







传统异常值检测
- 图形位置分布
例如箱线图检测异常值 - 统计方法检测:假设全量数据服从一定的分布,比如常见的正态分布,泊松分布等;在计算每个点属于这个分布的概率
- 距离检测:假设正常的数据比较集中,有较多的邻居,而异常数据特立独行,常用的有连续特征间的欧氏距离(标准化下的欧氏距离(马氏距离));名义变量下的余弦相似度
Isolation Forest
无监督异常检测(anomaly detection),或者又被称为离群点检测。
- 异常数据分样本中大多数数据不太一样
- 异常数据在整体数据样本中占比比较小
异常数据的不同,可以利用各种统计的、距离的、密度的量化指标去描述数据样本跟其他样本的疏离程度
孤立森林算法是一种适用于连续数据的无监督异常检测方法。与其他异常检测算法通过距离、密度等量化指标来刻画样本间的疏离程度不同,孤立森林算法通过对样本点的孤立来检测异常值。具体来说,该算法利用一种名为孤立树iTree的二叉搜索树结构来鼓励样本。由于异常值的数量较少且与大部分样本的疏离性,因此,异常值会被更早的孤立起来,也即异常值会距离iTree的根节点更近,而正常值则会距离根节点有更远的距离。此外,相较于LOF,K-means等传统算法,孤立森林算法对高纬数据有较好的鲁棒性。
定义
孤立树:
若T为孤立树的一个节点,T存在两种情况:没有子节点的外部节点,有两个子节点
(
T
l
,
T
r
)
(T_l,T_r)
(Tl,Tr)和一个test的内部节点。在T的test有一属性q和一个分割点p组成,q<p的点属于
T
l
T_l
Tl,反之属于
T
r
T_r
Tr
样本点x在孤立树中的路径长度h(x):样本点x在iTree的根节点到叶子节点经过的边的数量
算法流程
1.训练出t棵孤立树,组成孤立森林。随后将每个样本点带入森林中的每颗孤立树,计算平均高度,在计算每个样本点的异常值分数
(1)
X
=
x
1
,
.
.
.
.
.
.
.
,
z
n
X={x_1,.......,z_n}
X=x1,.......,zn为给定数据集,
∀
x
i
∈
X
,
x
i
=
(
X
i
1
,
.
.
.
.
.
.
,
x
i
d
)
\forall x_i \in X, x_i = (X_{i1},......,x_{id})
∀xi∈X,xi=(Xi1,......,xid), 从X中随机抽取
ψ
\psi
ψ个样本点构成X的子集X’放入根节点
(2)从d个维度中随机指定一个维度q,在当前数据中随机产生一个切割点p,
m
i
n
(
x
i
j
,
j
=
q
,
x
i
j
∈
X
′
)
<
p
<
m
a
x
(
x
i
j
,
j
=
q
,
x
i
j
∈
X
′
)
min(x_{ij},j=q,x_{ij}\in X')<p<max(x_{ij},j=q,x_{ij} \in X')
min(xij,j=q,xij∈X′)<p<max(xij,j=q,xij∈X′)
(3)此切割点p生成了一个超平面,将当前数据空间划分为两个子空间:指定维度小于p的样本点放入左子节点,大于或等于p的放入右子节点
(4)递归(2)和(3),直至所有的叶子节点都只有一个样本点或者孤立树已经达到指定高度
(5)循环(1)~(4),直至生成t个孤立树
2.对于每一个数据点
x
i
x_i
xi,令其遍历每一颗孤立树(iTree),计算点
x
i
x_i
xi在森林中的平均高度
h
(
x
i
)
h(x_i)
h(xi),对所有点的平均高度做归一化处理。异常值分数的计算公式如下:
s
(
x
,
μ
)
=
2
E
(
h
(
x
)
)
c
(
μ
)
s(x,\mu) = 2^{\frac{E(h(x))}{c(\mu)}}
s(x,μ)=2c(μ)E(h(x))
其中,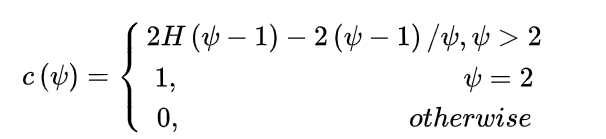
如果
E
(
h
(
x
)
)
−
>
c
(
μ
)
E(h(x))->c(\mu)
E(h(x))−>c(μ),那么s->0.5
如果
E
(
h
(
x
)
)
−
>
0
E(h(x))->0
E(h(x))−>0,那么s->1
如果
E
(
h
(
x
)
)
−
>
n
−
1
E(h(x))->n-1
E(h(x))−>n−1,那么s->0
算法应用
Isolation Forest 算法主要有两个参数:一个是二叉树的个数;另一个是训练单棵 iTree 时候抽取样本的数目。实验表明,当设定为 100 棵树,每棵树高度不超过8,抽样样本数为 256 条时候,IF 在大多数情况下就已经可以取得不错的效果。这也体现了算法的简单、高效。
Isolation Forest 是无监督的异常检测算法,在实际应用时,并不需要黑白标签。需要注意的是:
(1)如果训练样本中异常样本的比例比较高,违背了先前提到的异常检测的基本假设,可能最终的效果会受影响;
(2)异常检测跟具体的应用场景紧密相关,算法检测出的“异常”不一定是我们实际想要的。比如,在识别虚假交易时,异常的交易未必就是虚假的交易。所以,在特征选择时,可能需要过滤不太相关的特征,以免识别出一些不太相关的“异常”。
特点
- iForest具有线性时间复杂度。因为是ensemble的方法,所以可以用在含有海量数据的数据集上面。通常树的数量越多,算法越稳定。由于每棵树都是互相独立生成的,因此可以部署在大规模分布系统上来加速运算
- iForest不适用于特别高维的数据,由于每次切分数据空间都是随机选取一个维度,建完树后仍然有大量的维度信息没有又被使用,导致算法可靠性降低。高维空间还可能存在大量噪音维度或无关维度,影响树的构建。对这类数据,建议使用子空间异常检测技术。
- iForest仅对G咯罢了 anomaly敏感,即全局稀疏点敏感,不擅长处理局部的相对稀疏点
- iForest推动了重心估计理论发展,目前在分类聚类和异常检测中都取得显著效果
LOF(Local Outlier Factor)
局部异常因子算法
相关定义
- d(p,o):两点之间p和o之间的距离
- k-distance:第k距离,对于点p的第k距离 d k ( p ) = d ( p , o ) d_k(p) = d(p,o) dk(p)=d(p,o),p的第k距离,也就是距离p第k远的点的距离,不包括p
- k-distance neighborhood of p:第k距邻域,p的第k距离即以内的所有点,包括第k距离
- reach-distace 可达距离
- local reachability density:局部可达密度,表示点p的第k领域内颠倒p的平均可达距离的倒数
- local outlier factor 局部离群因子,表示点p的领域点Nk§的局部可达密度与点p的局部可达密度之比的平均数。如果这个比值越接近1,说明p的其邻域点密度差不多,p可能和邻域同属一簇;如果这个比值越小于1,说明p的密度高于其邻域点密度,p为密集点;如果这个比值越大于1,说明p的密度小于其邻域点密度,p越可能是异常点。
算法思想
主要是通过比较两个点p和其领域点的密度俩判断该点是否是异常点,如果点p的密度月底,越可能被认定是异常点。至于密度,是通过点之间的距离来计算的,点之间距离越远,密度越低,距离越近,密度越高。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









