







离群点检测
离群点检测时找出其行为很不同于预期对象的过程,这种对象称为离群点或异常。
离群点检测和聚类分析是两项高度相关的任务。
离群点和离群点分析
什么是离群点
离群点是一个数据对象,它显著不同于其他数据对象,好像他是被不同的机制产生的一样。
离群点不同于噪声数据,噪声数据是被观测变量的随机误差或方差,噪声数据在数据分析中不是令人感兴趣的。
离群点是有趣的,因为怀疑产生他们的机制不同于产生其他数据的机制。
离群点的类型
- 全局离群点:有时也别称为点异常
- 情境(或条件)离群点: 对于对象的特定情境,它显著的偏离其他对象。
在情境离群点检测中,所考虑数据对象的属性划分为两组:情境属性和行为属性
- 集体离群点:一个数据集,数据对象的一个子集形成集体离群点,如果这些对象作为整体显著偏离整个数据集。
离群点检测的挑战
- 正常对象和离群点的有效建模
- 针对应用的离群点检测
- 在离群点检测中处理噪声
- 可理解性
离群点检测方法
- 监督方法
- 无监督方法
- 半监督方法
统计学方法
统计学方法对数据的正常行做出假定,他们假定正常的数据对象由一个统计模型产生,而不遵循该模型的数据是离群点。
离群检测的统计学方法的一般思想是:学习一个拟合给定数据集的生成模型,然后识别该模型低概率区域中的对象,把它们作为离群点,然而,有许多不同方法来学习生成模型。
一般而言,根据如何制定和如何学习模型,离群点检测的统计学方法可以划分成两个主要类型:参数方法和非参数方法。
参数方法
基于正太分布的一元离群点检测
仅涉及一个属性或者变量的数据称为一元数据,通常数据由一个正太分布产生,然后可以由输入数据学习正太分布的参数,并把低概率的点识别为检测离群点:
如下例:


多元离群点检测
涉及两个或者多个属性或者变量的数据称为多元数据。许多一元离群点检测方法都可以扩充,用来处理多元数据。其核心思想是把多元离群点检测任务转换成一元离群点检测问题。
下面是两个例子:

使用混合参数分布
如果假定数据是由正太分布产生的,则在许多情况下这种假定很有效,然而,当实际数据很复杂时,这种假定过于简单,在这汇总情况下,假定数据是被混合参数分布产生的。

非参数方法
在离群点检测的非参数方法中,“正常数据”的模型从输入数据学习,而不是假定一个先验,通常非参数方法对数据做较少假定,因而在更多情况下都可以使用。
基于邻近性的方法
基于邻近性的方法假定一个对象是离群点,如果它在特征空间中的最近邻也远离它,集该对象与它的最近邻之间的邻近性显著地偏离数据集中其他对象与他们之间的近邻之间的邻近性。
基于距离的离群点检测和嵌套循环算法

基于网格的方法
基于密度的离群点检测
基于聚类的方法
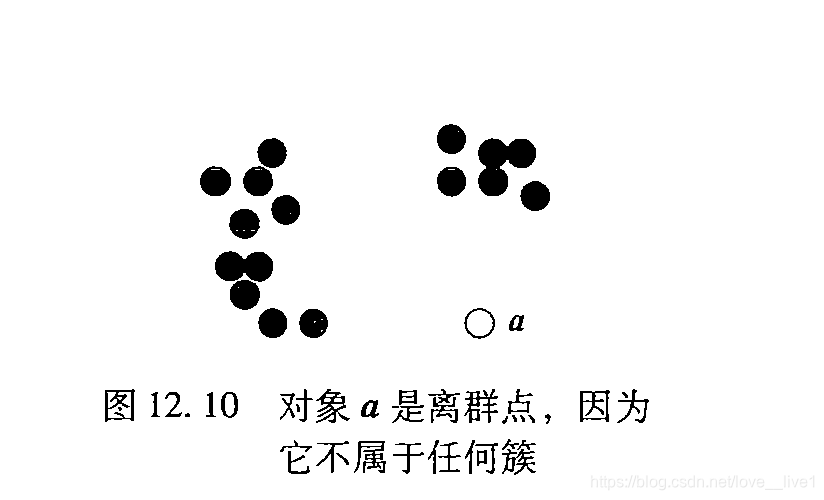
基于聚类的方法假定正常数据对象属于大的、稠密的簇,而离群点属于小或稀疏的簇,或者不属于任何簇。

基于分类的方法
如果训练数据具有类标号,则离群点检测可以看作分类问题,基于分类的离群点检测方法一般思想是训练一个可以区分“正常”数据和离群点的分类模型。
挖掘情景离群点和集体离群点
情境属性包括空间属性、时间、网络位置和复杂结构的属性。行为属性定义对象的特征,并用于估计对象在它所属的情境下是否是离群点。
一组数据对象形成一个集体离群点,如果这些对象作为一个整体显著地偏离整个数据集。尽管该组群中的每个对象可能并非离群点。
高维数据中的离群点检测
高维数据离群点检测面临离群点解释、数据稀疏性、数据子空间、维度可伸缩性的挑战。
扩充的传统离群点检测方法,使用传统的基于近邻性的离群点模型,为克服高维空间邻近性度量恶化问题,使用其他度量或构造子空间在其中检测离群点。
搜索各种子空间中的离群点的优点是,如果发现一个对象是很低维度的子空间中的离群点,则该子空间提供了重要信息,解释了对象为什么以及在何种程度上是离群点。
为高维离群点建立一个新模型,避免邻近性度量,而采用新的启发式方法来检测离群点。

















 1199
1199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









