth.net DAVID S | https://play-lh.googleusercontent.com/-75aK0WF... | Used to keep me organized, but all the 2020 UP... | 1 | 0 | NaN | 2020-10-26 13:28:07 | What do you find troublesome about the update?... | 2020-10-26 14:58:29 | newest | com.anydo |
| 4 | gp:AOqpTOHls7DW8wmDFzTkHwxuqFkdNQtKHmO6Pt9jhZE... | Louann Stoker | https://play-lh.googleusercontent.com/-pBcY_Z-... | Dan Birthday Oct 28 | 1 | 0 | 5.6.0.7 | 2020-10-26 06:10:50 | NaN | NaN | newest | com.anydo |
df.isnull().sum()
reviewId 0
userName 0
userImage 0
content 0
score 0
thumbsUpCount 0
reviewCreatedVersion 2162
at 0
replyContent 6677
repliedAt 6677
sortOrder 0
appId 0
dtype: int64
# # Let's have a look at the class balance.
# sns.countplot(df.score)
# # print(sns)
# plt.xlabel('review score')
# df.score
# ps =df.groupby('score')['score'].count()
# ps
# Function to convert score to sentiment
def to_sentiment(rating):
rating = int(rating)
# Convert to class
if rating <= 2:
return 0
elif rating == 3:
return 1
else:
return 2
# Apply to the dataset
df['sentiment'] = df.score.apply(to_sentiment)
# Plot the distribution
class_names = ['negative', 'neutral', 'positive']
print(df.sentiment)
# ax = sns.countplot(df.sentiment)
# plt.xlabel('review sentiment')
# ax.set_xticklabels(class_names)
0 0
1 0
2 0
3 0
4 0
..
12490 2
12491 2
12492 2
12493 2
12494 2
Name: sentiment, Length: 12495, dtype: int64
# Set the model name
MODEL_NAME = 'bert-base-cased'
# Build a BERT based tokenizer
tokenizer = BertTokenizer.from_pretrained(MODEL_NAME)
# Some of the common BERT tokens
print(tokenizer.sep_token, tokenizer.sep_token_id) # marker for ending of a sentence
print(tokenizer.cls_token, tokenizer.cls_token_id) # start of each sentence, so BERT knows we’re doing classification
print(tokenizer.pad_token, tokenizer.pad_token_id) # special token for padding
print(tokenizer.unk_token, tokenizer.unk_token_id) # tokens not found in training set
[SEP] 102
[CLS] 101
[PAD] 0
[UNK] 100
# Store length of each review
token_lens = []
# Iterate through the content slide
for txt in df.content:
tokens = tokenizer.encode(txt, max_length=512)
token_lens.append(len(tokens))
Truncation was not explicitly activated but `max_length` is provided a specific value, please use `truncation=True` to explicitly truncate examples to max length. Defaulting to 'longest_first' truncation strategy. If you encode pairs of sequences (GLUE-style) with the tokenizer you can select this strategy more precisely by providing a specific strategy to `truncation`.
# plot the distribution of review lengths
sns.distplot(token_lens)
plt.xlim([0, 256])
plt.xlabel('Token count')
Text(0.5, 0, 'Token count')
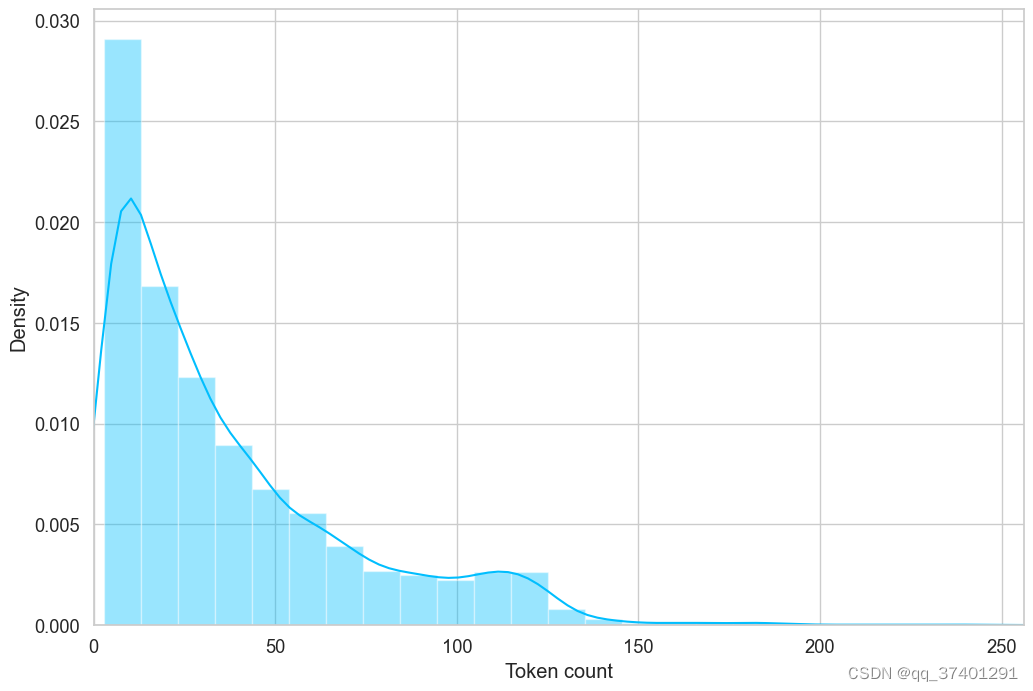
MAX_LEN = 160
class GPReviewDataset(Dataset):
# Constructor Function
def __init__(self, reviews, targets, tokenizer, max_len):
self.reviews = reviews
self.targets = targets
self.tokenizer = tokenizer
self.max_len = max_len
# Length magic method
def __len__(self):
return len(self.reviews)
# get item magic method
def __getitem__(self, item):
review = str(self.reviews[item])
target = self.targets[item]
# Encoded format to be returned
encoding = self.tokenizer.encode_plus(
review,
add_special_tokens=True,
max_length=self.max_len,
return_token_type_ids=False,
pad_to_max_length=True,
return_attention_mask=True,
return_tensors='pt',
)
return {
'review_text': review,
'input_ids': encoding['input_ids'].flatten(),
'attention_mask': encoding['attention_mask'].flatten(),
'targets': torch.tensor(target, dtype=torch.long)
}
df_train, df_test = train_test_split(df, test_size=0.2, random_state=42)
df_val, df_test = train_test_split(df_test, test_size=0.5, random_state=42)
print(df_train.shape, df_val.shape, df_test.shape)
(9996, 13) (1249, 13) (1250, 13)
def create_data_loader(df, tokenizer, max_len, batch_size):
ds = GPReviewDataset(
reviews=df.content.to_numpy(),
targets=df.sentiment.to_numpy(),
tokenizer=tokenizer,
max_len=max_len
)
return DataLoader(
ds,
batch_size=batch_size,
num_workers=0
)
# Create train, test and val data loaders
BATCH_SIZE = 32
train_data_loader = create_data_loader(df_train, tokenizer, MAX_LEN, BATCH_SIZE)
val_data_loader = create_data_loader(df_val, tokenizer, MAX_LEN, BATCH_SIZE)
test_data_loader = create_data_loader(df_test, tokenizer, MAX_LEN, BATCH_SIZE)
# Examples
data = next(iter(train_data_loader))
print(data.keys())
dict_keys(['review_text', 'input_ids', 'attention_mask', 'targets'])
print(data['input_ids'].shape)
print(data['attention_mask'].shape)
print(data['targets'].shape)
torch.Size([32, 160])
torch.Size([32, 160])
torch.Size([32])
# Load the basic BERT model
bert_model = BertModel.from_pretrained(MODEL_NAME)
Some weights of the model checkpoint at bert-base-cased were not used when initializing BertModel: ['cls.seq_relationship.bias', 'cls.predictions.decoder.weight', 'cls.predictions.transform.dense.weight', 'cls.predictions.bias', 'cls.seq_relationship.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.transform.LayerNorm.weight']
- This IS expected if you are initializing BertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
# Build the Sentiment Classifier class
class SentimentClassifier(nn.Module):
# Constructor class
def __init__(self, n_classes):
super(SentimentClassifier, self).__init__()
self.bert = BertModel.from_pretrained(MODEL_NAME)
self.drop = nn.Dropout(p=0.3)
self.out = nn.Linear(self.bert.config.hidden_size, n_classes)
# Forward propagaion class
def forward(self, input_ids, attention_mask):
_, pooled_output = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
return_dict=False
)
# Add a dropout layer
output = self.drop(pooled_output)
return self.out(output)
# Instantiate the model and move to classifier
model = SentimentClassifier(len(class_names))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
Some weights of the model checkpoint at bert-base-cased were not used when initializing BertModel: ['cls.seq_relationship.bias', 'cls.predictions.decoder.weight', 'cls.predictions.transform.dense.weight', 'cls.predictions.bias', 'cls.seq_relationship.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.transform.LayerNorm.weight']
- This IS expected if you are initializing BertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
# Number of hidden units
print(bert_model.config.hidden_size)
768
# Number of iterations
EPOCHS = 10
# Optimizer Adam
optimizer = AdamW(model.parameters(), lr=2e-5, correct_bias=False)
total_steps = len(train_data_loader) * EPOCHS
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=0,
num_training_steps=total_steps
)
# Set the loss function
loss_fn = nn.CrossEntropyLoss().to(device)
# # Function for a single training iteration FP32 loss function
# def train_epoch(model, data_loader, loss_fn, optimizer, device, scheduler, n_examples):
# model = model.train()
# losses = []
# correct_predictions = 0
#
# for d in data_loader:
# input_ids = d["input_ids"].to(device)
# attention_mask = d["attention_mask"].to(device)
# targets = d["targets"].to(device)
#
# outputs = model(
# input_ids=input_ids,
# attention_mask=attention_mask
# )
#
# _, preds = torch.max(outputs, dim=1)
# loss = loss_fn(outputs, targets)
# correct_predictions += torch.sum(preds == targets)
# losses.append(loss.item())
#
# # Backward prop
# loss.backward()
#
# # Gradient Descent
# nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
# optimizer.step()
# scheduler.step()
# optimizer.zero_grad()
#
# return correct_predictions.double() / n_examples, np.mean(losses)
使用混合精度训练 pytorch1.6以上才能支持使用fp16显卡 Tensorcore核心
from torch.cuda.amp import GradScaler, autocast
scaler = GradScaler()
def train_epoch(model, data_loader, loss_fn, optimizer, device, scheduler, n_examples):
model = model.train()
losses = []
correct_predictions = 0
for d in data_loader:
input_ids = d["input_ids"].to(device)
attention_mask = d["attention_mask"].to(device)
targets = d["targets"].to(device)
# Gradient Descent
nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.zero_grad()
with autocast():
#一定要把模型设置在fp16模型中输出
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask)
_, preds = torch.max(outputs, dim=1)
loss = loss_fn(outputs, targets)
correct_predictions += torch.sum(preds == targets)
losses.append(loss.item())
# Scales loss. Calls backward() on scaled loss to create scaled gradients.
# Backward passes under autocast are not recommended.
# Backward ops run in the same dtype autocast chose for corresponding forward ops.
scaler.scale(loss).backward()
# scaler.step() first unscales the gradients of the optimizer's assigned params.
# If these gradients do not contain infs or NaNs, optimizer.step() is then called,
# otherwise, optimizer.step() is skipped.
scaler.step(optimizer)
# Updates the scale for next iteration.
scaler.update()
return correct_predictions.double() / n_examples, np.mean(losses)
def eval_model(model, data_loader, loss_fn, device, n_examples):
model = model.eval()
losses = []
correct_predictions = 0
with torch.no_grad():
for d in data_loader:
input_ids = d["input_ids"].to(device)
attention_mask = d["attention_mask"].to(device)
targets = d["targets"].to(device)
# Get model ouptuts
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask
)
_, preds = torch.max(outputs, dim=1)
loss = loss_fn(outputs, targets)
correct_predictions += torch.sum(preds == targets)
losses.append(loss.item())
return correct_predictions.double() / n_examples, np.mean(losses)
history = defaultdict(list)
best_accuracy = 0
for epoch in range(EPOCHS):
# Show details
print(f"Epoch {epoch + 1}/{EPOCHS}")
print("-" * 10)
train_acc, train_loss = train_epoch(
model,
train_data_loader,
loss_fn,
optimizer,
device,
scheduler,
len(df_train)
)
print(f"Train loss {train_loss} accuracy {train_acc}")
# Get model performance (accuracy and loss)
val_acc, val_loss = eval_model(
model,
val_data_loader,
loss_fn,
device,
len(df_val)
)
print(f"Val loss {val_loss} accuracy {val_acc}")
print()
history['train_acc'].append(train_acc)
history['train_loss'].append(train_loss)
history['val_acc'].append(val_acc)
history['val_loss'].append(val_loss)
# If we beat prev performance
if val_acc > best_accuracy:
torch.save(model.state_dict(), 'best_model_state.bin')
best_accuracy = val_acc
# 获取过段时间后的时间
endtime = datetime.datetime.now()
print((endtime - starttime).seconds)
Epoch 1/10
----------
Train loss 0.6848097632106501 accuracy 0.7208883553421369
Val loss 0.5925843127071857 accuracy 0.7574059247397917
Epoch 2/10
----------
Train loss 0.48870645539638713 accuracy 0.8079231692677071
Val loss 0.6062256038188935 accuracy 0.7493995196156925
Epoch 3/10
----------
Train loss 0.34348880144925165 accuracy 0.8686474589835935
Val loss 0.6998532168567181 accuracy 0.743795036028823
Epoch 4/10
----------
Train loss 0.2768642743127034 accuracy 0.8961584633853542
Val loss 0.7555158618837595 accuracy 0.7445956765412329
Epoch 5/10
----------
Train loss 0.19659621281602893 accuracy 0.9308723489395759
Val loss 0.8499629437923432 accuracy 0.7141713370696556
Epoch 6/10
----------
Train loss 0.13516816481674154 accuracy 0.9560824329731893
Val loss 1.0227949187159537 accuracy 0.7101681345076061
Epoch 7/10
----------
Train loss 0.10121473114336499 accuracy 0.9680872348939576
Val loss 1.142523455619812 accuracy 0.7341873498799039
Epoch 8/10
----------
Train loss 0.08803147610244207 accuracy 0.9714885954381753
Val loss 1.170446154475212 accuracy 0.7421937550040032
Epoch 9/10
----------
Train loss 0.07703767744705271 accuracy 0.9755902360944378
Val loss 1.1894072636961937 accuracy 0.7389911929543634
Epoch 10/10
----------
Train loss 0.0677171527135064 accuracy 0.9771908763505402
Val loss 1.3171145111322402 accuracy 0.7453963170536428
716
# 读取训练好的模型
model.load_state_dict(torch.load('best_model_state.bin'))
test_acc, _ = eval_model(
model,
test_data_loader,
loss_fn,
device,
len(df_test)
)
test_acc.item()
def get_predictions(model, data_loader):
model = model.eval()
review_texts = []
predictions = []
prediction_probs = []
real_values = []
with torch.no_grad():
for d in data_loader:
texts = d["review_text"]
input_ids = d["input_ids"].to(device)
attention_mask = d["attention_mask"].to(device)
targets = d["targets"].to(device)
# Get outouts
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask
)
_, preds = torch.max(outputs, dim=1)
review_texts.extend(texts)
predictions.extend(preds)
prediction_probs.extend(outputs)
real_values.extend(targets)
predictions = torch.stack(predictions).cpu()
prediction_probs = torch.stack(prediction_probs).cpu()
real_values = torch.stack(real_values).cpu()
return review_texts, predictions, prediction_probs, real_values
y_review_texts, y_pred, y_pred_probs, y_test = get_predictions(
model,
test_data_loader
)
print(classification_report(y_test, y_pred, target_names=class_names))
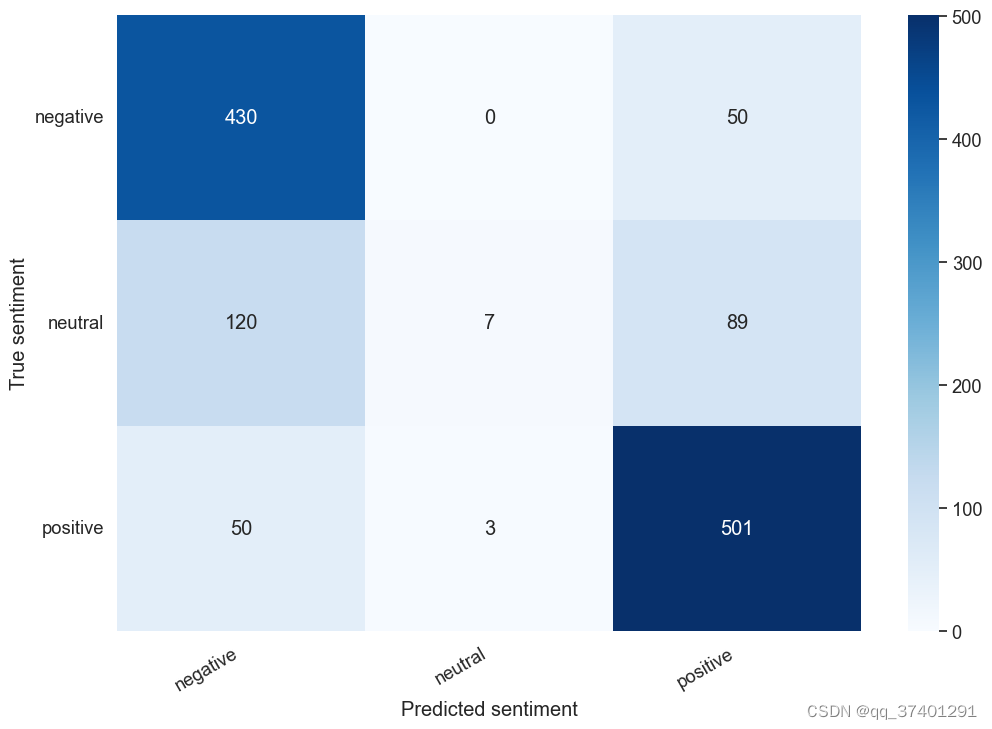
def show_confusion_matrix(confusion_matrix):
hmap = sns.heatmap(confusion_matrix, annot=True, fmt="d", cmap="Blues")
hmap.yaxis.set_ticklabels(hmap.yaxis.get_ticklabels(), rotation=0, ha='right')
hmap.xaxis.set_ticklabels(hmap.xaxis.get_ticklabels(), rotation=30, ha='right')
plt.ylabel('True sentiment')
plt.xlabel('Predicted sentiment');
cm = confusion_matrix(y_test, y_pred)
df_cm = pd.DataFrame(cm, index=class_names, columns=class_names)
show_confusion_matrix(df_cm)
review_text = "I love completing my todos! Best app ever!!!"
encoded_review = tokenizer.encode_plus(
review_text,
max_length=MAX_LEN,
add_special_tokens=True,
return_token_type_ids=False,
pad_to_max_length=True,
return_attention_mask=True,
return_tensors='pt',
)
input_ids = encoded_review['input_ids'].to(device)
attention_mask = encoded_review['attention_mask'].to(device)
output = model(input_ids, attention_mask)
_, prediction = torch.max(output, dim=1)
print(f'Review text: {review_text}')
print(f'Sentiment : {class_names[prediction]}')
precision recall f1-score support
negative 0.72 0.90 0.80 480
neutral 0.70 0.03 0.06 216
positive 0.78 0.90 0.84 554
accuracy 0.75 1250
macro avg 0.73 0.61 0.57 1250
weighted avg 0.74 0.75 0.69 1250
Review text: I love completing my todos! Best app ever!!!
Sentiment : positive















 1633
1633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









