








想必大家都知道,cuda里面每一个block上有一块高速缓冲区,这就是提供给block里面各个线程使用的shared memory,那怎么使用这一块内存呢?
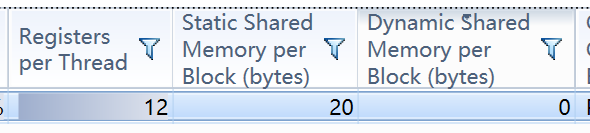
首先,shared memory分为固定分配方式和动态分配方式,就是上图的Static Shared Memory和Dynamic Shared Memory
1,固定分配
直接__shared__ int seme[5] ;这就是在每一个block里面分配5个int(20B)
__global__ void addKernel(int *c, const int *a)
{
int i = threadIdx.x;
__shared__ int smem[5];
smem[i] = a[i];
__syncthreads();
if (i == 0) //0号线程做平方和
{
c[0] = 0;
for (int d = 0; d<5; d++)
{
c[0] += smem[d] * smem[d];
}
}
if (i == 1)//1号线程做累加
{
c[1] = 0;
for (int d = 0; d<5; d++)
{
c[1] += smem[d];
}
}
if (i == 2) //2号线程做累乘
{
c[2] = 1;
for (int d = 0; d<5; d++)
{
c[2] *= smem[d];
}
}
}
调用,启动的时候,block个数1,所以shared memory使用20B
addKernel << <1,size, 0, 0 >> >(dev_c, dev_a);
通过nsight可以看出,使用了20B的共享内存,并且是Static的;

2,动态分配
没错,就是在block里面声明,前面加上extern;
__global__ void addKernel(int *c, const int *a)
{
int i = threadIdx.x;
extern __shared__ int smem[];
smem[i] = a[i];
__syncthreads();
if (i == 0) //0号线程做平方和
{
c[0] = 0;
for (int d = 0; d<5; d++)
{
c[0] += smem[d] * smem[d];
}
}
if (i == 1)//1号线程做累加
{
c[1] = 0;
for (int d = 0; d<5; d++)
{
c[1] += smem[d];
}
}
if (i == 2) //2号线程做累乘
{
c[2] = 1;
for (int d = 0; d<5; d++)
{
c[2] *= smem[d];
}
}
}
那在哪里指定大小呢?
原来是启动核函数的时候指定的第三个参数,之前使用多个流的时候,第四个参数绑定流的序号,第三个参数总是设为0,现在终于明白它的含义了
addKernel << <1,size, size*sizeof(int), 0 >> >(dev_c, dev_a);//第三个参数是每个block共享内存的大小

这几天正在准备写一篇关于cuda流的使用,然后会加上一些自己的学习总结,年轻,干就完了,奥利干!















 1223
1223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









