







b站自动动态抽奖保姆级教学——关注和转发、扫描动态抽奖链接思路
利用关注包可实现批量关注up主
可以实现实时扫描b站的所有动态抽奖链接,并且批量参与
自动动态抽奖思路:通过搜索包搜索动态抽奖的链接并且保存下来,然后依次访问,再利用关注包和转发包即可实现动态抽奖,注意保存已经参与过的id避免重复参与即可
b站登录协议请看点方蓝色字体
文章结尾附Python代码
一、抓包
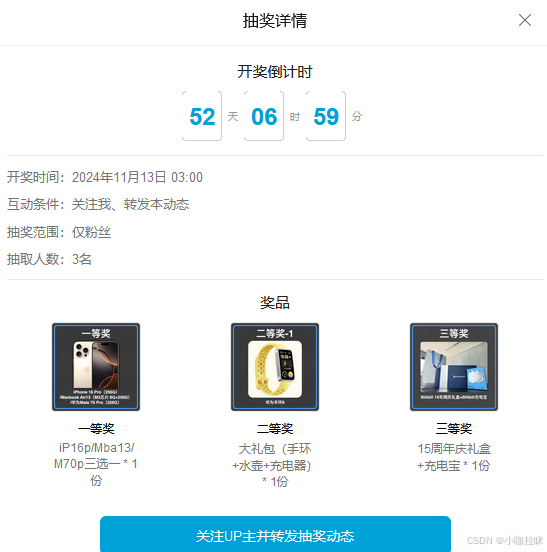
在点击关注UP主并转发抽奖之后,会看到有两个POST包:关注包、发动态包
1.1关注包
POSt请求 https://api.bilibili.com//x/relation/modify
请求表单数据act=1&csrf=46378a87cb7283a133e9c32b9c09bee7&extend_content=%7B%22entity%22:%22dt%22,%22entity_id%22:%22977045888118554640%22,%22show_detail%22:1%7D&fid=1575718735&gaia_source=native_h5_main&platform=1&spmid=333.1330.join-btn.0
关注成功的响应内容
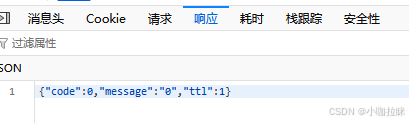
csrf——登录Cookie中即可找到
fid——关注的up主的uid
1.2转发包
POST请求 https://api.bilibili.com//x/dynamic/feed/create/dyn?csrf=46378a87cb7283a133e9c32b9c09bee7&platform=web&x-bili-device-req-json={"platform":"web","device":"pc"}&x-bili-web-req-json={"spm_id":"333.1330"}
请求表单数据:{"dyn_req":{"content":{"contents":[]},"scene":4,"attach_card":null},"web_repost_src":{"dyn_id_str":"977045888118554640"}}
转发成功的响应内容
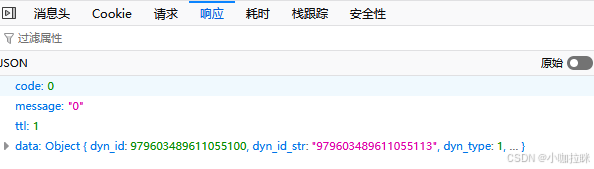
csrf
dyn_id_str——动态抽奖的动态主页的id,可在动态的链接中看到
![]()
本次抓包是通过这个动态进行抽奖,所以 dyn_id_str即为链接中的977045888118554640
fid和dyn_id_str均可在动态的URL响应中得到,只需要GET请求即可
二、批量获取动态抽奖的思路
通过搜索包搜索专栏中的动态抽奖合集,把最新的一页的文章id全部保存,再批量从这些合集响应内容中获取抽奖链接
2.1搜索包
https://www.bilibili.com/read/cv37770807/?from=search&spm_id_from=333.337.0.0&jump_opus=1
这些抽奖合集链接都是这个格式,在搜索响应中保存cv即可
GET请求参数全固定即可 https://api.bilibili.com/x/web-interface/wbi/search/type?category_id=0&search_type=article&ad_resource=5646&__refresh__=true&_extra=&context=&page=1&page_size=20&order=totalrank&pubtime_begin_s=0&pubtime_end_s=0&duration=&from_source=&from_spmid=333.337&platform=pc&highlight=1&single_column=0&keyword=动态抽奖&qv_id=9I2ItdeG70EkYlEwOksggc11eYqpHI0e&source_tag=3&gaia_vtoken=&web_location=1430654&w_rid=e6fa7219db71387b8b0cd42ba2508cf9&wts=1726921276
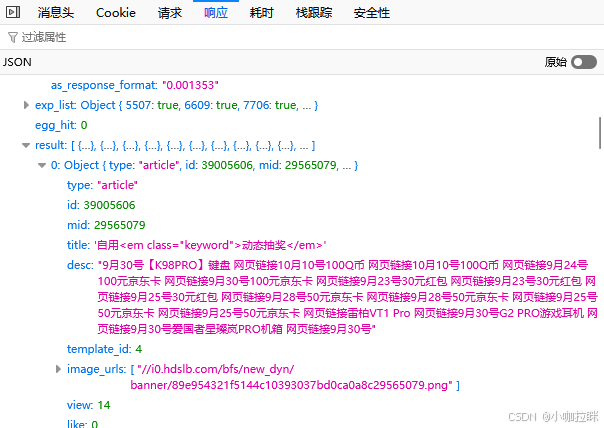
在响应的结果中的id即为搜索的合集的cv后的id(类似cv37770807)
2.2 搜索到的合集包示例
刚刚搜索到的其中一个id是37770807
直接GET请求 https://www.bilibili.com/read/cv37770807/?from=search&spm_id_from=333.337.0.0&jump_opus=1
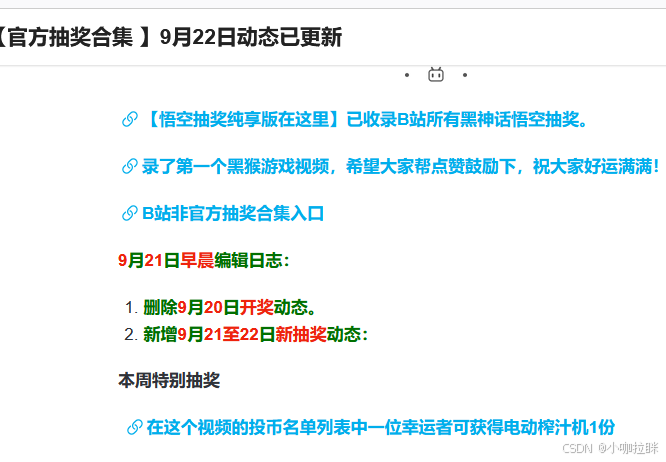


可以看到响应中有很多的抽奖链接 ,只需要把link保存下来即可
把所有的link保存下来后,批量请求这些link,获得up主的fid,通过关注包进行关注
再通过link后面的dyn_id_str通过转发包进行转发,即可实现动态抽奖
三、Python代码实现
3.1关注代码
def post_url(uid, url, data=None, headers=None, cookie_string=None):
try:
if cookie_string:
headers['Cookie'] = cookie_string
session = requests.Session()
response = session.post(url, data=data, headers=headers)
print(f'状态码: {response.status_code}')
if response.status_code == 200:
try:
if 'gzip' in response.headers.get('Content-Encoding', ''):
response_data = gzip.decompress(response.content).decode('utf-8')
else:
response_data = response.text
print("参与成功")
try:
json_data = json.loads(response_data)
print("响应数据:", json_data)
except json.JSONDecodeError:
pass
except Exception as e:
print("处理响应数据时出错:", e)
else:
print(f'请求失败,状态码:{response.status_code}')
print("响应内容:", response.text)
except Exception as e:
print("请求过程中发生错误:", e)
uid = result['uid']
data = {
'fid': uid,
'act': '1',
're_src': '0',
'csrf': bili_jct,
'spmid': '333.1368',
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:126.0) Gecko/20100101 Firefox/126.0',
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br, zstd',
'Content-Type': 'application/x-www-form-urlencoded',
'Referer': 'https://www.bilibili.com/read/cv34766197/',
'Origin': 'https://www.bilibili.com',
'Connection': 'keep-alive',
}
post_url(uid, 'https://api.bilibili.com/x/relation/modify', data, headers, cookie_string)3.2转发代码
def post_url(uid, url, data=None, headers=None, cookie_string=None):
try:
if cookie_string:
headers['Cookie'] = cookie_string
session = requests.Session()
response = session.post(url, data=data, headers=headers)
print(f'状态码: {response.status_code}')
if response.status_code == 200:
try:
if 'gzip' in response.headers.get('Content-Encoding', ''):
response_data = gzip.decompress(response.content).decode('utf-8')
else:
response_data = response.text
print("参与成功")
try:
json_data = json.loads(response_data)
print("响应数据:", json_data)
except json.JSONDecodeError:
pass
except Exception as e:
print("处理响应数据时出错:", e)
else:
print(f'请求失败,状态码:{response.status_code}')
print("响应内容:", response.text)
except Exception as e:
print("请求过程中发生错误:", e)
data = {
"dyn_req": {
"content": {
"contents": []
},
"scene": 4,
"attach_card": None
},
"web_repost_src": {
"dyn_id_str": article_id
}
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:126.0) Gecko/20100101 Firefox/126.0',
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br, zstd',
'Content-Type': 'application/json',
'Referer': 'https://www.bilibili.com/',
'Origin': 'https://www.bilibili.com',
'Connection': 'keep-alive',
}
post_url(uid,
f'https://api.bilibili.com/x/dynamic/feed/create/dyn?csrf={bili_jct}&platform=web&x-bili-device-req-json=%7B%22platform%22:%22web%22,%22device%22:%22pc%22%7D&x-bili-web-req-json=%7B%22spm_id%22:%22333.1330%22%7D',
json.dumps(data), headers, cookie_string)
3.3搜索代码
def scan(cookie):
url = "https://api.bilibili.com/x/web-interface/wbi/search/type"
params = {
"category_id": "0",
"search_type": "article",
"ad_resource": "5646",
"__refresh__": "true",
"_extra": "",
"context": "",
"page": "1",
"page_size": "20",
"order": "totalrank",
"duration": "",
"from_source": "",
"from_spmid": "333.337",
"platform": "pc",
"highlight": "1",
"single_column": "0",
"keyword": "互动抽奖", # 使用URL编码
"qv_id": "1h9RvukkgK4qVqhrgfb9czRJczxEkvB6",
"source_tag": "3",
"gaia_vtoken": "",
"web_location": "1430654",
"w_rid": "5f35641ccfe38eaf8766e71f671a966c",
"wts": str(int(time.time())/1000)# 当前时间戳
}
# 定义请求头
headers = {
"Host": "api.bilibili.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:126.0) Gecko/20100101 Firefox/126.0",
"Accept": "application/json, text/plain, */*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Referer": "https://search.bilibili.com/article?keyword=" + quote(
"互动抽奖") + "&from_source=webtop_search&spm_id_from=333.1007&search_source=5",
"Origin": "https://search.bilibili.com",
"Connection": "keep-alive",
"Cookie": cookie,
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-site",
"Priority": "u=4",
"TE": "trailers"
}
# 发送GET请求
response = requests.get(url, headers=headers, params=params)
# 打印响应状态码和内容类型
print("状态码:", response.status_code)
print("内容类型:", response.headers.get('Content-Type'))
# 检查响应是否成功并包含 'data' 键
if response.status_code == 200:
try:
response_json = response.json()
print("JSON解析成功")
print(response_json)
# 检查是否包含 'data' 键
if 'data' in response_json:
# 提取ID
ids = [item['id'] for item in response_json['data']['result']]
# 保存到CSV文件
df = pd.DataFrame(ids, columns=['id'])
df.to_csv('id.csv', index=False)
print("ID已保存到id.csv")
else:
print("响应中不包含 'data' 键:", response_json)
except ValueError:
print("JSON解析失败,响应内容:", response.text)
else:
print("请求失败,状态码:", response.status_code)


















 8171
8171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











