







目录
2.3 宏定义 #if 、#ifdef 、#ifndef 与 #endif
目录
2.3 宏定义 #if 、#ifdef 、#ifndef 与 #endif
前言
在支持POU的3.7.16版本内测期间,我有幸成为首批试用者,并撰写了一些针对特定功能和场景的短文。这些文章受到了积极的反馈,帮助了许多人,并收到了宝贵的意见,比如对系统性讲解的需求。但由于工作繁忙,我不得不将这一项目暂时搁置。
随着时间的推移,我在实际应用中遇到并解决了众多问题,这些经历让我深有感触。因此,我利用业余时间逐步完成了这份指南,旨在为更多同事和新接触信捷的朋友们提供帮助。
本指南并不追求深入的技术细节,而是旨在构建一个知识框架,以便快速掌握。尽管我们使用的是C语言,但信捷平台在许多方面都有其独特的概念和操作,这使得它与传统C语言并不完全相同。对于那些没有C语言经验的人来说,他们可能会发现,尽管参考了网络上的教程,实际应用中却感到困惑。而对于那些已经习惯了C语言的开发者来说,他们可能更多地感到不适应和不适。通过阅读本指南,你可以逐步了解信捷平台的设计思路,从而减少疑惑。本指南另一个显著优点是案例完全结合工控实际应用场景,例如轴控制,模拟量数据处理等。这些内容主要是基于我个人的实践与推断,虽不一定完全准确,但从逻辑上讲是合理的,并且测试结果也支持文中提到的内容。我希望大家在阅读后都能有所收获。本人V:Flovui。
注意事项:下文中提到的标准均为信捷PLC标准C,不等价其他编译器。本指南为个人理解与实践整理,不敢保证绝对正确,但是代码都是正常跑的,欢迎交流讨论。
1 数据类型
1.1 常用基本数据类型
1.1.1 整型
short:标准16bit整数类型。
int:标准32bit整数类型。
long long:标准64bit整数类型(long通常为32bit)。
1.1.1.1 修饰符
signed:有符号。
unsigned:无符号。
例如unsigned int即为无符号32bit整型。
1.1.2 浮点型
float:标准32bit浮点数类型。
double:标准64bit浮点数类型。
1.2 IEC61131-3标准基本数据类型
以下简称IEC标准。
使用IEC标准数据类型的要求:开发软件版本需要3.7.16及以上。
使用IEC标准数据类型的好处:关键字异色易识别(REAL)、关键字自动提示、错误易排查。同时新的ST语言POU也是使用这套数据类型,使用新标准对于移植或者学习ST都有很大好处。实际对于C底层来说只是一个新的重定义而已。
此类型数据在全局变量表中声明新的数据时可以看到列表中重定义的IEC标准数据类型。
1.2.1 整型
SINT:IEC8bit有符号整数类型。
INT:IEC16bit有符号整数类型。
DINT:IEC32bit有符号整数类型。
LINT:IEC64bit有符号整数类型。
USINT:IEC8bit无符号整数类型。
UINT:IEC16bit无符号整数类型。
UDINT:IEC32bit无符号整数类型。
ULINT:IEC64bit无符号整数类型。
1.2.2 浮点型
REAL:IEC32bit浮点数类型。
LREAL:IEC64bit浮点数类型。
1.2.3 位串型
BYTE:IEC8bit位串类型。
BOOL:IEC8bit位串类型。
WORD:IEC16bit位串类型。
DWORD:IEC32bit位串类型。
LWORD:IEC64bit位串类型。
1.3 常用复杂数据类型
1.3.1 数组(一维)
相同类型的元素组成的集合。
当我们需要用不同变量存储相似属性的数据时,就需要使用数组。下面举一个例子,某现场有5台电机,每个电机都有一个手动速度,如果不使用数组,我们定义每个轴的手动速度变量就需要写以下这种代码:
LREAL m_vel0=10,m_vel1=10,m_vel2=10,m_vel3=10,m_vel4=10;
//或者
/*
LREAL m_vel0=10;//手动速度0,赋初值10
LREAL m_vel1=10;
LREAL m_vel2=10;
LREAL m_vel3=10;
LREAL m_vel4=10;
*/可以看到这种定义方式非常啰嗦,要定义的数量越多越复杂,如果我们使用数组的话,这种情况下的变量定义就会变得十分简洁,如以下代码:
LREAL m_vel[5]={10,10,10,10,10};//定义数据长度为5个REAL数据的数组并挨个赋初值为10
//LREAL m_vel[5]={10};//对于赋相同值的情况,这种赋值方式等价于上一行这样不管是定义还是使用都会变得十分方便。
//第一种定义方式操作轴2的速度
m_vel2=20;
//第二种定义方式操作轴2的速度
m_vel[2]=20;
//数组形式还方便批量操作,下面写一个安全阈值保护,每个轴的速度不允许超过30.0
int i=0;
for(i=0;i<5;i++)
{
if(m_vel[i]>30.0)
{
m_vel[i]=30;
}
}
1.3.2 结构体
结构体(struct):不同类型的元素组成的集合。
1.3.2.1 结构体变量
实际应用中我们知道轴不可能只有一个手动速度的变量,以EtherCAT总线控制为例,做手动运行时通常还会有加减速度、停止方式(减速停机、急停),那么我们要为手动速度这样一个使用场景建立速度、加速度、减速度、停机模式四个数组么?毫无疑问这样会很麻烦,所以我们可以利用结构体完成我们的目的。我们对一个轴建立一个手动速度控制参数结构体,里面包含四个元素,LREAL型速度、加速度、减速度;UINT型停止模式(0:减速停机1:急停)。代码如下:
typedef struct
{
LREAL vel;
LREAL v_acc;
LREAL v_dec;
UINT stop_mode;//0:减速停机;1:急停
}M_VEL_CTRL_DATA;//标准格式,定义手动速度控制参数结构体类型,和INT、REAL是一个概念
/
M_VEL_CTRL_DATA mvcd;//以类型定义数据对象
mvcd.vel=10;
mvcd.v_acc=100;
mvcd.v_dec=100;
mvcd.stop_mode=1;//0:减速停机;1:急停
/
/
M_VEL_CTRL_DATA mvcd={10,100,100,1};//以类型定义数据对象(快速赋初值方法)
/在上面的代码中我们首先定义了手动控制速度数据结构体类型M_VEL_CTRL_DATA,然后我们用这个类型定义了新的结构体数据mvcd,结构体数据mvcd内有四个数据对象,在程序中引用时使用"."英文句号引用,例如速度就是mvcd.vel。
1.3.2.2 结构体变量数组
结构体作为一种自定义数据类型,同样也可以数组化,我们建立好一个电机的手动控制速度数据结构体数据对象,针对5台电机的场景建立五个结构体数据,一样会不方便。所以结构体数据代码如下:
/
M_VEL_CTRL_DATA mvcd[5];//以类型定义数据对象不赋初值
/
/
M_VEL_CTRL_DATA mvcd[5] = {
{10.0, 100.0, 100.0, 0},
{15.0, 100.0, 100.0, 1},
{20.0, 100.0, 100.0, 0},
{25.0, 100.0, 100.0, 1},
{30.0, 100.0, 100.0, 1}
};//以类型定义数据对象并赋初值
/使用这种方式定义数据最直观的好处就是程序维护变得方便了,并一定程度上降低了开发难度。以往使用寄存器的方式时,我们一般会按每个轴占用13个寄存器,偏移20个寄存器,规划从例如HD0开始的100个字做五个轴的手动速度参数存储。在程序开发时我们需要先对寄存器做类型宏定义,#define LRHD *(LREAL*)&HD,将整数的HD寄存器地址(默认从0开始)强制类型转换位LREAL型指针并解引用,然后在接下来的程序操作LRHD[0]就是第一个轴的速度、LRHD[20]就是第二个轴的速度、LRHD[53]就是第三个轴的停止模式。而当我们使用了结构体方式时,我们定义的mvcd[0].vel就是第一个轴的速度、mvcd[1].vel就是第二个轴的速度、mvcd[2].stop_mode就是第三个轴的停止模式。在我们实际开发中,3.7.16以上版本的XDPPRO做了许多兼容,定义结构体数据变得十分简单,再后面的章节中会做讲解,前期先从C语言本身的角度入手。
1.3.3 枚举
枚举(enum):一组命名的整数常量。
枚举类型可以使我们的程序更加具有可读性,在上面的程序中我们的stop_mode可以通过赋0或者1的值来设置轴的停止模式。每个轴的编号是数组索引编号,在程序繁多的时候,密密麻麻的0、1经常会令我们头晕转向,为了便于分辨和后期维护,只能在后面加注释,但是阅读代码时,注释在后面往往无法在第一时间得知0、1、2、3等数字的意义,针对这种情况,我们可以使用枚举工具,将0、1、2等顺序整数值定义为更有意义的文字符号。示例代码如下:
typedef enum {
STOP_MODE_DECELERATE = 0, // 减速停机
STOP_MODE_EMERGENCY = 1 // 急停
} StopMode;
typedef enum {
AXIS_X, //轴0
AXIS_Y, //轴1
AXIS_Z, //轴2
AXIS_C0, //轴3
AXIS_C1 //轴4
} AxisIndex;
//枚举类型内默认第一元素从0开始排列
/*
typedef enum {
STOP_MODE_DECELERATE = 2, // 减速停机
STOP_MODE_EMERGENCY // 急停
} StopMode;//从2开始顺序排列
typedef enum {
STOP_MODE_DECELERATE = 10, // 减速停机
STOP_MODE_EMERGENCY = 24 // 急停
} StopMode;//不顺序且有单独值的排列
*/
mvcd[AXIS_X].vel = 20;//轴0的手动速度被设置为20
mvcd[AXIS_Z].stop_mode = STOP_MODE_EMERGENCY;//轴2的停止模式被设置为急停1.3.4 指针
指针:存储另一个变量的内存地址。
典型特点:跨函数操作变量。
1.3.4.1 基本指针
指针在C语言内是一个十分复杂的概念,本文作为基本开发指南,只讲解部分常用的变量指针。首先是基本数据类型变量指针,我们以INT型变量var为例,代码如下:
INT i = 0;//声明INT类型变量i,即申请一个大小为INT的内存区域,此区域名为i
INT* i_p = NULL;//声明指向INT类型的指针变量i_p,并初始化为空
i_p = &i;//将变量i的地址赋值给指针变量i_p
//于是我们有两种向变量i赋值的方法
1
i=10;//向INT型变量i赋值整数10
2
*i_p=10;//向INT型指针变量i_p存储的地址代表的内存赋值整数10在C语言中,变量不是抽象的概念,变量有具体的大小和地址。在上面的案例中,当我们声明INT类型变量i时,就是向内存申请了一块大小为INT的内存空间,其地址是随机的。在我们的PLC中的寄存器,我认为是指向具体地址的指针变量。
指针是专用于存储变量地址的变量,指针的类型,则是规定该指针允许存储什么类型变量的地址。例如INT类型的指针变量不允许存储REAL类型变量的地址。所以声明指针的语句结构就是【变量类型* 指针变量名;】在变量类型后面加星号,然后空格,然后指针变量名、分号。星号放在指针变量名前也等价【变量类型 *指针变量名;】,但是出于规范和安全考虑,建议统一放在类型后面。除了常用变量类型的指针,数组指针、指针的指针、void指针本指南不讨论,可以自行研究。
在案例的第三行,变量i的左侧出现了一个特殊的符号【&】,这个符号在变量前面的作用是取变量的地址,所以这个语句的效果就是将INT型变量i的地址获取出来,赋值给存储INT型变量地址的指针变量i_p。这样指针变量i_p内就存储了变量i的地址。
在案例的第五行,展示了指针变量最常见的用法,看到这里可能会觉得抽象,但是没关系,这里不是真正用指针的地方,后面在结构体指针和函数参数指针会深入讲。在这一行出现了另一个特殊符号【*】,这个符号的作用是解引用指针,所谓解引用就是使【星号+指针变量】这个语句指向指针变量内所存储的地址代表的数据。在上面的案例中,指针变量i_p存储的是变量i的地址,所以解引用i_p指针变量,实际上就是指向了变量i里的数据。可以将i理解为INT大小的某地址的名字、别名,i_p是存储INT大小地址的容器,*i_p就是i_p变量内存储的INT大小的地址,所以*i_p等价于i。在汇编语言中,内存都是具体的十六进制地址,在C中地址被变量名取代,所以很难理解指针。用现实的例子举例,以【公司】作为变量名,声明变量【公司 无锡信捷电气股份有限公司】,那么【无锡信捷电气股份有限公司】这个变量的地址就是【无锡市滨湖区建筑西路816号】。我们再声明一个指针变量【公司* 自动化公司】,然后给指针变量【自动化公司】赋值变量【&无锡信捷电气股份有限公司】的地址,那么指针变量【自动化公司】内存储的就是【无锡市滨湖区建筑西路816号】。 最后我们对指针变量【自动化公司】解引用,于是变量【无锡信捷电气股份有限公司】和指针解引用【*自动化公司】的实际意义都是【无锡市滨湖区建筑西路816号】这个地址上的具体公司,所以这两种操作是等价的。
重点注意指针变量声明后要及时初始化,如果未初始化就会变成野指针。初始化要么在声明是就用&符号取某个变量地址进行赋值,要么就像案例中赋值NULL宏定义,意为地址空。如果未经初始化,指针内存储的地址将是随机的,对未知的地址解引用,会导致程序异常、系统出错等情况。
1.3.4.2 结构体指针
在结构体小节内,指南讲述了结构体变量的引用,直接引用结构体变量是一种快捷操作,但是当结构体变量作为函数的参数传递时,函数会将整个结构体的数据复制到函数参数内,这样当结构体数据足够庞大时,会消耗极多的性能,所以通常,在函数传递结构体时,会用结构体指针当作参数来间接操作结构体数据,毕竟指针传递的地址,比庞大的结构体数据要小的多得多。例如我们轴控的POU引用轴结构体,实际上都是结构体指针,梯形图里没有&取地址符是因为做了优化,当我们在C语言的POU中编写程序时,向对应参数赋值时都需要加&取地址符,更多的会在函数与轴控部分继续讨论,下面基于结构体变量小节的案例举一个结构体指针的例子。
typedef struct
{
LREAL vel;
LREAL v_acc;
LREAL v_dec;
UINT stop_mode;//0:减速停机;1:急停
}M_VEL_CTRL_DATA;//标准格式,定义手动速度控制参数结构体类型,和INT、REAL是一个概念
/
M_VEL_CTRL_DATA mvcd;//以类型定义数据对象
/
/
M_VEL_CTRL_DATA* mvcd_p=NULL;//定义结构体指针并初始化为空
mvcd_p = &mvcd;//向结构体指针赋值结构体变量地址
/
/
mvcd.vel=10;
mvcd.v_acc=100;
mvcd.v_dec=100;
mvcd.stop_mode=1;//0:减速停机;1:急停
/
/
mvcd_p->vel=10;
mvcd_p->v_acc=100;
mvcd_p->v_dec=100;
mvcd_p->stop_mode=1;//0:减速停机;1:急停
/在上面的代码中【->】符号是操作结构体指针变量指向的结构体成员的常用符号,利用指针知识,我们可以看出mvcd.vel和mvcd_p->vel这两种操作是等价的。在我们的软件中,输入结构体引用符号【.】或【->】后,会自动排列出结构体内可操作的成员。
2 常用宏定义与关键字
在C语言中,宏定义是通过预处理器指令#define实现的,它们在编译之前就被处理。宏定义可以用于定义常量、创建复合的宏表达式、条件编译等。以下是一些常见的C语言宏定义:
NULL:表示空指针
true 和 false:布尔值真和假。
size_t:无符号整数类型,用于表示对象的大小。
sizeof:计算变量、常量、数据类型的字节大小。常与size_t配合使用。
#ifdef、#ifndef、#define、#undef:用于条件编译。
#if、#ifdef、#ifndef、#else、#elif、#endif:用于编译时的条件判断
2.1 宏定义 #define 的基本用法
1、定义常量
有些场合,例如定义一个最大限制,这个参数在程序很多地方都会用到,那么用宏定义就很方便,将来修改程序只需要修改宏定义即可。或者定义M寄存器的地址。都可以有效提高代码可读性。#define 的基本格式是【#define 宏的名 宏的值】,案例如下:
#define MAX 10
int num;
if(num < Max)
{
//……
}
if(num == Max)
{
//……
}
if(num > Max)
{
//……
}#define SysRegAddr_M_D_HD
#define MOTOR_START_ADDR 100
if(M[MOTOR_START_ADDR])
{
//……
}#define SysRegAddr_M_D_HD是一个比较特别的定义,我也暂时没有弄明白,这里先不深究,只要知道怎么用就好。有新的需要在C中访问的地址,就在这行后面加_地址即可,例如添加HSD脉冲输出累计寄存器。在C中需要访问第一路脉冲输出的累计值HSD0寄存器时,就在这一行后面添加_HSD,然后在下面定义#define DINT_HSD *(DINT*)&HSD,程序中写DINT_HSD[0],即可访问HSD0寄存器。#define DINT_HSD *(DINT*)&HSD在进阶用法里面会详细说。
2、给变量赋别名
尤其是给D或者HD寄存器赋别名。
#define NUM i
int i=0;
if(NUM==0)
{
//……
}#define NUM D[0]
if(NUM==0)
{
//……
}
2.2 宏定义 #define 的进阶用法
#define 还可以定义带参数的宏,或者宏函数,这允许创建更复杂的代码片段,这些代码片段可以在不同的地方使用不同的参数值。
#define SQUARE(x) ((x) * (x))//一个参数x,后面括号内的语句计算平方#define ABS(x) ((x) < 0 ? -(x) : (x))
//计算绝对值,(语句1?语句2:语句3)的意义是语句1为真时返回语句2的值,否则返回语句3的值#define REAL_HD *(REAL*)&HD
//&HD 首先取HD寄存器的地址
//(REAL*) 其次强制转换为REAL类型的指针
//*(REAL*)&HD 解引用指针
//#define REAL_HD 解引用指针后的数据宏定义为REAL_HD 在C语言中,当使用 #define REAL_HD *(REAL*)&HD 这样的宏定义时,REAL_HD 实际上被定义为一个单一的值,而不是一个数组。然而,由于 REAL_HD 是通过解引用一个指向 REAL 类型的指针得到的,所以可以利用指针算术来访问连续的 REAL 类型的数据。
这里的关键点在于,尽管 REAL_HD 本身不是一个数组,但由于它是一个指针的解引用结果,所以可以像访问数组一样使用它。这是因为在C语言中,指针和数组之间有着非常紧密的关系。具体来说:
-
指针的解引用:
REAL_HD是通过解引用一个指向REAL类型的指针得到的。这意味着REAL_HD实际上是一个REAL类型的值。 -
指针算术:尽管
REAL_HD是一个值,但由于它来源于一个指针的解引用,仍然可以使用指针算术来访问连续的REAL类型的数据。例如,REAL_HD + 1会给下一个REAL类型的地址,REAL_HD + 2会给再下一个REAL类型的地址,以此类推。 -
数组访问:在C语言中,可以通过指针算术来访问数组元素。因此,即使
REAL_HD本身不是一个数组,仍然可以使用REAL_HD[0]、REAL_HD[1]等形式来访问数据,因为这些操作实际上是通过指针算术来实现的。 -
类型转换:在宏定义中,
&HD被转换为REAL*类型的指针,这意味着HD数组的首地址被解释为一个指向REAL类型数据的指针。由于REAL类型的大小是INT 类型大小的两倍,所以每个REAL类型的数据实际上占用了两个INT类型的数据。
因此,尽管 REAL_HD 本身不是一个数组,但由于它是一个指针的解引用结果,仍然可以使用数组访问的方式来访问连续的 REAL 类型的数据。这是C语言中指针和数组之间紧密关系的一个体现。综上,我认为寄存器定义的底层实现,大概率就是整数数组。
#define REAL_HD *(REAL*)&HD
#define MOTOR_SPEED(x) REAL_HD[0 + x * 10]
MOTOR_SPEED(1)=100;//等价REAL_HD[10]=100
MOTOR_SPEED(5)=100;//等价REAL_HD[50]=100值得注意的是,这里面有一个比较特别的东西,就是BIT型寄存器,例如X、Y、M、T、C等,如果直接对他们进行二次定义,例如
#define M_REG M[0]//无效
#define M_REG 0//有效
M[M_REG]=TRUE;
编译器会直接报错。分析错误信息会发现,BIT寄存器地址的实现和其他整数寄存器不同,整数寄存器在分析与测试中,基本就是整数数组。但是BIT寄存器地址背后都是函数,函数有一个参数,参数为指针。BIT寄存器地址的宏定义的对象其实不是数组之类的变量,而是函数。这里先不深入,只要知道像上面代码一样不能直接定义即可,附录中再仔细分析。
2.3 宏定义 #if 、#ifdef 、#ifndef 与 #endif
在C语言中,#if、#ifdef、#ifndef和#endif是预处理指令,用于条件编译。这些指令帮助开发者在编译时根据条件包含或排除代码段,这在处理不同平台的兼容性、特性开关等方面非常有用。下面是这些指令的详细解释:
#if
#if 是 C 语言中的一个预处理指令,用于条件编译。它允许编译器根据指定的条件来决定是否编译某个代码块。如果条件为真(即非零),则编译#if和对应的#endif之间的代码;如果条件为假(即零),则跳过这段代码。
基本语法
#if constant_expression
/* 如果 constant_expression 为真(非零),则编译这部分代码 */
#else
/* 如果 constant_expression 为假(零),则编译这部分代码 */
#endif示例
BMC_AXIS_REF *Axis(int index)
{
#define num 2 //此处修改轴数量
BMC_AXIS_REF *Axis_a[num];
#if(num >= 1)//条件满足,执行
Axis_a[0] = &BMC_Axis000;
#endif
#if(num >= 2)//条件满足,执行
Axis_a[1] = &BMC_Axis001;
#endif
#if(num >= 3)//条件不满足,不执行
Axis_a[2] = &BMC_Axis002;
#endif
}这是我之前开发的轴控相关程序,这里面在num宏定义后面输入本程序有效的轴数量,下面根据条件编译对应的指针数组映射代码方便后面的程序调用。
#ifdef
(如果已定义)指令用于检查一个宏是否已经定义。如果宏已经定义,编译器会编译#ifdef和#endif之间的代码。
语法:
#ifdef 宏名称
/* 宏已定义时编译的代码 */
#endif示例:
#ifdef XD5E_PLC
//……
#endif 在这个例子中,如果XD5E_PLC宏被定义了,那么包含#ifdef XD5E_PLC和#endif之间的代码将被编译;否则,这部分代码将被忽略。
#ifndef
#ifndef(如果未定义)指令用于检查一个宏是否没有定义。如果宏没有定义,编译器会编译#ifndef和#endif之间的代码。
语法:
#ifndef macro_name
/* 宏未定义时编译的代码 */
#endif示例:
#ifndef GLOBAL_H
#define GLOBAL_H
extern INT global_var;
#endif在头文件中是#ifndef最常用的使用场景,在头文件中以此格式可以实现头文件保护功能,即防止多次调用。案例中第一行检查是否定义GOLABL_H宏定义,如果未定义,那么第二行定义这个宏定义并执行后面截止到#endif行的代码,如果检查已定义过,就说明这个头文件被多次包含,则不需要重复执行后面截止到#endif行的代码。
#endif
#endif指令用于结束#ifdef或#ifndef的条件编译块。
条件编译是C语言中一个强大的特性,它允许开发者在不改变代码逻辑的情况下,根据不同的编译条件编译不同的代码。
2.4 关键字 typedef 的基本用法
typedef 是 C 语言中的一个关键字,用于为数据类型定义一个新的名称。它不会创建新的数据类型,而是为已有的数据类型提供一个别名。typedef 的主要目的是提高代码的可读性和可维护性,它允许程序员使用更简洁或更有意义的名称来代替复杂的类型定义。
以下是 typedef 的基本语法:
typedef existing_type new_type_name; 注意:typedef语句的原名称在前,新名词在后,与define相反
existing_type 是已经存在的数据类型。
new_type_name 是为 existing_type 定义的新名称。
举例
1、基本数据类型别名:
typedef unsigned int uint; // 将 unsigned int 定义为 uint
uint a = 10; // 使用 uint 而不是 unsigned int以上是C标准数据类型的重定义,因为我们底层基于C,所以我认为例如UINT,就是
typedef unsigned short UINT这样转换的(C标准short是16bit整数)。
2、 结构体别名:
typedef struct
{
LREAL vel;
LREAL v_acc;
LREAL v_dec;
UINT stop_mode;//0:减速停机;1:急停
}M_VEL_CTRL_DATA;// 将 struct 定义为 M_VEL_CTRL_DATA
M_VEL_CTRL_DATA mvcd;
// 使用 M_VEL_CTRL_DATA 而不是 struct {...}
//利用定义好的结构体类型别名定义新的结构体变量
//以上等价
struct
{
LREAL vel;
LREAL v_acc;
LREAL v_dec;
UINT stop_mode;//0:减速停机;1:急停
}mvcd;
//下面这种写法每定义一个新结构体变量都需要把结构体自身抄写上去,很麻烦2.5 关键字 static 的基本用法
在C语言中,static关键字用于控制变量的存储区和生命周期,以及控制函数和变量的链接属性。以下是static关键字的几种用途和含义:
2.5.1 局部静态变量
当static关键字用于函数内部的局部变量时,它改变了变量的存储区从栈到静态存储区。这意味着变量的生命周期不再局限于函数调用的开始和结束,而是持续到程序的整个运行周期。每次函数调用时,static变量会保留上一次调用结束时的值。
例如:
void func()
{
static INT count = 0; // 局部静态变量
count++;
} 在这个例子中,每次调用func时,count的值都会增加,并且保持在函数调用之间。正常函数局部变量的值只保持到本次调用结束。
2.5.2 全局静态变量
当static关键字用于全局变量时,它限制了变量的链接属性,使得变量只能在定义它的文件内部访问,即变成了内部链接。这与默认的外部链接不同,后者允许其他文件通过extern关键字访问该变量。
例如:
// file1.c
static INT global_var = 10; // 只能在 file1.c 中访问
// file2.c
extern INT global_var; // 错误:无法在 file2.c 中访问 global_var 在这个例子中,global_var只能在file1.c中访问,即使在file2.c中使用extern声明也无法访问。extern关键字下一节说明。
2.5.3 静态函数
当static关键字用于函数时,它将函数的链接属性设置为内部链接,这意味着函数只能在定义它的文件内部调用。这有助于避免命名冲突,并限制函数的作用域。作用域的概念,在函数章节内将详细说明。其意义就是有效范围。
例如:
// file1.c
static void func()
{
// 函数体
}
// file2.c
void func(); // 错误:无法在 file2.c 中调用 func 在这个例子中,func只能在file1.c中被调用。
综上,static关键字是一个多功能的工具,它可以用来控制变量的生命周期、存储位置和链接属性,以及函数的链接属性。正确使用static可以提高程序的效率和安全性。
2.6 关键字 extern 的基本用法
extern 关键字在 C 语言中用于声明全局变量或函数,使其能够在不同的文件中被访问。它主要用来处理跨文件的变量或函数的链接问题。extern 关键字在信捷POU的设计中并不常用,因为POU系统有自己的全局变量,几乎用不到extern 关键字,可以略过,但是在信捷传统函数功能库中是可能频繁使用的,具体差异在信捷POU与函数章节深入探讨。以下是 extern 关键字的详细用法和含义:
2.6.1 声明全局变量
当一个全局变量在一个文件中定义后,其他文件中可以使用 extern 关键字来声明这个变量,从而实现跨文件访问。
定义全局变量: 在一个文件中定义全局变量:
// file1.c
INT global_var = 100; // 全局变量定义 声明全局变量: 在其他文件中使用 extern 声明这个变量:
// file2.c
extern INT global_var; // 声明全局变量
void main()
{
global_var = 50; // 访问全局变量
}2.6.2 声明函数
extern 也用于声明在其他文件中定义的函数,使得这些函数可以在当前文件中被调用。
定义函数: 在一个文件中定义函数:
// file1.c
void func()
{
#define SysRegAddr_D_HD
D[0] = 5;
} 声明函数: 在其他文件中使用 extern 声明这个函数:
// file2.c
extern void func(); // 声明函数
void main()
{
func(); // 调用函数
}2.6.3 链接属性
extern 关键字用于指定变量或函数的链接属性为“外部链接”,这意味着它们可以在程序的其他部分被访问。如果没有使用 extern 声明,编译器会假设该变量或函数只在当前文件中使用,具有“内部链接”。
2.6.4 头文件中的使用
在头文件中使用 extern 声明全局变量是一种常见的做法,这样可以在多个源文件中共享这些变量,而不需要在每个文件中重复定义。
头文件:
// global.h
extern INT global_var; // 声明全局变量源文件:
// file1.c
#include "global.h"
INT global_var = 100; // 定义全局变量使用文件:
// file2.c
#include "global.h"
INT main() {
global_var = 0; // 访问全局变量
return 0;
}2.6.5 注意事项
定义与声明:一个全局变量或函数只能有一个定义,但可以有多个声明。
头文件保护:在使用头文件时,应使用宏定义来防止头文件被多次包含,例如:
#ifndef GLOBAL_H
#define GLOBAL_H
extern INT global_var;
#endif extern 关键字是 C 语言中处理跨文件变量和函数访问的关键工具,正确使用它可以提高代码的模块化和重用性。
2.7 关键字 const 的基本用法
关键字 const 在 C 语言中用于定义常量,即那些一旦初始化后其值不能被改变的变量。使用 const 可以提高代码的可读性和安全性,因为它明确地告诉编译器和程序员,这些变量的值是不应该被修改的。基本用法如下:
2.7.1 定义常量
使用 const 关键字可以定义一个常量,其值在初始化后不能被改变。
const INT MAX_NUM = 100; 在这个例子中,MAX_NUM 是一个常量,其值为 100,不能被修改。
2.7.2 指针和常量
const 可以与指针一起使用,以限制指针指向的数据不能被修改。
const INT *ptr;
INT num = 10;
ptr = #
*ptr = 20; // 错误:不能修改指向的值 在这个例子中,ptr 指向一个 const int,因此不能通过 ptr 修改它指向的值。
2.7.3 常量指针
const 可以用于指针本身,表示指针的值(即它所指向的地址)不能被改变。
INT num = 10;
INT *const ptr = #
ptr = &anotherNum; // 错误:不能改变指针的值 在这个例子中,ptr 是一个常量指针,不能改变它指向的地址。
2.7.4 常量指针到常量数据
const 可以同时用于指针和指针指向的数据,表示指针和数据都不能被改变。
const INT *const ptr = #
*ptr = 20; // 错误:不能修改指向的值
ptr = &anotherNum; // 错误:不能改变指针的值 在这个例子中,ptr 既不能改变它指向的值,也不能改变它指向的地址。
2.7.5 增强代码安全性
使用 const 可以增加代码的安全性,因为它防止了意外的修改,特别是在复杂的程序中,多个函数可能会操作相同的数据。
2.7.5.1 函数参数
const 以用于函数参数,以保证函数不会修改传入的参数。
INT comp(const M_VEL_CTRL_DATA *pMVCD)
{
if(pMVCD->vel==0)
{
return 0;//Err
}
else
{
return 1;//Done
}
}在这个例子中,比较函数不能修改传入结构体指针指向的结构体数据的值。
2.7.5.2 函数返回值
const 也可以用于函数返回值,以保证返回的值不会被调用者修改。
const INT comp(const M_VEL_CTRL_DATA *pMVCD)
{
if(pMVCD->vel==0)
{
return 0;//Err
}
else
{
return 1;//Done
}
} 在这个例子中,返回的值是 const 的,调用者不能修改它。
2.7.6 总结
const 关键字是 C 语言中一个非常有用的工具,它不仅提高了代码的可读性,还增强了代码的安全性。通过明确地声明哪些变量是不可变的,const 帮助程序员避免错误,并确保程序的逻辑更加清晰和稳定。
3 基本语句
仅作简单介绍和案例举例。
3.1 if 语句
if 语句用于在满足特定条件时执行一段代码。下面的例子中判断体温是否超过37.2摄氏度,超过执行某些代码,反之执行另一些代码。
REAL body_temp = 38;
if (body_temp >= 37.2)
{
//发烧
}
else
{
//正常
}3.2 switch 语句
switch 语句允许你基于不同的情况执行不同的代码块,通常用于替代多个 if-else 语句。下面的例子是检查报警代码情况并执行对应对策。
INT ErrCode = 0;
//……
switch (ErrCode) {
case 0:
//正常
break;
case 1:
//报警信息1
break;
case 2:
//报警信息2
break;
case 3:
//报警信息3
break;
default:
//报警信息未定义
break;
}3.3 for 语句
for 语句用于在给定条件为真的情况下重复执行一段代码。此外还有冒泡排序,冒泡排序此处不再赘述,可以百度或者提问AI。
INT i=0,ErrCount=0;
for (i = 0; i < 5; i++)
{
if(D[0 +i]<=0)
{
ErrCount++;//检查D0到D4五个寄存器内的参数是否输入正确,统计输入错误的数量
}
}3.4 while 语句
while 语句也是用于重复执行代码,但它会一直执行,直到条件不再满足。实际上for是集成度更高的while,可读性更强。while是更自由地for,可以自由设定运行条件,以及判断逻辑。
// for 循环
for (int i = 0; i < 10; i++)
{
// 循环体
}
// while 循环
int i = 0;
while (i < 10) {
// 循环体
i++;
}
4 函数
在C语言中,函数是执行特定任务的自包含代码块,具有特定的功能。函数是C语言中实现代码复用和模块化的关键,它们使得程序更加结构化和易于管理。这部分指南会讲的比较细,以便后面的章节扩展。以下是C语言函数的一些基本概念:
4.1 定义和声明
4.1.1 函数定义
函数定义是函数的实际实现,它包括函数的声明和函数体。函数体包含了执行特定任务的代码。一个函数定义的基本格式如下:
返回类型 函数名称(参数类型 参数名1, 参数类型 参数名2, ...)
{
// 函数体
// 代码执行特定的任务
} 返回类型:指定函数返回值的数据类型。如果函数不返回任何值,则使用void作为返回类型。
函数名称:这是函数的标识符,用于在程序中调用函数。
参数列表:定义函数接受的参数,包括参数的类型和名称。参数列表可以为空,表示函数不接受任何参数。
函数体:大括号{}内包含的代码块,定义了函数的具体行为。
示例:
INT C_add(INT a, INT b)
{
return a + b; // 返回两个整数的和
} 在这个例子中,C_add是一个函数,它接受两个整数参数a和b,并返回它们的和。
4.1.2 函数声明
函数声明告诉编译器函数的名称、返回类型和参数类型,但不包括函数体。函数声明的主要目的是让编译器知道函数的存在和签名,这样在编译时可以检查函数调用的正确性。函数声明的基本格式如下:
返回类型 函数名称(参数类型 参数名1, 参数类型 参数名2, ...);返回类型:与函数定义中的返回类型相同。
函数名称:与函数定义中的名称相同。
参数列表:包括参数的类型和名称,用于告诉编译器函数接受哪些类型的参数。
示例:
INT C_add(INT a, INT b);// 函数声明,没有函数体 这个声明告诉编译器有一个名为C_add的函数,它接受两个INT类型的参数,并返回一个INT类型的值。
函数声明的作用
提前声明:在函数定义之前使用函数,让编译器知道函数的存在。
模块化:在大型项目中,函数可能在不同的文件中定义。通过声明,可以在不同的文件中引用这些函数。
参数检查:在编译时检查函数调用的参数是否与声明匹配。
4.1.3 函数原型
函数原型是C语言中的一种特殊声明,它只包含返回类型和参数类型,不包含参数名。函数原型的格式如下:
返回类型 函数名称(参数类型, 参数类型, ...);示例:
INT C_add(INT, INT);// 函数原型,没有参数名函数原型主要用于C语言的早期版本中,因为那时编译器不支持带参数名的声明。在现代C语言(C99及以后版本)中,函数原型和带参数名的声明可以互换使用,但原型更简洁,常用于头文件中。通过这些概念,可以在C语言程序中有效地使用函数,实现代码的复用和模块化。
4.2 返回类型
在C语言中,函数的返回类型定义了函数执行完毕后返回给调用者的值的数据类型。返回类型是函数声明和定义中非常重要的一部分,因为它告诉编译器和程序员函数将返回什么类型的数据。在实际开发中,我们常用的返回类型有两大类,一是基本数据类型返回值,这个建议用IEC标准数据类型,二是无返回值。
4.2.1 返回基本数据类型
有基本数据类型返回值的函数通常用来作为运算数据以及查询状态使用。下面各举一个例子:
INT C_max(INT a, INT b);//函数声明
void main()//主函数
{
#define SysRegAddr_D_HD
INT num=0;
num = C_max(4,6);//函数调用
D[0] = num;
}
INT C_max(INT a, INT b)//函数本体
{
if (a > b)
{
return a; // 返回两个整数中较大的一个
}
else
{
return b;
}
}
在这个例子中,c_max函数接受两个整数参数a和b,并返回它们中较大的一个。由于函数的返回类型是INT,所以return语句后面跟着的必须是整数值。主函数中调用函数并输入两个参数4和6,函数将返回6,所以num的值将为6,D0寄存器的值将为6。
4.2.2 void 返回类型
如果函数不需要返回任何值,那么它的返回类型应该是void。这意味着函数执行完毕后不会给调用者任何值。这种函数有一种场景特别常见,那就是初始化函数,有时我们会设计一个初始化函数,内部保存设备调好后,各参数寄存器的最优值,在生产新设备或者终端客户改错参数后,触发按钮调用初始化函数批量设置参数寄存器的参数值,这种情况一般不需要设计返回值,如果设计一个初始化完成信号也可以,但是需要判断各个寄存器是否设置成功,数据量很大的时候还是很麻烦的。
4.2.3 示例
void C_init()//初始化函数
{
#define SysRegAddr_D_HD
D[0] = 1;
D[1] = 2;
D[2] = 3;
D[3] = 4;
//……
}4.2.4 注意事项
- 确保函数的返回类型与
return语句后面的值的类型相匹配。 - 如果函数声明为返回
void,那么在函数体中不应该有return语句(除非return后面没有值)。 - 函数的返回类型对于编译器检查函数调用的正确性非常重要。
通过理解返回类型,可以更精确地控制函数的行为,确保函数能够正确地返回期望的数据。
4.3 参数列表
在C语言中,参数列表是函数定义和声明中的一个重要组成部分,它指定了函数可以接收哪些类型的参数。参数列表允许函数根据传入的值执行不同的操作,使得函数更加灵活和通用。
4.3.1 参数列表的定义
参数列表是函数定义或声明中括号()内的部分,它包含了一系列的参数声明。每个参数声明包括参数的类型和名称。参数列表定义了函数调用时必须提供的参数的数量和类型。
4.3.2 参数列表的格式
参数列表的格式如下:
(参数类型1 参数名1, 参数类型2 参数名2, ...) 参数类型:指定参数的数据类型,如INT、REAL、WORD等。
参数名:参数的标识符,用于在函数体内引用该参数。
4.3.3 参数列表的规则
参数数量:参数列表中可以有任意数量的参数,包括零个参数(即没有参数)。
参数顺序:在函数调用时,参数必须按照参数列表中声明的顺序传递。
参数类型:每个参数必须指定一个类型,且类型必须与传递给函数的实际参数类型匹配。
参数名:虽然参数名在函数调用时不是必须的,但在函数体内使用参数时,参数名用于区分不同的参数。
4.3.4 参数传递
C语言中有两种主要的参数传递方式:
值传递:这是C语言的默认参数传递方式。在这种方式下,函数接收的是参数值的副本,对参数的任何修改都不会影响到原始数据。
指针传递:通过传递指向参数的指针,函数可以直接修改原始数据。这种方式允许函数修改传递给它的参数。这个暂时先不讲,后面详细讲。
4.3.5 示例
下面是一个包含参数列表的函数定义示例:
INT C_add(INT a, INT b)
{
return a + b; // 返回两个整数的和
}在这个例子中,C_add函数的参数列表包含两个参数:a和b,它们都是INT类型。当调用C_add函数时,必须传递两个整数作为参数,如下所示:
INT result = C_add(5, 3); // 调用add函数,传递两个整数5和34.4 函数调用:
函数调用是C语言中一个核心的概念,它指的是在程序中请求一个已定义的函数执行其代码的过程。函数调用使得代码模块化,提高了代码的复用性和可读性。下面详细讲解函数调用的各个方面:
4.4.1 函数调用的基本格式
在C语言中,函数调用的基本格式如下:
函数名(实际参数1, 实际参数2, ...);函数名:被调用的函数的名称。
实际参数:传递给函数的具体值或变量,这些值或变量必须与函数定义时参数列表中指定的类型相匹配。
4.4.2 函数调用的过程
参数传递:在函数调用时,实际参数被传递给函数的形式参数。如果函数使用值传递,那么实际参数的值会被复制到函数的形式参数中。如果函数使用指针传递,那么实际参数的地址会被复制到函数的形式参数中。
函数执行:函数体中的代码被执行。这可能包括计算、条件判断、循环等操作。
返回值处理:如果函数有返回值,那么在函数执行完毕后,返回值会被传递回函数的调用者。如果函数的返回类型是void,则不返回任何值。
控制流返回:函数执行完毕后,程序的控制流返回到函数调用的位置,继续执行后续的代码。
4.4.3 函数调用的示例
假设我们有一个计算两个整数之和的函数C_add:
INT C_add(INT a, INT b)
{
return a + b; // 返回两个整数的和
}我们可以这样调用这个函数:
INT C_add(INT a, INT b);
void main()//主函数
{
INT sum=0;
sum = C_add(4,6);// 调用add函数,传递3和5作为参数
}
INT C_add(INT a, INT b)
{
return a + b; // 返回两个整数的和
} 在这个例子中,3和5是实际参数,它们被传递给C_add函数的形式参数a和b。函数计算这两个数的和,并返回结果,这个结果被存储在变量sum中。
4.4.4 函数调用的注意事项
- 参数匹配:调用函数时,实际参数的数量和类型必须与函数定义中的参数列表相匹配。
- 返回值:如果函数有返回值,那么调用者可以使用这个返回值,否则,如果函数返回
void,调用者不能期望有任何返回值。 - 作用域:函数的形式参数只在函数体内部有效,一旦函数执行完毕,这些参数的作用域就结束了。
- 递归调用:函数可以调用自身,这种调用称为递归。递归需要有一个明确的结束条件,否则会导致无限递归。本指南暂不讨论递归,感兴趣可以自行查找相关资料。
4.4.5 函数调用与程序流程
函数调用对程序流程有重要影响。函数调用可以改变程序的执行顺序,使得程序可以根据需要执行不同的代码块。这使得程序更加灵活,能够处理更复杂的逻辑。
通过理解和掌握函数调用,可以编写更加模块化和高效的C语言程序。函数调用是C语言中实现代码复用和程序控制流的基本工具。
4.5 作用域
函数作用域是指在程序中定义的变量和函数的可见性和生命周期。在C语言中,作用域主要分为两种:局部作用域和全局作用域。
4.5.1 局部作用域
局部作用域通常指的是函数内部。在局部作用域中定义的变量被称为局部变量,它们只在定义它们的函数内部可见,一旦函数执行结束,这些变量就会被销毁。
特点:
局部性:局部变量只在定义它们的函数内部可见,对其他函数来说是不可见的。
生命周期:局部变量的生命周期仅限于函数的执行期间。当函数调用结束时,局部变量的存储空间会被释放。
遮蔽:如果局部变量和全局变量同名,局部变量会遮蔽全局变量,即在该函数内部,同名的局部变量优先级更高。
示例:
INT globalVar = 10; // 全局变量
INT foo()
{
INT localVar = 20; // 局部变量
return localVar;
}
void main()
{
INT localVar = 30; // 另一个局部变量
INT t0 = 0;
t0 = foo(); // 调用foo函数,t0将等于20
} 在这个例子中,localVar在foo函数和main函数中都是局部变量,它们互不干扰,即使它们有相同的名字。
4.5.2 全局作用域
全局作用域指的是在所有函数之外定义的变量和函数,它们在整个程序中都是可见的。
特点
全局性:全局变量和函数在整个程序中都是可见的,可以在任何函数内部直接访问。
生命周期:全局变量的生命周期是整个程序的执行期间,从程序开始执行到结束。
初始化:全局变量需要被初始化,否则它们的值是未定义的。
示例:
INT globalVar = 10; // 全局变量
INT foo()
{
INT localVar = 20; // 局部变量
globalVar = 5; // 全局变量修改值为整数5
return localVar;
}
INT main()
{
INT localVar = 30; // 另一个局部变量
INT t0 = 0;
globalVar = 20; // 全局变量修改值为整数20
t0 = foo(); // 调用foo函数,其中全局变量修改值为整数5
} 在这个例子中,globalVar是一个全局变量,它可以在main函数和foo函数中被访问。在main函数第二行被赋值20,但是下一行调用foo函数立刻被赋值5,全局变量全局有效。
除了局部和全局还有块作用域的概念,本指南暂时省略,可以自行查找相关资料。
4.6 基本函数
通过前面C语言知识的了解,对于函数的因果缘由应该会有一个比较清晰的概念了,本节通过一个简单的基本函数案例-模拟量输入通道批量处理,重新梳理一下函数知识。
const REAL XJ_ADC(INT, INT, REAL);//函数声明
void FUNC0()
{
#define SysRegAddr_D_HD_ID
#define REAL_D *(REAL*)&D
for(INT i=0;i<4;i++)//4AD四路模拟量模块
{
REAL_D[0+i*2] = XJ_ADC(ID[10000+i],16384,100.0);//模块1,AD精度14bit,映射输出最大值100.0
REAL_D[8+i*2] = XJ_ADC(ID[10100+i],16384,100.0);//模块2,AD精度14bit,映射输出最大值100.0
}
}
const REAL XJ_ADC(INT CH_D,INT CH_MaxValue,REAL RT_MaxValue)//返回值禁止修改;参数:通道数据输入,通道最大值,输出最大值
{
if(CH_MaxValue<=0 || RT_MaxValue<=0)
{
return 0;//输入参数检查
}
else
{
return (REAL)CH_D/CH_maxValue*RT_MaxValue;//计算通道值到实际值
}
}INT与REAL是IEC标准数据类型,替代了C里的short和float。
const REAL XJ_ADC(INT, INT, REAL);//函数声明 这行代码声明了一个名为 XJ_ADC 的函数,它接受三个参数:一个 INT 类型的通道数据输入,一个 INT 类型的最大值,和一个 REAL 类型的最大值。const 关键字表示函数返回的 REAL 值是只读的,不能被修改。
void FUNC0()
{
#define SysRegAddr_D_HD_ID
#define REAL_D *(REAL*)&D FUNC0 函数定义开始。这里有两个宏定义:
SysRegAddr_D_HD_ID:这个宏是信捷标准C开头的宏定义,默认没有ID通道,手动添加_ID即可。
REAL_D:这个宏将 D 强制类型转换为 REAL 指针,然后解引用它,使得 REAL_D 可以像数组一样访问 D寄存器,宏定义那一节有提到。
for(INT i=0;i<4;i++)//4AD四路模拟量模块
{
REAL_D[0+i] = XJ_ADC(ID[10000+i],16384,100.0);//模块1,AD精度14bit,映射输出最大值100.0
REAL_D[4+i] = XJ_ADC(ID[10100+i],16384,100.0);//模块2,AD精度14bit,映射输出最大值100.0
}
} 这是一个循环,用于处理四个ADC通道。对于每个通道,它调用 XJ_ADC 函数,将通道数据、最大值和输出最大值作为参数。ID 是模拟量模块读取值的通道,存储了电压或电流数字量数据。REAL_D 将D寄存器转换为32bit浮点类型,存储转换后的模拟值。
const REAL XJ_ADC(INT CH_D,INT CH_MaxValue,REAL RT_MaxValue)//返回值禁止修改;参数:通道数据输入,通道最大值,输出最大值
{
if(CH_MaxValue<=0 || RT_MaxValue<=0)
{
return 0;//输入参数检查
}
else
{
return (REAL)CH_D/CH_MaxValue*RT_MaxValue;//计算通道值到实际值
}
} 这是 XJ_ADC 函数的定义。它接受三个参数,并进行错误检查:如果通道最大值或输出最大值不大于0,则返回0。否则,它计算并返回一个 REAL 值,这个值是将通道数据 CH_D 映射到实际值 RT_MaxValue 的结果。
设计思路
-
类型别名:使用
INT和REAL以提高代码的可读性和可维护性。 -
函数声明:提前声明
XJ_ADC函数,以便在FUNC0中使用。 -
宏定义:使用宏定义来标记和简化代码,例如
REAL_D宏允许将D作为REAL类型的数组来访问。 -
循环处理:在
FUNC0函数中,使用循环来处理多个ADC通道,提高代码的效率和可读性。 -
参数检查:在
XJ_ADC函数中,进行参数检查以确保输入的有效性。 -
值映射:
XJ_ADC函数将ADC通道值映射到实际的物理量,这是通过比例计算实现的。 -
错误处理:如果输入参数无效,
XJ_ADC函数返回0,这是一种简单的错误处理方式。
整体来看,这段代码的设计思路是将模拟信号转换为数字信号,并将其映射到实际的物理量,同时确保代码的可读性和运行稳定性。
4.7 复杂函数(使用指针参数的函数)
4.7.1 一般指针参数
在开发函数时,可能我们并不完全只是遵循接收输入数据、返回输出数据的流程,有时会需要对输入的数据有所改动,例如为了方便不想在调用函数后根据返回值修改输入值而是直接修改输入值。这时候我们就需要用指针参数来实现我们的目的。下面用一个自加函数做例子:
// 函数声明
void incAnyINT(INT *ptr, INT n);
void main()
{
INT value = 5; // 初始值
incAnyINT(&value, 10); // 传递value的地址,调用函数自加10
}
// 函数定义
void incAnyINT(INT *ptr, INT n)
{
if (ptr != NULL) // 检查指针是否为空
{
*ptr += n; // 通过指针修改变量的值
}
}这个例子中我们写了一个自加任意整数函数incAnyINT,也许你会觉得实现这样的功能似乎不需要写一个函数,因为这个例子是方便理解后面内容的。这个函数是一个无返回值的函数,有两个参数,第一个参数是存储INT型变量地址的指针,第二个变量是累加的值。函数内首先判断指针是否为空,这是为了安全的保护,如果指针为空则不进行任何处理。如果不为空则将指针内存储的地址解引用,该地址内存储的数据与参数n传入的数据相加并保存到该地址存储的数据内。
回到整体,第一行先声明函数,因为函数写在最下方,调用函数之前必须声明。主函数内声明了一个局部变量value并初始化为5,下一行调用我们写的自加函数,第一个参数位置用取地址符&取value的地址,第二个参数写了10。调用函数后局部变量value自加10,结果为15。
4.7.2 结构体指针参数
了解了一般指针函数后,下面进入重头戏,使用结构体指针参数的函数。我们绝大多数时候都在和这个打交道,理解了这个,对于项目开发中的大多数问题就都可以理解了。
首先我们回顾之前掌握的一些特性:
1、函数参数传递的是具体的值,是一种复制操作。
2、结构体数据在实际使用中往往规模/数据量很大。
3、值传递时参数为只读。
综上,在函数处理结构体时,数据庞大的结构体值的复制会影响性能,同时结构体中的数据各有作用,我们往往既需要写也需要读。所以在函数操作结构体参数时通常直接采用结构体指针作为参数,传递地址负载就很轻了,同时也能满足多样化的操作需要。下面举一个例子。
// 定义一个表示人的Person结构体
typedef struct {
char name[50]; // 人的名字
INT age; // 人的年龄
} Person;
// 函数声明
void updateAge(Person *ptr, INT newAge);
void main()
{
Person person = {"Fengzizhen", 25}; // 创建一个Person变量并初始化
updateAge(&person, 26); // 传递person的地址和新年龄
}
// 函数定义
void updateAge(Person *ptr, INT newAge) {
if (ptr != NULL) // 检查指针是否为空
{
ptr->age = newAge; // 通过指针修改结构体中的年龄
}
} 在这个案例中,我们先定义了一个两个元素的结构体,一个是长度为50字节的字符数组,可以存储长度为50字节以内的字符串,一个是年龄,共同组成了【人】这个结构体person。
下方是一个更新年龄的函数,因为相比姓名,人的年龄会更频繁变化。函数有两个参数,一个参数是Person类型结构体指针,一个是新的年龄。函数内部首先检查指针是否为空,做安全保护。然后使用【->】解引用结构体指针指向外部关联的结构体实际的age变量,赋值新年龄newAge。
主函数上方声明函数,主函数内使用Person结构体类型声明新的person结构体数据并初始化两个子数据分别为Fengzizhen和25。下一行调用年龄更新函数,person结构体的age子变量从25被更新为26。
到这里,我们基本将背景知识介绍完毕,下面的章节着重介绍在信捷PLC平台上的开发应用。
5 信捷POU与函数
在这一章节,我将推测一下信捷的库函数以及POU设计,可以更加深入理解信捷C运行的逻辑。
5.1 信捷库函数
库函数这部分不细说,只推断结构设计,使用方法在信捷基本指令篇手册有详细的说明,这里不再赘述。
5.1.1 文件结构
从文件结构上来说,差不多是传统的工程【C文件、头文件】结构。
5.1.2 数据类型重构
函数库对基本数据类型进行了重构,提高了可读性:
BOOL; //布尔量
INT8U; //8位无符号整数
INT8S; //8位有符号整数
INT16U //16位无符号整数
INT16S //16位有符号整数
INT32U //32位无符号整数
INT32S //32位有符号整数
FP32; //单精度浮点
FP64; //双精度浮点 这写重定义大概率是通过typedef关键字实现的:
typedef char BOOL; //布尔量
typedef unsigned char INT8U; //8位无符号整数
typedef char INT8S; //8位有符号整数
typedef unsigned short INT16U //16位无符号整数
typedef short INT16S //16位有符号整数
typedef unsigned int INT32U //32位无符号整数
typedef int INT32S //32位有符号整数
typedef float FP32; //单精度浮点
typedef double FP64; //双精度浮点
5.1.3 C文件设计
头文件没有什么特别的地方,编译器在建立新的头文件是预先写好了防重复引用的保护,用户直接在中间编写内容即可。
#ifndef _FUNC1_H
#define _FUNC1_H
//编写代码
#endif比较特别的是C文件,信捷在建立新的C文件(信捷C函数)的时候,做了一个图形化界面,这个界面可以配置该文件内主函数的函数名,参数数量、名称、参数类型、参数可关联的寄存器。配置完成后,在C文件内生成一个定义好的函数模板,在定义过程中可以预览。

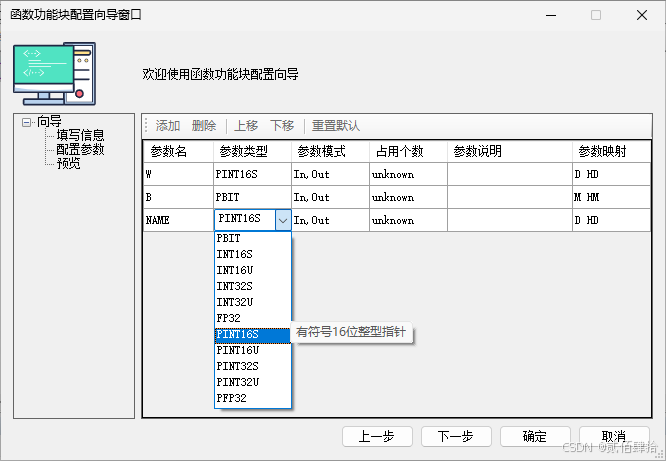
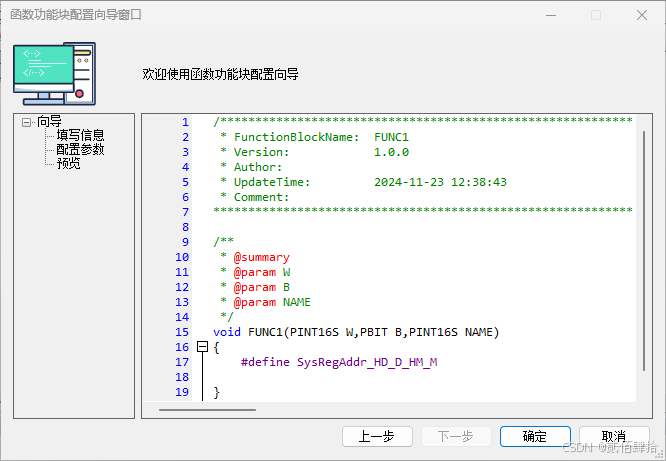
可以看到,信捷对这个的命名是FunctionBlock(函数块),但实际上经过测试,我感觉就是单独的C文件,这个C文件内有与C文件同名的函数FUNC1,主要的代码在这个函数内编辑,但实际上在这个函数之外,上面或者下面都可以写代码只不过不会被执行,除非被同名C函数调用。其原因是在梯形图中调用该函数块时只调用了同名的C函数,而不是这个函数块(C文件)内所有的代码。关于函数块即文件的猜测,可以用extern关键字佐证。信捷内部常见的一种开发方法是在某个函数块内写大量的函数,写在同名函数外,这样函数的作用域即全局。但是其他函数内无法直接调用这些函数,需要先声明外部函数,例如函数块A内这么写:
//FunctionBlock A
void FUNCA()
{
//
}
INT test()
{
return 6;
}函数块B(文件B)内无法直接调用函数块A(文件A)内的函数test,而需要先声明外部函数,即:
//FunctionBlock B
extern INT test();
void FUNCB()
{
INT a = test();
}这样函数块B(文件B)内就可以使用文件A内写的test函数了。
5.2 信捷POU
这部分是本指南的重心,在这里我将仔细拆解信捷POU的设计,帮助更好的理解与使用。
5.2.1 文件结构与全局变量分析
信捷POU的设计,本质上还是工程【C文件、头文件】结构。但是做了非常多的优化,首先一点就是去掉了POU库里的头文件,刚开始我也不太理解,后来我感觉是被优化掉了,可以说更便捷了,但是自由度因人而异。(补充,3.7.18版本可以调用功能库内的头文件,那么POU库的导出又是个问题了,手动黑人问号)
优化掉头文件后,多了全局变量表与全局用户数据类型表,全局变量表内可以自定义各种变量(变量名、变量类型、是否关联寄存器)。用户数据类型表内可以自定义结构体,结构体可以被全局变量使用。例如在用户数据类型表内定义一个结构体,然后在全局变量内定义一个全局结构体变量。如下:
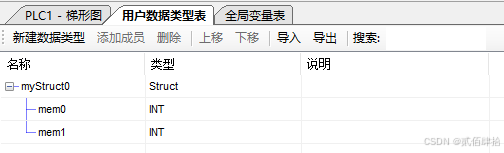

为什么我说信捷POU基于C,其实从信捷POU优化掉头文件,我就大概能猜到全局变量是如何实现的了,那就是用一个源文件内写好全局的结构体数据类型以及变量,并在头文件中外部链接,然后其他的C文件内在编译时默认引用这个头文件,代码如下:
//Global_File_H.h 全局变量H文件
#ifndef _GLOBAL_FILE_H_H
#define _GLOBAL_FILE_H_H
typedef struct{
INT mem0;
INT mem1;
}myStruct0;
extern myStruct0 varGlobal0;
#endif//Global_File_C.c 全局变量C文件
#include "Global_File_H.h" //引用全局变量头文件
//全局变量
myStruct0 varGlobal0={0,0};//func0.c 其他函数
#include "Global_File_H.h" //引用全局变量头文件
void func0()
{
varGlobal0.mem0 = 5;//使用全局变量
}上面这是在一般C中实现全局变量与全局数据类型的设计方法。
5.2.2 数据类型重构
和函数库一样,多半是基于基本类型重定义而来。
typedef char BOOL; //布尔量
typedef unsigned char USINT; //8位无符号整数
typedef char SINT; //8位有符号整数
typedef unsigned short UINT //16位无符号整数
typedef short INT //16位有符号整数
typedef unsigned int UDINT //32位无符号整数
typedef int DINT //32位有符号整数
typedef float REAL; //单精度浮点
typedef double LREAL; //双精度浮点
//........不一一列举5.2.3 C文件设计
在信捷POU中,C文件被分为了两大类,一是函数(FC),一是函数块(FB)。但其实本质上这两个是一回事,下面仔细分析。
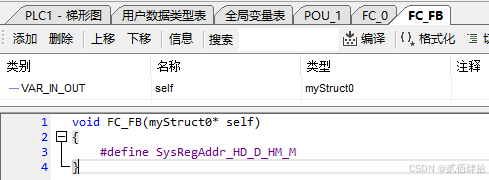
5.2.3.1 函数FC
首先从函数也就是FC开始说。FC建立后在上方的图形化配置表格内可以配置以下种类:INPUT、INOUT、OUTPUT。对应我们在C中定义的函数参数,INPUT是普通参数,只读,只能接收外部传入函数的数据,INOUT和OUTPUT是指针参数,可以直接访问外部参数位置关联的变量,实现了写的效果,OUTPUT、INOUT是可读可写,这个从代码区的FC函数参数区也可以看出来,OUTPUT类型VAR2与INOUT类型VAR3是指针参数。
FC_0配置与代码、梯形图调用如下
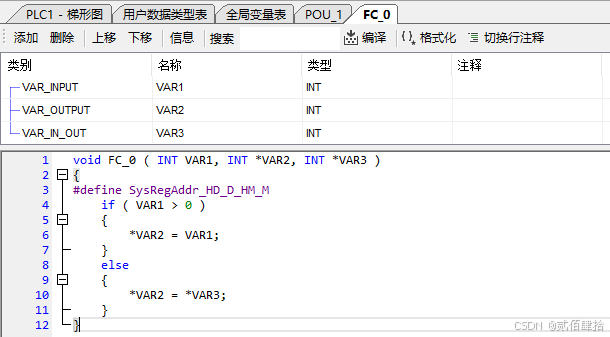
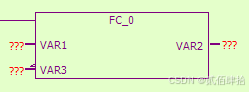
推测的C模拟如下:
//POU代码内部兼参数定义
void FC_0 ( INT VAR1, INT *VAR2, INT *VAR3 )
{
#define SysRegAddr_HD_D_HM_M
if ( VAR1 > 0 )
{
*VAR2 = VAR1;
}
else
{
*VAR2 = *VAR3;
}
}
//梯形图调用
FC_0(……,&……,&……);
5.2.3.1.1 函数FC的C内调用
根据参数类型传递变量或者地址。
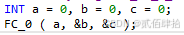
INT a = 0, b = 0, c = 0;
FC_0 ( a, &b, &c );5.2.3.2 函数块FB
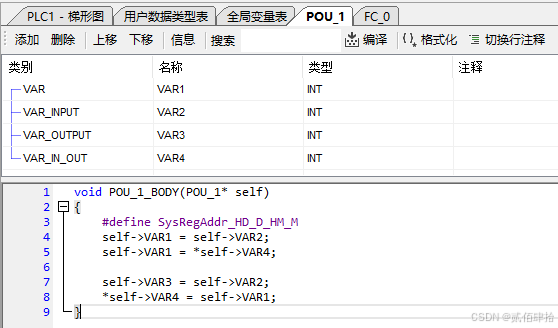
然后是函数块也就是FB,FB可以配置的数据有四种,INPUT、INOUT、OUTPUT、VAR。但是对于函数本身来说只有一种,那就是一个结构体指针,表现在代码上就是:
void POU_1_BODY(POU_1* self)
{
#define SysRegAddr_HD_D_HM_M
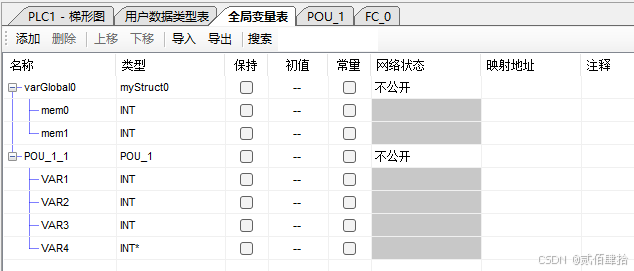
}新建了一个名为POU_1的FB,自动生成了一个名为POU_1_BODY的函数与名为POU_1的结构体类型,结构体成员可以在FB上方的表格中编辑。函数参数区定义了一个POU_1类型的结构体指针参数self,所以FB的函数只有这个一个参数,表格中的是POU_1结构体类型的成员。INPUT、VAR与OUTPUT成员是普通的数据,INPUT类型成员在梯形图图形界面可以接收其他变量的数据(输入引脚),OUTPUT类型成员在梯形图图形界面可以向其他变量写数据(输出引脚),INOUT成员是指针数据,在梯形图图形界面可以接收其他变量的地址(输入输出引脚)。在梯形图中调用后会在全局变量表中声明一个POU_1类型的结构体变量,习惯称之为FB实例。结构体变量中可以看到,只有INOUT类型的VAR4成员是INT指针。
POU_1代码与配置、代码情况如下:

从以上分析可以看出,FB本质就是以结构体指针为参数的函数,即使是FC,如果在参数区定义一个INOUT类型结构体变量,实际上和FB一模一样。

推测的C模拟同样功能如下:
//POU_1参数编辑表(全局有效
typedef struct{
INT VAR1;
INT VAR2;
INT VAR3;
INT* VAR4;
}POU_1;
//全局变量
POU_1 POU_1_1;
//POU_1梯形图调用
POU_1_1.VAR4 = &……;
POU_1_BODY(&POU_1_1);
POU_1_1.VAR1 = ……;
POU_1_1.VAR2 = ……;
…… = POU_1_1.VAR3;
//POU_1内部代码
void POU_1_BODY(POU_1* self)
{
#define SysRegAddr_HD_D_HM_M
self->VAR1 = self->VAR2;
self->VAR1 = *self->VAR4;
self->VAR3 = self->VAR2;
*self->VAR4 = self->VAR1;
}5.2.3.2.1 函数FB的C调用
关联对应的结构体变量地址,并按规则给对应结构体成员赋值。
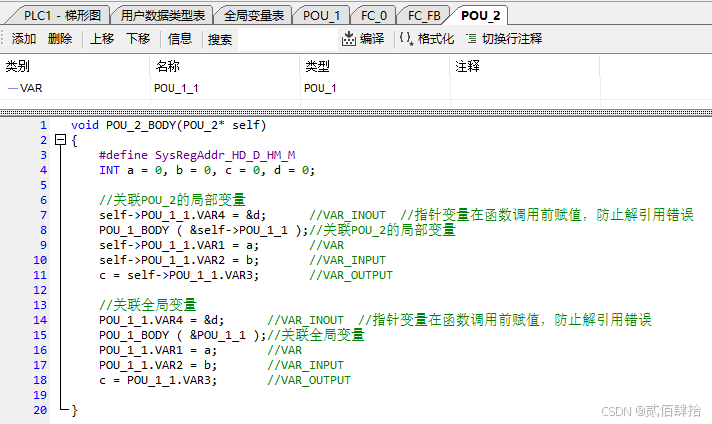
模拟纯C实现如下
//POU_1参数编辑表(全局有效
typedef struct{
INT VAR1;
INT VAR2;
INT VAR3;
INT* VAR4;
}POU_1;
//全局变量
POU_1 POU_1_1;
POU_2 POU_2_1;
//POU_1内部代码
void POU_1_BODY(POU_1* self)
{
#define SysRegAddr_HD_D_HM_M
self->VAR1 = self->VAR2;
self->VAR1 = *self->VAR4;
self->VAR3 = self->VAR2;
*self->VAR4 = self->VAR1;
}
//POU_2参数编辑表(全局有效
typedef struct{
POU_1 POU_1_1;
}POU_2;
//POU_2梯形图调用
POU_2_1.POU_1_1= &POU_1_1;
POU_2_BODY(&POU_2_1);
//POU_2内部代码
void POU_2_BODY(POU_2* self)
{
#define SysRegAddr_HD_D_HM_M
INT a = 0, b = 0, c = 0, d = 0;
//关联POU_2的局部变量
self->POU_1_1.VAR4 = &d; //VAR_INOUT //指针变量在函数调用前赋值,防止解引用错误
POU_1_BODY ( &self->POU_1_1 );//关联POU_2的局部变量
self->POU_1_1.VAR1 = a; //VAR
self->POU_1_1.VAR2 = b; //VAR_INPUT
c = self->POU_1_1.VAR3; //VAR_OUTPUT
//关联全局变量
POU_1_1.VAR4 = &d; //VAR_INOUT //指针变量在函数调用前赋值,防止解引用错误
POU_1_BODY ( &POU_1_1 );//关联全局变量
POU_1_1.VAR1 = a; //VAR
POU_1_1.VAR2 = b; //VAR_INPUT
c = POU_1_1.VAR3; //VAR_OUTPUT
}5.2.4 总结
看到这里,相信已经对POU了然了,在使用中或者将来的ST语言POU都能轻松理解了。根据内测版本软件来看,ST版本在底层处理大概率和C别无二致,只是语言表达方式的区别,例如C赋值用=,ST用:=这样子。等正式版本发布后,我会在附录中做一个C与ST的关键字、语法等的简单对照,帮助更快上手。
6 EtherCAT运动控制开发中的应用
POU在实际应用中,最常见的场景应该说主要是多轴运控,我们以一条线数十个轴为例,这数十个轴极大概率在特定功能上是相同的,例如使能、手动调试等功能。亦或者在控制工艺上一致,例如几个一组,执行相似的动作。这种情况下POU就很方便用来封装特定工艺,重复部署。同样的代码复制几十遍,那样太麻烦了。同时在轴控中经常会遇到相当多的计算,使用梯形图时计算是很烦人的,所以在以往大型项目实践中,博图、GXWork、Codesys等支持ST语言的平台都具有相当大的优势。而现在支持C的POU给了我们新的选择,灵活性完全不亚于友商。
下面我将围绕轴控POU的设计与特性优化方面分享一下我在EtherCAT运控开发方面的一些经验。
6.1 轴对象结构体
在IEC标准基础上,信捷将每个EtherCAT轴设计为了结构体对象,比如西门子、Codesys也是这样的设计。在轴配置界面中输入轴数后,自动建立对应数量的结构体对象,按BMC_Axis000、BMC_Axis001、BMC_Axis002这样的命名规则依次排列。在全局变量的_SYS_AXIS表格中可以看到这个结构体对象:
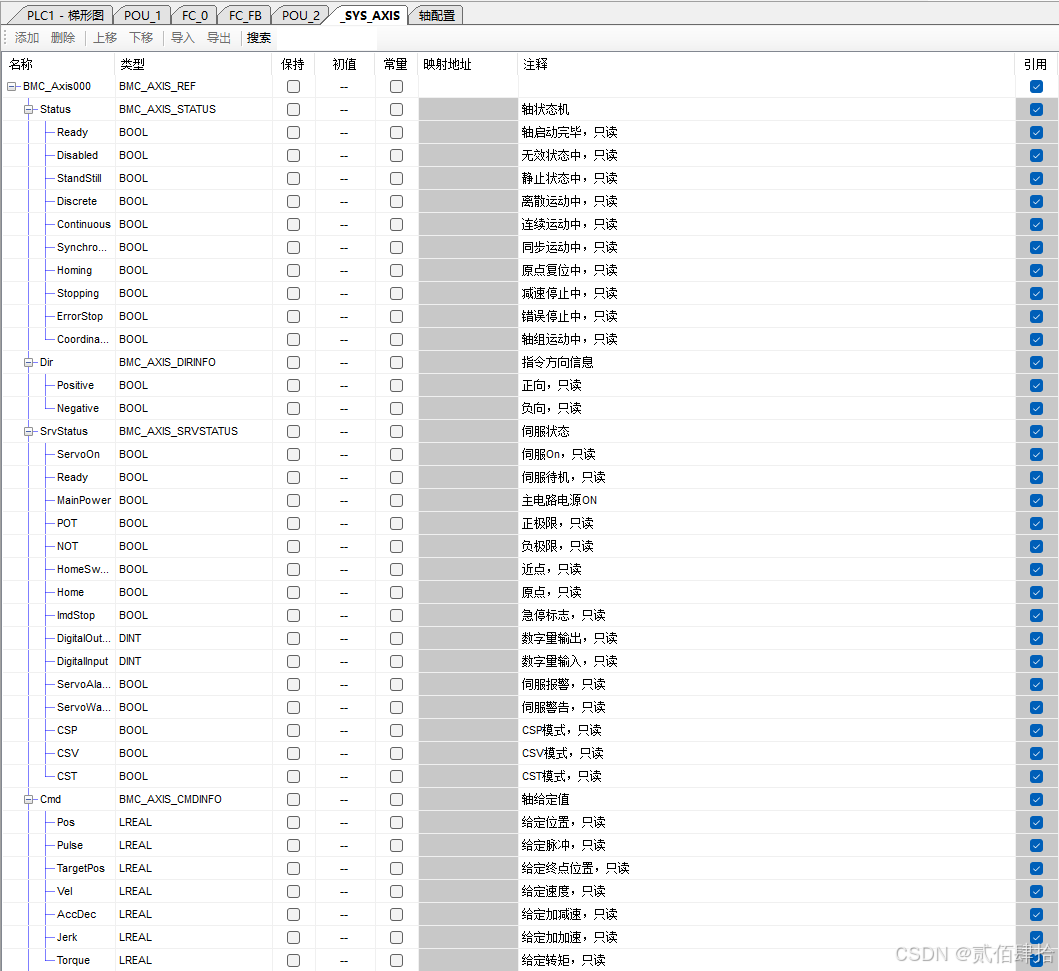
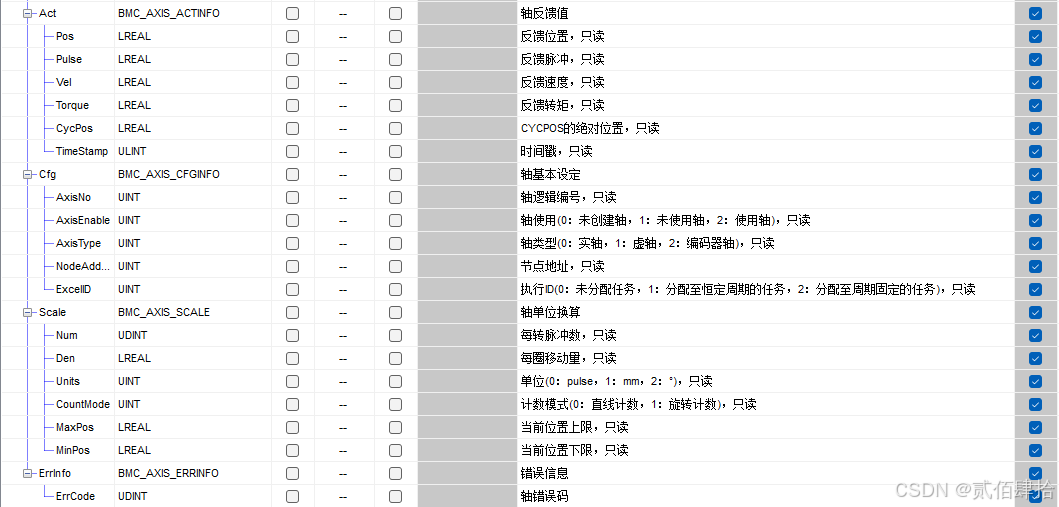
可以看到轴控结构体下面还嵌套了很多结构体,实现关于轴的各种各样功能,后面的引用复选框可以决定轴控结构体是否全局可见,使用时必须勾选,否则程序内部会报错。轴控POU引用轴控对象时,大概就是通过操作结构体对象内部的参数来实现运动控制。需要注意的一点是,在监控结构体对象内的参数例如实时位置时,必须开启I9900EtherCAT通讯中断,否则数据不刷新,该中断默认开启,如果未开启,请置位SM1995线圈。
6.2 轴控FB的C内调用
本节以调用BMC_A_Power使能指令块为例,讲解调用方法:
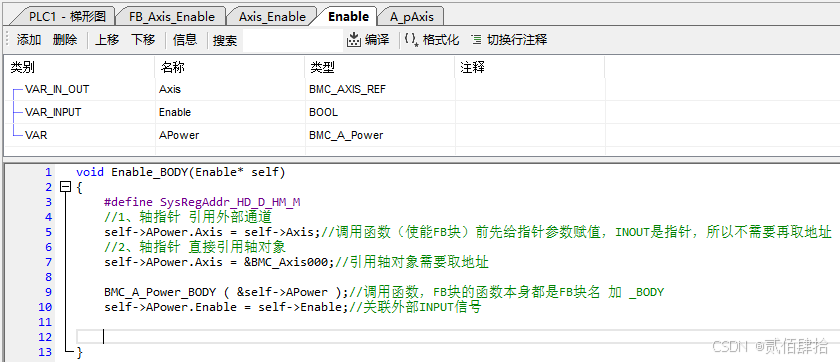
注意事项:任何FB块,包括自己建立的和系统的,在C中的函数名都是FB块名加 _BODY,比如使能指令块的名字是BMC_A_Power,这意味着有一个全局结构体的名字是BMC_A_Power,函数本身的名字是BMC_A_Power_BODY,这个看我们自己建立的也可以看出来,例如这个就是Enable_BODY。调用带指针参数的函数块,一定要在调用之前给指针参数赋值,否则未知指针可能会导致系统死机。封装时轴对象引用最好使用外部输入进来的,这样才能达到在外部重复调用的效果。
轴控工艺封装一般步骤:1、建立轴对象引用通道,上方INOUT类别BMC_AXIS_REF类型Axis对象。2、建立轴控FB块实例,也就是对应FB块结构体数据,上方VAR类别BMC_A_Power类型APower对象,必须为普通数据。3、建立其他输入输出通道,如上方INPUT类别BOOL类型Enable对象。
下面照例展示纯C模拟代码(虽然说是模拟,但是经过测试,是可以在功能库直接跑的。但是有个限制,功能库函数内定义的变量按手册说不能超过100WORD,所以最好搭配全局变量。不搭配全局变量也有办法,那就是把定义的数据直接关联硬件地址,不过这个属于高级用法了,以后再做补充):
//FB内参数定义区
typedef struct{
BMC_AXIS_REF* Axis;
BOOL Enable;
BMC_A_Power APower;
}Enable;
//全局变量
Enable Enable_1;
//外部调用
Enable_BODY(&Enable_1);
void Enable_BODY(Enable* self)
{
#define SysRegAddr_HD_D_HM_M
//1、轴指针 引用外部通道
self->APower.Axis = self->Axis;//调用函数(使能FB块)前先给指针参数赋值,INOUT是指针,所以不需要再取地址
//2、轴指针 直接引用轴对象
self->APower.Axis = &BMC_Axis000;//引用轴对象需要取地址
BMC_A_Power_BODY ( &self->APower );//调用函数,FB块的函数本身都是FB块名 加 _BODY
self->APower.Enable = self->Enable;//关联外部INPUT信号
}以上就是轴控FB在C内调用的一般方法。但是这个例子还不完美,如果我们想要批量使能,使能块实例APower可以做成数组形式APower[64],但是轴对象如何处理呢?系统里都是单个独立的。不过没关系,已经解决了,下节细说。
6.3 轴对象指针数组
针对这个情况,我们直接自己开发一个函数,函数返回值是轴指针,函数拥有一个参数,轴号,也即索引。这样在引用轴时,直接在POU上方extern外部声明一下函数,使用时直接写函数即可。代码如下:
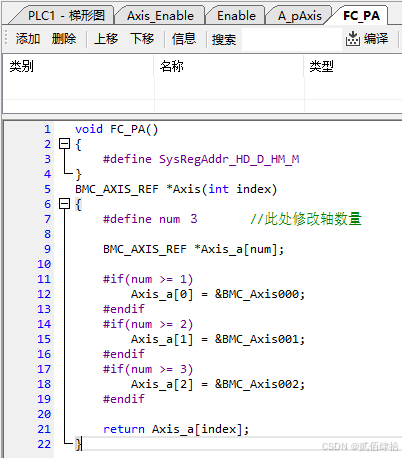
函数返回值是BMC_AXIS_REF轴类型指针,参数是索引index,下方是条件定义,实际有几个轴就在num定义处改为实际轴数即可。接着是定义了一个BMC_AXIS_REF轴类型指针数组,数组长度是实际轴数。再下方是条件定义,超出实际轴数量以外的代码不编译,例如轴数修改为2,那么BMC_Axis002这行就不编译了,实际也没有,这样不需要频繁删改,也避免了报错。最后是根据索引,返回对应指针,后续可以优化以下,做索引溢出的保护。完整的32轴代码附于附录,需要可以取用,也可以看之前的文章。
有了轴指针函数这个工具,我们就可以开发多轴批量使能的封装了。
6.4 多轴批量使能封装
多轴批量使能块按照前面的封装步骤,建立使能信号输入通道,使能轴数输入通道,使能完成标志输出通道;建立指令块实例数组,声明外部函数。代码如下:

首先使用for循坏批量调用使能函数块,然后给予轴指针与启动命令。然后统计所有的使能函数块实例内有多少使能成功标志,如果标志数量符合启动的轴数,那么就是全部使能成功。C模拟代码对照如下:
//FB内参数定义区
typedef struct{
BOOL Start;
INT Num_Of_Axis;
BMC_A_Power APower[32];
BOOL StartDone;
}Axis_Enable;
//全局变量
Axis_Enable Axis_Enable_1;
//外部调用
Axis_Enable_BODY(&Axis_Enable_1);
//函数代码区
extern BMC_AXIS_REF *Axis ( int index );//声明外部函数
void Axis_Enable_BODY ( Axis_Enable *self )
{
#define SysRegAddr_HD_D_HM_M
int i, j, k, cunt0;
for ( i = 0; i < self->Num_Of_Axis; i++ )
{
self->APwoer[i].Axis = Axis ( i );
BMC_A_Power_BODY ( &self->APwoer[i] );
self->APwoer[i].Enable = self->Start;
}
cunt0 = 0;
for ( j = 0; j < self->Num_Of_Axis; j++ ) //检查有多少轴使能成功,
{
if ( self->APwoer[j].PwrStat == 1 )
{
cunt0 = cunt0 + 1;
}
}
if ( cunt0 == self->Num_Of_Axis )//计数与轴数相等即为全部使能成功
{
self->StartDone = 1;
}
else
{
self->StartDone = 0;
}
}
7 致谢
本指南写到这里基本结束,后期逐步进行内容补充以及错误修改。在此感谢工作中帮助过我的亲人、老师、同事、行业内的朋友们,祝身体健康,工作顺利。
以下排名按时间顺序:
LorryLiu;
谭军燕,于鹏,张永波,程麒文,隋明森;
罗煌盛,张英豪,李威威,王成钦;
信捷技术支持团队;
郁永燕、程文、孙克宇,朱军,王晓伟,顾明将,王维杰,刘同鹏,刘明杰,王法凯,张铭,周俊杰,赵延昊,赵文杰,丁伟,王栋,任晓鹏。
8 附录
8.1 信捷产品ST语言开发对照
8.1.1 基本数据类型
8.1.2 复杂数据类型
8.1.3 基本语法
8.2 中断高速计数案例(库函数)
下面展示一个利用外部中断点实现二倍频、四倍频高速计数的案例,采用库函数开发。主函数文件内定义全局变量:计数器当前值、模式(二/四倍频)、A相ON状态,A相OFF状态,B相ON状态,B相OFF状态。在头文件中编写外部调用代码,在各函数中引用。代码如下:
主函数:
//MAIN.c
#include "Global_File_H.h" //引用全局变量头文件
DINT HCount=0;
BOOL Mode = 0;
BOOL A_R=0;
BOOL A_F=0;
BOOL B_R=0;
BOOL B_F=0;
void MAIN()
{
#define SysRegAddr_HD_D_HM_M
#define DINT_D *(DINT*)&D
Mode = 1;
DINT_D[0] = HCount;
}
头文件:
//Global_File_H.h
#ifndef _GLOBAL_FILE_H_H
#define _GLOBAL_FILE_H_H
extern DINT HCount;
extern BOOL Mode;
extern BOOL A_R;
extern BOOL A_F;
extern BOOL B_R;
extern BOOL B_F;
#endifA相上升沿中断函数:
//HC_AR.c
#include "Global_File_H.h"
void HC_AR()
{
#define SysRegAddr_HD_D_HM_M
A_R = 1;
A_F = 0;
if(!Mode)
{
if ( A_R && !B_R )
{
HCount++;
}
}
else
{
if ( A_R && !B_R )
{
HCount++;
}
if ( A_R && B_R )
{
HCount--;
}
}
}
A相下降沿中断函数:
//HC_AF.c
#include "Global_File_H.h"
void HC_AF()
{
#define SysRegAddr_HD_D_HM_M
A_R = 0;
A_F = 1;
if(!Mode)
{
if ( A_F && B_R )
{
HCount++;
}
}
else
{
if ( A_F && B_R )
{
HCount++;
}
if ( A_F && B_F )
{
HCount--;
}
}
}B相上升沿中断函数:
//HC_BR.c
#include "Global_File_H.h"
void HC_BR()
{
#define SysRegAddr_HD_D_HM_M
B_R = 1;
B_F = 0;
if(!Mode)
{
if ( !A_R && B_R )
{
HCount--;
}
}
else
{
if ( A_R && B_R )
{
HCount++;
}
if ( A_F && B_R )
{
HCount--;
}
}
}
B相下降沿中断函数:
//HC_BF.c
#include "Global_File_H.h"
void HC_BF()
{
#define SysRegAddr_HD_D_HM_M
B_R = 0;
B_F = 1;
if(!Mode)
{
if ( A_R && B_F )
{
HCount--;
}
}
else
{
if ( A_F && B_F )
{
HCount++;
}
if ( A_R && B_F )
{
HCount--;
}
}
}
8.3 中断高速计数案例(POU)
POU版本采用内建全局变量,非表格,早期表格测试时有实时性问题。基本原理是在主函数定义五个外部链接的全局变量:计数器当前值、A相ON状态,A相OFF状态,B相ON状态,B相OFF状态。然后再梯形图中建立四个中断程序,A相上升沿中断,A相下降沿中断,B相上升沿中断,B相下降沿中断。分别引用四个函数。函数内访问对应外部全局变量,实时进行处理,实测可以正常运行。代码如下:
主函数:
//FC
//EIH_Main.c
DINT HCount=0;//计数器当前值
BOOL Mode = 0;//0:二倍频;1:四倍频
BOOL A_R=0;//A相ON状态,
BOOL A_F=0;//A相OFF状态,
BOOL B_R=0;//B相ON状态,
BOOL B_F=0;//B相OFF状态
void EIH_Main()
{
#define SysRegAddr_HD_D_HM_M
#define DINT_D *(DINT*)&D
Mode = 1;
DINT_D[0] = HCount;
}A相上升沿中断函数:
//FC
//EIH_AR.c
extern DINT HCount;
extern BOOL Mode;
extern BOOL A_R;
extern BOOL A_F;
extern BOOL B_R;
extern BOOL B_F;
void EIH_AR()
{
#define SysRegAddr_HD_D_HM_M
A_R = 1;
A_F = 0;
if(!Mode)//二倍频
{
if ( A_R && !B_R )
{
HCount++;
}
}
else//四倍频
{
if ( A_R && !B_R )
{
HCount++;
}
if ( A_R && B_R )
{
HCount--;
}
}
}A相下降沿中断函数
//FC
//EIH_AF.c
extern DINT HCount;
extern BOOL Mode;
extern BOOL A_R;
extern BOOL A_F;
extern BOOL B_R;
extern BOOL B_F;
void EIH_AF()
{
#define SysRegAddr_HD_D_HM_M
A_R = 0;
A_F = 1;
if(!Mode)//二倍频
{
if ( A_F && B_R )
{
HCount++;
}
}
else//四倍频
{
if ( A_F && B_R )
{
HCount++;
}
if ( A_F && B_F )
{
HCount--;
}
}
}B相上升沿中断函数
//FC
//EIH_BR.c
extern DINT HCount;
extern BOOL Mode;
extern BOOL A_R;
extern BOOL A_F;
extern BOOL B_R;
extern BOOL B_F;
void EIH_BR()
{
#define SysRegAddr_HD_D_HM_M
B_R = 1;
B_F = 0;
if(!Mode)//二倍频
{
if ( !A_R && B_R )
{
HCount--;
}
}
else//四倍频
{
if ( A_R && B_R )
{
HCount++;
}
if ( A_F && B_R )
{
HCount--;
}
}
}B相下降沿中断函数
//FC
//EIH_BF.c
extern DINT HCount;
extern BOOL Mode;
extern BOOL A_R;
extern BOOL A_F;
extern BOOL B_R;
extern BOOL B_F;
void EIH_BF()
{
#define SysRegAddr_HD_D_HM_M
B_R = 0;
B_F = 1;
if(!Mode)//二倍频
{
if ( A_R && B_F )
{
HCount--;
}
}
else//四倍频
{
if ( A_F && B_F )
{
HCount++;
}
if ( A_R && B_F )
{
HCount--;
}
}
}
8.4 轴指针数组案例
原理是一个FC(C文件)里可以写很多函数,所以只需要在一个文件里写一个返回值为轴结构体指针、索引为参数的函数就可以了。其他POU也就是.c文件在函数调用位置前使用extern声明一下即可。轴指针索引函数内利用条件预处理指令,现在不需要手动注释未定义/未使用的轴,只需要在宏定义处更改轴数即可,但是超出未定义的轴范围时仍然会报错。
下面是函数代码:
//FC文件:A_pAxis.c
void A_pAxis()//无用,仅作新建.c文件存储函数用
{
#define SysRegAddr_HD_D_HM_M
}
BMC_AXIS_REF *Axis(INT index)//轴指针函数
{
#define num 4 //此处修改轴数量
BMC_AXIS_REF *Axis_a[num];
#if(num >= 1)
Axis_a[0] = &BMC_Axis000;
#endif
#if(num >= 2)
Axis_a[1] = &BMC_Axis001;
#endif
#if(num >= 3)
Axis_a[2] = &BMC_Axis002;
#endif
#if(num >= 4)
Axis_a[3] = &BMC_Axis003;
#endif
#if(num >= 5)
Axis_a[4] = &BMC_Axis004;
#endif
#if(num >= 6)
Axis_a[5] = &BMC_Axis005;
#endif
#if(num >= 7)
Axis_a[6] = &BMC_Axis006;
#endif
#if(num >= 8)
Axis_a[7] = &BMC_Axis007;
#endif
#if(num >= 9)
Axis_a[8] = &BMC_Axis008;
#endif
#if(num >= 10)
Axis_a[9] = &BMC_Axis009;
#endif
#if(num >= 11)
Axis_a[10] = &BMC_Axis010;
#endif
#if(num >= 12)
Axis_a[11] = &BMC_Axis011;
#endif
#if(num >= 13)
Axis_a[12] = &BMC_Axis012;
#endif
#if(num >= 14)
Axis_a[13] = &BMC_Axis013;
#endif
#if(num >= 15)
Axis_a[14] = &BMC_Axis014;
#endif
#if(num >= 16)
Axis_a[15] = &BMC_Axis015;
#endif
#if(num >= 17)
Axis_a[16] = &BMC_Axis016;
#endif
#if(num >= 18)
Axis_a[17] = &BMC_Axis017;
#endif
#if(num >= 19)
Axis_a[18] = &BMC_Axis018;
#endif
#if(num >= 20)
Axis_a[19] = &BMC_Axis019;
#endif
#if(num >= 21)
Axis_a[20] = &BMC_Axis020;
#endif
#if(num >= 22)
Axis_a[21] = &BMC_Axis021;
#endif
#if(num >= 23)
Axis_a[22] = &BMC_Axis022;
#endif
#if(num >= 24)
Axis_a[23] = &BMC_Axis023;
#endif
#if(num >= 25)
Axis_a[24] = &BMC_Axis024;
#endif
#if(num >= 26)
Axis_a[25] = &BMC_Axis025;
#endif
#if(num >= 27)
Axis_a[26] = &BMC_Axis026;
#endif
#if(num >= 28)
Axis_a[27] = &BMC_Axis027;
#endif
#if(num >= 29)
Axis_a[28] = &BMC_Axis028;
#endif
#if(num >= 30)
Axis_a[29] = &BMC_Axis029;
#endif
#if(num >= 31)
Axis_a[30] = &BMC_Axis030;
#endif
#if(num >= 32)
Axis_a[31] = &BMC_Axis031;
#endif
#if(num >= 33)
Axis_a[32] = &BMC_Axis032;
#endif
#if(num >= 34)
Axis_a[33] = &BMC_Axis033;
#endif
#if(num >= 35)
Axis_a[34] = &BMC_Axis034;
#endif
#if(num >= 36)
Axis_a[35] = &BMC_Axis035;
#endif
#if(num >= 37)
Axis_a[36] = &BMC_Axis036;
#endif
#if(num >= 38)
Axis_a[37] = &BMC_Axis037;
#endif
#if(num >= 39)
Axis_a[38] = &BMC_Axis038;
#endif
#if(num >= 40)
Axis_a[39] = &BMC_Axis039;
#endif
#if(num >= 41)
Axis_a[40] = &BMC_Axis040;
#endif
#if(num >= 42)
Axis_a[41] = &BMC_Axis041;
#endif
#if(num >= 43)
Axis_a[42] = &BMC_Axis042;
#endif
#if(num >= 44)
Axis_a[43] = &BMC_Axis043;
#endif
#if(num >= 45)
Axis_a[44] = &BMC_Axis044;
#endif
#if(num >= 46)
Axis_a[45] = &BMC_Axis045;
#endif
#if(num >= 47)
Axis_a[46] = &BMC_Axis046;
#endif
#if(num >= 48)
Axis_a[47] = &BMC_Axis047;
#endif
#if(num >= 49)
Axis_a[48] = &BMC_Axis048;
#endif
#if(num >= 50)
Axis_a[49] = &BMC_Axis049;
#endif
#if(num >= 51)
Axis_a[50] = &BMC_Axis050;
#endif
#if(num >= 52)
Axis_a[51] = &BMC_Axis051;
#endif
#if(num >= 53)
Axis_a[52] = &BMC_Axis052;
#endif
#if(num >= 54)
Axis_a[53] = &BMC_Axis053;
#endif
#if(num >= 55)
Axis_a[54] = &BMC_Axis054;
#endif
#if(num >= 56)
Axis_a[55] = &BMC_Axis055;
#endif
#if(num >= 57)
Axis_a[56] = &BMC_Axis056;
#endif
#if(num >= 58)
Axis_a[57] = &BMC_Axis057;
#endif
#if(num >= 59)
Axis_a[58] = &BMC_Axis058;
#endif
#if(num >= 60)
Axis_a[59] = &BMC_Axis059;
#endif
#if(num >= 61)
Axis_a[60] = &BMC_Axis060;
#endif
#if(num >= 62)
Axis_a[61] = &BMC_Axis061;
#endif
#if(num >= 63)
Axis_a[62] = &BMC_Axis062;
#endif
#if(num >= 64)
Axis_a[63] = &BMC_Axis063;
#endif
return Axis_a[index];
}下面是其他POU调用函数示例:
extern BMC_AXIS_REF *Axis ( INT );//其他.c文件中调用外部函数前声明函数
//FB结构体定义区
typedef FB_Axis_Absolute{
INT Num_Of_Axis;
BMC_A_MoveA AMoveA[64];
ManCtrlStruct ManCtrl[64];
ManParaStruct ManPara[64];
}
//批量绝对运动FB
void FB_Axis_Absolute_BODY(FB_Axis_Absolute* self)
{
#define SysRegAddr_HD_D_HM_M
INT i;
for(i=0;i<self->Num_Of_Axis;i++)
{
self->AMoveA[i].Axis = Axis(i);//调用函数,参数为for索引i
BMC_A_MoveA_BODY ( &self->AMoveA[i] );
self->AMoveA[i].Execute = self->ManCtrl[i].MoveAbsolute;
self->AMoveA[i].Pos = self->ManPara[i].AbsolutePosition;
self->AMoveA[i].Vel = self->ManPara[i].Velocity;
self->AMoveA[i].Acc = self->ManPara[i].Acceleration;
self->AMoveA[i].Deceleration = self->ManPara[i].Deceleration;
self->AMoveA[i].Jerk = self->ManPara[i].Jrek;
}
}
8.5 X、Y、M等位变量的C地址
#define M_REG M[0]//无效
#define M_REG 0//有效
M[M_REG]=TRUE;
前文中我们简单分析了位变量的C内地址宏定义实现,但是没有展开讲,只是像上面说了下使用规则。在这里我尝试仔细分析一下看看。首先我们看报错,写一个测试函数
void test()
{
#define SysRegAddr_HD_D_HM_M
#define M_TEST M[0]
M_TEST = 0;
}然后编译查看错误:
1. test.c: In function 'test':
test.c:2:28: warning: passing argument 1 of 'MBSReadBit' makes pointer from integer without a cast [-Wint-conversion]
test.c:3:5: note: in expansion of macro 'M_TEST'
#include "motion_control_type.h"
^
In file included from ..\inc/funcbnew.h:19:0,
from test.c:5:
..\inc/bit.h:12:13: note: expected 'BIT * {aka struct <anonymous> *}' but argument is of type 'INT32U {aka unsigned int}'
static BOOL MBSReadBit( BIT* BitAdd )
^
test.c:3:12: error: lvalue required as left operand of assignment
#include "motion_control_type.h"
^第一行错误,提示错误在test函数中。
第二行错误,函数 MBSReadBit 在test函数第二行被调用时,传递的第一个参数是从整数类型转换为指针类型而没有进行显式类型转换。这说明M[0]这个寄存器引用,其实是函数MBSReadBit ,这个函数需要一个指针参数,但是我们给的是一个整数参数【0】,于是发生了隐式类型转换,整数0被转换为指针。
第三行错误,提示错误由于test函数第三行宏展开导致的。
第四至七行错误,显示test默认调用了一个头文件motion_control_type.h,这可能是定义了MBSReadBit 函数或者BIT类型数据的地方。
第八至十行错误,指出 MBSReadBit 函数期望的参数类型是 BIT*(即指向 BIT 结构的指针),但实际上传递的是 INT32U 类型(即 unsigned int)。然后为我们展示了函数全貌【static BOOL MBSReadBit( BIT* BitAdd)】,局部函数,返回值为BOOL,参数是BIT指针存储BIT地址,函数作用是读该参数地址内的值返回为BOOL。M[0]宏定义的封装可能是这个函数,宏定义参数在内部被计算为指针指向的地址。
后面的错误:指出在 test.c 文件的第3行,有一个赋值操作,但是左边的操作数不是一个可以被赋值的变量。
分析到这里其实没有什么头绪,只是知道不能这么用,底层代码还是看不到,于是我去XC软件试了一下,发现XC也有相似的函数报错:
1. [Error(ccom):../../../tmp/PrjFuncB/FUNC1.c,line 13] unknown variable M
===> MBSWriteBit( M + 0 , 1 );
[Warning(ccom):../../../tmp/PrjFuncB/FUNC1.c,line 13] too few parameters
===> MBSWriteBit( M + 0 , 1 );
[Error(ccom):../../../tmp/PrjFuncB/FUNC1.c,line 14] Sorry compilation terminated because of these errors in FUNC1().
===> }
..\..\..\tmp\PrjFuncB\FUNC1.c但是还是没有什么头绪,后来我找了一位前辈,得到了一点有关底层的代码,可以实现我们想要的地址别名宏定义效果。
注意:以下内容仅适用于当前XD、XL系列PLC,不保证任何时间任何产品都好用,也无法保证安全性。仅作为技术学习与讨论分享。
底层有一个内部变量【__M】(双下划线),类型为char。使用时extern char __M;外部引用以下,这个地址等同于D、HD这些寄存器数组变量。然后写指针定义,#define M_ ((ARM_BIT*)(&__M)),这个宏将M_强制定义为指向数组M__第一个元素的ARM_BIT类型指针(在C语言中,数组名本身就是一个指向数组第一个元素的指针。),所以这里M_是指针,地址为M__数组第一个元素的地址。访问M0地址就写M_[0]即可。我们要的效果现在也可以直接定义:#define M_TEST M_[0]。需要注意的是,上面有一个特殊类型ARM_BIT,这个是要区分PLC芯片用的。在刚刚提到的代码上方,写一个条件定义判断:
#ifdef ARM_M3M4
typedef INT32U ARM_BIT;
#else
typedef INT8U ARM_BIT;
#endif
所以总结代码如下:
void test()
{
#define SysRegAddr_HD_D_HM_M
#ifdef ARM_M3M4//芯片检查
typedef INT32U ARM_BIT;
#else
typedef INT8U ARM_BIT;
#endif
extern char __M;
#define M_ ((ARM_BIT*)(&__M))
#define M_TEST M_[0]
#define MOTOR_START(x) M_[1000 + x * 20]
M_TEST = 1;
MOTOR_START ( 2 ) = 1;
}虽然仍然没有搞清楚底层是如何实现的,但是问题算是解决了,经过测试XD5E,XLH24A16,XDH30A32都是ARM_A8芯片平台,暂时没有更多产品进行测试。在这里特别感谢顾工的支持,在学习与工作上不吝赐教,几乎有求必应,四米马赛90°7。
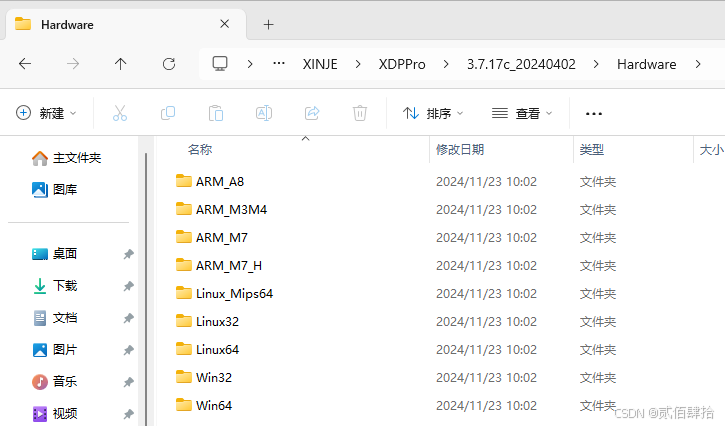
XDPPRO软件根目录可以看到信捷产品采用的芯片平台,还是蛮多的,所以以上代码不保证完全可用,只能说大多数情况是没有问题的。
8.6 强制类型转换
C语言中的强制类型转换是一种将一个数据类型的值转换为另一个数据类型的操作。这种转换可以在编译时进行,也可以在运行时进行。在C语言中,强制类型转换主要有两种形式:显式转换和隐式转换。
显式转换
显式转换是由程序员明确指定的,使用(type)语法。这种转换可以是将一个类型转换为另一个类型,比如从int转换为float,或者从float转换为int。
语法:
(数据类型) 表达式;示例:
int i = 10;
float f = (float)i; // 将int转换为float隐式转换
隐式转换是编译器自动进行的,不需要程序员显式指定。这种转换通常发生在不同数据类型的表达式混合运算时,编译器会自动将它们转换为一个共同的类型,然后进行运算。
示例:
int i = 10;
float f = 5.5;
int result = i + f; // 隐式将i转换为float,然后与f相加常见类型转换
整数转换为浮点数: 整数会被转换为浮点数,小数部分为0。
浮点数转换为整数: 浮点数的小数部分会被截断,只保留整数部分。
大整数转换为小整数: 如果大整数的值超出了小整数类型的范围,可能会发生溢出。
小整数转换为大整数: 通常不会有问题,除非整数溢出。
不同浮点数类型之间的转换: 比如从float转换为double,可能会有精度损失。
注意事项
强制类型转换可能会导致数据丢失,尤其是从大类型转换到小类型时。
强制类型转换不会改变变量的存储大小,只会改变解释数据的方式。
过度使用强制类型转换可能会降低代码的可读性和可维护性。
在实际编程中,应该谨慎使用强制类型转换,确保转换是安全和必要的。
8.7 结构体数据分配地址(强制类型转换的应用)
#define SysRegAddr_D_HD_M
typedef struct{
double vel;//速度
double acc;//加速度
double dec;//减速度
double jerk;//加加速度
double empty;//内存对齐占位
}SPEED;//速度结构体
SPEED* speed = (SPEED*)(&D[0]);
#define SysRegAddr_D_HD_M
typedef struct{
double vel;//速度
double acc;//加速度
double dec;//减速度
double jerk;//加加速度
double empty;//内存对齐占位
}SPEED;//速度结构体
SPEED* speed[10] = {NULL};
for(int i=0;i<10;i++)
{
speed[i] = (SPEED*)(&D[0 + i * sizeof(SPEED) / 2]);
}第一个案例取D0寄存器地址,然后强制转换为SPEED结构体指针类型,赋值给指针speed。第二个案例定义了十个结构体指针并初始化为NUILL。然后利用for语句批量分配指向的寄存器,其中采用sizeof宏计算SPEED的字节数一半,防止寄存器重叠。
8.8
8.9
8.10
9 更新记录
9.1 V1.0.0
初版。2024年12月1日。


















 7900
7900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











