







写个文档,方便以后查询。
一、搭建准备
1、
主机:ubuntu 16.04.1 desktop
虚拟机:virtualbox
版本 5.1.22 r115126 (Qt5.5.1)
服务器操作系统:ubuntu16.04.2 server
软件包:
jdk-8u121-linux-x64.tar.gz
hadoop-2.8.0.tar.gz
zookeeper-3.4.10.tar.gz
hbase-1.3.0-bin.tar.gz
spark-2.1.0-bin-without-hadoop.tgz
2、ip地址规划
Master:192.168.0.190
Slave1:192.168.0.191
动态添加删除节点测试IP
Slave2:192.168.0.192
3、安装规划
创建用户hadoop 所有文件均安在hadoop用户目录下
二、安装准备
。。。。。省略安装服务器步骤 百度很多教程。。。。。
1、创建用户hadoop //-------Master,Slave1,Slave2都要
$sudo useradd -m hadoop -s /bin/bash //--------(d /home/hadoop)有参数-m 可以不加; -p 我尝试很多次 加不上密码 不知道什么问题
$sudo usermod -g hadoop -G sudo hadoop //--------赋予用户使用sudo命令
$sudo passwd hadoop
passwd: hadoop //-------hadoop用户密码
2、查看/home目录下有无hadoop,权限详情
$sudo ls -s /home
drwxr-xr-x 3 ff ff 4096 May 11 11:44 ff //--------(搭建服务器时创建的用户)
drwxr-xr-x 17 hadoop hadoop 4096 May 15 16:46 hadoop
drwx------ 2 root root 16384 May 11 10:58 lost+found
以下操作均在用户hadoop下进行 命令 $su hadoop
3、主机名修改
//-------vi分三种模式:一般模式,编辑模式,命令行模式。
$sudo vim /etc/hostname //-------vim工具没有,可以在联网的情况下输入 $sudo apt-get install -y vim
localhost //-------一般模式下双击dd 删除此行 不确定什么模式可以按Esc进入一般模式
点击键盘i进入编辑模式 输入Master 点击Esc 在一般模式下用命令行输入:x保存退出 //-----命令行模式就是在一般模式下输入:即可 //----Slave1/2 修改省略 方法一样
$sudo hostname Master //----Slave1/2 修改省略 方法一样
4、ip地址映射 //---------Master,Slave1/2均需要修改
$sudo vim /etc/hosts
输入:$ 使光标移动到最后 点击o添加
192.168.0.190 Master
192.168.0.191 Slave1
192.168.0.192 Slave2
5、ssh无密钥登录搭建 //-------具体原理和搭建可以百度
$ssh-keygen -t rsa //------Master,Slave1/2
Master$ssh-copy-id hadoop@Master //-------公钥不给自己 hadoop启动会让输入密码
Master$ssh-copy-id hadoop@Slave1
Master$ssh-copy-id hadoop@Slave2
Slave1$ssh-copy-id hadoop@Master
Slave1$ssh-copy-id hadoop@Slave1
Slave1$ssh-copy-id hadoop@Slave2
Slave2$ssh-copy-id hadoop@Master
Slave2$ssh-copy-id hadoop@Slave1
Slave2$ssh-copy-id hadoop@Slave2
6、软件包上传
电脑主机:
ubuntu16.04.1$:scp -r /home/cat/下载/* hadoop@192.168.0.190:/home/hadoop //------(/home/cat/下载/)是你的下载包位置,*是通配符,代表所有的文件
至此 安装准备搭建完成
三、hadoop搭建
Master:~$vim tar.sh //-------编辑脚本解压会方便很多 内容如下
#!/bin/bash
echo -e "\033[36m ======= START TAR.GZ ======= \033[0m" //----可以省略
for i in /home/hadoop/*.tar.gz;
do
tar -zxvf $i -C /home/hadoop
done
echo -e "\033[36m ======= START TGZ ======= \033[0m" //----可以省略
for ii in /home/hadoop/*.tgz;
do
tar -zxvf $ii -C /home/hadoop
done
echo -e "\033[35m ======= END ======= \033[0m" //------可以省略
保存退出
赋予权限 Master:~$sudo chmod 755 tar.sh
执行 Master:~$./tar.sh
2、环境变量
$sudo vim /etc/profile //----(vim ~/.bashrc也可) spark、hadoop都有start-all.sh 所以我没有写spark环境变量
export JAVA_HOME=/home/hadoop/jdk1.8.0_121
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export HADOOP_HOME=/home/hadoop/hadoop-2.8.0
export ZOOKEEPER_HOME=/home/hadoop/zookeeper-3.4.10
export HBASE_HOME=/home/hadoop/hbase-1.3.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$HBASE_HOME/bin //----PATH=$PATH很重要 不能写错
保存退出 输入如下
$source /etc/profile
Master$cd /home/hadoop/hadoop-2.8.0/etc/hadoop
3、编辑hadoop的几个重要文件
Master:/home/hadoop/hadoop-2.8.0/etc/hadoop$vim hadoop-env.sh
//---------(vim 命令行下输入/export JAVA 查找关键字)
export JAVA_HOME=/home/hadoop/jdk1.8.0_121 //-------修改为
保存退出
Master:/home/hadoop/hadoop-2.8.0/etc/hadoop$vim cors-site.xml
//-------在<configuration></configuration>之间添加:
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-temp</value>
</property>
<!---------以下是扩展,可以不写------->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property> //-----------------:x
第二个重要文件
Master:/home/hadoop/hadoop-2.8.0/etc/hadoop$vim hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name> //-------------dfs.name.dir 也可
<value>/home/hadoop/hadoop-temp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name> //-------------dfs.data.dir 也可
<value>/home/hadoop/hadoop-temp/dfs/data</value>
</property>
<property>
<name>dfs.hosts</name> //---------------节点白名单
<value>/home/hadoop/datanode-allow.list</value>
</property>
<property>
<name>dfs.hosts.exclude</name> //-----------------节点黑名单
<value>/home/hadoop/datanode-deny.list</value>
</property>
<!-----------以下是扩展 可以不写---------->
<property>
<name>dfs.web.ugi</name>
<value>supergroup</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/home/hadoop/hadoop-temp/dfs/namesecondary</value>
</property>
<property>
<name>dfs..datanode.max.xcievers</name>
<value>4096</value>
</property>
第三个文件
Master:/home/hadoop/hadoop-2.8.0/etc/hadoop$vim mapreduce-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
<!------------- 以下可以不写-------------->
<property>
<name>mapred.remote.os</name>
<value>Linux</value>
</property>
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
<property>
<name>mapreduce.applicatoin.classpath</name>
<value>
/home/hadoop/hadoop-2.8.0/etc/hadoop,
/home/hadoop/hadoop-2.8.0/share/hadoop/common/*,
/home/hadoop/hadoop-2.8.0/share/hadoop/common/lib/*,
/home/hadoop/hadoop-2.8.0/share/hadoop/yarn/*,
/home/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/*,
/home/hadoop/hadoop-2.8.0/share/hadoop/hdfs/*,
/home/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/*,
/home/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/*,
/home/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/*
</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1536</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3072</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx3072M</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx6144M</value>
</property>
<property>
<name>mapreduce.cluster.map.memory.mb</name>
<value>-1</value>
</property>
<property>
<name>mapreduce.cluster.reduce.memory.mb</name>
<value>-1</value>
</property>
第四个
Master:/home/hadoop/hadoop-2.8.0/etc/hadoo$vim yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>Master:8088</value>
</property>
<!--------------以下可以不写-------------->
<property>
<name>yarn.nodemanager.aux-service.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>Master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>Master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>Master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>Master:8033</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>
/home/hadoop/hadoop-2.8.0/etc/hadoop,
/home/hadoop/hadoop-2.8.0/share/hadoop/common/*,
/home/hadoop/hadoop-2.8.0/share/hadoop/common/lib/*,
/home/hadoop/hadoop-2.8.0/share/hadoop/yarn/*,
/home/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/*,
/home/hadoop/hadoop-2.8.0/share/hadoop/hdfs/*,
/home/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/*,
/home/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/*,
/home/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/*
</value>
</property>
修改slaves文件
Master:/home/hadoop/hadoop-2.8.0/etc/hadoop$vim slaves
删除原有的地址 添加
slave1
至此文件修改完毕
6、创建黑白名单列表文件 //-------------------注意当前所在路径
Master:~$touch datanode-allow.list && touch datanode-deny.list
7、传输hadoop jdk文件夹 //-------------------注意当前所在路径
Master:~$scp -r jdk1.8.0_121/ hadoop@Slave1:/home/hadoop
Master:~$scp -r hadoop-2.8.0/ hadoop@Slave1:/home/hadoop
删除Slave1hdfs-site.xml中的黑/白名单配置 否则格式化会出错
8、在Master上进行
Master:~$hdfs namenode -format
Master:~$start-all.sh
Master:~$mr-jobhistory-daemon.sh start historyserver
Master:~$jps
18209 NameNode
18882 JobHistoryServer
18917 Jps
18582 ResourceManager
18427 SecondaryNameNode
在ubuntu 16.04.1主机web页面输入192.168.0.190:50070 验证 //-----------0.110是因为我之前用的ip是0.110 请根据Master ip进行验证
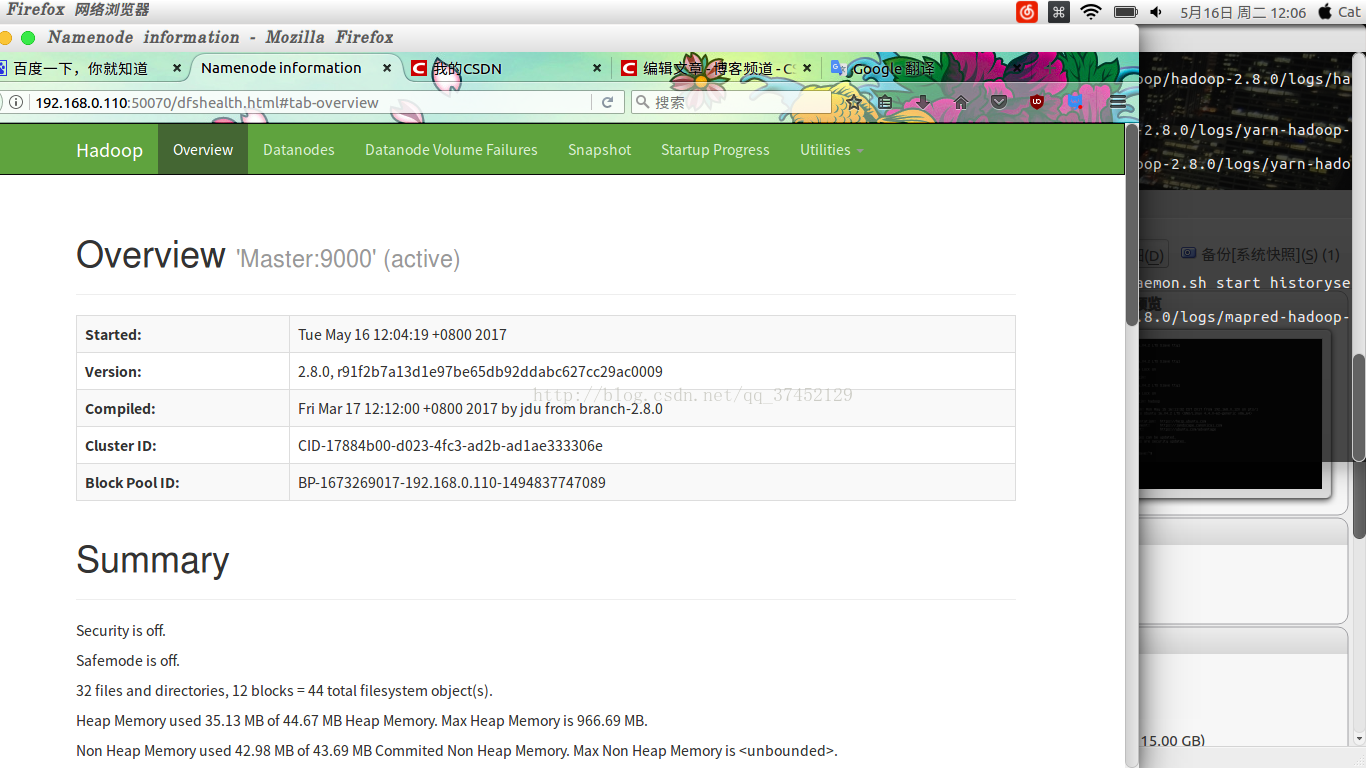
验证集群之否有问题:
Master:~$vim Test.txt
ID Name Type Age
1 Tom 88.00 18
2 Jon 91.00 19
3 Tim 70.00 17
Master:~$hadoop fs -mkdir /input
Master:~$hadoop fs -ls /
Found 3 items
drwxr-xr-x - hadoop supergroup 0 2017-05-16 12:13 /input
drwxr-xr-x - hadoop supergroup 0 2017-05-15 16:57 /system
drwxrwx--- - hadoop supergroup 0 2017-05-15 16:43 /tmp
Master:~$hadoop fs -put Test.txt /input
Master:~$hadoop fs -ls /input
Found 1 items
-rw-r--r-- 3 hadoop supergroup 62 2017-05-16 12:14 /input/Test.txt
Master:~$hadoop jar hadoop-2.8.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar wordcount /input /output
Master:~$hadoop fs -ls -R /output
-rw-r--r-- 3 hadoop supergroup 0 2017-05-16 12:17 /output/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 94 2017-05-16 12:17 /output/part-r-00000
Master:~$hadoop fs -cat /output/part-r-00000
1 1
17 1
18 1
19 1
2 1
3 1
79.00 1
88.00 1
91.00 1
Age 1
ID 1
Jon 1
Name 1
Tim 1
Tom 1
Type 1
至此hadoop搭建完毕 如出现问题 请百度解决
四、Zookeeper搭建
hadoop@Master:~$ cd zookeeper-3.4.10/conf/
hadoop@Master:~/zookeeper-3.4.10/conf$ l
configuration.xsl log4j.properties zoo_sample.cfg
hadoop@Master:~/zookeeper-3.4.10/conf$ cp zoo_sample.cfg zoo.cfg
hadoop@Master:~/zookeeper-3.4.10/conf$ vim zoo.cfg //--------修改如下配置
dataDir=/home/hadoop/zookeeper-3.4.10/data
server.0=Master:2888:3888
server.1=Slave1:2888:3888
hadoop@Master:~/zookeeper-3.4.10$ mkdir data && echo 0 > data/myid
hadoop@Master:~/zookeeper-3.4.10$ cat data/myid
0
hadoop@Master:~/zookeeper-3.4.10$ scp -r /home/hadoop/zookeeper-3.4.10/ hadoop@Slave1:/home/hadoop/
hadoop@Slave1:~$ echo 1 > zookeeper-3.4.10/data/myid
hadoop@Slave1:~$ cat zookeeper-3.4.10/data/myid
1
hadoop@Master:~/zookeeper-3.4.10$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
hadoop@Master:~/zookeeper-3.4.10$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower
hadoop@Slave1:~$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
hadoop@Slave1:~$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: leader
zookeeper搭建完毕 失败请找zookeeper.out日志查看问题
五、hbase搭建
hadoop@Master:~$ cd hbase-1.3.0/conf/
hadoop@Master:~/hbase-1.3.0/conf$ l
hadoop-metrics2-hbase.properties hbase-policy.xml regionservers
hbase-env.cmd hbase-site.xml
hbase-env.sh log4j.properties
hadoop@Master:~/hbase-1.3.0/conf$ vim hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://Master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>Master,slave1</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/zookeeper-3.4.10/data</value>
</property>
</configuration>
hadoop@Master:~/hbase-1.3.0/conf$ vim regionservers
Master
Slave1
hadoop@Master:~/hbase-1.3.0/conf$vim hbase-env.sh
export JAVA_HOME=/home/hadoop/jdk1.8.0_121
export HBASE_MANAGES_ZK=false
hadoop@Master:~/hbase-1.3.0/conf$ scp -r /home/hadoop/hbase-1.3.0/ hadoop@Slave:/home/hadoop/
hadoop@Master:~/hbase-1.3.0/conf$ start-hbase.sh
hadoop@Master:~/hbase-1.3.0/conf$ jps
20272 HRegionServer
18209 NameNode
18882 JobHistoryServer
20082 HMaster
18582 ResourceManager
19686 QuorumPeerMain
20330 Jps
18427 SecondaryNameNode
web 192.168.0.190:16010
六、spark搭建
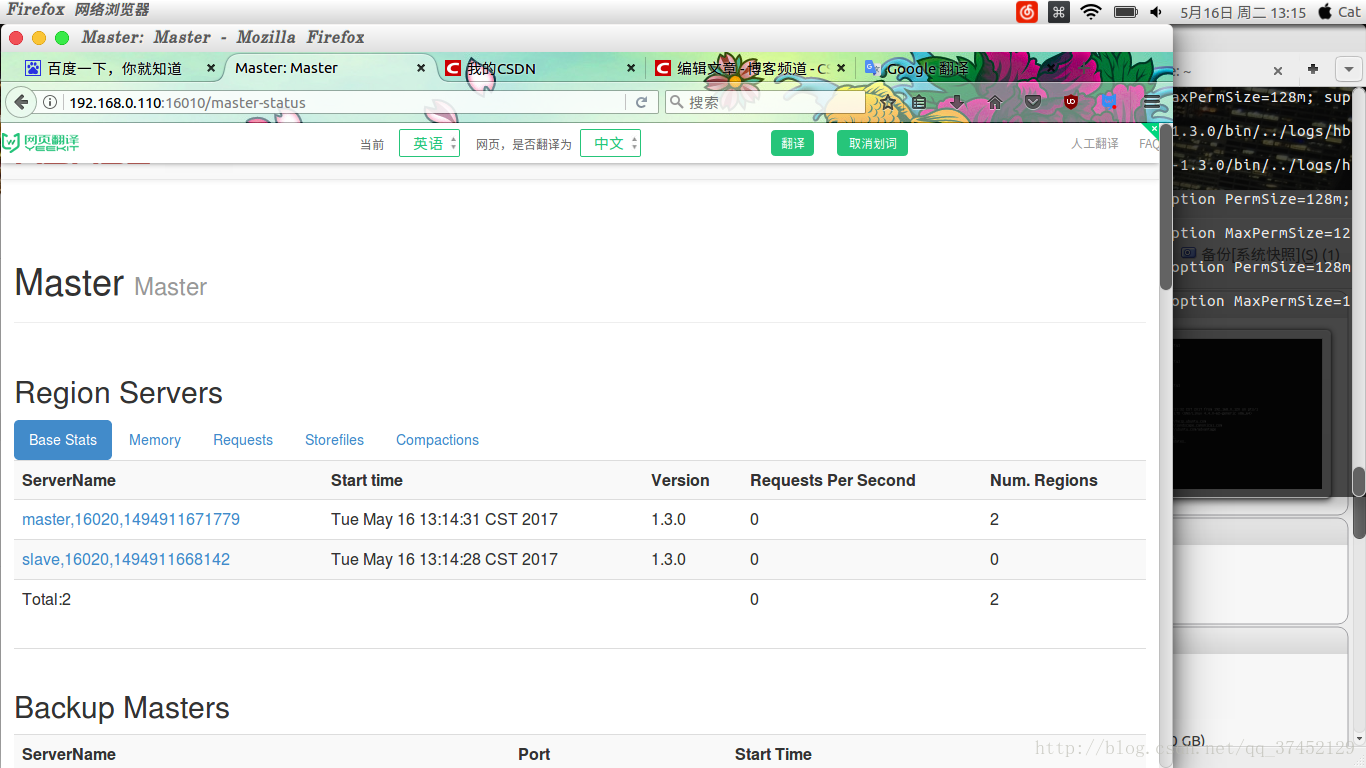
hadoop@Master:~/hbase-1.3.0/conf$ cd
hadoop@Master:~$ cd spark-2.1.0-bin-without-hadoop/
bin/ data/ jars/ python/ sbin/
conf/ examples/ licenses/ R/ yarn/
hadoop@Master:~$ cd spark-2.1.0-bin-without-hadoop/
hadoop@Master:~/spark-2.1.0-bin-without-hadoop$ l conf/
docker.properties.template slaves.template
fairscheduler.xml.template spark-defaults.conf.template
log4j.properties.template spark-env.sh.template*
metrics.properties.template
hadoop@Master:~/spark-2.1.0-bin-without-hadoop$ cp conf/slaves.template conf/slaves
hadoop@Master:~/spark-2.1.0-bin-without-hadoop$ cp conf/spark-env.sh.template conf/spark-env.sh
hadoop@Master:~/spark-2.1.0-bin-without-hadoop$ cp conf/spark-defaults.conf.template conf/spark-defaults.conf
hadoop@Master:~/spark-2.1.0-bin-without-hadoop$ vim conf/spark-env.sh
最后方添加如下
export JAVA_HOME=/home/hadoop/jdk1.8.0_121
export HADOOP_HOME=/home/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=/home/hadoop/hadoop-2.8.0/etc/hadoop
export SPARK_MASTER_HOST=Master
export SPARK_CLASSPATH=$(/home/hadoop/hadoop-2.8.0/bin/hadoop classpath)
hadoop@Master:~/spark-2.1.0-bin-without-hadoop$vim conf/spark-defaults.conf
spark.master spark://master:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://Master:9000/directory
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 5g
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
hadoop@Master:~/spark-2.1.0-bin-without-hadoop$ vim conf/slaves
删除localhost
添加:
Master
Slave1
hadoop@Master:~$ rm -rf hadoop-2.8.0/share/hadoop/common/lib/servlet-api-2.5.jar hadoop-2.8.0/share/hadoop/tools/lib/servlet-api-2.5.jar hadoop-2.8.0/share/hadoop/yarn/lib/servlet-api-2.5.jar hadoop-2.8.0/share/hadoop/hdfs/lib/servlet-api-2.5.jar
hadoop@Master:~/spark-2.1.0-bin-without-hadoop$ scp -r /home/hadoop/spark-2.1.0-bin-without-hadoop/ hadoop@Slave1:/home/hadoop/
hadoop@Master:~/spark-2.1.0-bin-without-hadoop$ sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /home/hadoop/spark-2.1.0-bin-without-hadoop/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-Master.out
Slave: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/spark-2.1.0-bin-without-hadoop/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-Slave.out
Master: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/spark-2.1.0-bin-without-hadoop/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-Master.out
hadoop@Master:~/spark-2.1.0-bin-without-hadoop$ jps
20272 HRegionServer
21744 Jps
18209 NameNode
18882 JobHistoryServer
20082 HMaster
21571 Master
18582 ResourceManager
19686 QuorumPeerMain
21689 Worker
18427 SecondaryNameNode
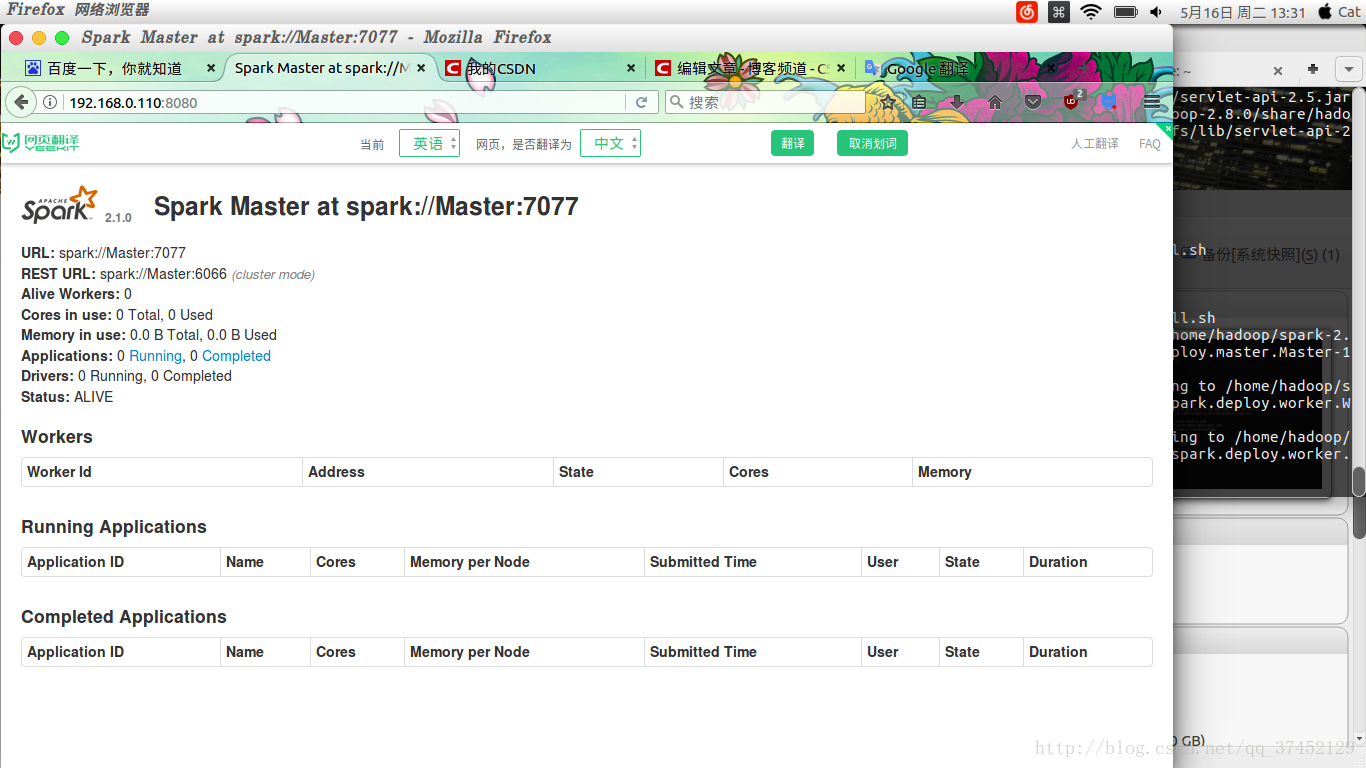
spark web端口号8080
4040监视端口需要打开spark-shell














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









