







比赛链接:https://www.kaggle.com/competitions/feedback-prize-effectiveness/overview
公开代码:https://www.kaggle.com/code/mustafakeser4/feedback-eda/notebook
导包加载数据
import numpy as np
import pandas as pd
import os
import seaborn as sns
import matplotlib.pyplot as plt
from tqdm.notebook import tqdm
from wordcloud import WordCloud,ImageColorGenerator
from PIL import Image
pd.options.display.width = 180
pd.options.display.max_colwidth = 120
train = pd.read_csv("../input/feedback-prize-effectiveness/train.csv")
test = pd.read_csv("../input/feedback-prize-effectiveness/test.csv")
sample_sub = pd.read_csv("../input/feedback-prize-effectiveness/sample_submission.csv")
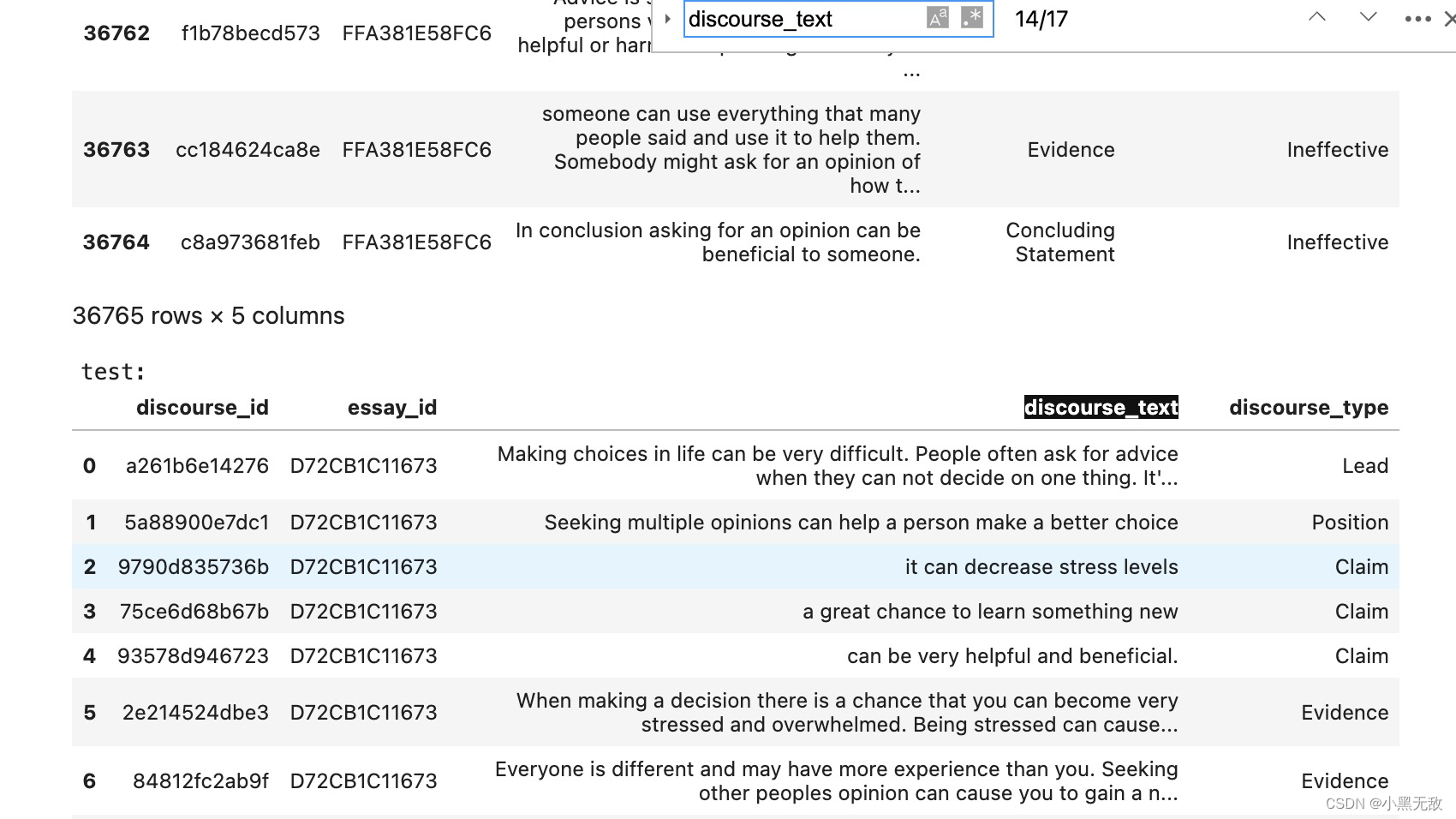
print('train:')
display(train)
print('test:')
display(test)
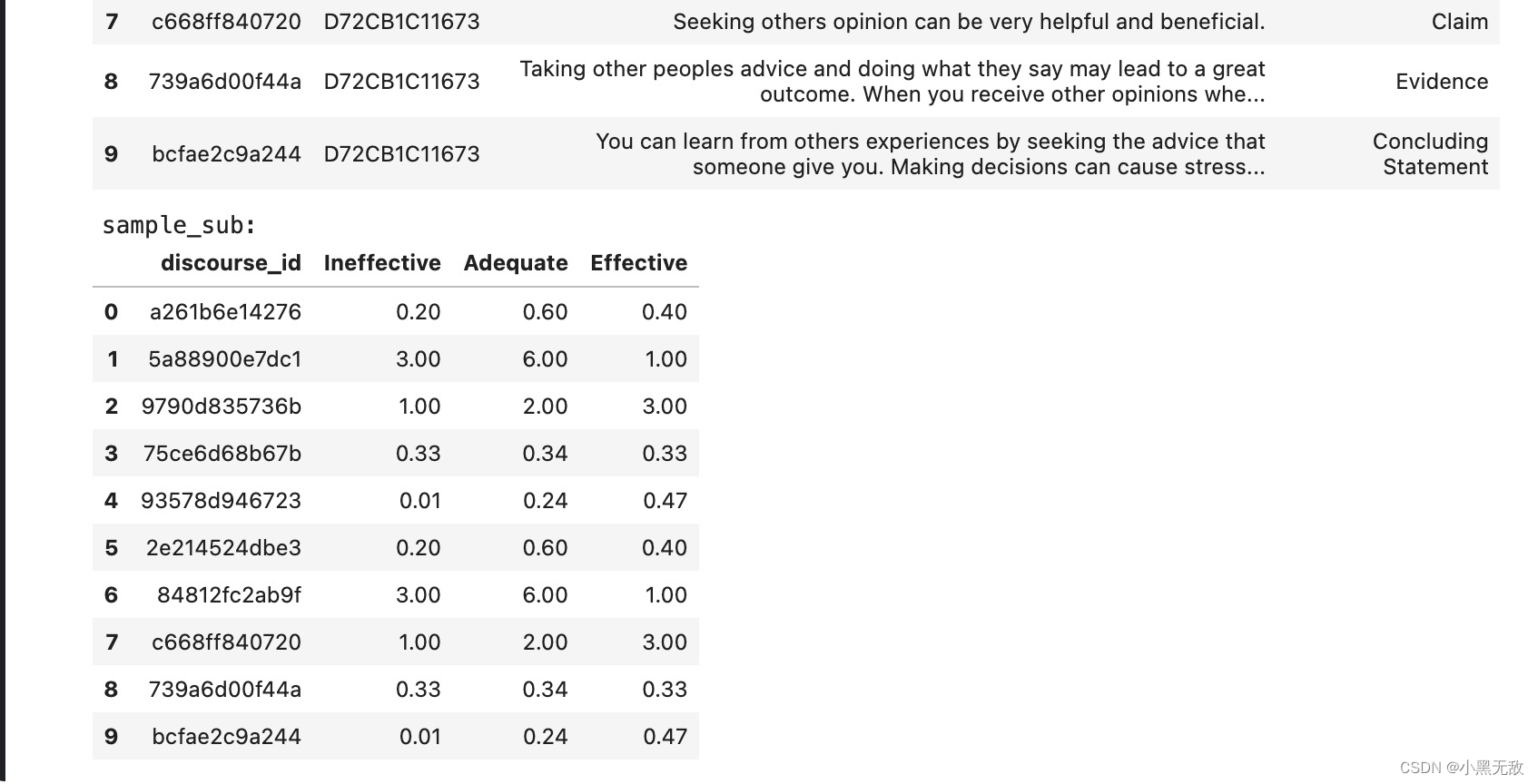
print('sample_sub:')
display(sample_sub)

train.describe()

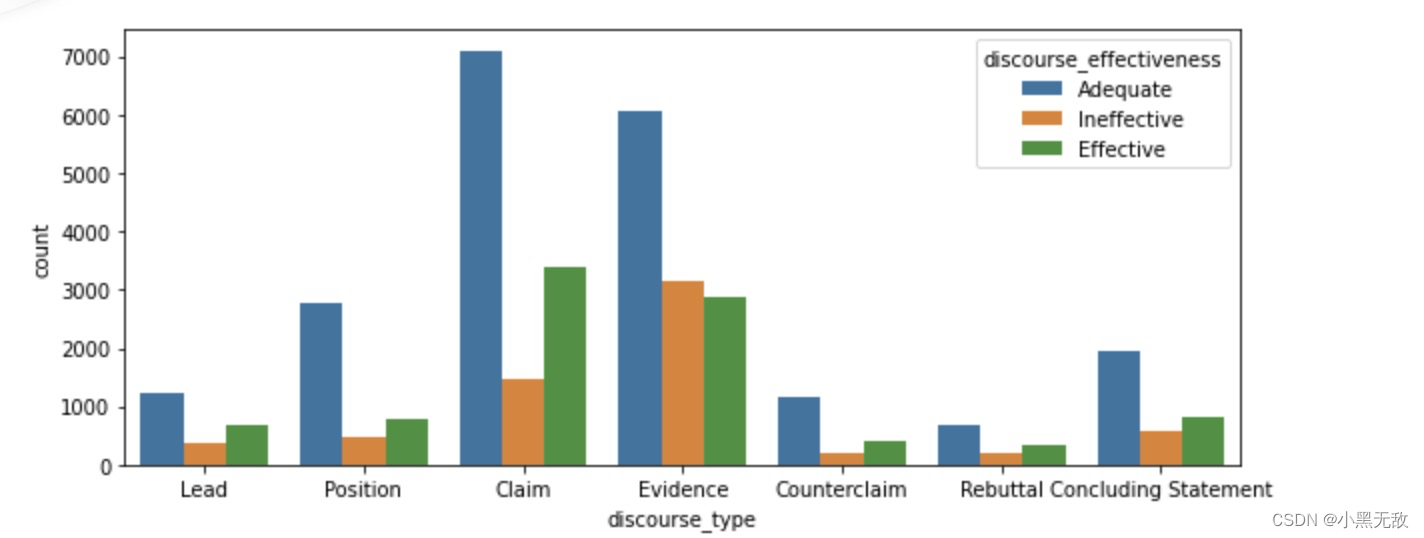
统计每类问题下,学生们的答题评分分布
def count_string(x):
return len(x.split())
train['word_count'] = train.discourse_text.apply(count_string)
test['word_count'] = test.discourse_text.apply(count_string)
import seaborn as sns
plt.figure(figsize = (10,4))
sns.countplot(data = train,x = 'discourse_type',hue = 'discourse_effectiveness')
def pieplot(df,col ,title,explodeplace=0):
"""
df: DataFrame
col: column
title: title for plot
explodeplace: segment|slice location for exploding
"""
labels = df[col].value_counts().index
sizes = df[col].value_counts()
# 初始化偏移程度
# https://vimsky.com/examples/usage/matplotlib-axes-axes-pie-in-python.html
explode = np.zeros(len(sizes))
explode[explodeplace]=0.1
fig1, ax1 = plt.subplots()
ax1.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%',
shadow=True, startangle=90)
ax1.axis('equal')
ax1.set_title(title)
plt.show()
print(df[col].value_counts())
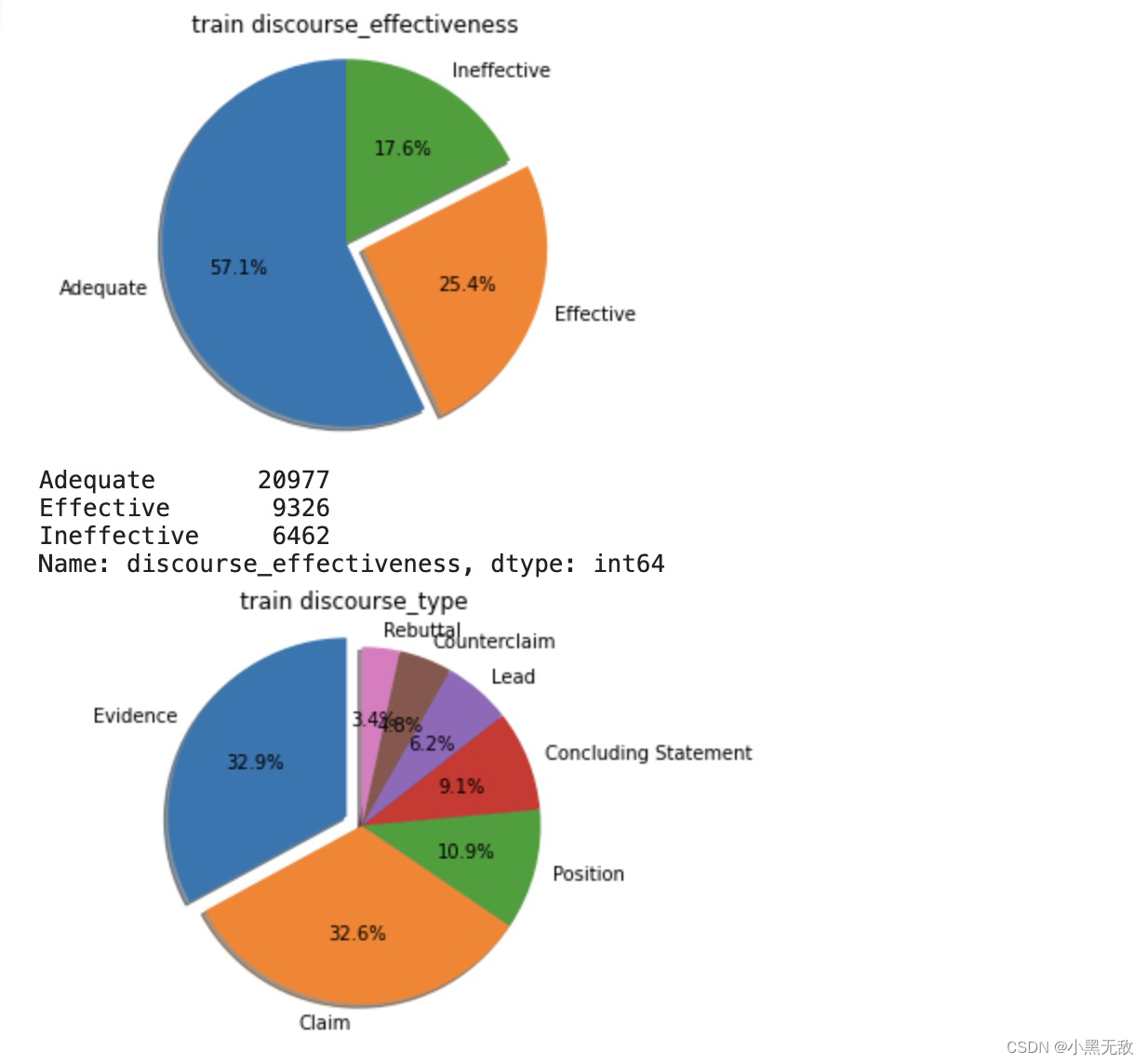
分别考察:训练集整体评分分布、训练集整体问题类型分布、测试集整体评分分布
pieplot(train,"discourse_effectiveness","train discourse_effectiveness",explodeplace=1)
pieplot(train,"discourse_type","train discourse_type",explodeplace=0)
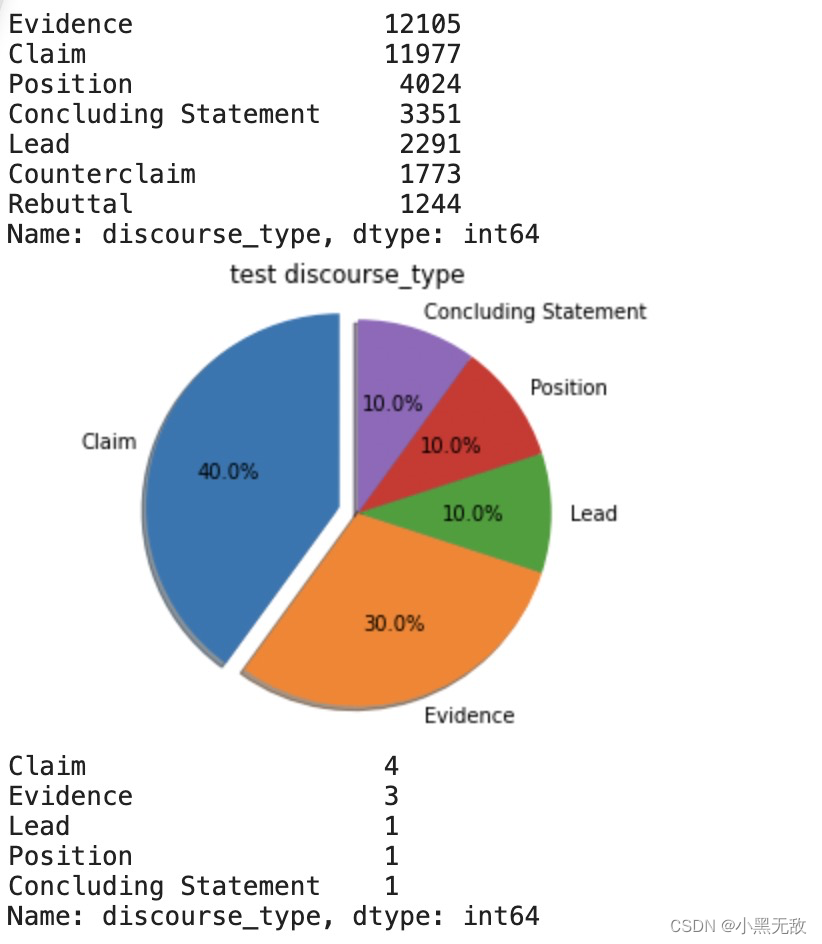
pieplot(test,"discourse_type","test discourse_type",explodeplace=0)
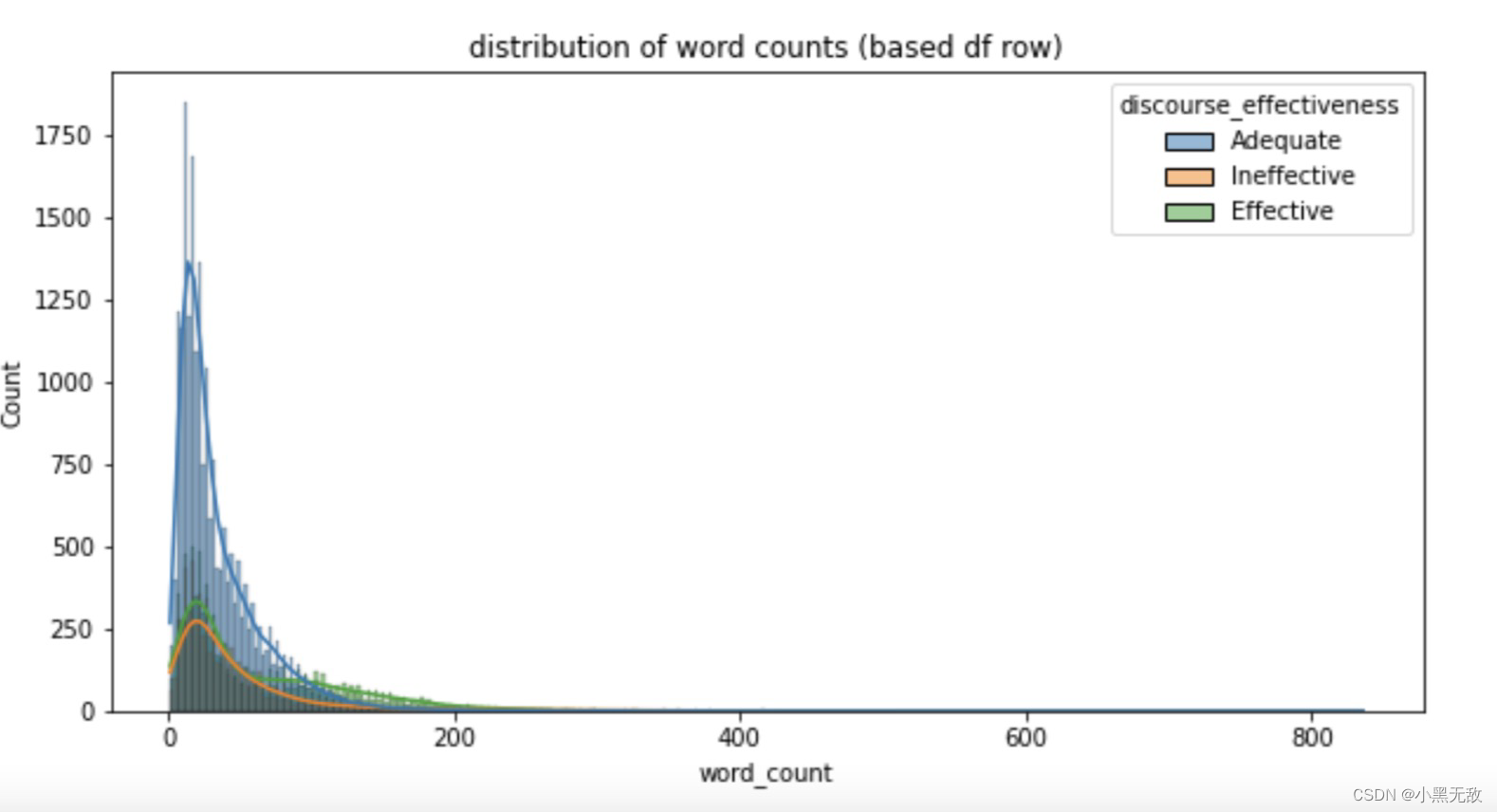
统计每个评分下,“问题”的长度分布
plt.figure(figsize = (10,5))
sns.histplot(data = train,x = 'word_count',hue = 'discourse_effectiveness',kde = True)
plt.title('distribution of word counts (based df row)')
train_txt_list = os.listdir("../input/feedback-prize-effectiveness/train")
test_txt_list = os.listdir("../input/feedback-prize-effectiveness/test")
train_word_count = []
for txt in tqdm(train_txt_list):
with open("../input/feedback-prize-effectiveness/train/"+txt,'r') as f:
data = f.read().replace('\n','')
train_word_count.append(len(data.split()))
test_word_count = []
for txt in tqdm(test_txt_list):
with open("../input/feedback-prize-effectiveness/test/"+txt, "r") as f:
data = f.read().replace('\n','')
test_word_count.append(len(data.split()))
train_count_dict = dict(zip([f[:-4] for f in train_txt_list],train_word_count))
test_count_dict = dict(zip([f[:-4] for f in test_txt_list],test_word_count))
每篇文章的字数统计
essay_count_df = pd.DataFrame(data = train_count_dict.values(),index = train_count_dict.keys(),columns = ['word_count'])
essay_count_df
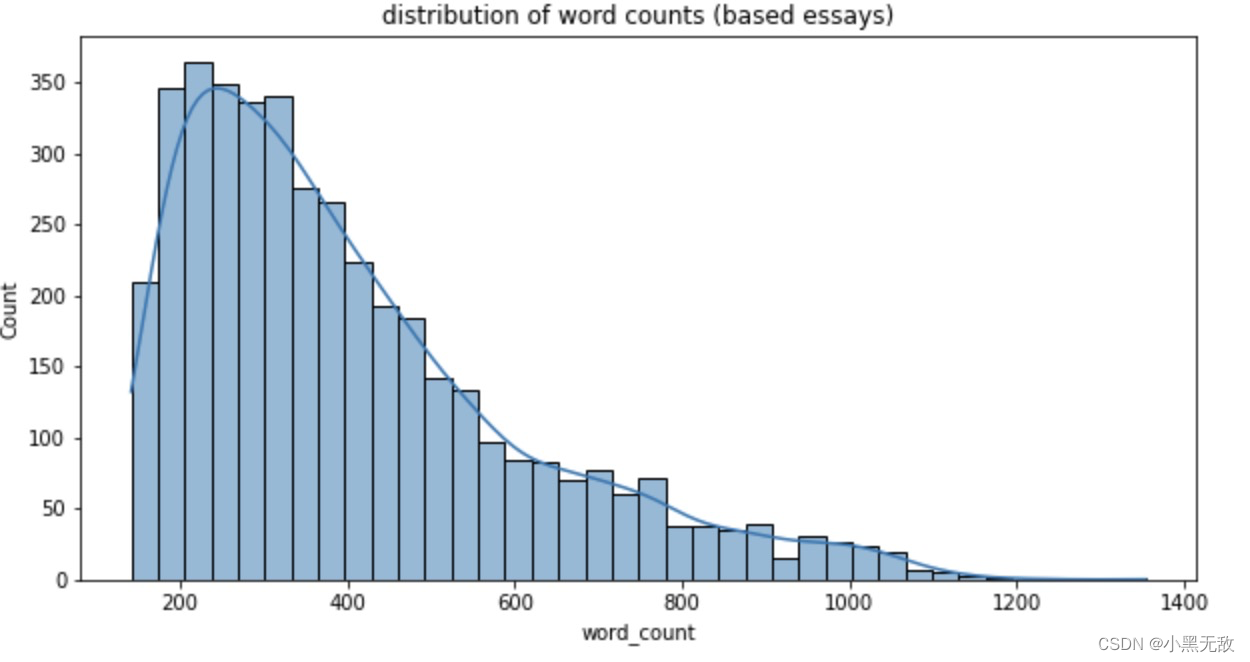
文章的长度分布
plt.figure(figsize = (10,5))
sns.histplot(data = essay_count_df,x = 'word_count',kde = True)
plt.title("distribution of word counts (based essays)");
essay_ids = train.essay_id.unique().tolist()
first_sentence_word_count = []
first_sentence_effectiveness = []
for ids in tqdm(essay_ids):
A = train[train.essay_id == ids]
first_sentence_word_count.append(A.iloc[0]['word_count'])
first_sentence_effectiveness.append(A.iloc[0]["discourse_effectiveness"])
essay_count_df['first_discourse'] = first_sentence_word_count
essay_count_df["first_sentence_effectiveness"] = first_sentence_effectiveness
essay_count_df.head()
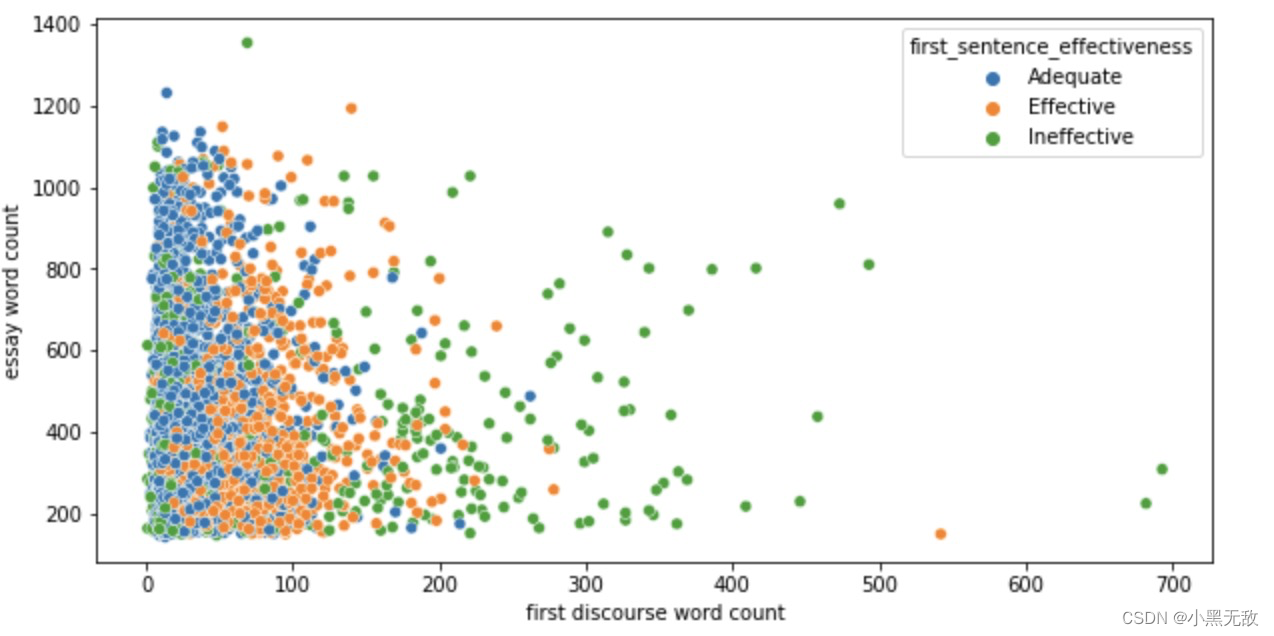
每个评分的“问题”长度分析:评分低的“问题”偏长
plt.figure(figsize = (10,5))
sns.scatterplot(data = essay_count_df,y = 'word_count',x="first_discourse",hue="first_sentence_effectiveness")
plt.xlabel("first discourse word count")
plt.ylabel("essay word count");
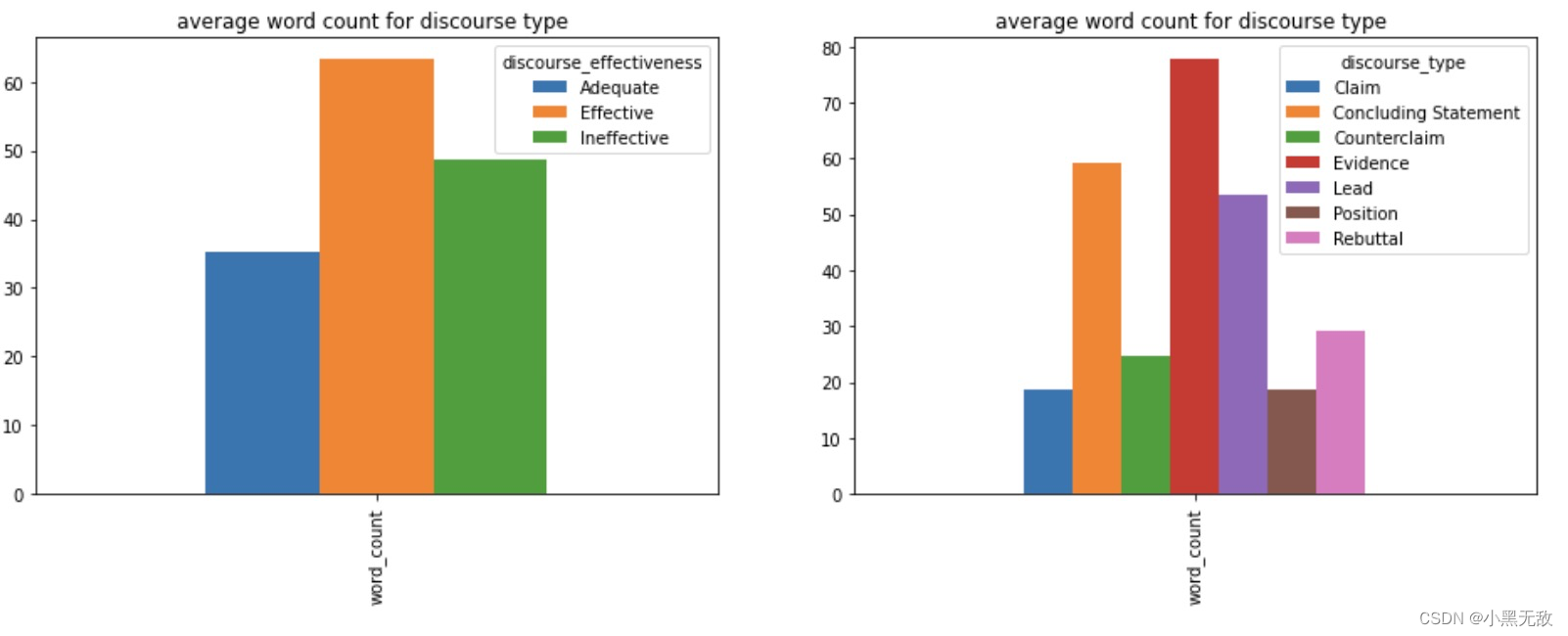
_,ax = plt.subplots(ncols = 2,nrows = 1,figsize = (16,5))
train.groupby("discourse_effectiveness").mean().T.plot(kind = 'bar',ax = ax[0])
ax[0].set_title("average word count for discourse type ");
train.groupby('discourse_type').mean().T.plot(kind="bar",ax=ax[1])
ax[1].set_title("average word count for discourse type ");
停用词
import nltk
from nltk.corpus import stopwords
print(stopwords.words('english'))

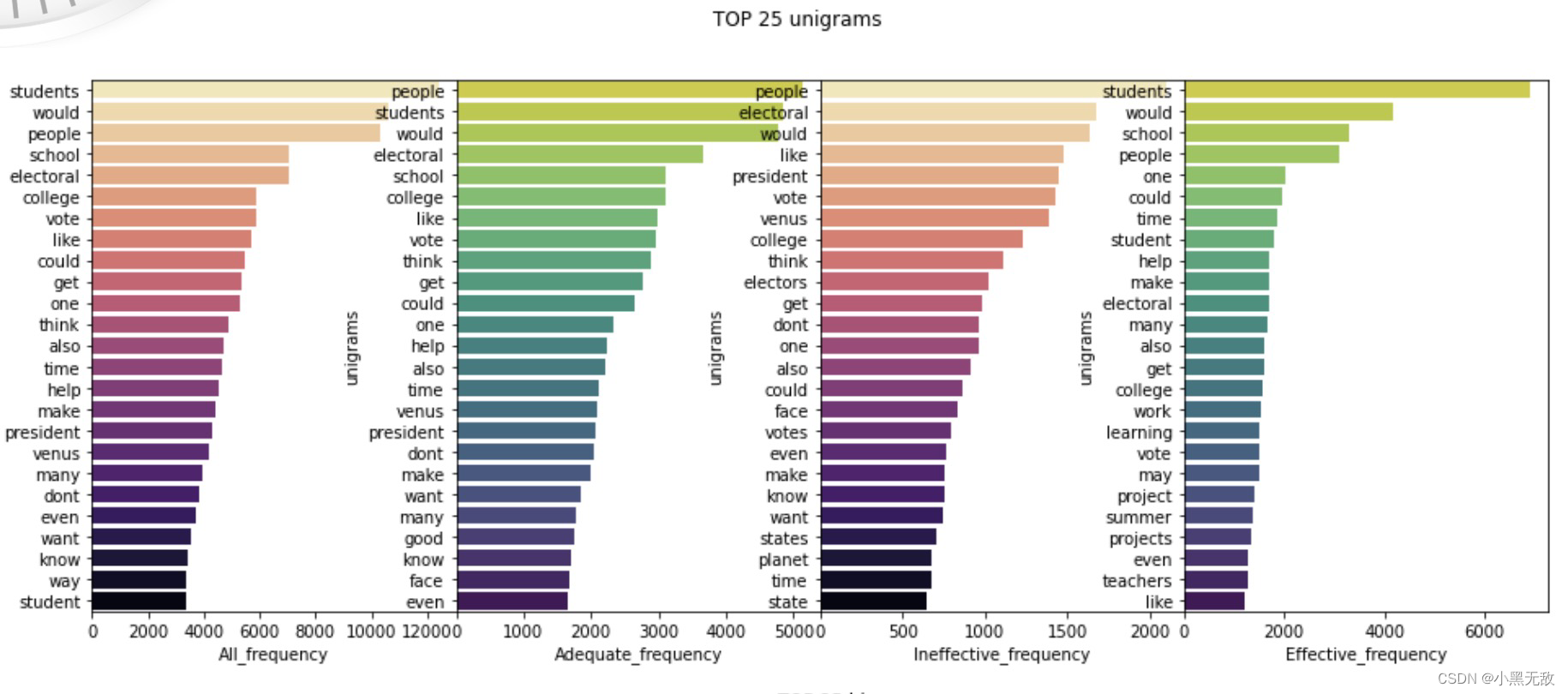
统计每个评分下的“问题”的高频gram
def generate_ngrams(text,stop_words,n_gram = 1):
token = [token for token in text.lower().split(' ') if token != '' if token not in stop_words]
ngrams = zip(*[token[i:] for i in range(n_gram)])
return [' '.join(ngram) for ngram in ngrams]
#generate_ngrams('I love you for ever.',['a'],2)
grams = ["unigrams","bigrams","trigrams"]
type_effectiveness = ['All','Adequate', 'Ineffective', 'Effective']
stop_words = stopwords.words('english')
import warnings
warnings.filterwarnings('ignore')
for name in type_effectiveness:
for i,ngram in enumerate(grams):
if name == 'All':
locals()[name] = train.discourse_text
else:
locals()[name] = train[train.discourse_effectiveness == name].discourse_text
locals()[name]["mytext_new"] = locals()[name].str.lower().str.replace('[^\w\s]','')
locals()[name+'_'+ngram] = pd.Series(generate_ngrams(' '.join(locals()[name].mytext_new.to_list()),stop_words, n_gram=i+1)).value_counts()
name = 'unigrams'
top = 25
for ngram in grams:
if ngram != 'trigrams':
sl = 0
a = 0
else:
sl = 1
a = 2.5
fig,axs = plt.subplots(ncols = 4,nrows = 1,figsize=(16,int(top/4)),sharey = False)
plt.subplots_adjust(hspace = 0.5,wspace = 1*a)
sns.barplot(y=locals()[f"All_{ngram}"].index[sl:top],x = locals()[f"All_{ngram}"].values[sl:top],palette = 'magma_r',ax = axs[0])
axs[0].set_xlabel('All_frequency')
axs[0].set_ylabel(ngram)
sns.barplot(y=locals()[f"Adequate_{ngram}"].index[sl:top], x = locals()[f"Adequate_{ngram}"].values[sl:top],palette='viridis_r',ax=axs[1])
axs[1].set_xlabel("Adequate_frequency")
axs[1].set_ylabel(ngram)
sns.barplot(y=locals()[f"Ineffective_{ngram}"].index[sl:top], x = locals()[f"Ineffective_{ngram}"].values[sl:top],palette='magma_r',ax=axs[2])
axs[2].set_xlabel("Ineffective_frequency")
axs[2].set_ylabel(ngram)
sns.barplot(y=locals()[f"Effective_{ngram}"].index[sl:top], x = locals()[f"Effective_{ngram}"].values[sl:top],palette='viridis_r',ax=axs[3])
axs[3].set_xlabel("Effective_frequency")
axs[3].set_ylabel(ngram)
fig.suptitle(f"TOP {top} {ngram}")
plt.show()
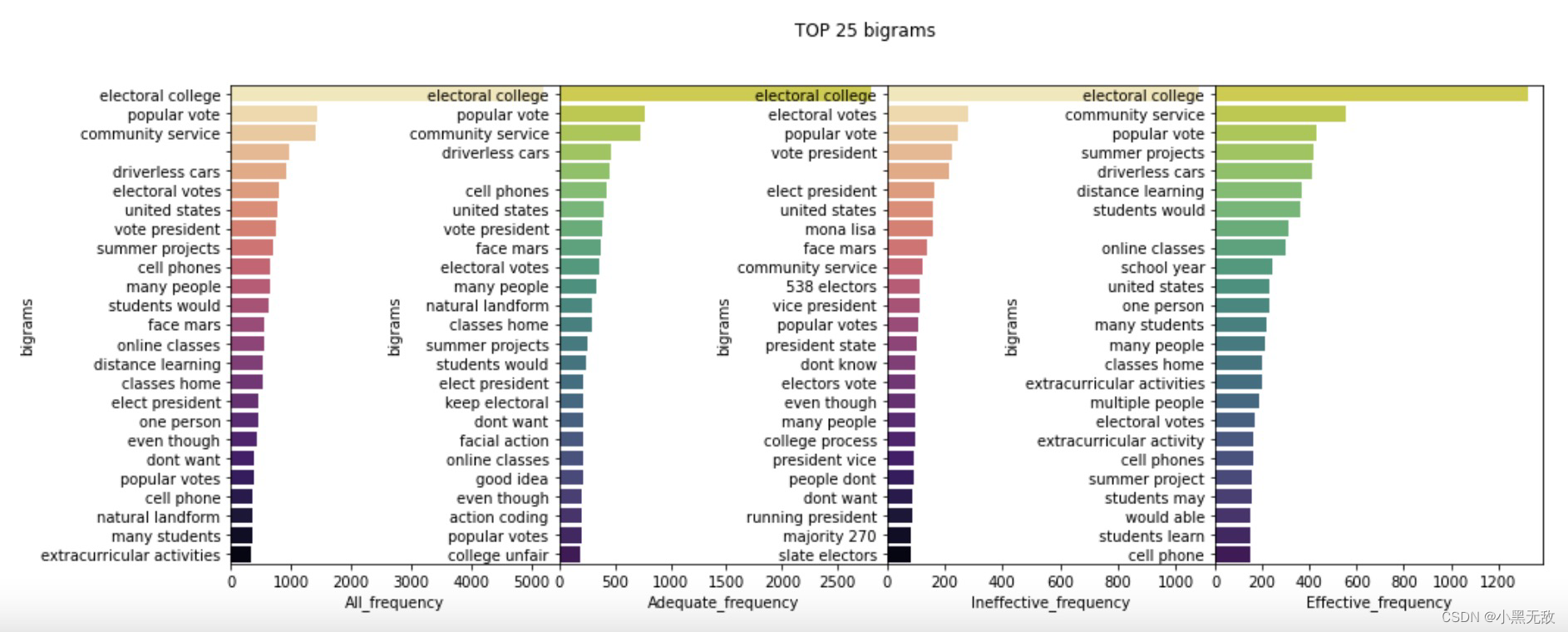
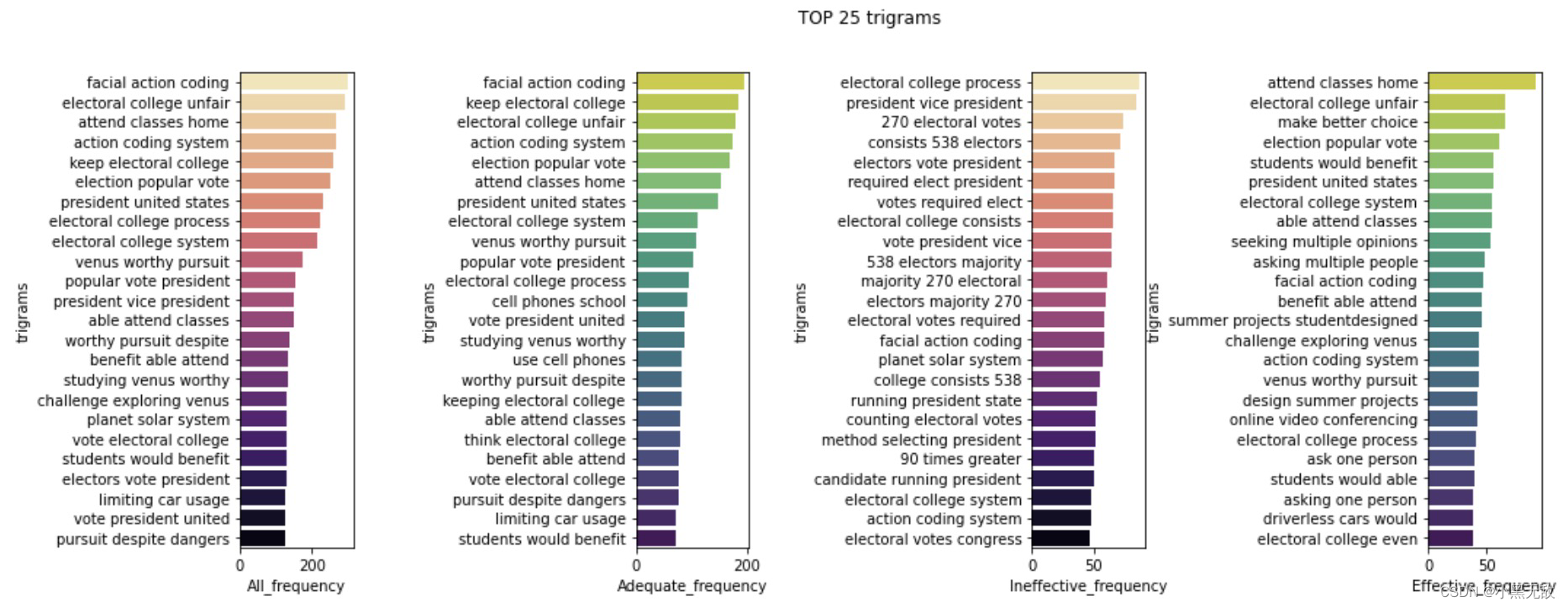
词云图
def word_cloud(is_df = False,df = None,title_plot_df = ' ',is_essay = True,essay_id = '007ACE74B050',discourse_id = '0013cc385424'):
"""
is df: True if text from df. True cancels essay id and discource id options
df: text column in df
is_assey: True: whole essay text word cloud | False: discourse text word cloud
"""
path = "../input/feedback-prize-effectiveness/train/"
if is_df:
data = ' '.join(df.to_list())
else:
if is_essay:
with open(path+essay_id+'.txt','r') as f:
data = f.read().replace('\n','')
else:
data = train[train['discourse_id'] == discourse_id]['discourse_text'][0]
#print(data)
wordcloud = WordCloud(relative_scaling=0.1,colormap="cividis",prefer_horizontal=0.5,background_color="white",mode= "RGB").generate(data)
plt.figure(figsize = (12,8),dpi=90)
plt.imshow(wordcloud, interpolation="antialiased",aspect=0.5)
plt.axis('off')
plt.margins(x=0, y=0)
if is_df:
plt.title(f" {title_plot_df} ")
else:
if is_essay:
plt.title(f"essay id: {essay_id} word cloud")
else:
plt.title(f"discourse_id: {discourse_id} word cloud")
plt.show()
word_cloud(is_df=True, df=train[train.discourse_effectiveness=='Adequate'].discourse_text,
title_plot_df="Adequate word cloud"
,is_essay=True,essay_id="007ACE74B050"
,discourse_id="0013cc385424")

word_cloud(is_df=True, df=train[train.discourse_effectiveness=='Ineffective'].discourse_text,
title_plot_df="Ineffective word cloud"
,is_essay=True,essay_id="007ACE74B050"
,discourse_id="0013cc385424")

word_cloud(is_df=True, df=train[train.discourse_effectiveness== 'Effective'].discourse_text,
title_plot_df="Effective word cloud"
,is_essay=True,essay_id="007ACE74B050"
,discourse_id="0013cc385424")

word_cloud(is_essay=True,essay_id="007ACE74B050",discourse_id="0013cc385424")

word_cloud(is_essay=False,essay_id="007ACE74B050",discourse_id="0013cc385424")

训练
分别用每个评分的“问题”作为词向量训练
import tensorflow_hub as hub
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import log_loss,accuracy_score,classification_report,confusion_matrix
from sklearn.preprocessing import OneHotEncoder,LabelEncoder
vec = TfidfVectorizer(ngram_range=(1,2),stop_words=stop_words)
vec.fit(train.discourse_text.to_list()+test.discourse_text.to_list())
le = LabelEncoder()
preds = []
models = {}
vectorizers = {}
for name in ['All','Adequate', 'Effective', 'Ineffective']:
vec = TfidfVectorizer(ngram_range=(1,2),stop_words=stop_words)
X = train.discourse_text.to_list()
y = le.fit_transform(train.discourse_effectiveness.astype(str))
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.1,random_state=0)
if name=='All':
vec=TfidfVectorizer(ngram_range=(1,2),stop_words=stop_words)
vec.fit(train.discourse_text.to_list())
else:
vec = TfidfVectorizer(ngram_range=(1,2),stop_words=stop_words)
vec.fit(train.discourse_text[train.discourse_effectiveness==name].to_list())
X_train = vec.transform(X_train)
X_test = vec.transform(X_test)
testvec = vec.transform(test.discourse_text.to_list())
lgsc = LogisticRegression(max_iter=600,penalty='l2',C=1.015)
lgsc.fit(X_train,y_train)
pred=lgsc.predict_proba(X_test)
print(f"\n{name} logloss train: {log_loss(y_train,lgsc.predict_proba(X_train))}, logloss val: {log_loss(y_test,pred)}")
predtest = lgsc.predict_proba(testvec)
preds.append(predtest)
models[name] = lgsc
vectorizers[name] = vec
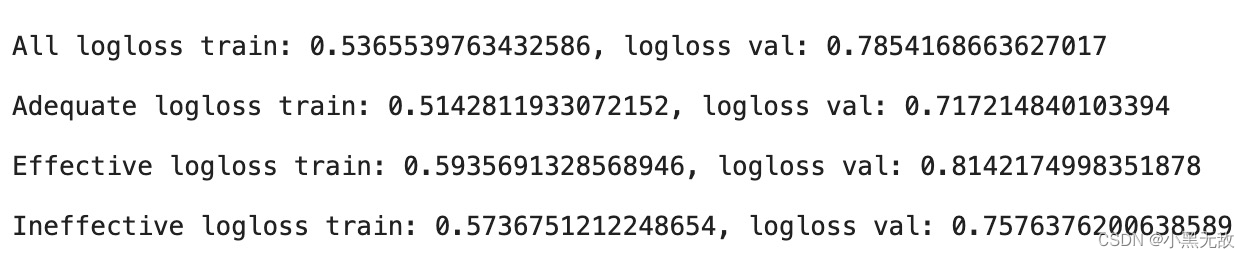
print(classification_report(y_train,np.argmax(lgsc.predict_proba(X_train),axis=1)))
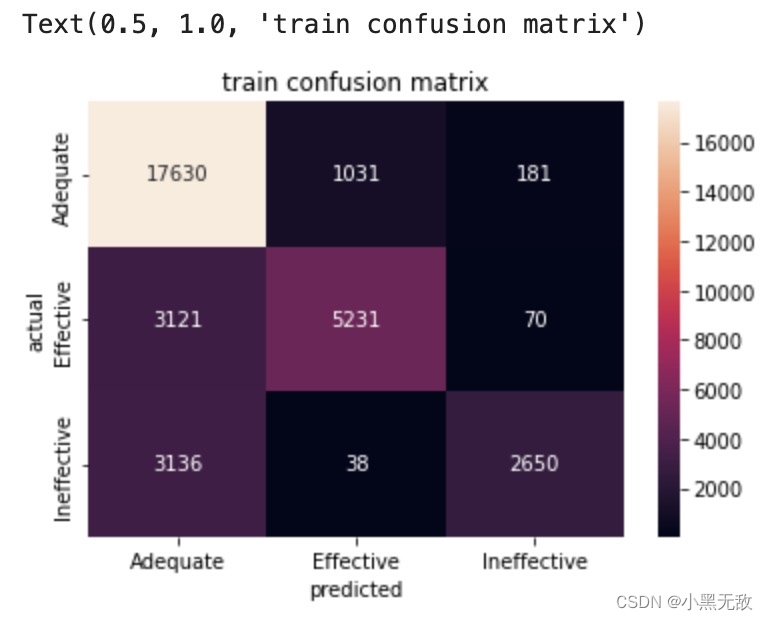
sns.heatmap(confusion_matrix(y_train,np.argmax(lgsc.predict_proba(X_train),axis=1)),annot=True,fmt='.0f',xticklabels=le.classes_,yticklabels=le.classes_)
plt.xlabel("predicted")
plt.ylabel("actual")
plt.title('train confusion matrix')
提交
predtest = np.mean(preds,axis=0)
sample_sub.iloc[:,1:]=predtest
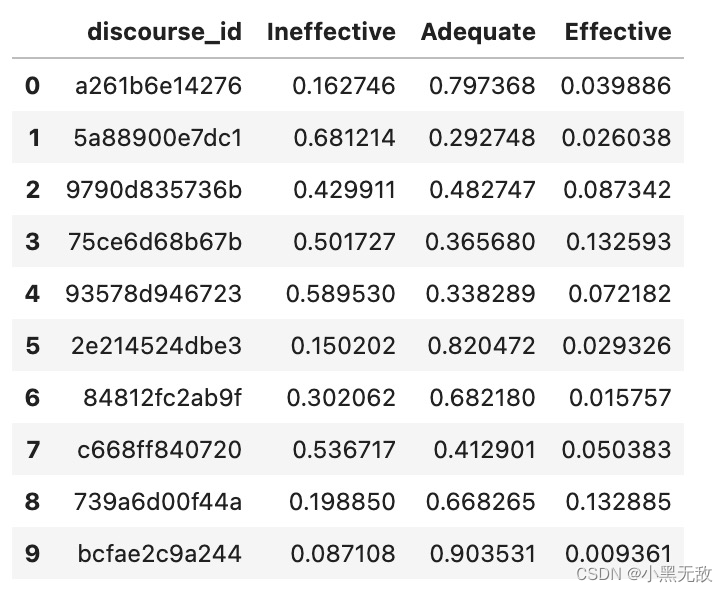
sample_sub.to_csv("submission.csv",index=False)
sample_sub















 1167
1167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









