







本文主要给大家介绍使用MindStudio进行StarNet_MobileNetV3模型英文图像文字识别开发过程,主要内容包括MindStudio安装、MindStudio工程创建、模型介绍与获取、模型转换、模型推理5个部分。
一、MindStudio安装
1.1 MindStudio介绍
MindStudio是一套基于华为昇腾AI处理器开发的AI全栈开发平台,包括基于芯片的算子开发、以及自定义算子开发,同时还包括网络层的网络移植、优化和分析,另外在业务引擎层提供了一套可视化的AI引擎拖拽式编程服务,极大的降低了AI引擎的开发门槛。MindStudio功能框架如图1所示。
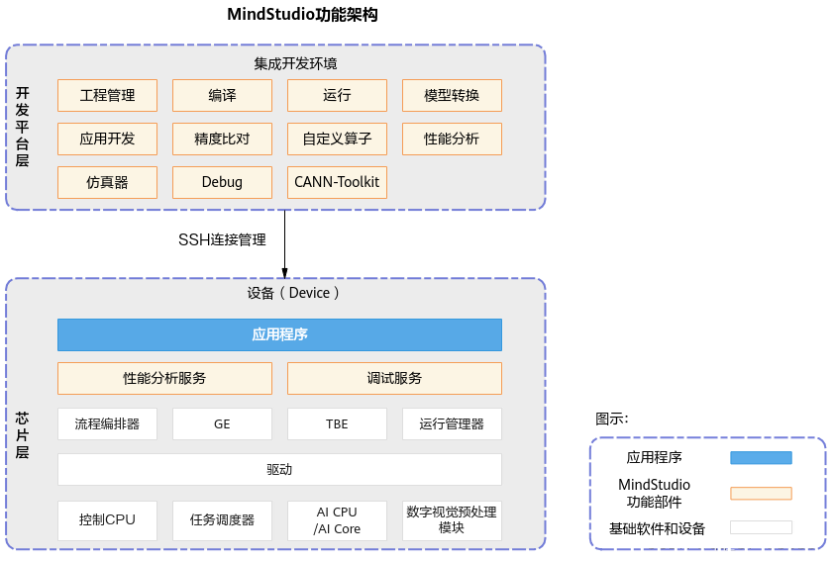
图1
1.2 MindStudio安装
MindStudio的安装包可以通过官方网站获取,链接如下,本文使用的版本为5.0.RC3。
https://www.hiascend.com/zh/software/mindstudio
MindStudio的安装过程可以参考安装指南,链接如下:
https://www.hiascend.com/document/detail/zh/mindstudio/50RC3/instg/instg_000002.html
二、MindStudio工程创建
1.1 主界面功能介绍
首次启动MindStudio会提示是否导入配置,如图2所示,可以选择不导入配置,点击OK进入MindStudio主界面。

图2
MindStudio欢迎界面比较简洁,相关功能如下:
a.工程管理功能,如图3所示,包括新建工程,打开、导入工程。
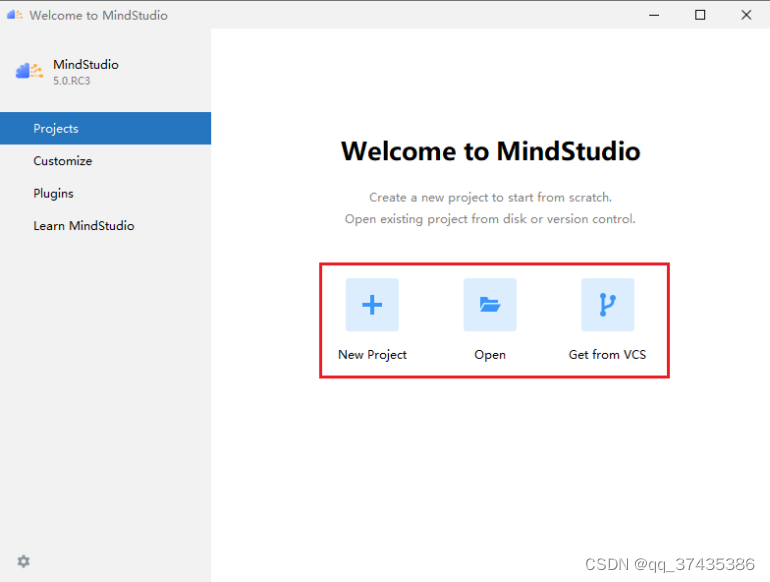
图3
b.用户设置功能,可以设置主题、字体等,如图4所示,将界面颜色设置为IntelliJ Light。

图4
c.插件管理功能,如图5所示,可以安装、卸载一些常用的插件。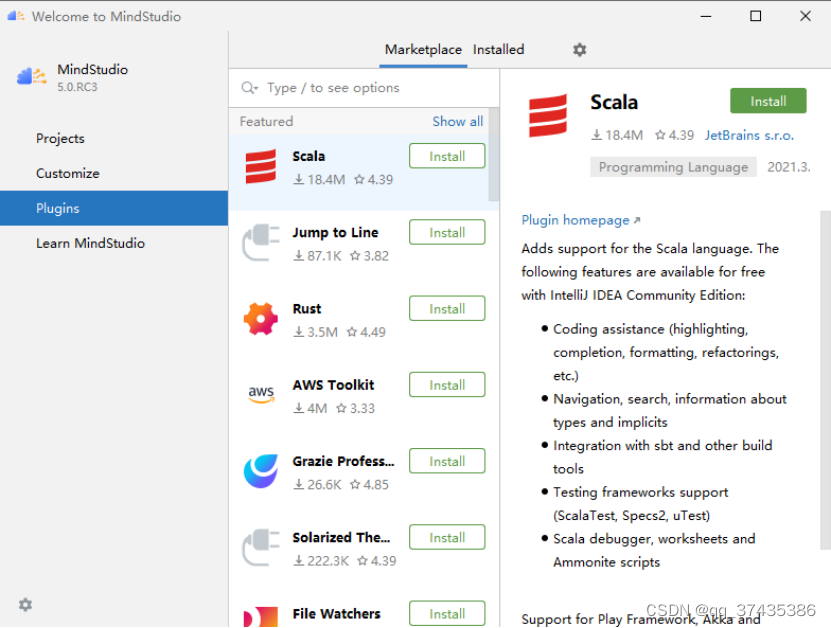
图5
d.学习功能,如图6所示,可以进入到MindStudio用户帮助界面。
图6
1.2 创建工程
使用MindStudio主界面的工程管理功能创建一个新的工程,具体步骤为:
a.点击New Project开始创建一个新的工程,如图7所示。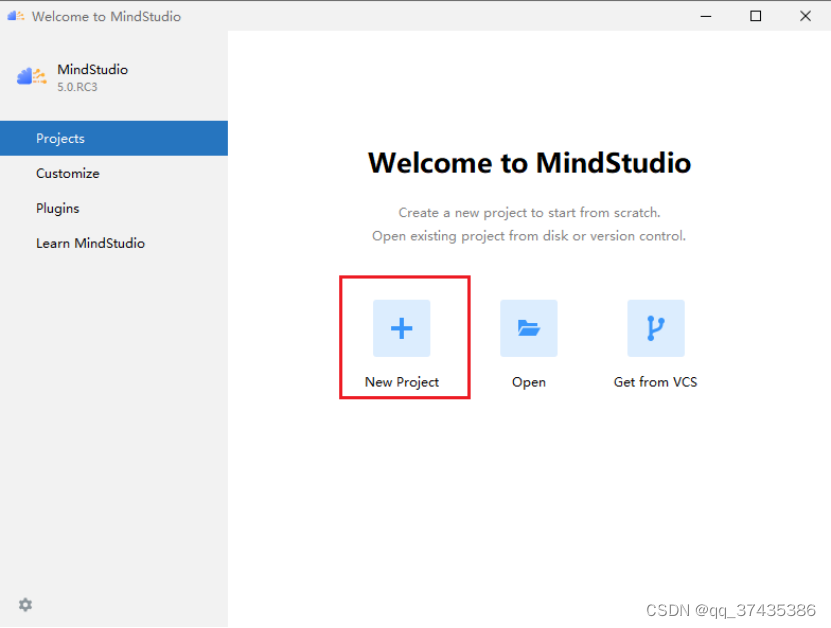
图7
b.New Project界面如图8所示,选择Ascend App,点击Change进行CANN配置。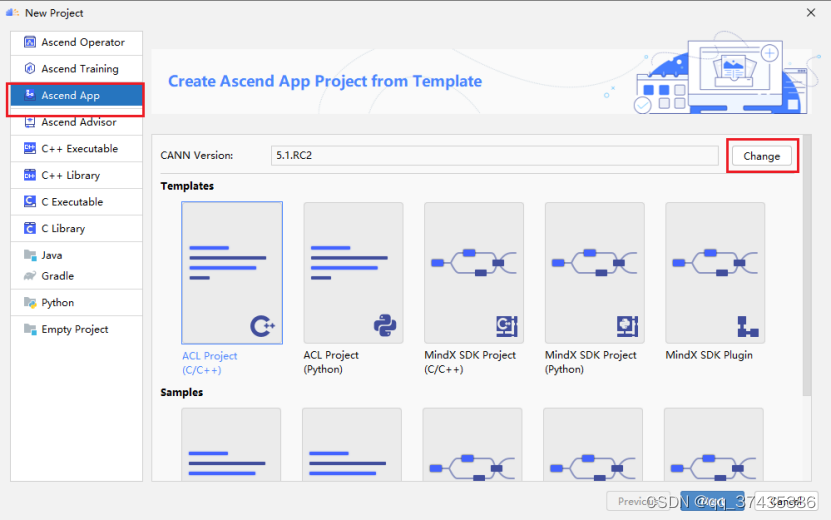
图8
c.CANN配置界面如图9所示,点击Remote Connection的+号图标添加远程服务器链接,点击SSH Configurations中的+号,输入远程服务器相关信息,点击OK。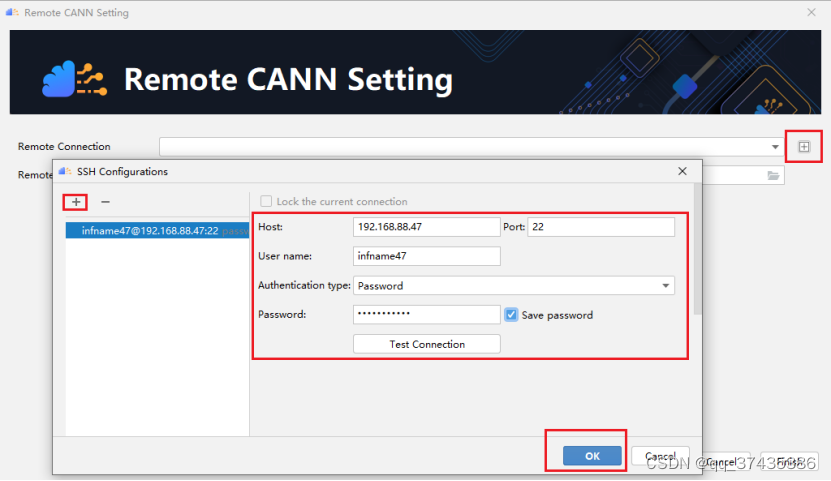
图9
d.如图10所示,点击Remote CANN location中的文件夹图标,选择远程服务CANN安装路径,点击OK确认,点击Finish结束配置。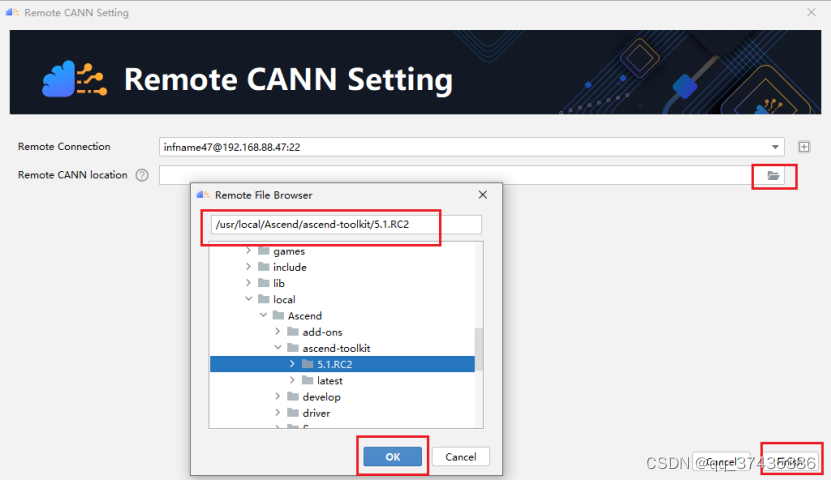
图10
e.CANN配置结束后会自动同步远程CANN信息,如图11所示。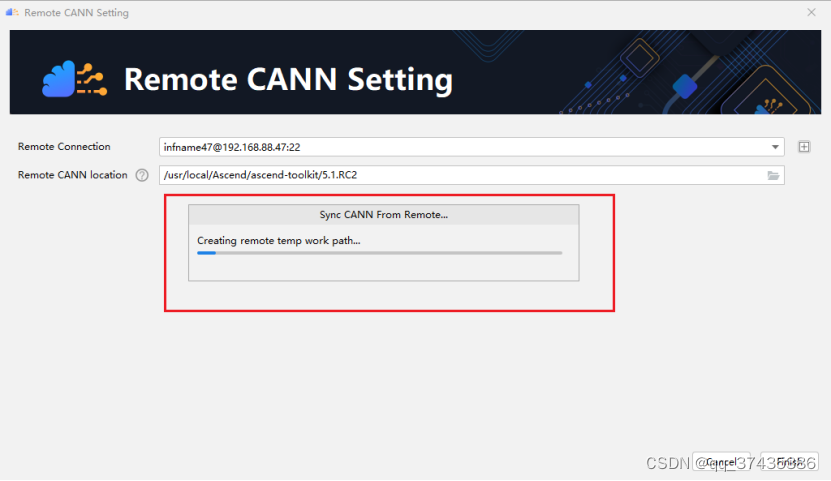
图11
f.同步完成后自动返回New Project界面,如图12所示,选择ACL Project(Python),点击Next继续。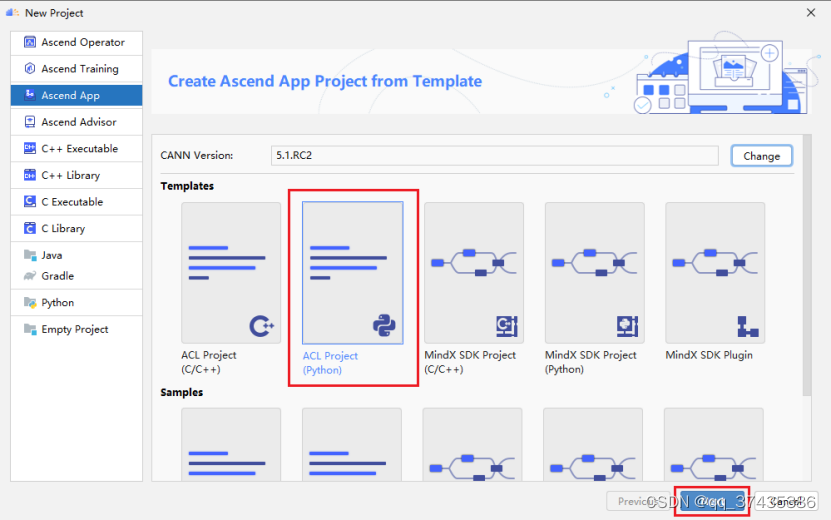
图12
g.设置工程名称和位置,如图13所示,点击Finish继续。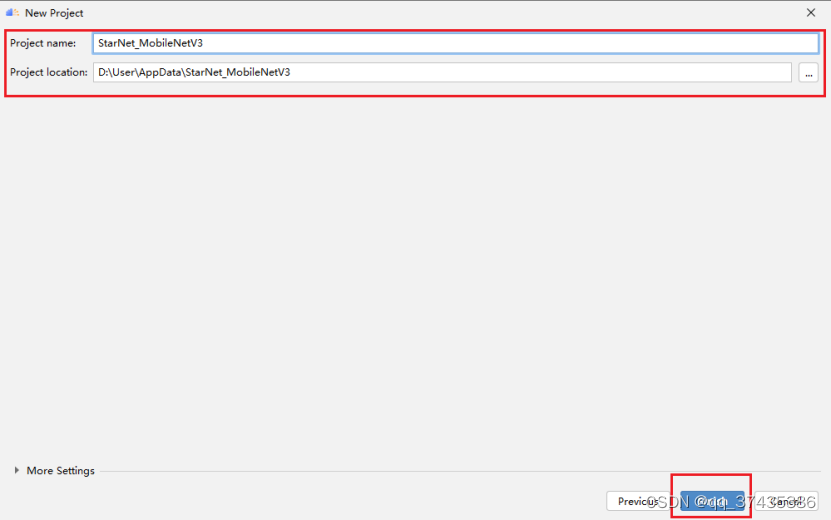
图13
h.如图14所示,自动打开新建工程,此时会弹出提示信息,点击Close关闭,也可以选择不再提示。
图14
通过以上步骤完成工程创建。
1.3 工程配置
工程创建完成后需要进行相关配置,包括SDK、Deployment。具体步骤如下:
a.如图15所示,点击File->Project Structure进入工程结构配置界面。
图15
b.工程结构界面如图16所示,选择SDKs,点击+号,选择Add Python SDK添加Python解释器。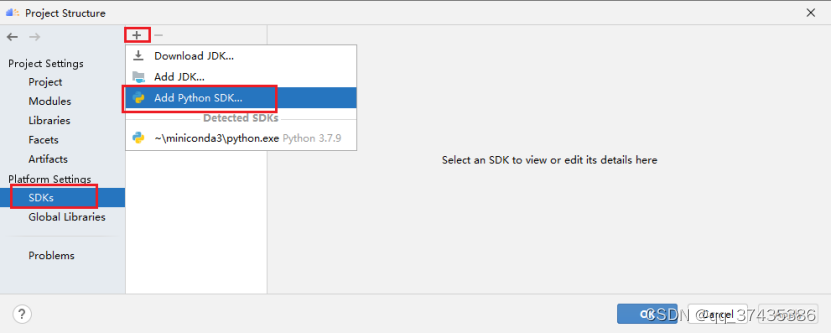
图16
c.在添加Python解释器界面,如图17所示,选择SSH Interpreter,然后选择Deploy会自动识别远程Python相关信息,点击OK完成。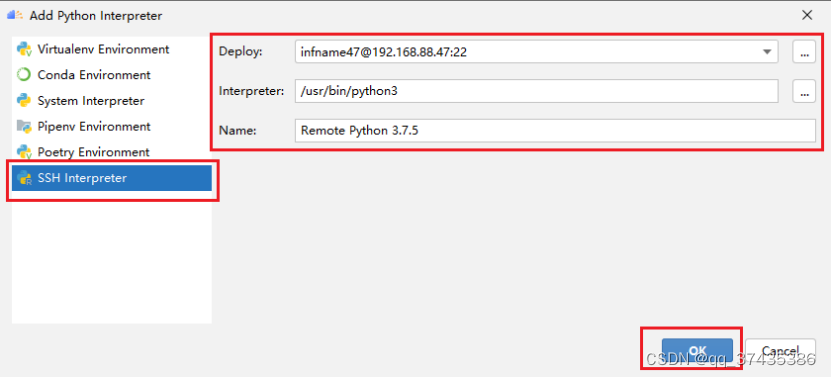
图17
d.返回工程结构界面,如图18所示,选择Project,在SDK列表选择Remote Python,点击OK完成。
图18
e.进入Deployment设置界面,如图19所示,点击Tools-Deployment-Configuration。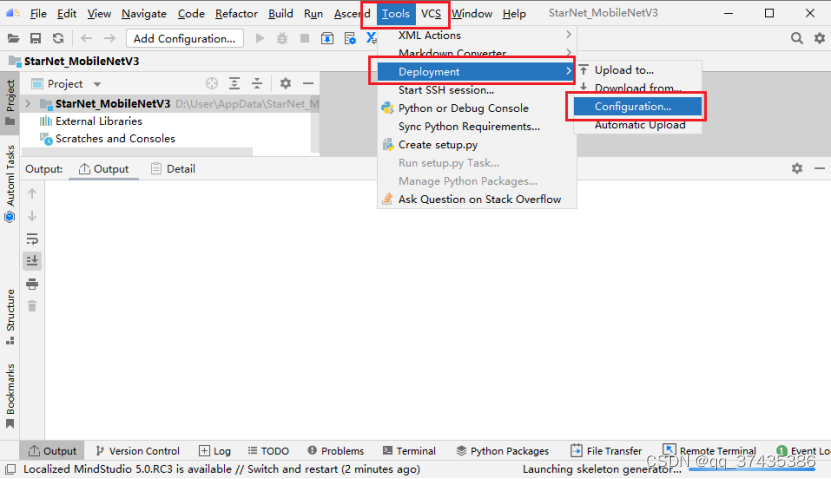
图19
f. Deployment设置界面如图20所示,选择Deployment,点击远程服务器,点击Mappings标签,输入远程开发映射路径,点击OK完成。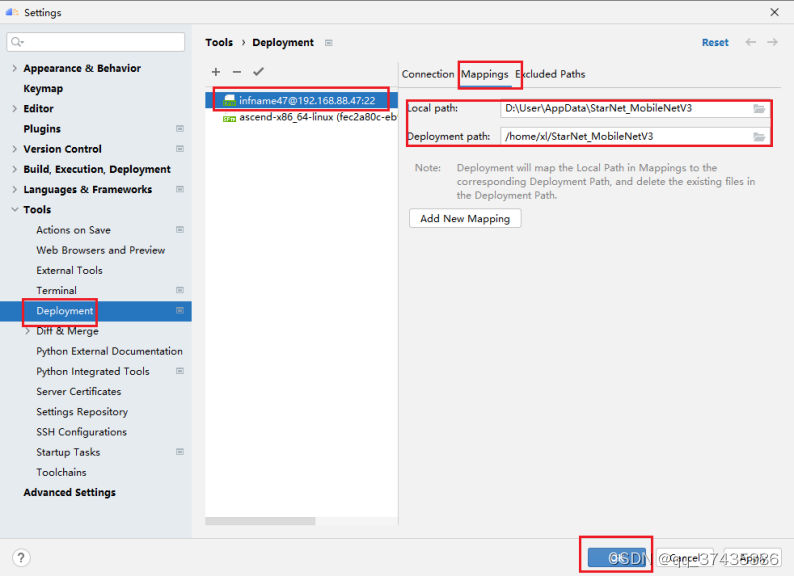
图20
1.4 激活远程终端
a.激活远程终端,如图21所示,点击Tools,选择Start SSH session。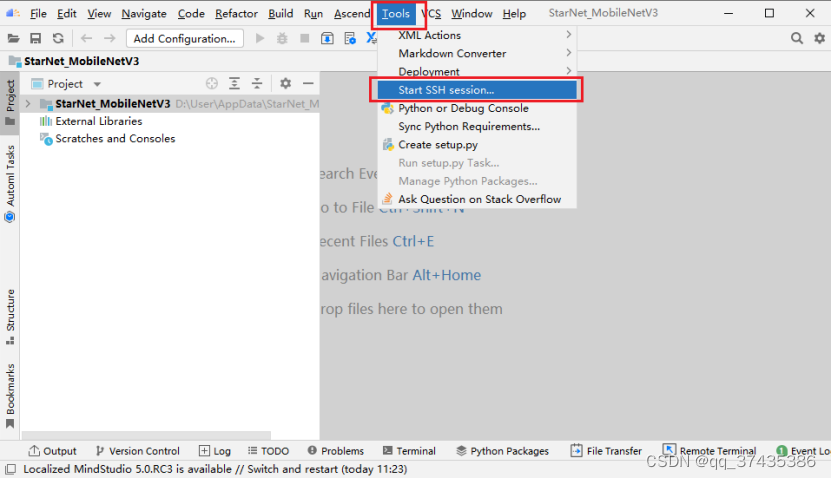
图21
b.如图22所示,在弹出的对话框中选择远程服务器,启动Remote Terminal窗口。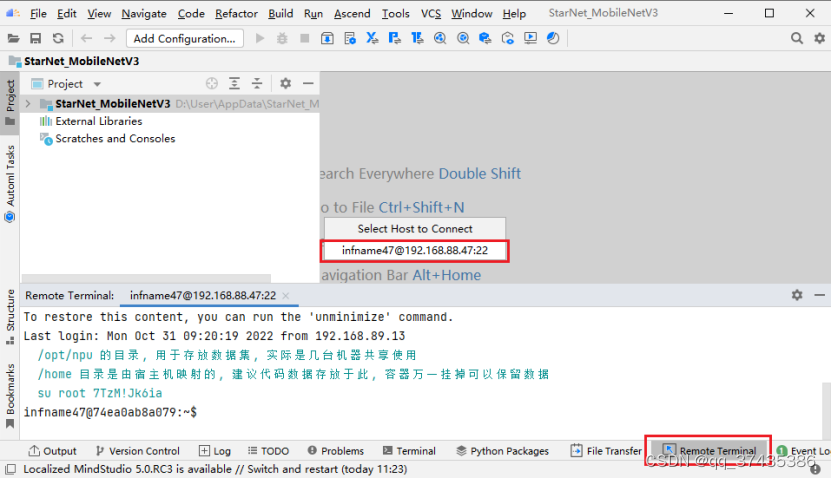
图22
三、模型代码获取
3.1 模型介绍
StarNet是用于图像文本识别的模型,StarNet 强调了通过空间注意机制和残差学习策略从文本区域中提取基于图像的代表性特征的重要性。它是迄今为止提出的用于场景文本识别的最深的神经网络,其结构如图23所示,模型详细介绍可参考论文:STAR-Net: a spatial attention residue network for scene text recognition,链接为:
http://www.bmva.org/bmvc/2016/papers/paper043/paper043.pdf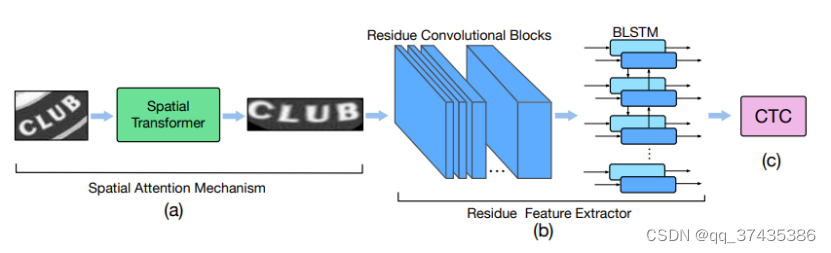
图23
3.2 工程脚本获取
工程相关脚本如图24所示,其中:
inv_delta_C.npy:常量数据
StarNet_MobileNetV3.patch:模型补丁文件
StarNet_MobileNetV3_infer.py:模型推理脚本
requirements.txt:工程依赖信息
图24
3.3 模型代码获取
在本地终端窗口可以通过以下命令获取模型代码:
git clone -b release/2.5 https://github.com/PaddlePaddle/PaddleOCR.git
cd PaddleOCR
git reset --hard a40f64a70b8d290b74557a41d869c0f9ce4959d5
git apply ../ StarNet_MobileNetV3.patch
rm .\applications\
cd ..
mv .\inv_delta_C.npy .\PaddleOCR\tools\
模型代码目录结构如科25所示。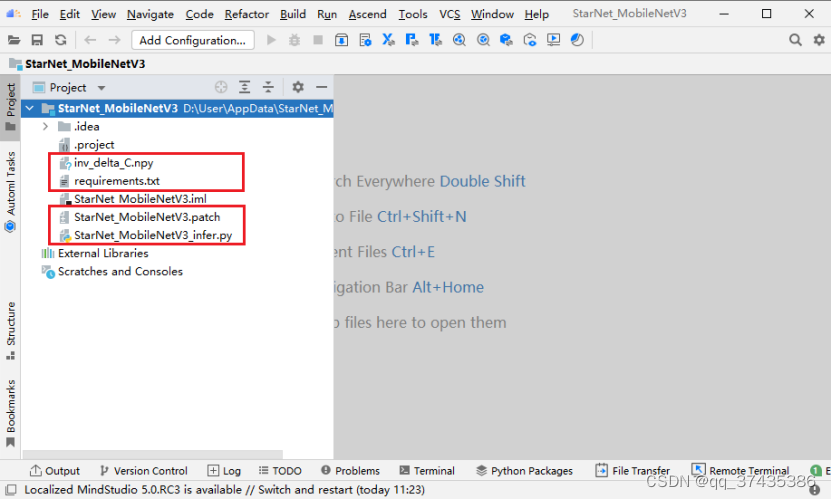
图25
3.4 模型权重获取
模型权重链接为:
https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_mv3_tps_bilstm_ctc_v2.0_train.tar
本地下载后,解压到StarNet_MobileNetV3\checkpoint目录下,如图26所示。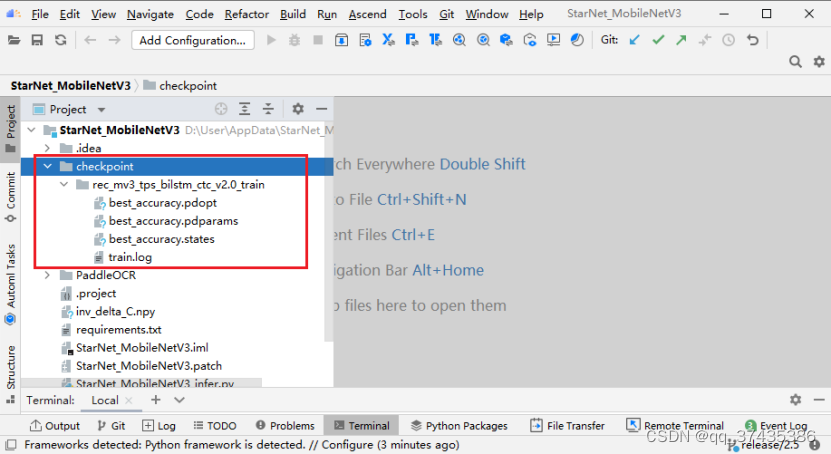
图26
3.5 推理工具获取
推理工具使用的是 ais_infer,该工具的获取、编译、安装说明链接为:
https://gitee.com/ascend/tools/tree/master/ais-bench_workload/tool/ais_infer
下载后将 ais_infer 工具代码放到本地工程路径下,推理工具目录如图27所示。
图27
3.6 同步代码
整个工程代码结构如图28所示,选中工程名称,点击Tools->Deployment->Upload to将代码同步到远程服务器。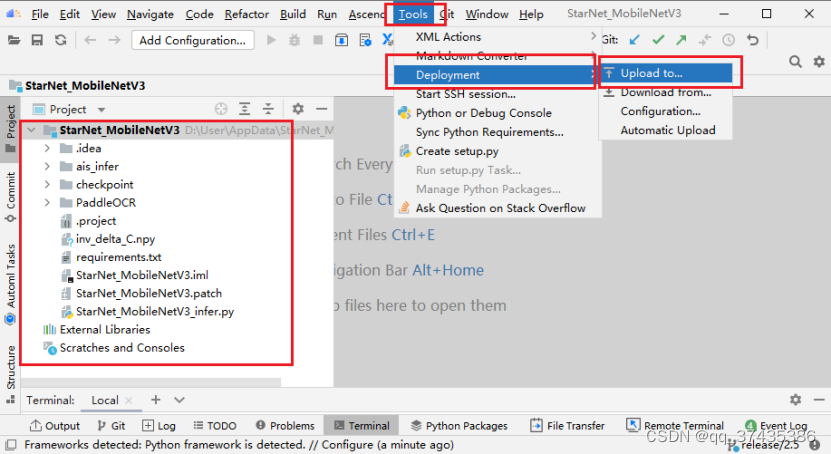
图28
在图29中弹出的对话框中选择远程服务器名称,开始同步文件。
 图29
图29
3.7 配置远程环境
在远程终端窗口中需要通过以下步骤配置远程服务器环境
a.通过cd命令进入远程映射目录。
b.安装依赖,命令为:
pip3 install -r requirements.txt --user
c.进入ais_infer编译目录,命令为:
cd ais_infer/backend/
d.进行编译,命令为:
pip3 wheel ./
e.安装编译好的python包,命令为:
pip3 install aclruntime-0.0.1-cp37-cp37m-linux_x86_64.whl
f.返回到远程项目目录,命令为:
cd ../../
通过以上步骤完成代码获取以及远程环境配置。
四、模型转换
4.1 转onnx模型
a.首先创建可执行命令,如图30所示,点击Add Cofiguration。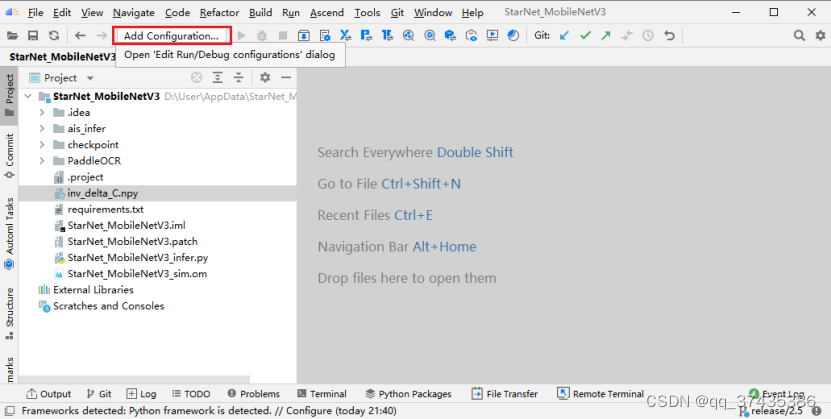
图30
b.命令配置界面如图31所示,点击+号,选择Python。
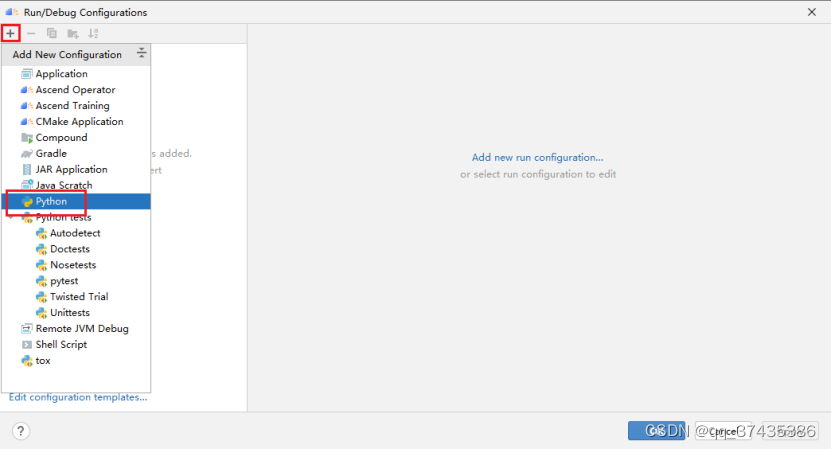
图31
c.命令配置界面如图32所示,需要配置的参数为:
1.Name:命令名称
2.Script Path:可执行脚本
3.Parameters:命令参数,具体如下:
-c /home/xl/StarNet_MobileNetV3/PaddleOCR/configs/rec/rec_mv3_tps_bilstm_ctc.yml
-o
Global.pretrained_model=/home/xl/StarNet_MobileNetV3/checkpoint/rec_mv3_tps_bilstm_ctc_v2.0_train/best_accuracy
Global.save_inference_dir=/home/xl/inference/rec_starnet
参数说明:
-c:模型配置脚本
-o:可配置参数:Global.pretrained_model表示训练权重,Global.save_inference_dir表示推理权重保存路径
4.Use specified interpreter:使用指定Python解释器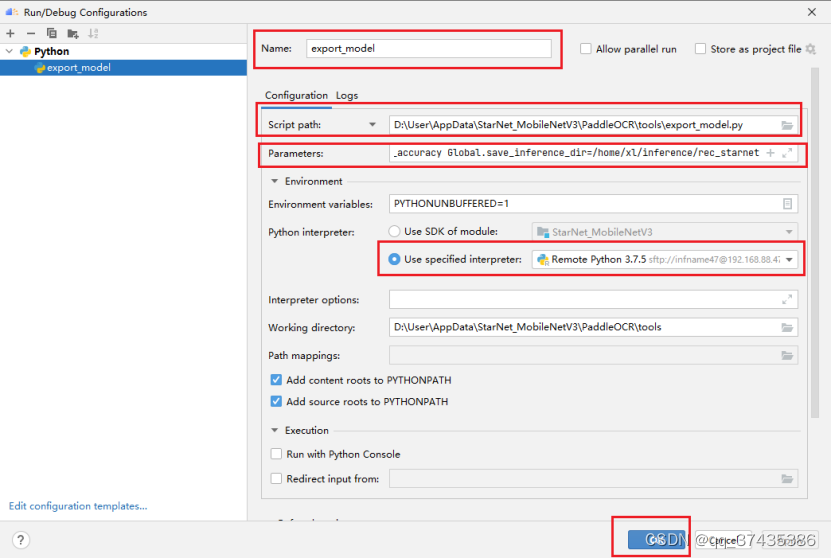
图32
d.运行命令,如图33所示,点击命令执行按钮。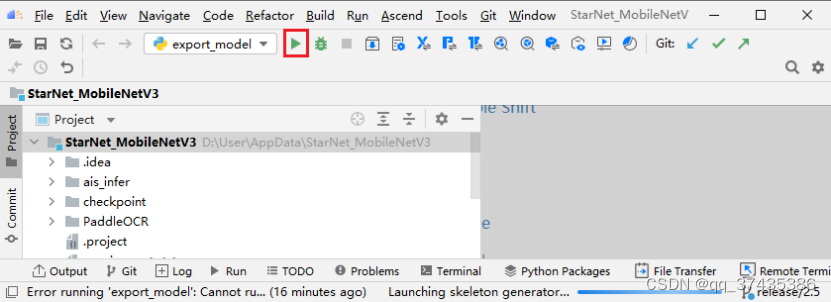
图33
e.成功转出推理权重如图34所示。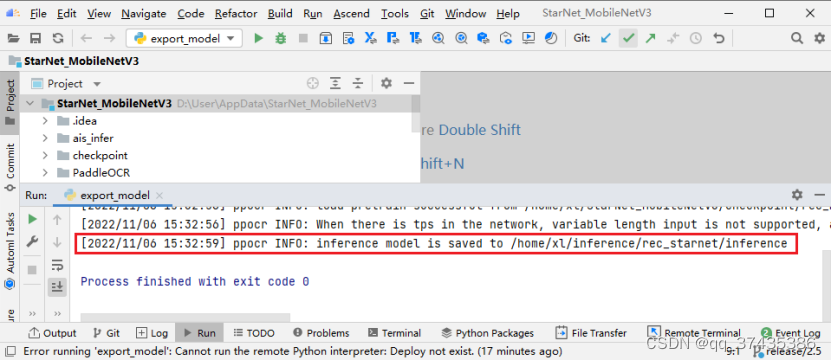
图34
f.然后在远程终端窗口使用paddle2onnx工具命令将推理权重转为onnx模型,命令为:
paddle2onnx \
--model_dir ../inference/rec_starnet \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--save_file ../StarNet_MobileNetV3.onnx \
--opset_version 11 \
--enable_onnx_checker True
成功转出onnx模型如图35所示,模型名称为:StarNet_MobileNetV3.onnx。
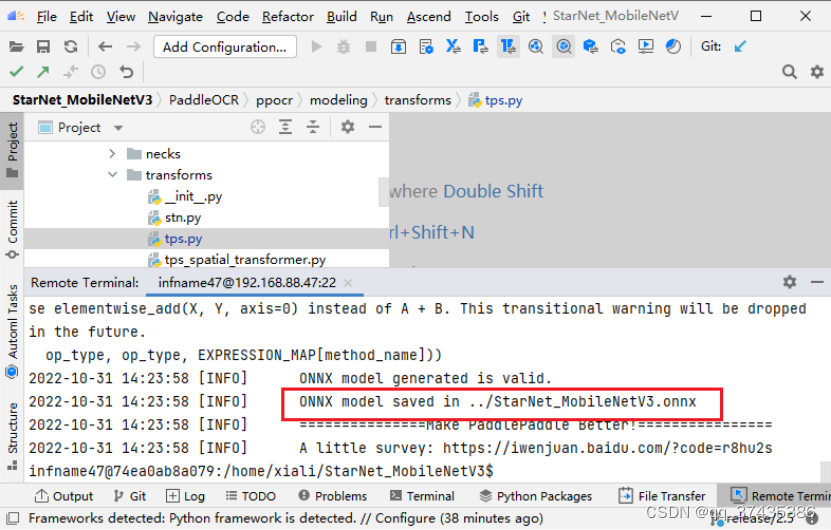
图35
g.最后使用onnx simplifier工具优化模型,该工具的作用是对onnx模型进行常量折叠和shap推导,得到最终的用于转om的onnx模型:StarNet_MobileNetV3_sim.onnx。命令为:
onnxsim ../StarNet_MobileNetV3.onnx ../StarNet_MobileNetV3_sim.onnx
4.2 转om模型
将onnx转为om模型需要用到MindStudio的模型转换功能,具体步骤如下:
a.打开模型转换功能,如图36所示,点击Model Converter按钮。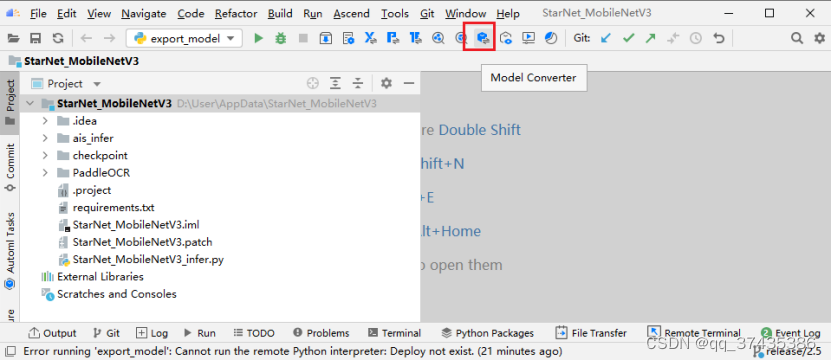
图36
b.进入Model Converter界面,如图37所示,点击Model File文件夹图标,然后选择远程环境中的onnx模型,点击OK。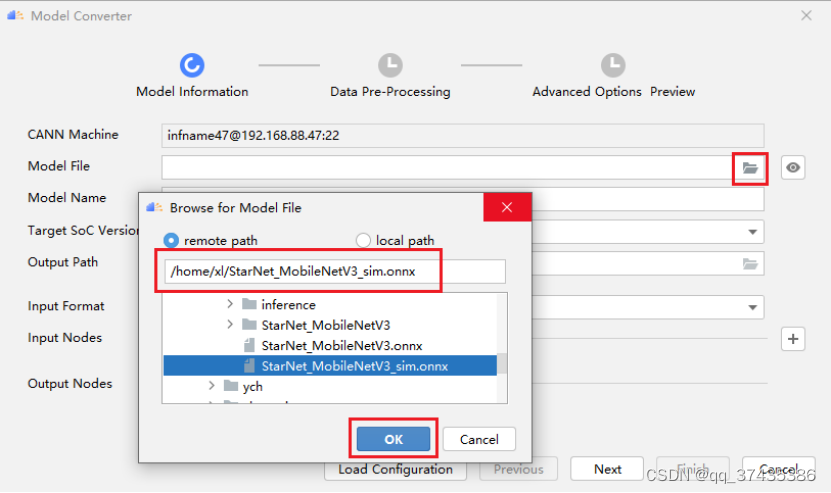
图37
开始自动解析onnx模型信息,如图38所示。
图38
c.模型解析完成后,如图39所示,补全模型转换信息,点击Next继续,模型转换参数信息包括如下:
1.Model Name:保存om模型的名称
2.Target SoC Version:目标芯片型号,本文使用的是Ascend310P3
3.Output Path:om模型保存路径
4.Input Format:输入数据格式,本文模型使用是NCHW,表示图像数据。
5.Input Nodes:模型输入节点:本文模型包括一个x,其Shape为1,3,32,100,Type为FP32。
6.Output Nodes:模型输出节点,本文没有配置,使用默认输出节点。
图39
d.对模型参数进行校验后如图40所示,不选择进行数据预处理,点击Next继续。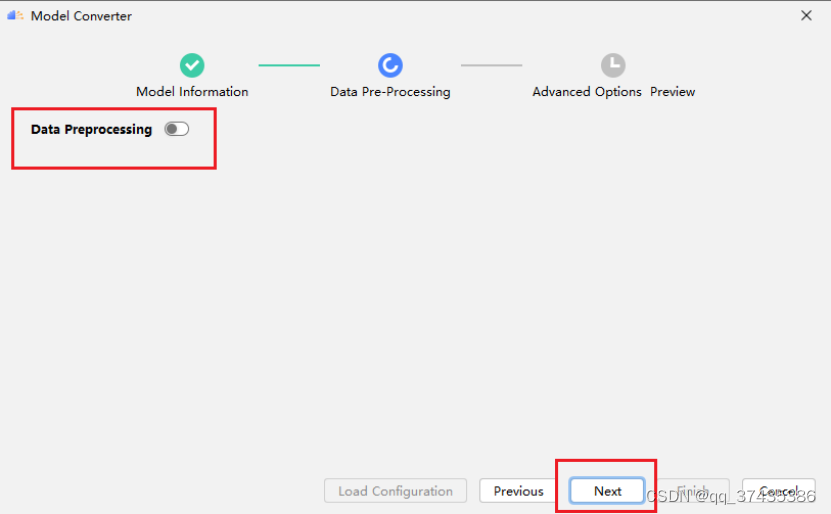
图40
e.确认模型转换命令,如图41所示,点击Finish完成,开始进行模型转换。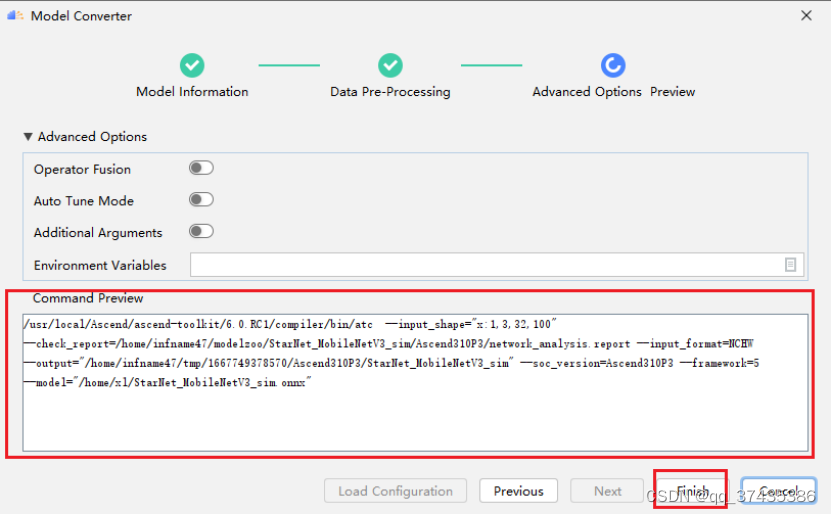
图41
f.模型转换完成后如图42所示,同时在本地生成om模型:StarNet_MobileNetV3_sim.om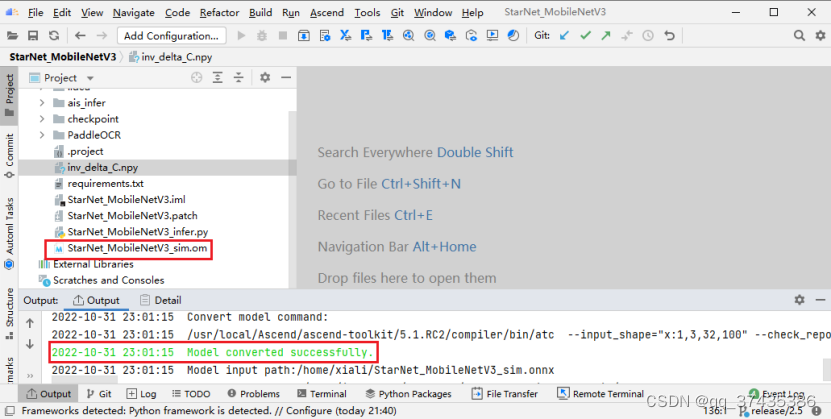
图42
通过以上步骤完成了模型转换。
五、图像文字识别
获取om模型StarNet_MobileNetV3_sim.om后,可以进行离线推理,步骤如下:
a.创建离线推理命令,如图43,点击Edit Configurations。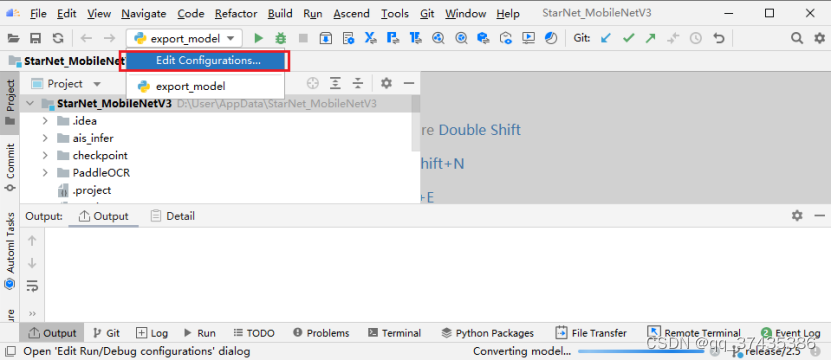
图43
b.命令配置界面如图44所示,点击+号,选择Python。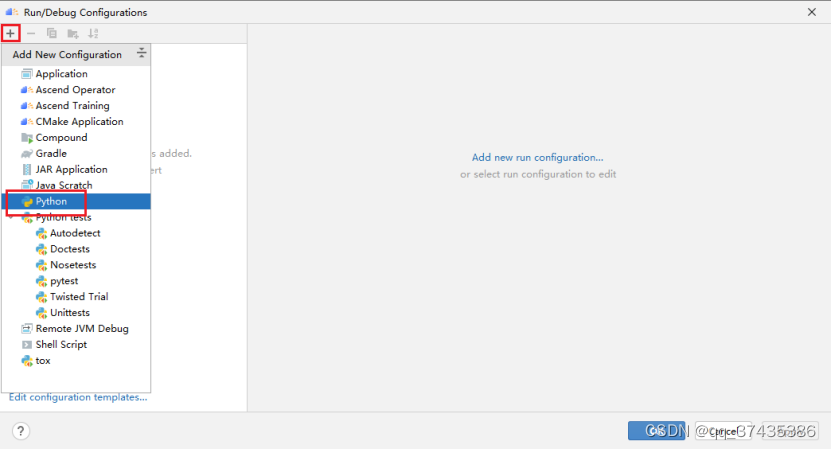
图44
c.命令配置界面如图45所示,输入可执行命令名称、可执行脚本、参数、Python 解释器,点击 OK 完成创建。其中命令参数为:
--image_dir="PaddleOCR/doc/imgs_words/en/word_3.png" \
--rec_model_dir="/home/xl/inference/rec_starnet/" \
--rec_image_shape="3, 32, 100"\
--rec_char_dict_path="./PaddleOCR/ppocr/utils/ic15_dict.txt"
参数说明:
--image_dir:推理图片路径
--rec_model_dir:离线权重路径
--rec_image_shape:图片 shape 信息
--rec_char_dict_path:文字字典路径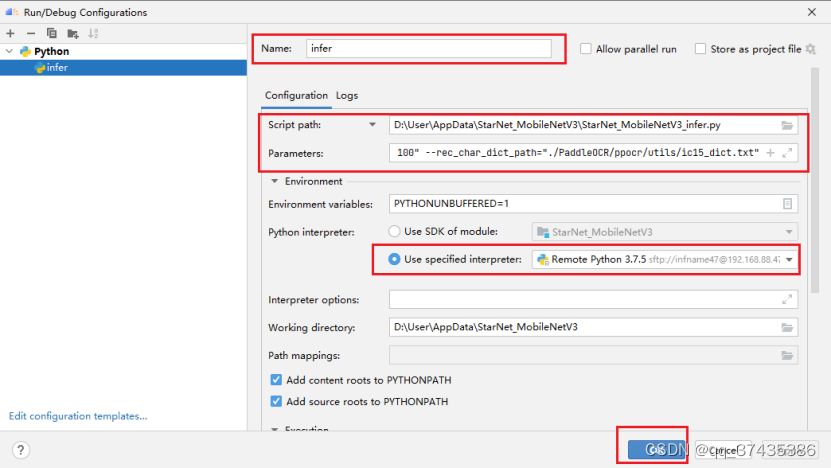
图45
d.执行推理,如图46所示,点击运行按钮开执行推理命令。
图46
e.命令运行完成后,推理结果如图47所示,对图像word_3.png的识别结果为:154。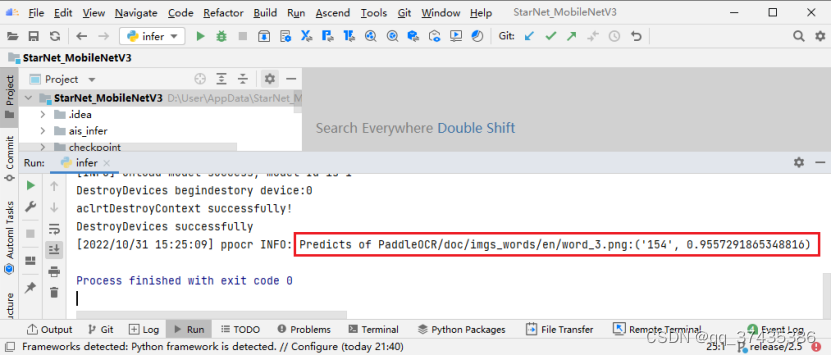
图47
f.查看原始图片,如图48所示,可以看出原始图片word_3.png的内容为154,和推理结果一致。
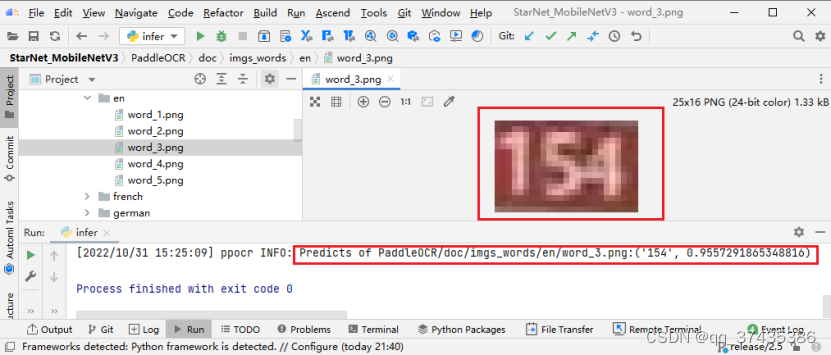
图48
通过以上步骤完成了StarNet_MobileNetV3模型英文图像文字识别,并且识别结果与原始图片内容一致。
六、总结
在使用MindStudio进行StarNet_MobileNetV3模型英文图像文字识别开发,整个指导、参考主要通过以下渠道,供大家参考:
1.MindStudio用户手册:
https://www.hiascend.com/document/detail/zh/mindstudio/50RC3/progressiveknowledge/index.html
2.MindStudio开发者社区:
https://bbs.huaweicloud.com/forum/forum-945-1.html
3.MindStudio B站:
https://space.bilibili.com/1611070055















 628
628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









