






课程地址:【NodeJS+Gulp基础入门+实战】 https://www.bilibili.com/video/BV1aE411n737/?share_source=copy_web&vd_source=b1cb921b73fe3808550eaf2224d1c155
目录
9 服务器端基础概念
前面介绍了Node.js的基础知识,学会了Node.js中的核心知识——模块化开发。
下面进入到网站的服务器端开发阶段。开始介绍服务器端的相关概念。
9.1 网站的组成
网站应用程序主要分为两大部分,客户端和服务器端。
客户端:在浏览器中运行的部分,就是用户看到并与之交互的界面程序。使用html、css、JavaScript构建。
服务器端:在服务器中运行的部分,负责存储数据和处理应用逻辑。
现在可以将服务器理解为另外一台电脑,主要负责存储数据,支撑网站业务逻辑。
之前学习的都是前端技术,构建用户界面的技术,代码是运行在浏览器中的。
服务器端技术,学习在服务器上存储数据,使用Node.js书写网站业务逻辑。代码是运行在服务器电脑上的。

客户端和服务器端通过请求和响应获取数据创建数据。
请求:客户端向服务器端发送的指令,告诉服务器端,客户端要获取数据。
响应:服务器端接收到指令后对客户端进行回应或应答,将客户端请求的数据发给客户端。
网站其实就是客户端和服务器基于请求和响应模型的一种应用结构。
网站的组成包括客户端和服务器端两部分。
9.2 Node网站服务器
能够提供网站访问服务的机器就是网站服务器,它能够接收客户端的请求,能够对请求做出响应。

① 首先,它需要是一台电脑。② 这台电脑要安装Node这个代码运行环境。③ 在Node环境中使用Node.js创建可以接收请求和响应请求的对象。
满足以上3个条件,那么它就是一个Node网站服务器。
真实的网站服务器一般是放置在专门的网络机房中的。
服务器电脑和我们平时使用的电脑有一些区别。它可以没有鼠标、键盘和显示器,它可以只有一个主机。
程序员一般通过远程控制的方式去控制这台服务器。
Node服务器向外界提供网站服务,那么用户如何可以访问到这个网站?
要访问服务器中提供的网站,要在茫茫网络中找到这台服务器(通过IP地址的方式)。
9.3 IP地址
IP地址:互联网中设备的唯一标识。
IP: Internet Protocol Addresss,互联网协议地址。
接入互联网的设备,需要有一个唯一的访问地址,方便他人找到本设备。就好像现实生活中每个人都有一个家庭住址一样。别人可以通过某个人的家庭住址找到某个人。
计算机的IP地址是由一串数字组成的,由3个点隔开的一串数字组成。
使用IP地址可以访问到网站服务器,因为IP地址难以记忆,平时不会直接使用IP地址去访问网站。
9.4 域名
由于IP地址难以记忆,所以产生了域名的概念。
所谓域名就是平时上网所使用的网址。
比如在浏览器的地址栏输入baidu.com就能访问百度的官网了。
域名和IP地址是对应的关系。
http://www.itheima.com <=> http://124.165.219.100/
虽然浏览器地址栏中输入的是网址,但是最终还是会将域名转换为IP地址才能访问到指定的网站服务器。
9.3和9.4,通过IP地址或者域名找到网站的服务器。但是服务器不仅可以向外界提供网站服务,还可以提供邮件服务、文件上传与下载服务和数据库服务等。
如何区分服务?当有请求时,怎样判断该请求请求的服务类型。
为了区分不同的服务,计算机中有个端口的概念。
9.5 端口
端口是计算机与外界通讯交流的出口,用来区分服务器电脑中提供的不同的服务。
生活中的例子:学校食堂,不同窗口卖不同的食物。食堂通过窗口号区分不同的食物。
可以将服务器看作这个大食堂,在一台服务器中可以提供很多种服务,比如网站服务、邮件服务、文件上传与下载服务等。
当客户端通过IP地址找到服务器端电脑后,服务器端电脑如何知道此客户端希望服务器提供何种服务呢?
此时端口就出现了。计算机的端口与食堂的窗口概念是一样的,计算机的端口号用来区分服务器提供的不同的服务的。
端口号是一堆数字。
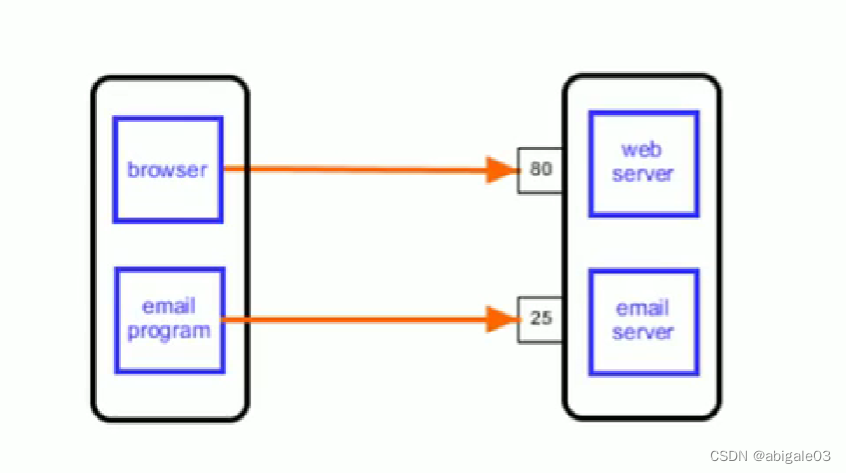
上图,左边是客户端电脑,右边是服务器端电脑。
客户端电脑在访问到服务器端电脑后,还需要通过端口号告诉服务器端,它想要找的是哪种服务。
比如浏览器在找到服务器后,告诉服务器要访问80端口号上提供的服务(即web服务)。再比如客户端电脑上的邮件软件,在找到服务器电脑后,告诉服务器电脑要访问25端口号上提供的服务(即邮件服务)。
9.6 URL
这节分析客户端访问服务器端的请求地址。
URL:Uniform Resource Locator,统一资源定位符,是专为标识Internet网上资源位置而设的一种编址方式。
url中标注了要请求的服务器地址,提供服务的端口,要请求的资源位置等信息。
平时所说的网页地址(网址)指的即是URL。
通过网址确定要访问的资源在互联网的位置。
9.6.1 URL的组成
传输协议: // 服务器IP或域名:端口/资源所在位置标识
http://www.itcast.cn/news/20181018/89818947.html
1 传输协议:网站用的传输协议一般是http协议。
http协议:超文本传输协议,提供了一种发布和接受html页面的方法。
超文本:超级文本。文本中不仅可以包含文字,还可以包含图片、视频和音频等,实际指的就是html文本。
http协议:规定了客户端和服务器端通信格式,比如传输内容的类型以及格式等。
2 服务器IP或域名地址
通过上述地址先找到要请求的服务器。
3 端口
为什么在浏览器中输入网址时从来没有输入过端口?
网站应用大多使用80端口,在没有使用端口情况下,浏览器请求默认加上80端口。
4 资源所在位置标识
通过这个标识,在服务器中找到要找的资源。
9.7 开发过程中客户端和服务器端的说明
客户端:浏览器,可以是任何一台电脑的浏览器。
服务器端:远端电脑。
做服务器端开发,在开发阶段,客户端和服务器端使用同一台电脑,即开发人员电脑。
开发人员的电脑既充当客户端,又充当服务器端。

开放者电脑里既安装了浏览器。又安装了Node运行环境。所以既可以充当客户端,又可以充当服务器端。
问题:既然是同一台电脑,怎么通过网络的方式去访问服务器呢?
本台电脑都有一组特殊的IP和域名代表本机。即A在他的电脑输入localhost就代表A自己的主机。
本机域名:localhost
本地IP:127.0.0.1
开发过程中输入locakhost代表通过网络的方式找到自己电脑中的服务器。
10 创建web服务器
已完成:网站服务器实际就是一台电脑,这台电脑里要安装node软件。
使用Node.js创建软件层面的网站服务器。要得到请求对象和响应对象。

③ Node.js与JavaScript是一样的,都是基于事件驱动的语言,都是当...时去做...
比如客户端,当用户点击按钮时,去做什么事情;鼠标移到某个盒子的时候,要做什么事情。
Node.js也是,当有请求来的时候,要接受这个请求。
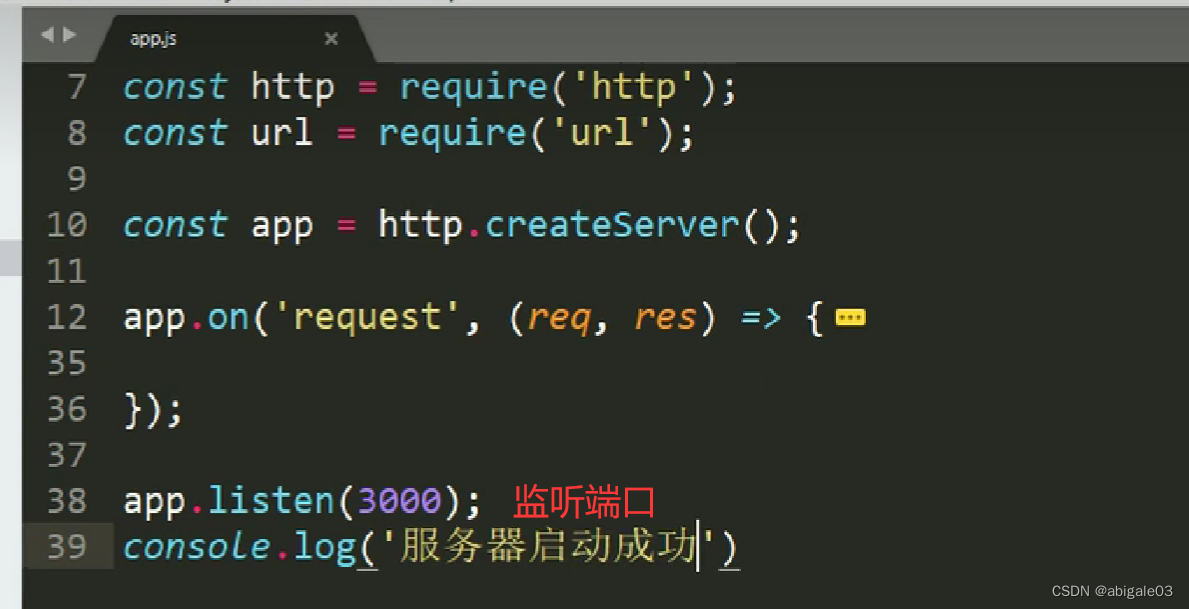
④ 网站服务器创建好后,要去监听一个端口,否则无法向外界提供服务。
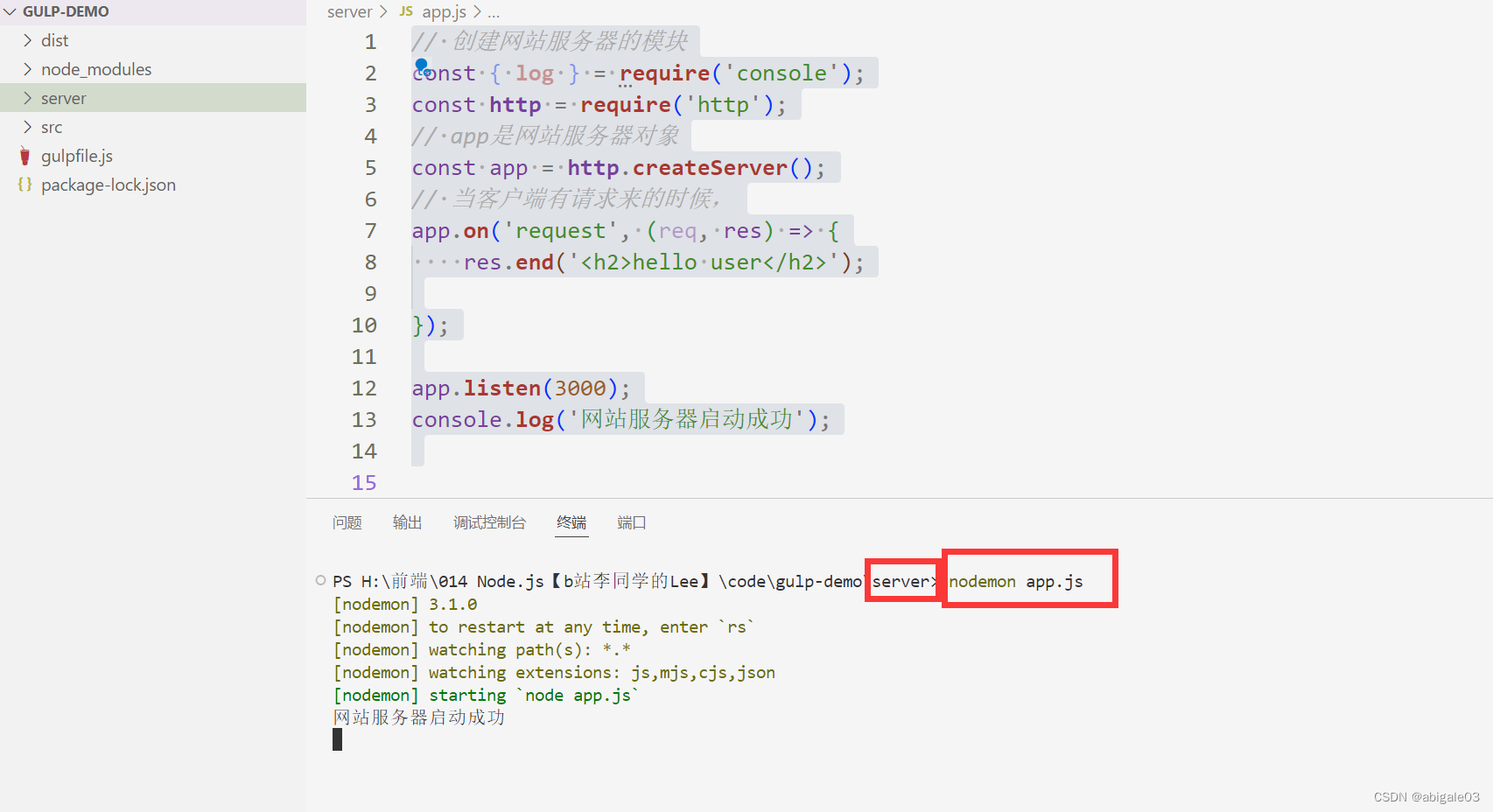
// 创建网站服务器的模块
const { log } = require('console');
const http = require('http');
// app是网站服务器对象
const app = http.createServer();
// 当客户端有请求来的时候,
app.on('request', (req, res) => {
res.end('<h2>hello user</h2>');
});
app.listen(3000);
console.log('网站服务器启动成功');
问题:接下来要去访问这个服务器。怎么访问呢?
① 首先使用node命令执行上述文件(只有文件执行了,网站服务器才能启动成功),② 然后在浏览器中访问服务器。
① 启动服务器
在server文件夹下,使用node命令执行app.js文件。
这里使用nodemon命令,后续文件变化就可以自动执行这个文件。
② 访问服务器
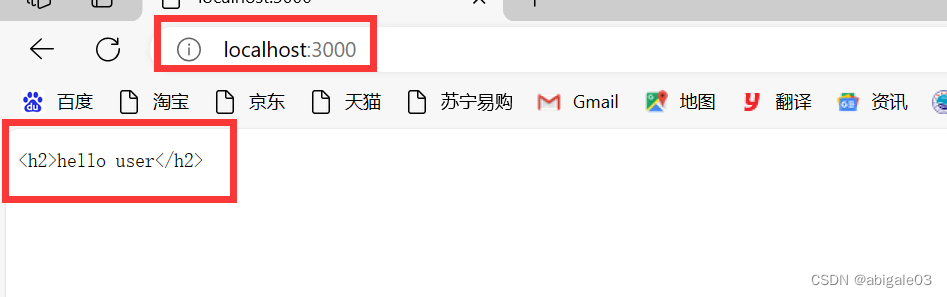
由于这个网站是在自己电脑的服务器启动的,因此要访问自己的电脑,使用特殊的域名localhost(使用localhost找到自己的电脑)。
但是自己的电脑提供很多服务,怎么去区分服务呢?怎么让他知道现在要访问的是网站这个服务呢?
加上端口号。
比如刚才监听的是3000这个端口,就在localhost后加上3000这个端口号。
结果
显示服务器返回的信息。
新问题:h2标签怎么原封不动输出了呢?不应该显示成标题的样式吗?
了解http协议可以解决这个问题。
总结:创建网站服务器的方法如下。
// 创建网站服务器的模块
const { log } = require('console');
const http = require('http');
// app是网站服务器对象
const app = http.createServer();
// 当客户端有请求来的时候,
app.on('request', (req, res) => {
res.end('<h2>hello user</h2>');
});
app.listen(3000);
console.log('网站服务器启动成功');
11 HTTP协议
11.1 http协议的概念
http协议:客户端与服务器端通信规范。
为什么要有这个规范?
在网站应用在运行中,服务器端要知道客户端请求了什么,客户端要知道服务器端响应了什么。不能鸡同鸭讲。
客户端与服务器端通信需要一个统一的规范,即http协议。
超文本传输协议(英文: Hyper Text Transfer Protocol)规定了如何从网站服务器传输超文本(html文本)到本地浏览器,基于客户端服务器架构工作,是客户端和服务器端请求和应答的标准。
超文本,超级文本,指文件不只包含文字,还有视频音频图片等等,实际指的就是html文本。
11.2 报文
在http请求和响应的过程中传递的数据块就叫报文,包括要传送的数据和一些附加信息,并且要遵守规定的格式。
报文:客户端和服务器端对话的说明和对话的内容。
数据块包含了请求和响应的相关信息。例如用户在登录时输入的用户名和密码,包含在请求数据块中进行传递;当前登录是成功还是失败,此消息被包含在响应数据块中。
数据块在传输过程中要遵循规定的格式,实际是冒号分割的键值对。
报文分请求报文和响应报文。
实际浏览器例子。
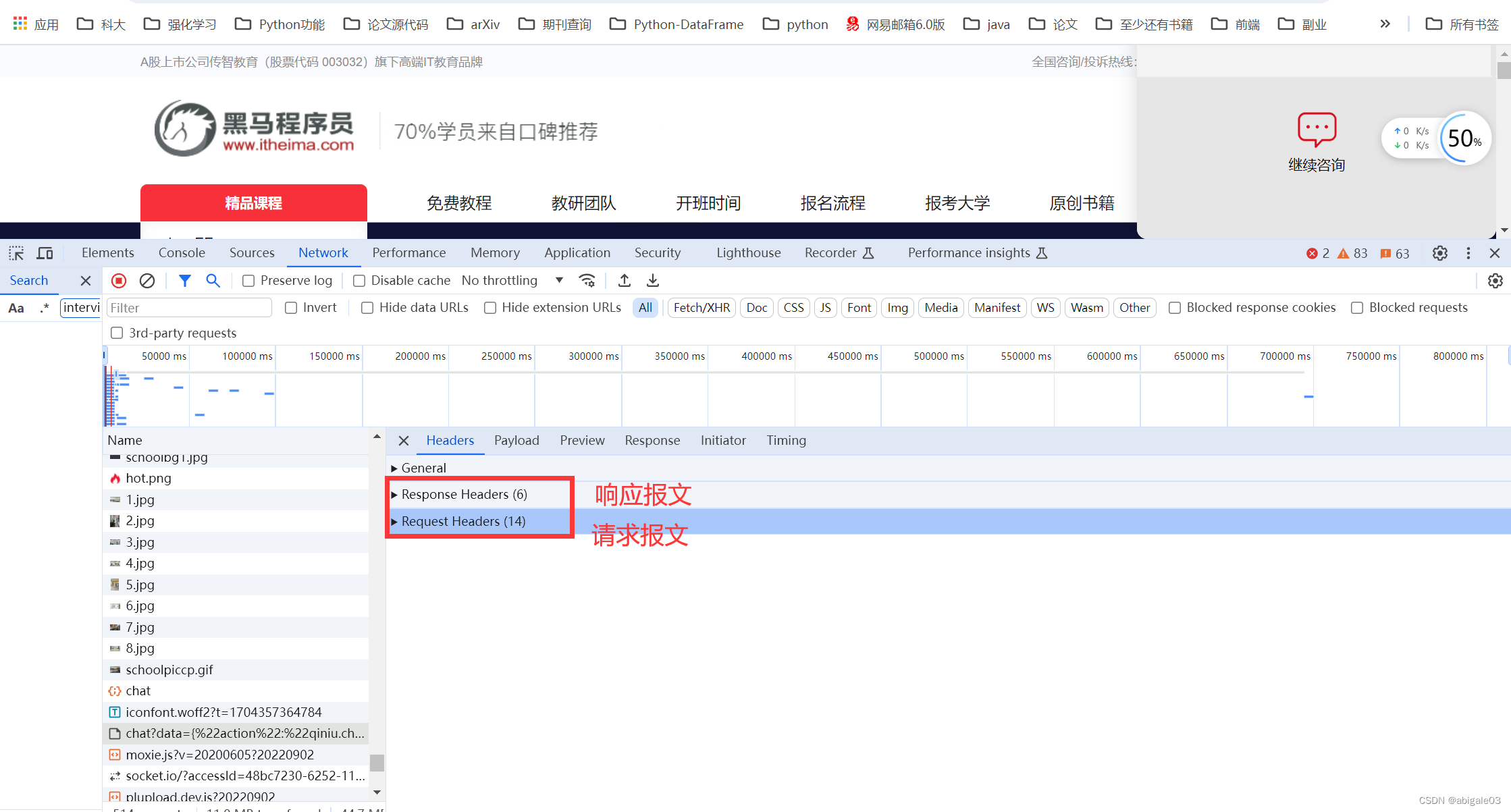
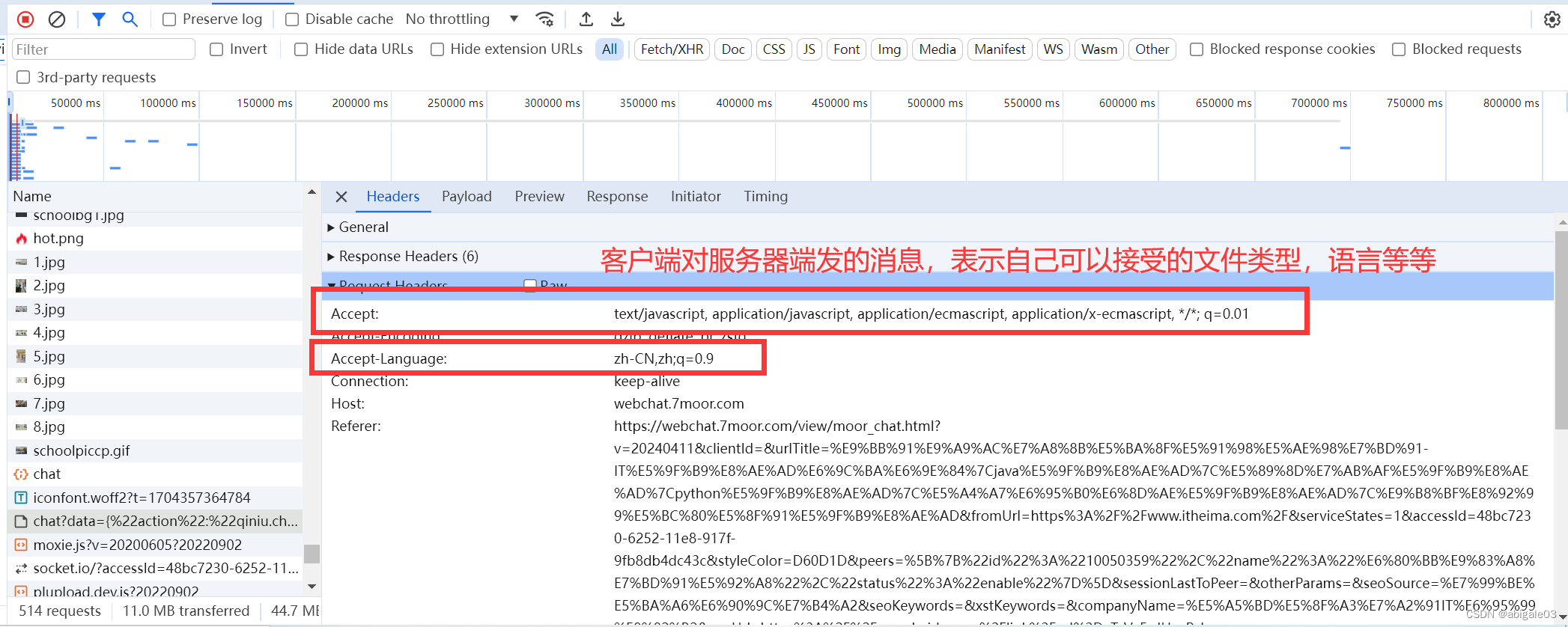
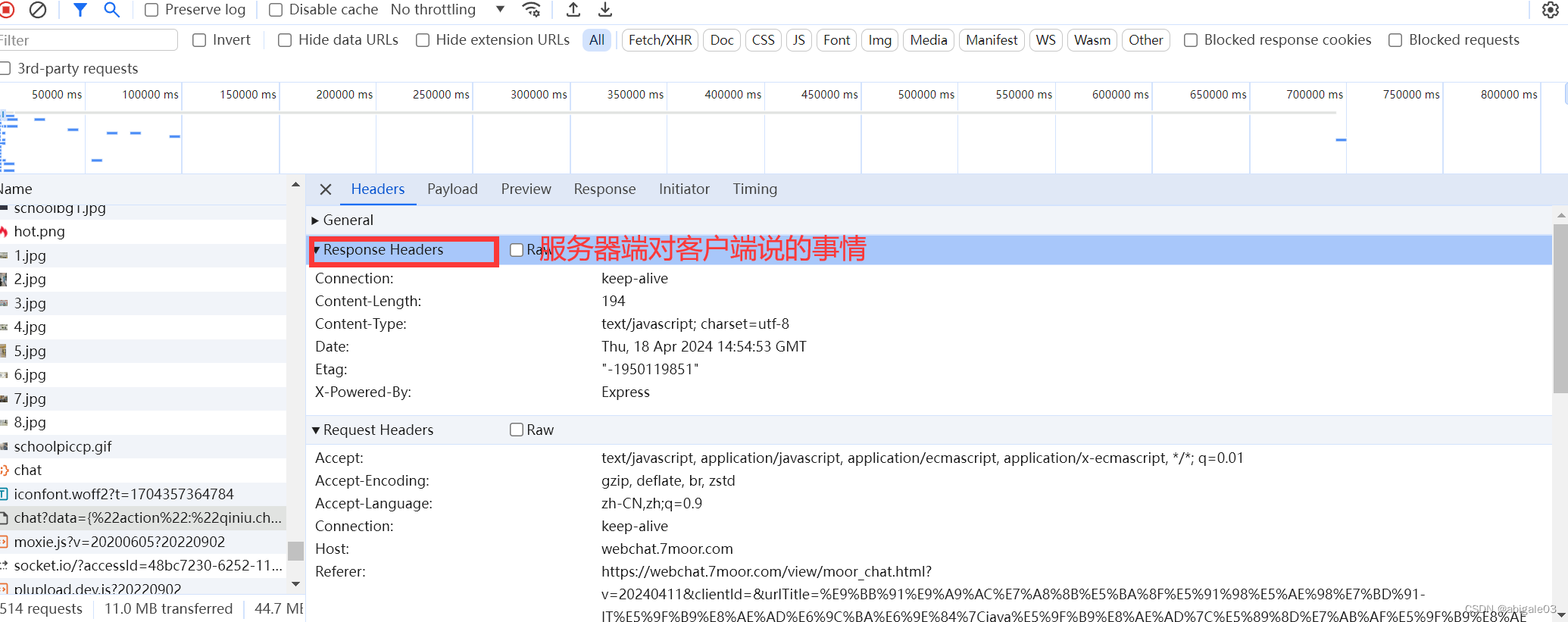
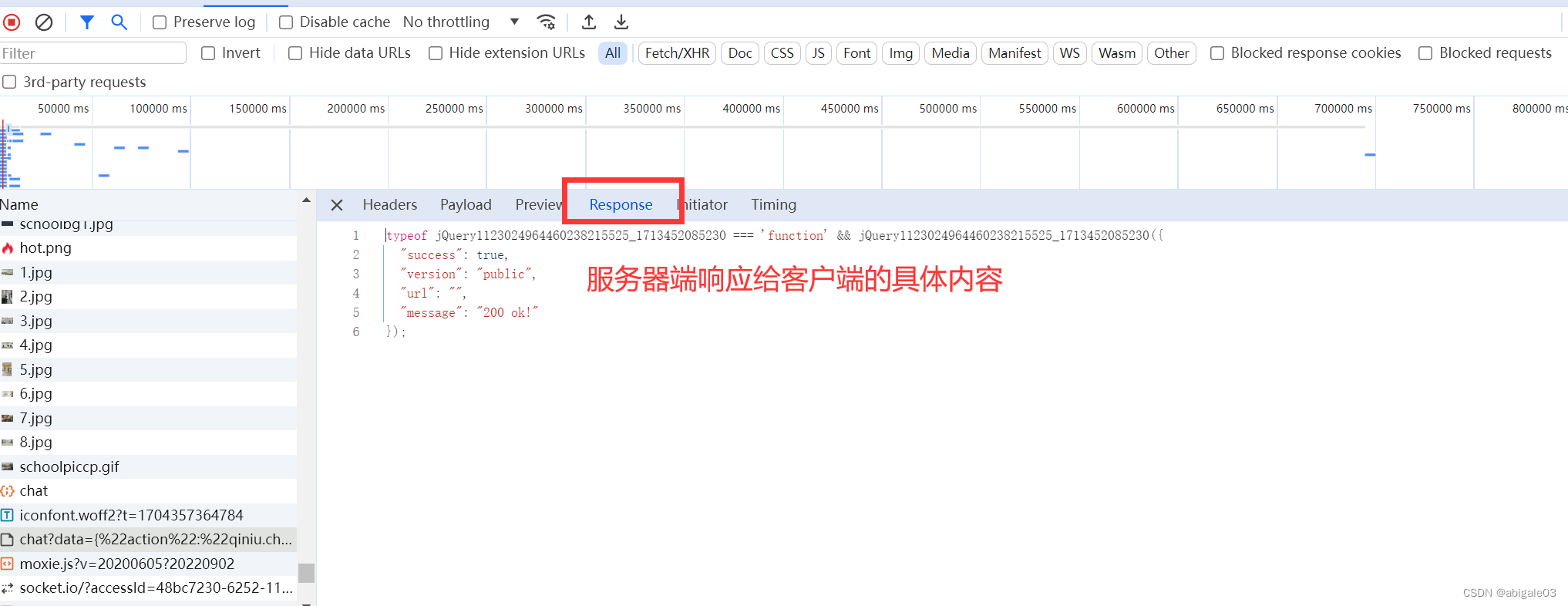
11.2.1 请求报文
客户端向服务器端发送请求时所携带的数据块,即客户端对服务器端发的消息。

1 请求方式 request method
告诉服务器本次请求要做的事情。
- get 请求数据
- post 发送数据
- post请求相当于get请求要安全一些。
客户端向服务器端发送请求,最常见的get请求就是在浏览器的地址栏中输入网址的方式。
服务器端可以获取客户端的请求方式。
1 发送get请求
实践
1 在服务器里打印输出下请求方式
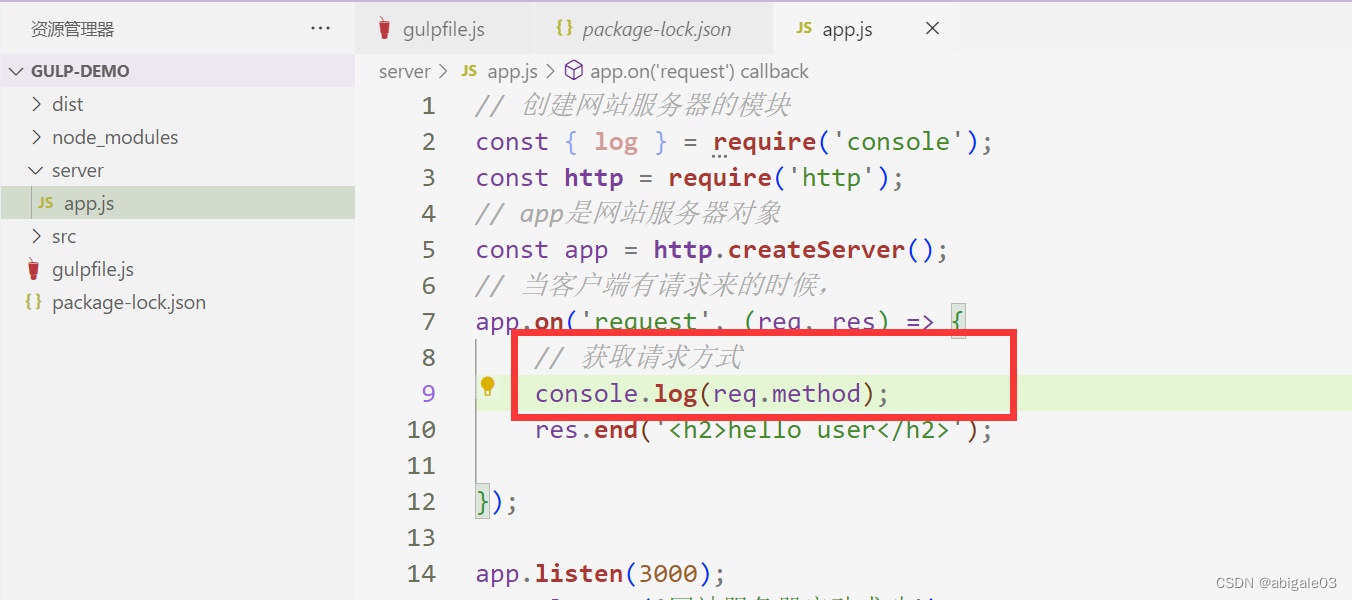
2 控制台中开启服务器。
此时网站服务器已经启动成功。

3 切换到浏览器中
服务器端给客户端做出了响应。
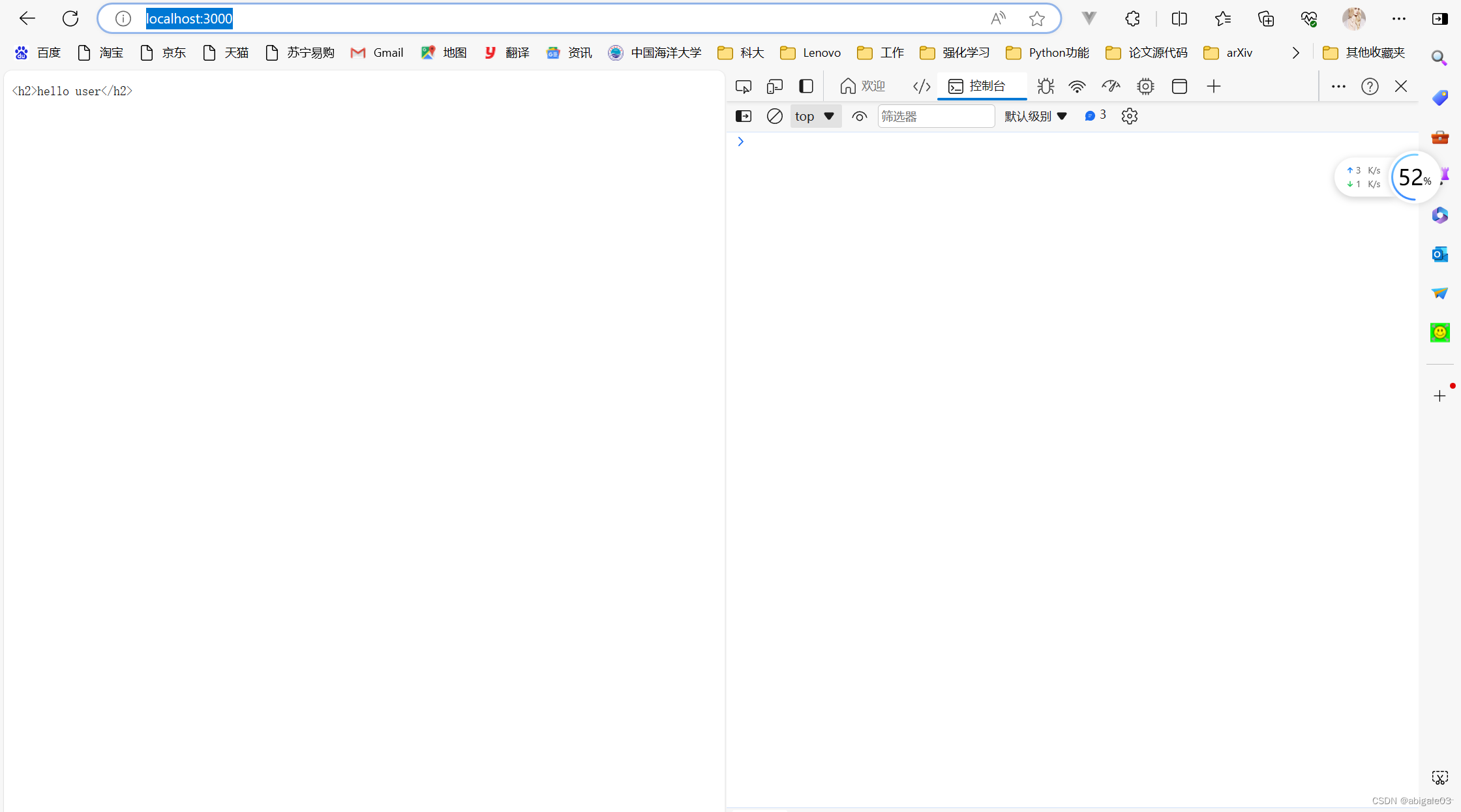
4 切换到命令行窗口中
此时有请求方式输出,是get请求。

问题:此时为什么有两个GET输出呢?实际我们只发了一个请求。
下图确实有2个请求(其实我的有4个请求)
① 第一个就是输入的localhost这个请求
② 浏览器的图标请求(浏览器自动发出的请求,也是get方式)
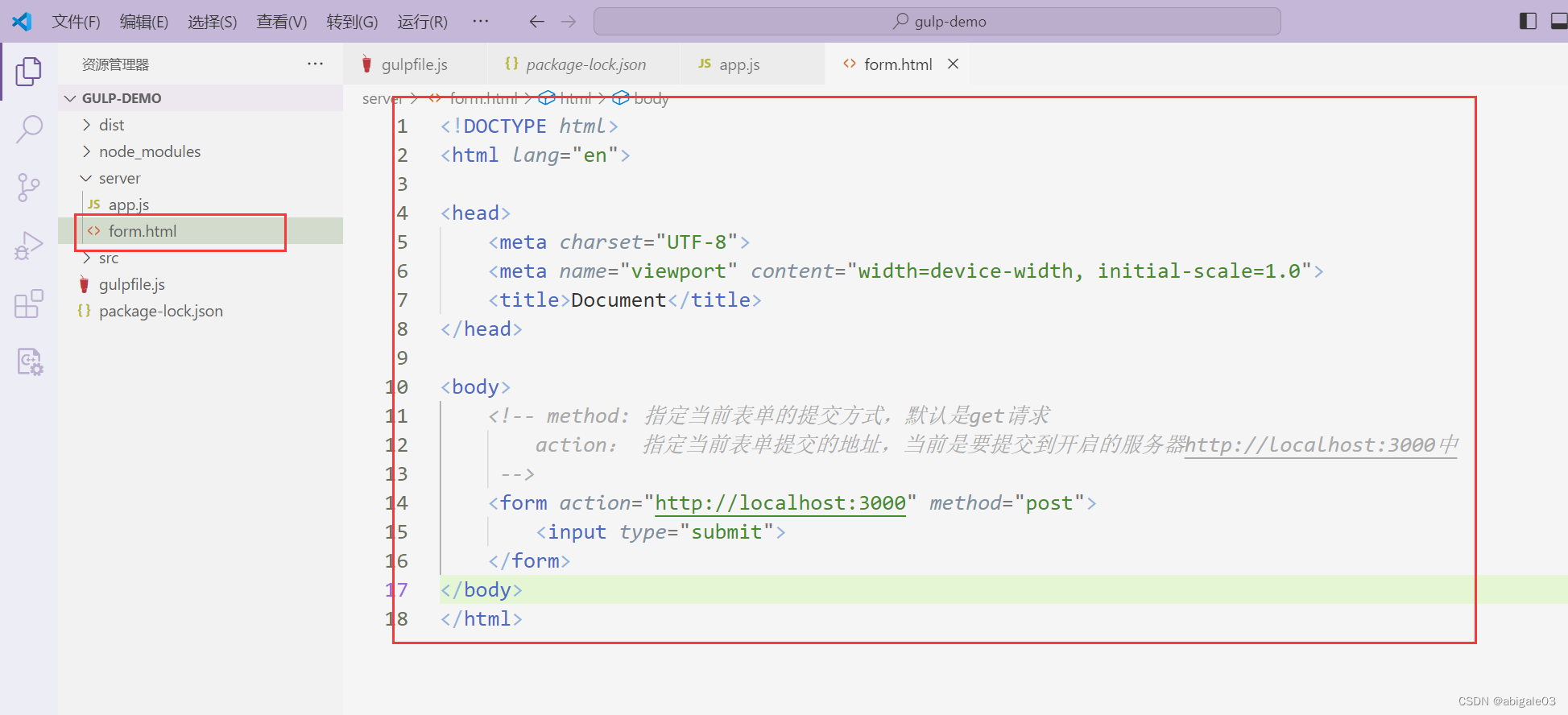
2 发送post请求
可以通过表单的方式发生post请求。
form标签。
实践
1 在server下new一个文件form.html
2 右键,在浏览器中打开
3 点击提交按钮

4 切换到命令行窗口
此时命令行窗口有post输出。证明刚才提交表单的请求是post请求。
问题:post请求后还有一个get请求?
post请求发送完成后,紧接着表单发生了默认行为,而默认行为是表单的跳转行为。而表单的跳转行为默认是get方式。因此命令行在post请求打印后又输出了get方式。

总结:通过地址栏输入网址发送的请求是get请求。通过表单发送post请求。
问题:服务器拿到get和post请求有什么用呢?
3 服务器处理不同请求
通过req.method判断客户端的请求是get还是post请求。
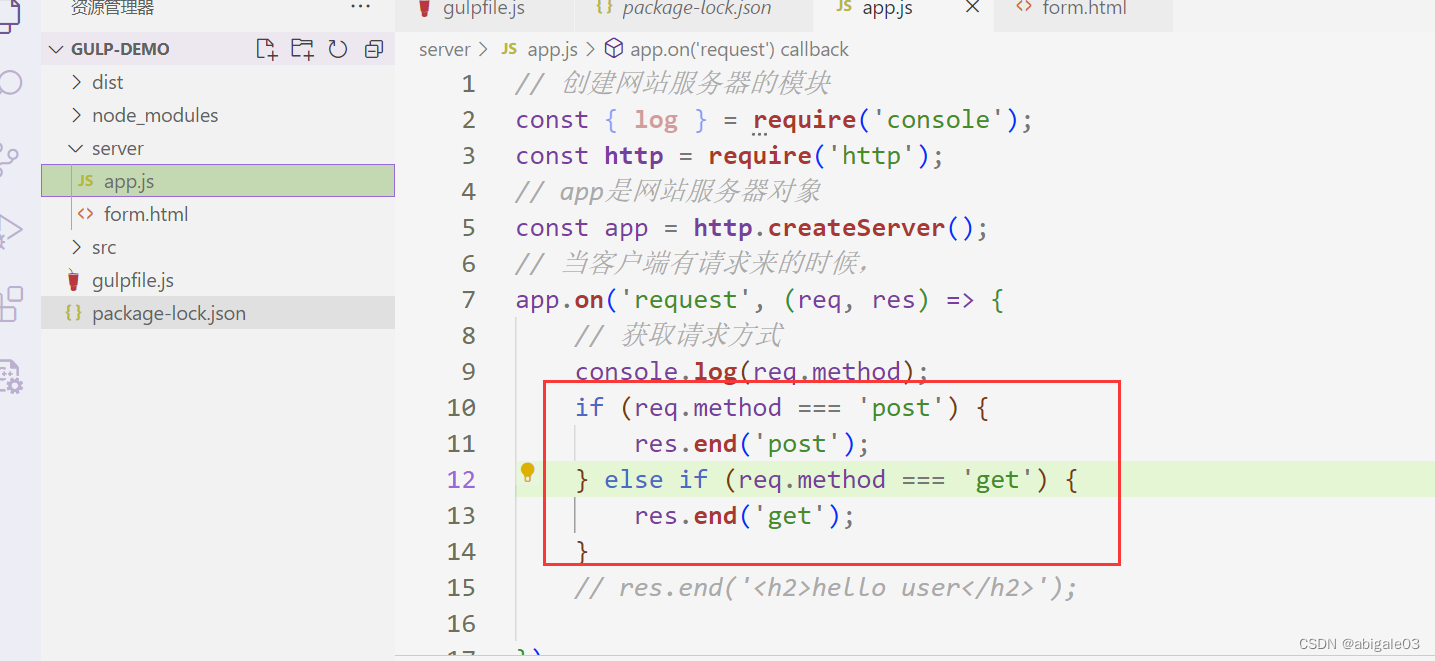
2 请求地址
req.headers 获取请求报文
req.url 获取请求地址
req.method 获取请求方法
1 获取请求地址
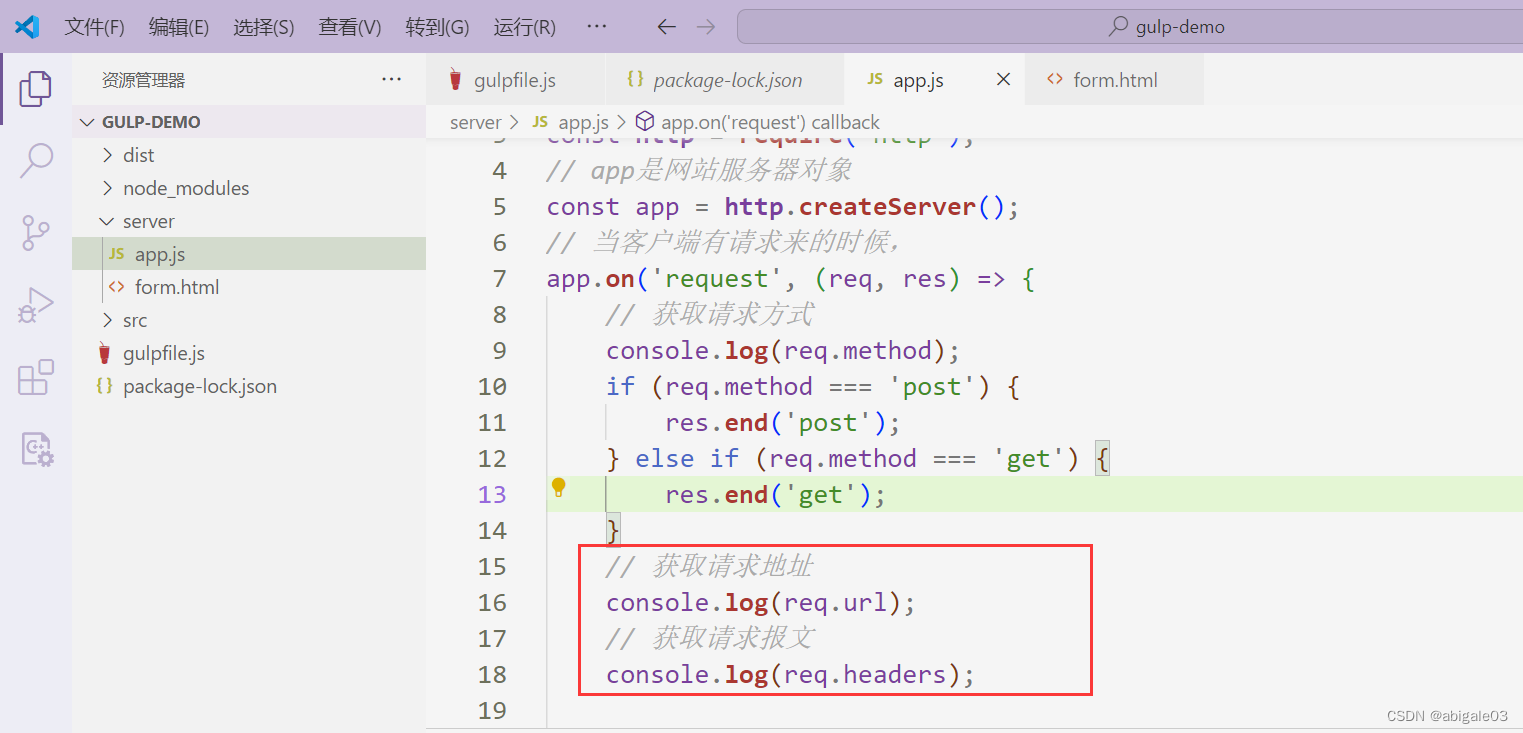

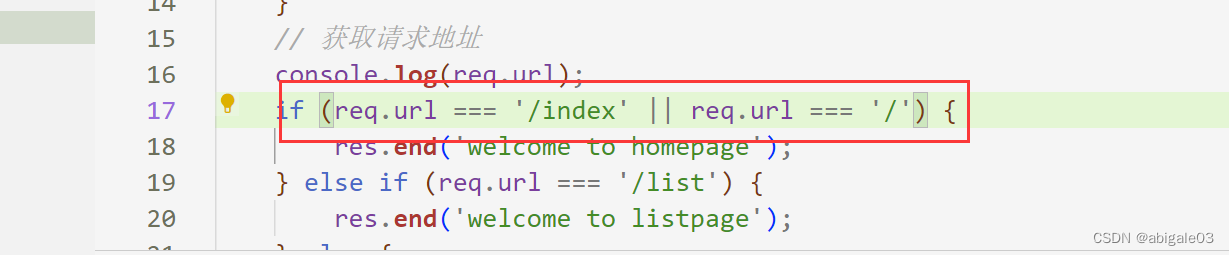
url请求地址,实际上是个标识,服务器根据url为客户端响应不同的地址。具体如何做?做判断。
判断url
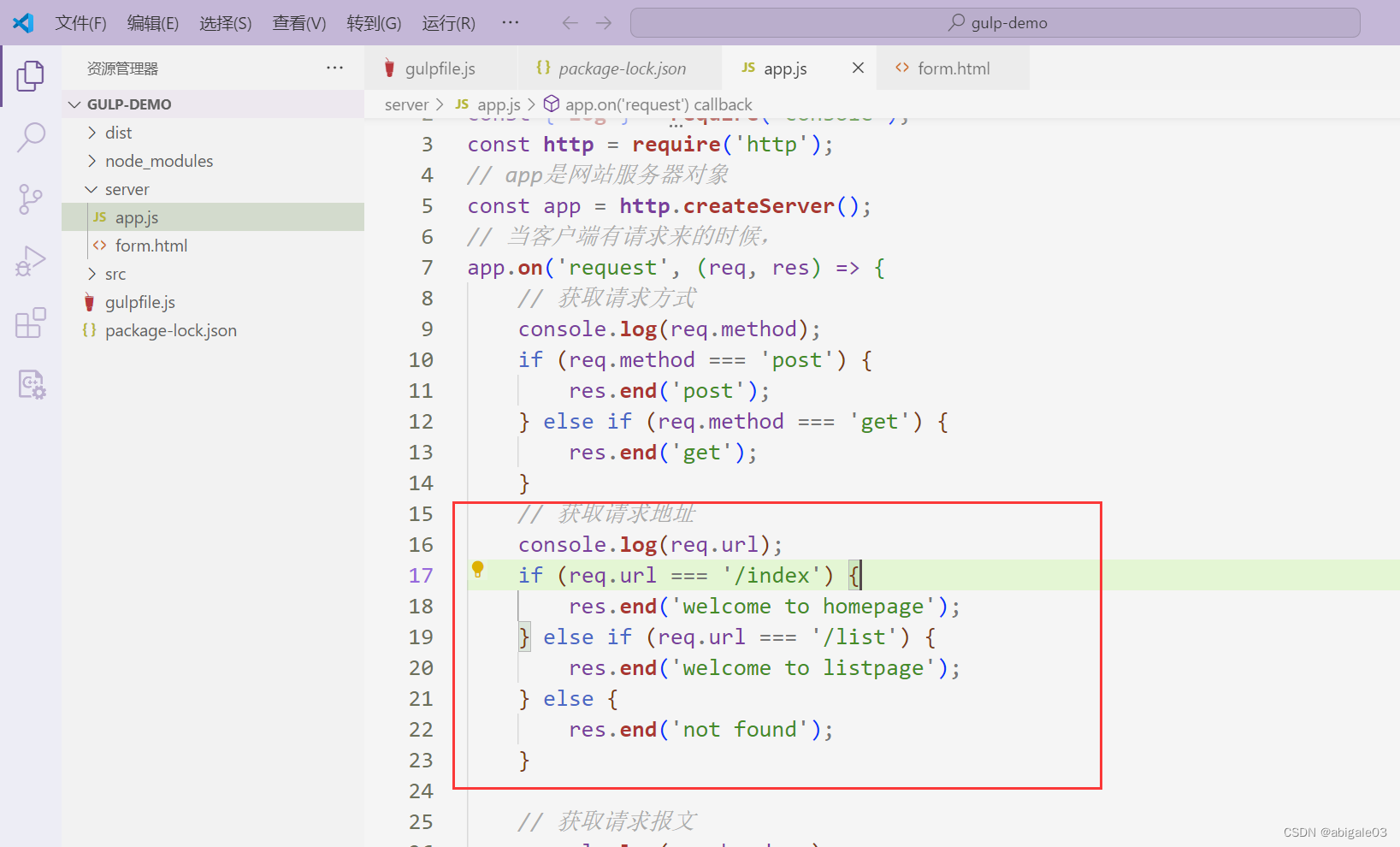
效果
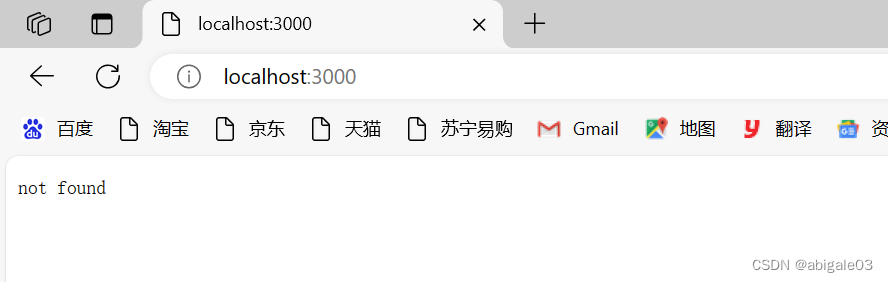
1 url为空或不存在的地址
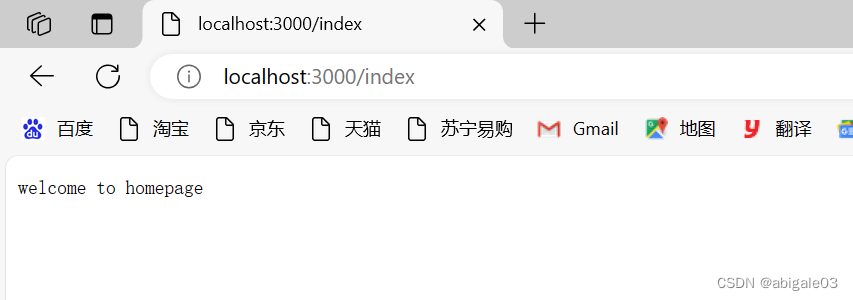
2 url为/index
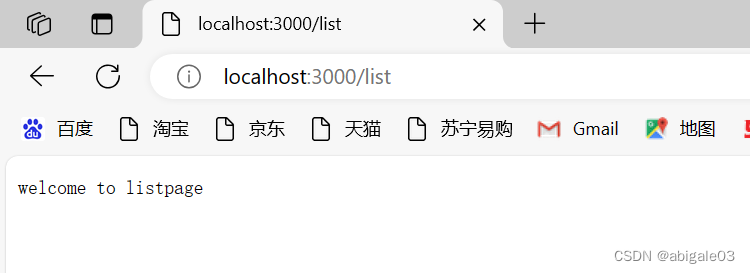
3 url为list
问题:如果客户端在请求时没有输入请求地址,那么服务器端获取到的请求地址是什么?
是一个斜杠。
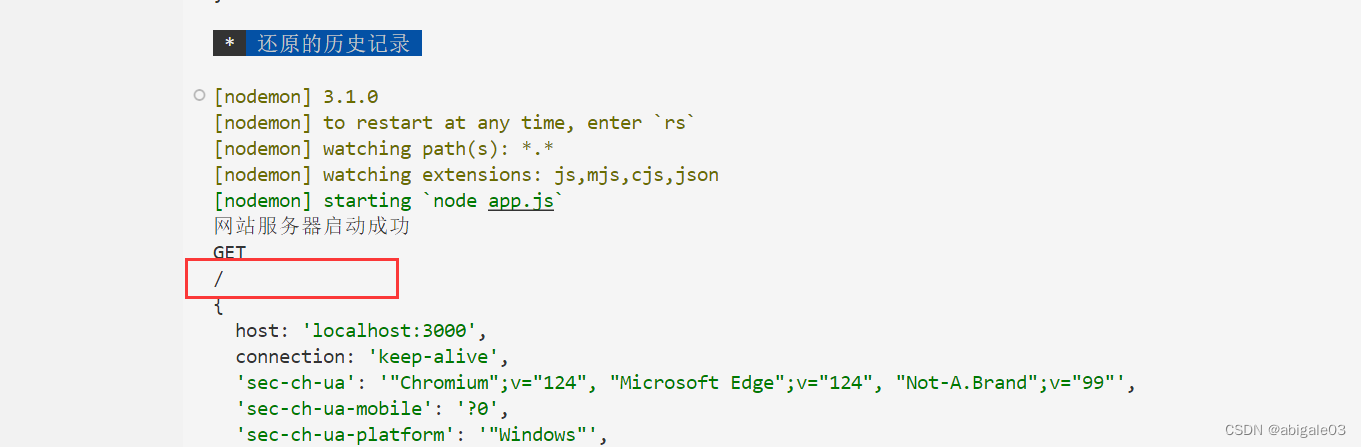
斜杠有什么用呢?
一般而言,在访问一个网址时,默认显示首页。此时按照前面的逻辑,服务器端会返回not found。
但是希望不输入请求地址,显示首页。
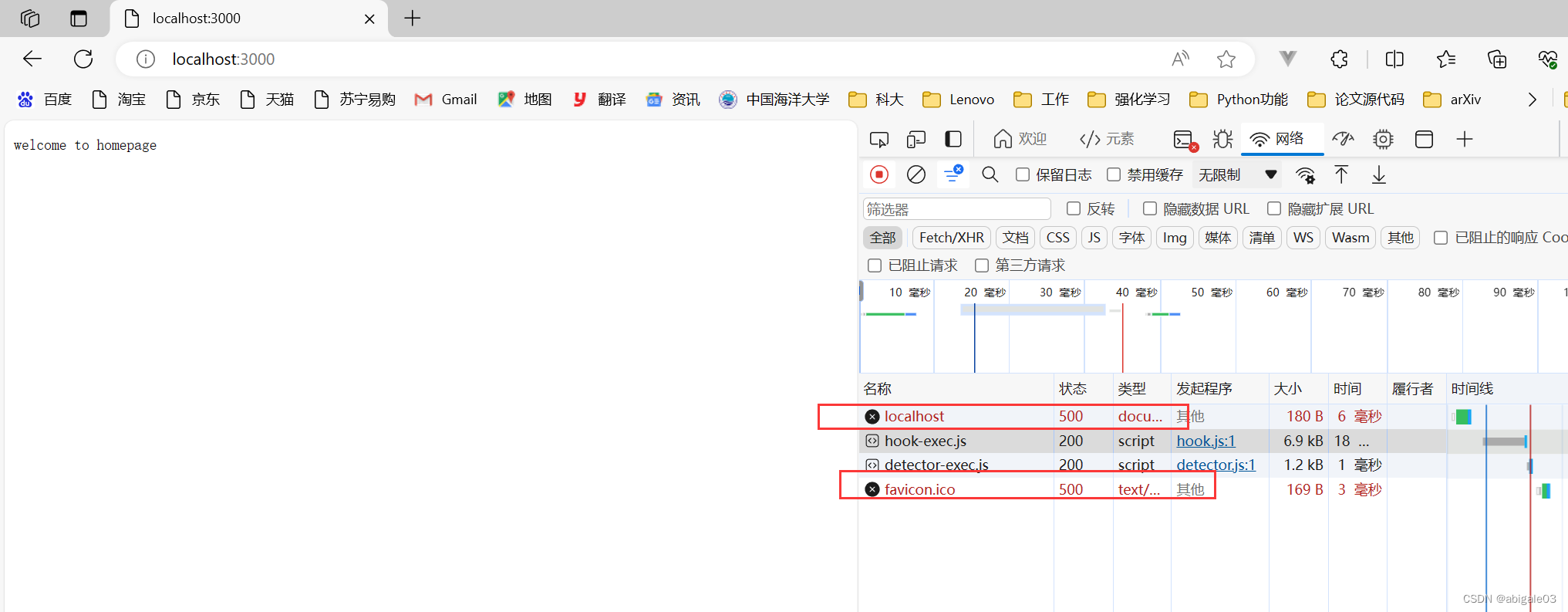
如下图,补充条件,当url是 / 时,服务器端返回首页(这里用homepage表示首页)
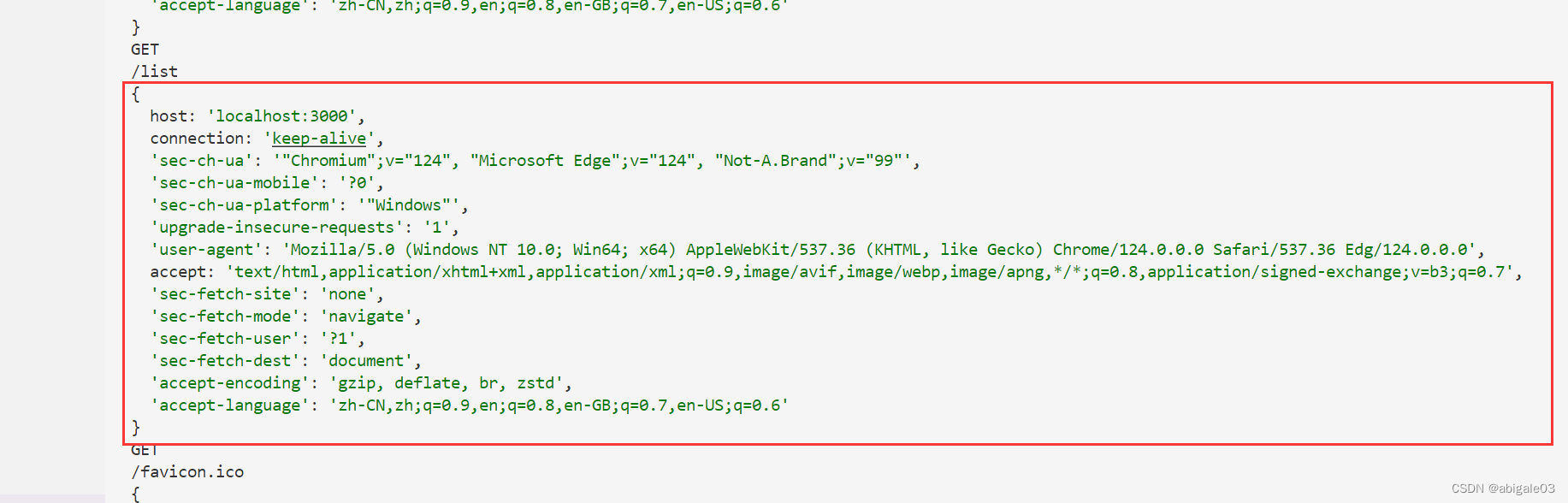
2 获取请求报文
req.headers,获取请求报文
示例
获取其中某项
两种写法
req.headers.accept;
req.headers['accept'];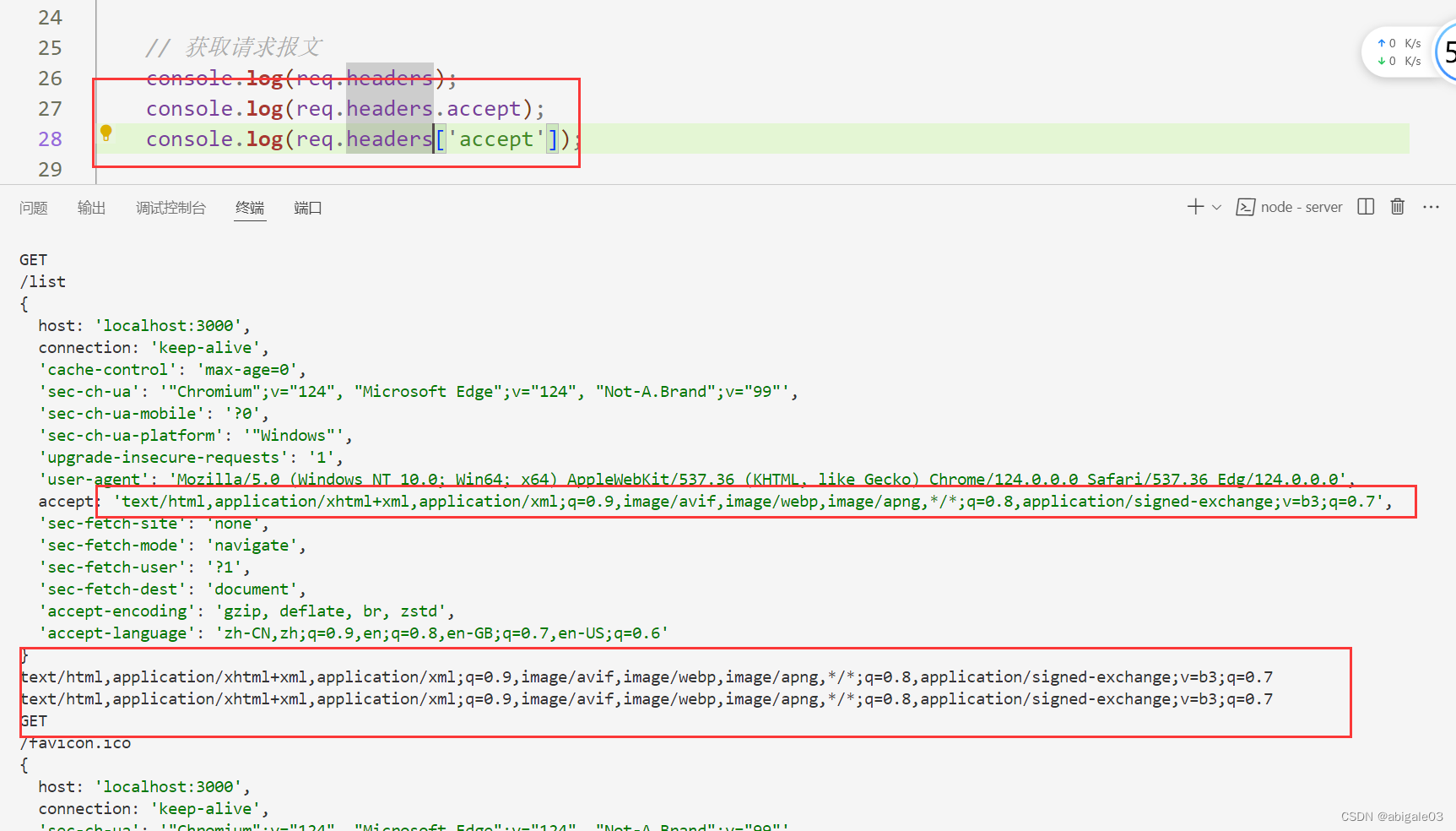
11.2.2 响应报文
服务器端对客户端进行响应时携带的数据块,即服务器端对客户端发的消息。

对于客户端每次请求,服务器端都要给予响应。
在响应时,服务器都要告诉客户端当前请求的结果(成功还是失败)。
如何告诉客户端结果?
http状态码。
1 http状态码
- 200 请求成功
- 404 请求的资源没有被找到
- 500 服务器端错误
- 400 客户端请求有语法错误
- 比如请求路径错误或请求参数不匹配,都可以返回400错误。
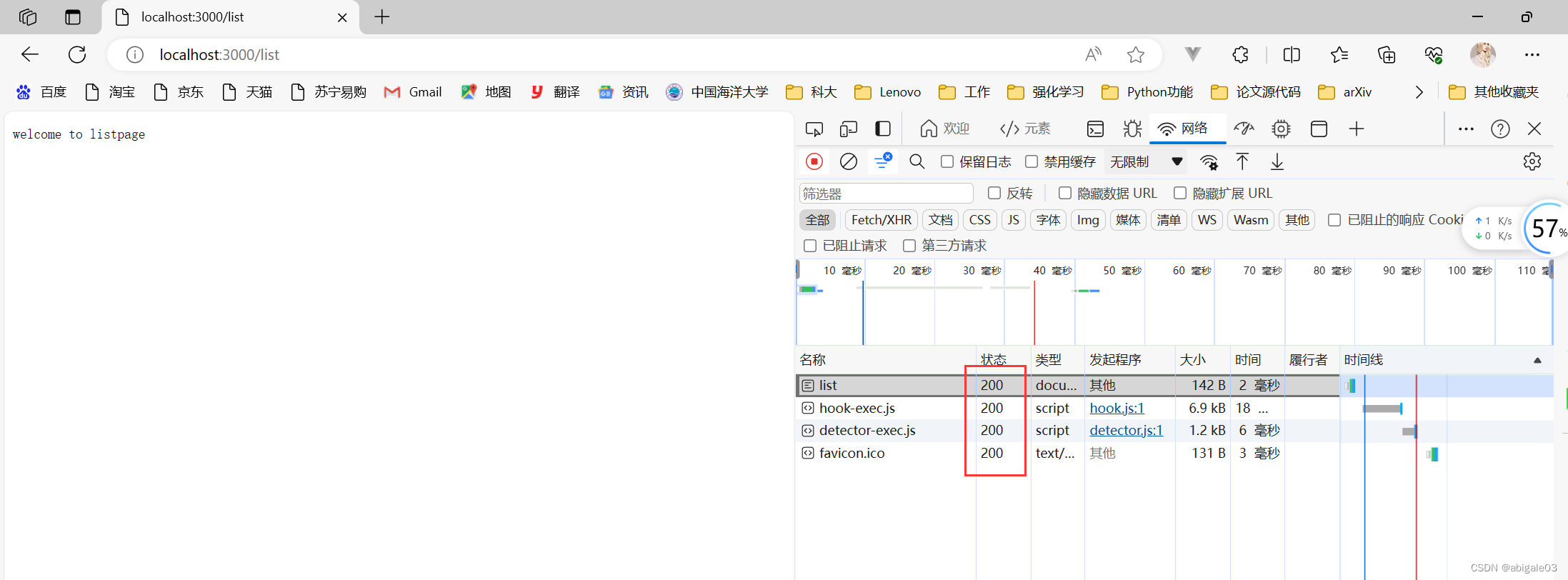
设置http状态码
res.writeHead(http状态码);示例
1 请求成功 200
2 请求失败,服务器故障 500
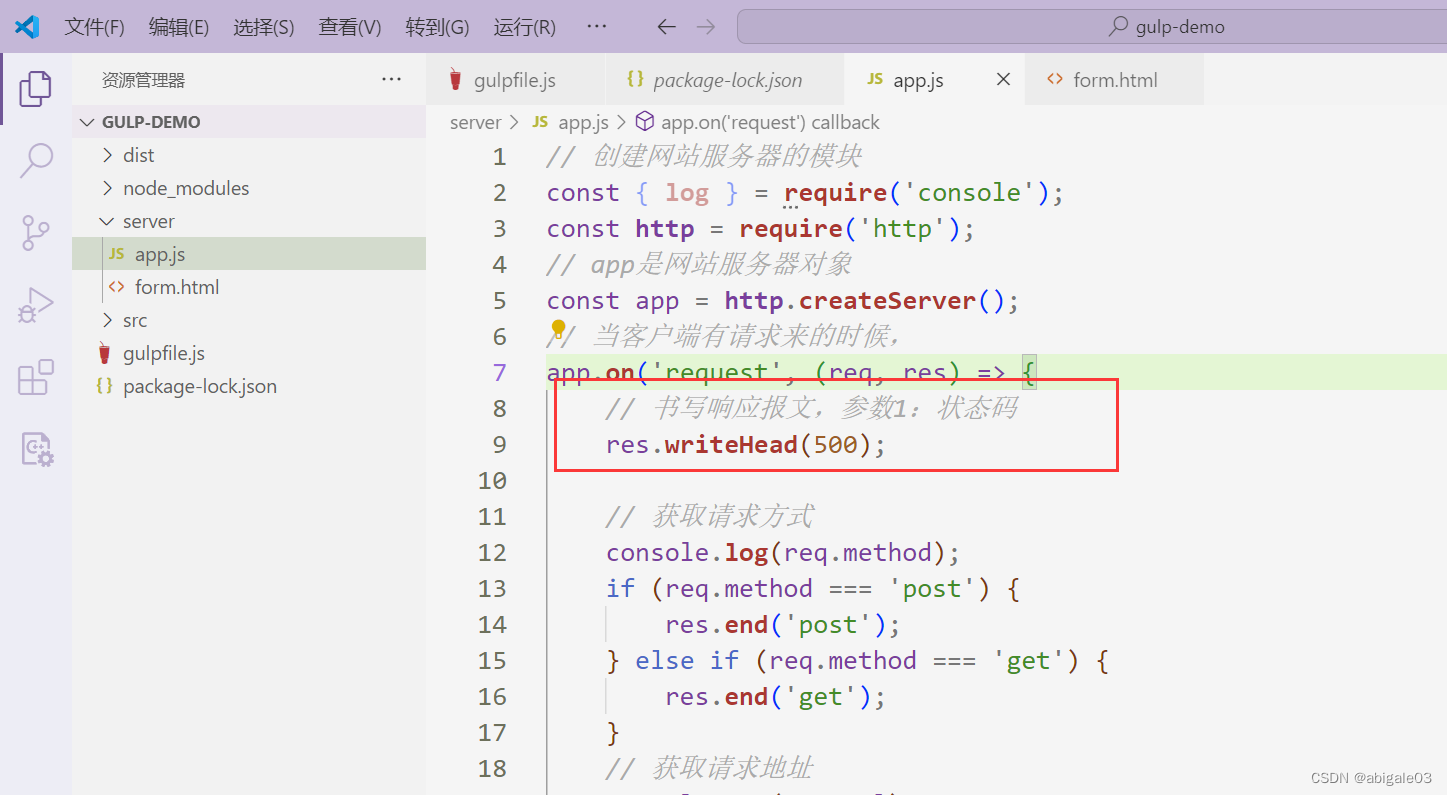
结果
3 客户端请求有语法错误 400

2 内容类型
服务器端对客户端做出响应,是有响应内容。响应内容的类型需要人为指定,可以返回文本、css文件、html文件或js文件等。每种内容都是有类型的。需要告诉客户端当前返回的内容类型,否则浏览器无法去解析文件内容。
目前,对于一些高级浏览器,不指定类型也是没问题的,浏览器会自动识别分析,而对于老的浏览器就无法做到这点,因此会出问题。
内容类型
- 纯文本,text/plain
- html文件,text/html
- css文件,text/css
- js文件,application/javascript
- jpeg文件,image/jpeg
- json文件,application/json
设置内容类型的方法
res.writeHead(http状态码,响应报文信息);
响应报文信息(对象类型),content-type(内容类型)属性。根据当前返回的内容类型去指定响应报文信息里的content-type。默认是纯文本类型,即‘text/plain’.
示例
为返回信息加h2标签
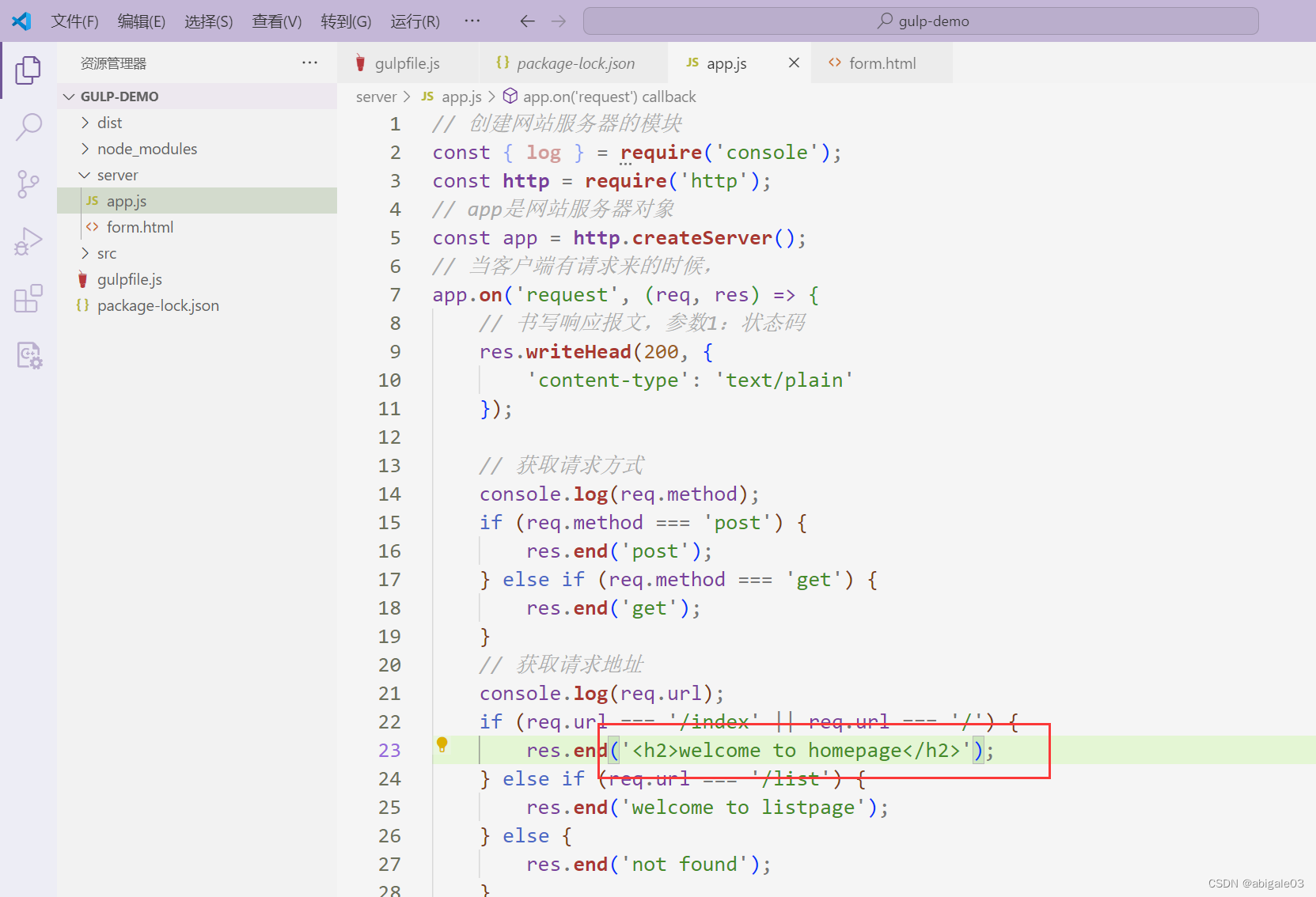
效果
原封不动显示出<h2>标签。

原因:因为指定的内容类型是text/plain,即返回一个纯文本。这里浏览器将<h2>也当做纯文本展示。
解决:要想让浏览器就解析h2标签,需要指定内容类型是html文件。告诉浏览器,服务器当前返回的是html文本内容。
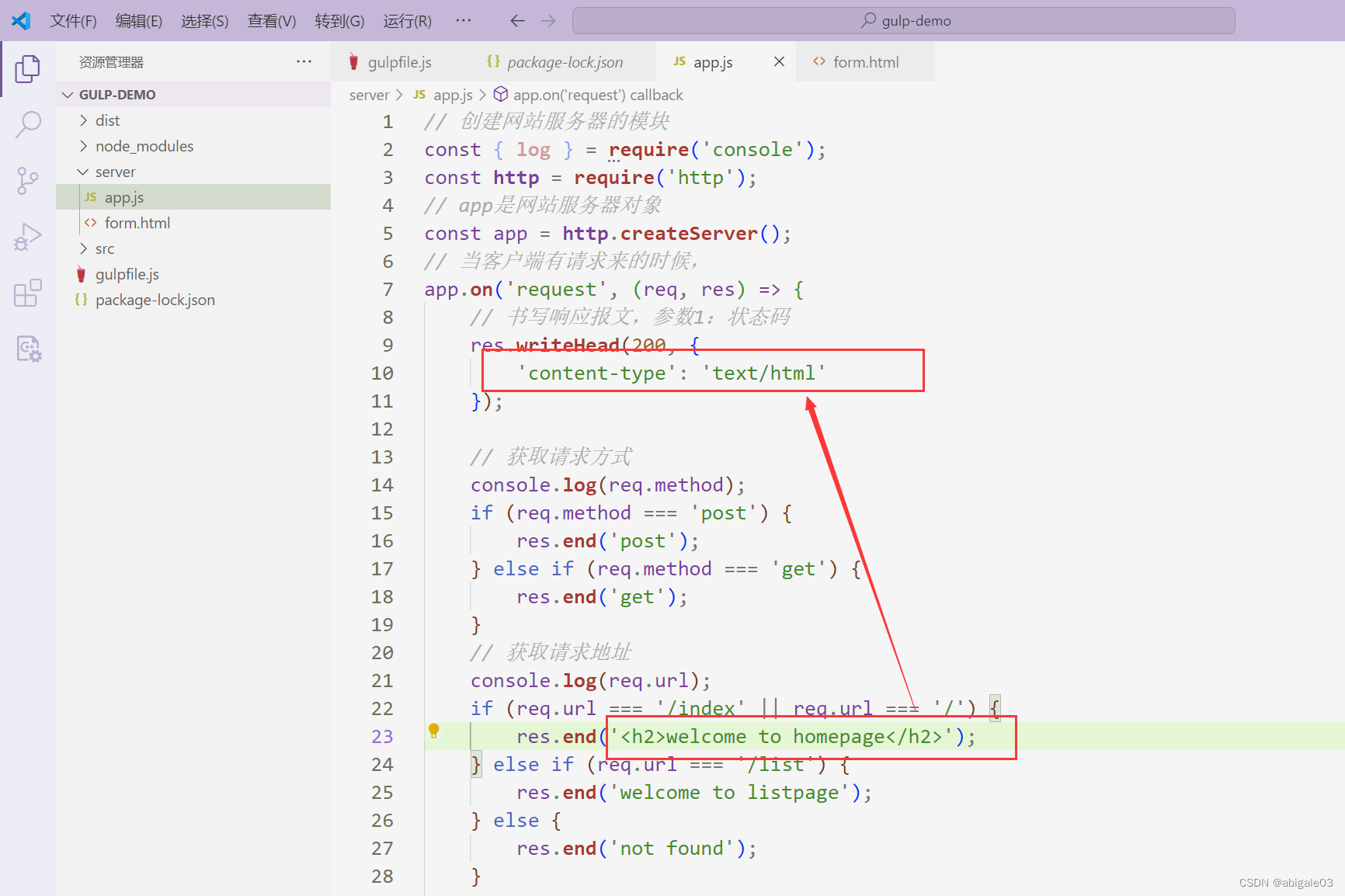
效果
此时h2就被解析出来了。
问题:将返回的信息改为中文。
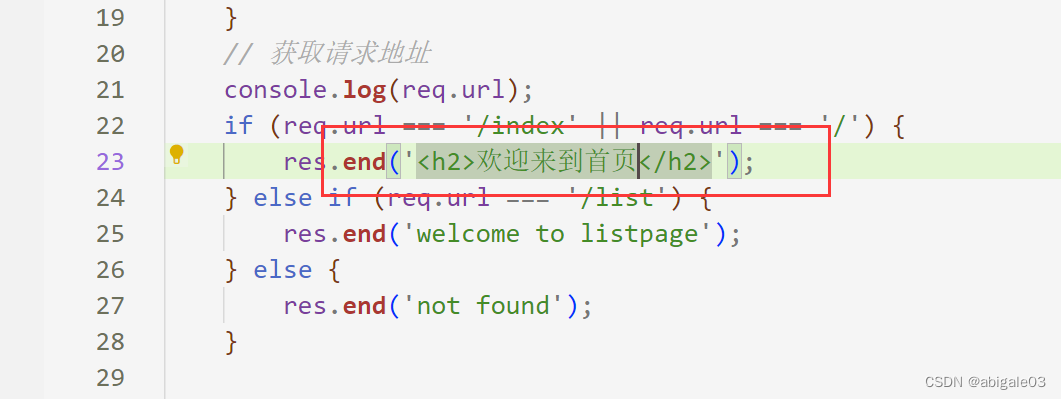
效果
显示乱码文本。
解决:服务器需要告诉浏览器当前返回的文本的编码类型。
在做网页开发时,编码一般是utf8。
指定编码类型

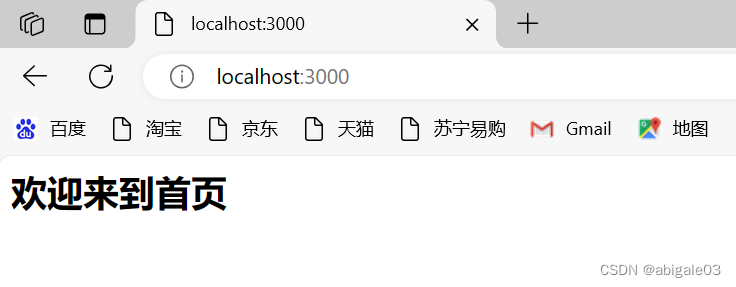
效果
乱码的问题就得到解决了。
12 HTTP请求与响应处理
12.1 请求参数
客户端向服务器端发送请求时,有时需要额外携带一些客户信息,客户信息需要通过请求参数的形式传递到服务器端。
比如登陆操作,客户端需要将用户名和密码传递到服务器端。
比如在网站后台发布一些文章信息,在表单输入标题,文章发布日期,文章封面以及文章内容。这些在表单中输入的信息也是通过请求参数传递给服务器端的。
12.2 GET请求参数
get请求,请求参数在地址栏中进行传输。
12.2.1 请求携带参数
- 参数被放置在浏览器地址栏中,例如:http://localhost:3000/?name=zhangyuyao&age=18
- 1 ?表示后面是要额外携带的数据
- 2 额外携带的数据就是键值对。
- 键值对以等号进行分隔
- 传递多个数据,以&进行分隔
- 3 服务端器端获取请求参数,需要通过字段去获取值。
示例
服务器端输出一下req的url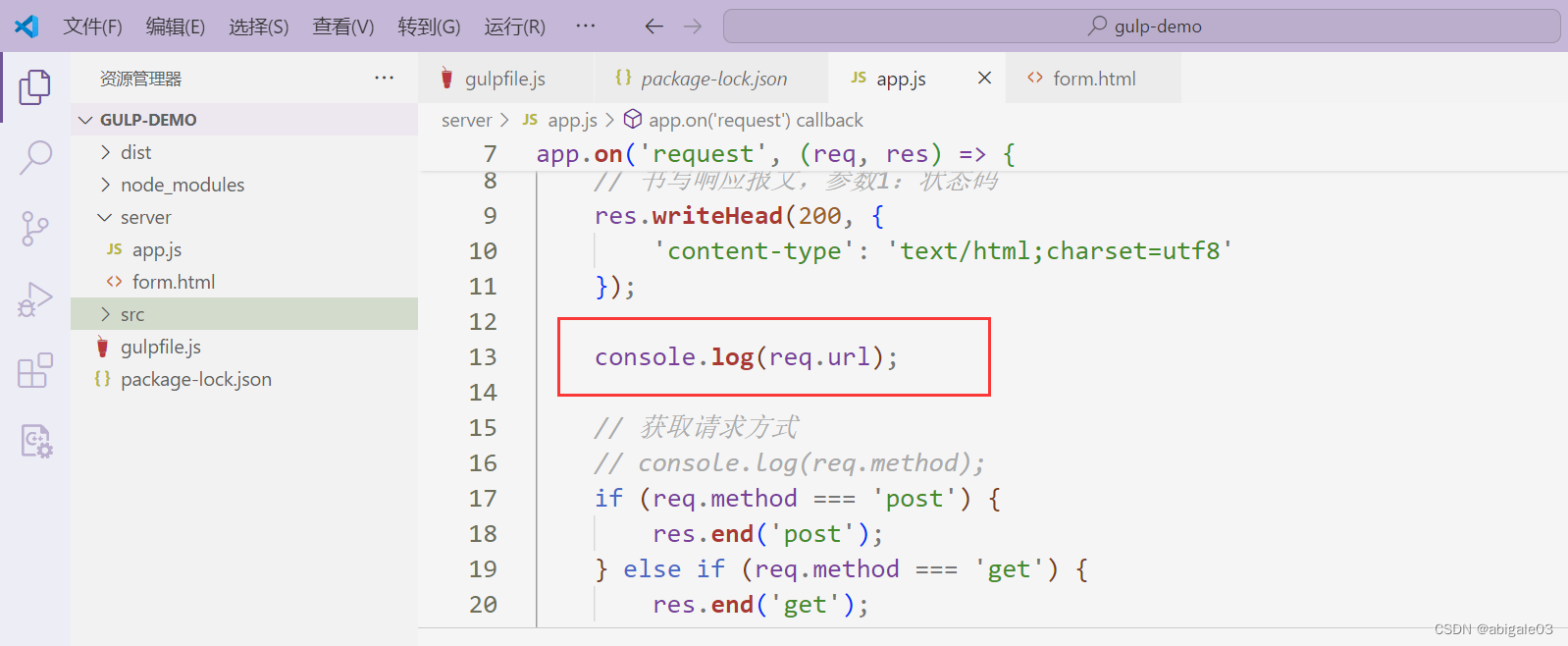
浏览器访问index路径,且携带参数

此时没有此页面,且服务器返回not found信息。
切换到服务器
控制台打印出该请求的url,在url里包含了请求携带的参数。

12.2.2 获取请求参数
url.parse(要解析的url地址, 是否将请求参数转换为对象形式);
从req.url里如何获取name和age的值呢?
思路:通过字符串截取可以获得name和age的字段值。
简单方式:Node.js提供了内置模块url模块,可以通过内置模块的方法处理请求参数。
parse:解析
1 引入url模块
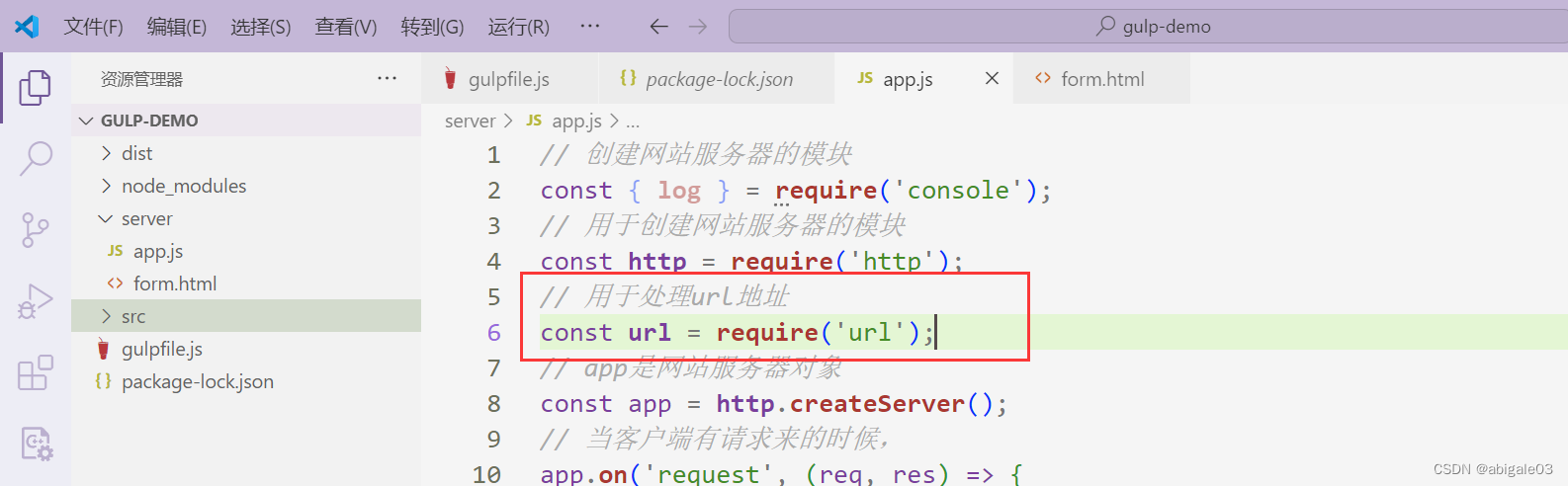
2 使用url.parse方法

3 浏览器输入请求地址或刷新浏览器
4 服务器控制台打印结果
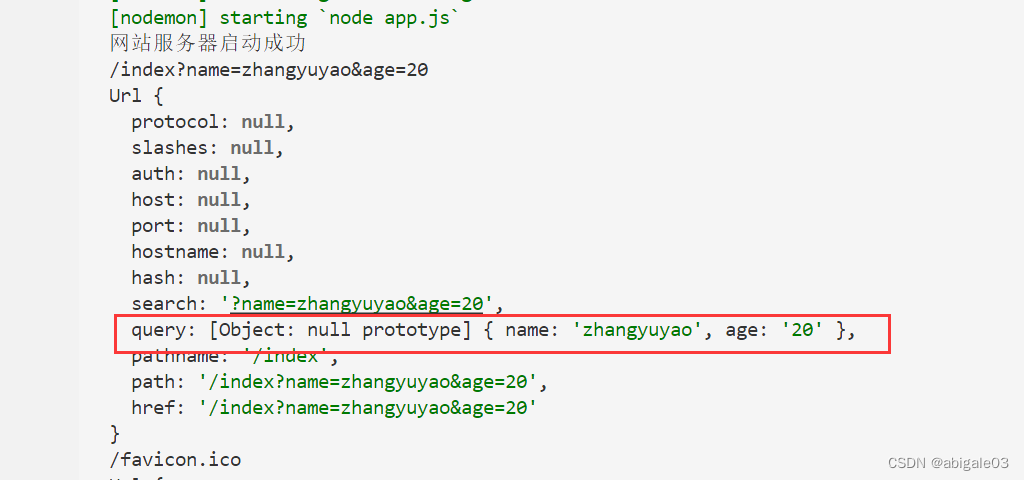
url.parse方法返回一个对象。
- search:代表查询参数
- query:与search差不多
- pathname:请求地址
返回的这个对象格式还是不方便。
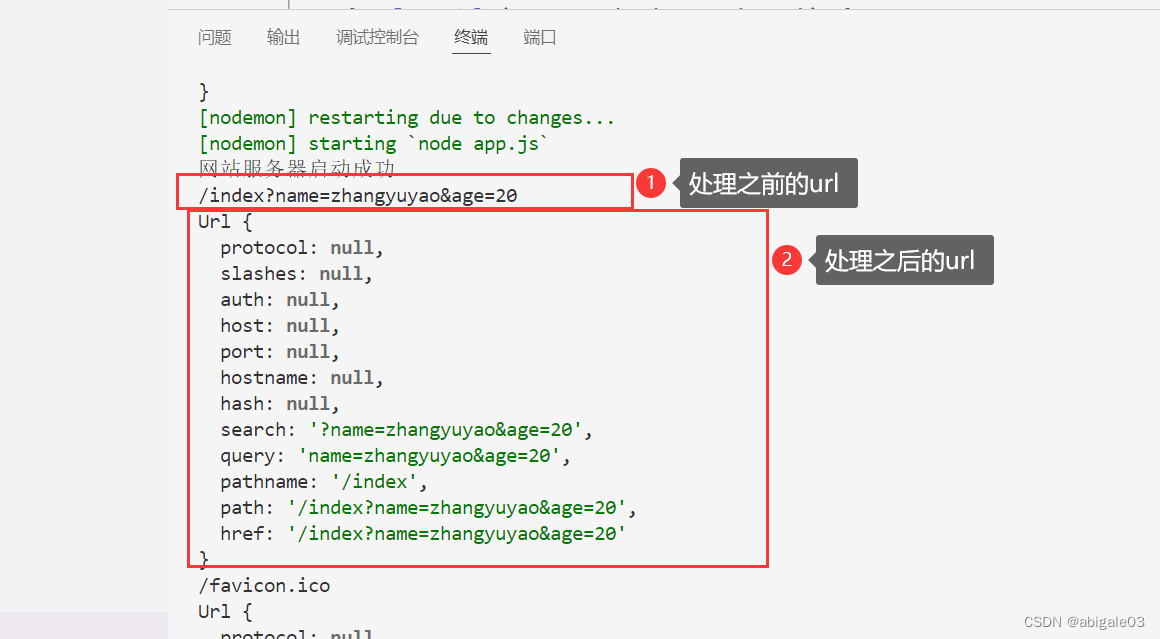
问题:如何将请求参数转换为对象呢?
解决:写入第二个参数,true,将查询参数转为对象的形式。
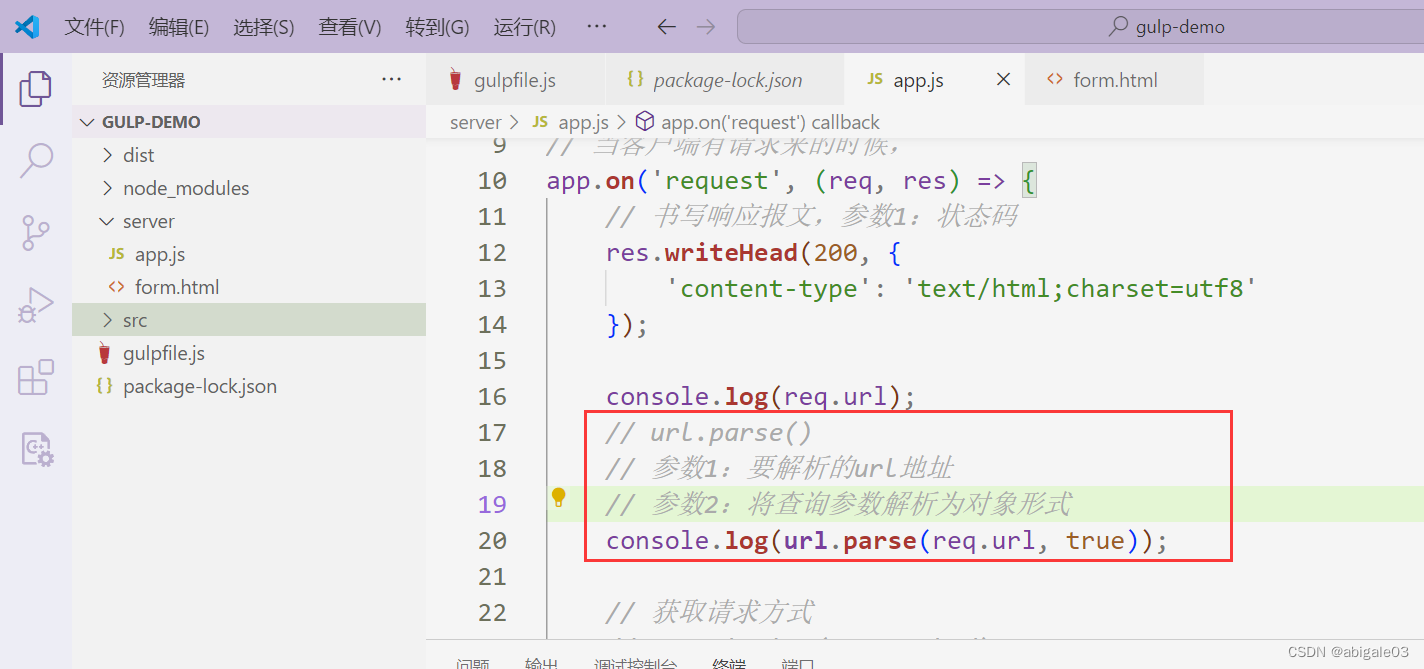
效果
此时query已经是对象形式。
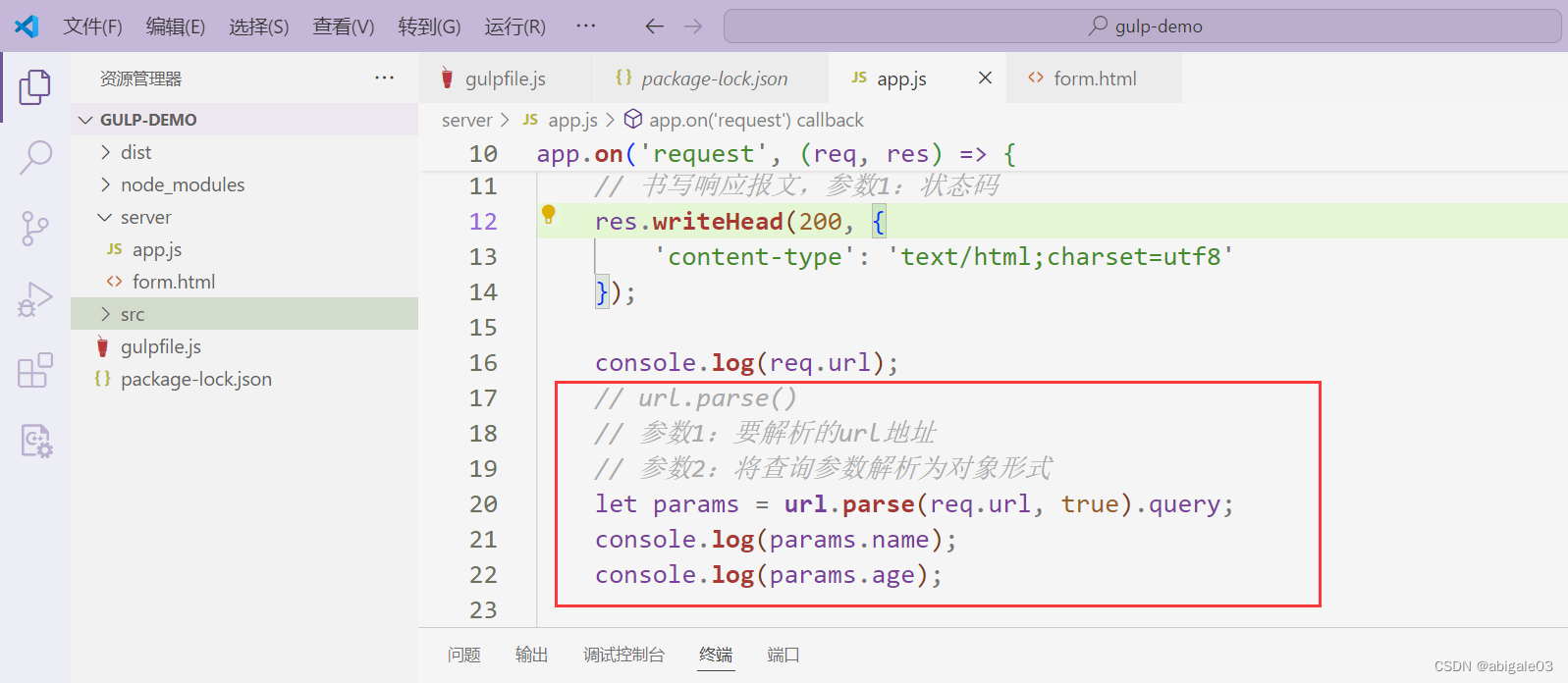
获取query值。
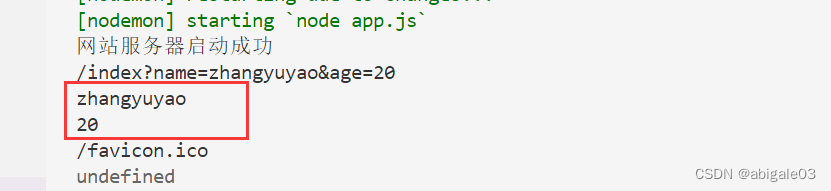
结果
注意:
再判断请求路径,就不能单纯的用req.url去做判断了,可以使用url解析后的对象的pathname(存储的是客户端不包含请求参数的请求地址)去判断。
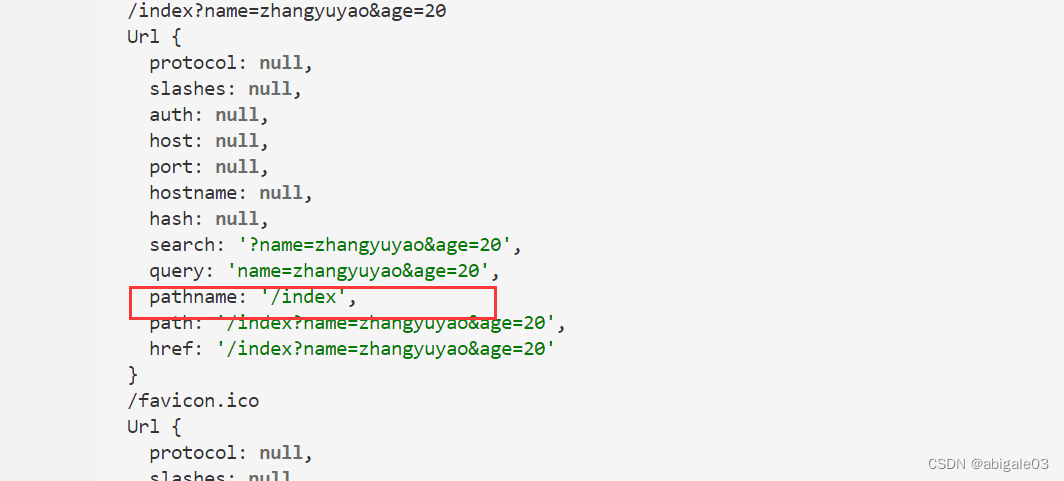
解构赋值,分别获取请求参数(对象形式)和请求地址(不带请求参数的地址)。服务器直接根据pathname去对请求的路径进行判断,返回不同的结果。
结果
12.3 post请求参数
- post请求,请求参数不在地址栏中,而在请求报文(请求体)中。
- 获取post参数需要data和end事件。获取get参数需要req.url方法。
- post参数转换为对象类型,使用内置模块querystring的parse方法。
12.3.1 发送请求参数
填写表单并点击提交按钮。

表单数据,存储了请求参数。
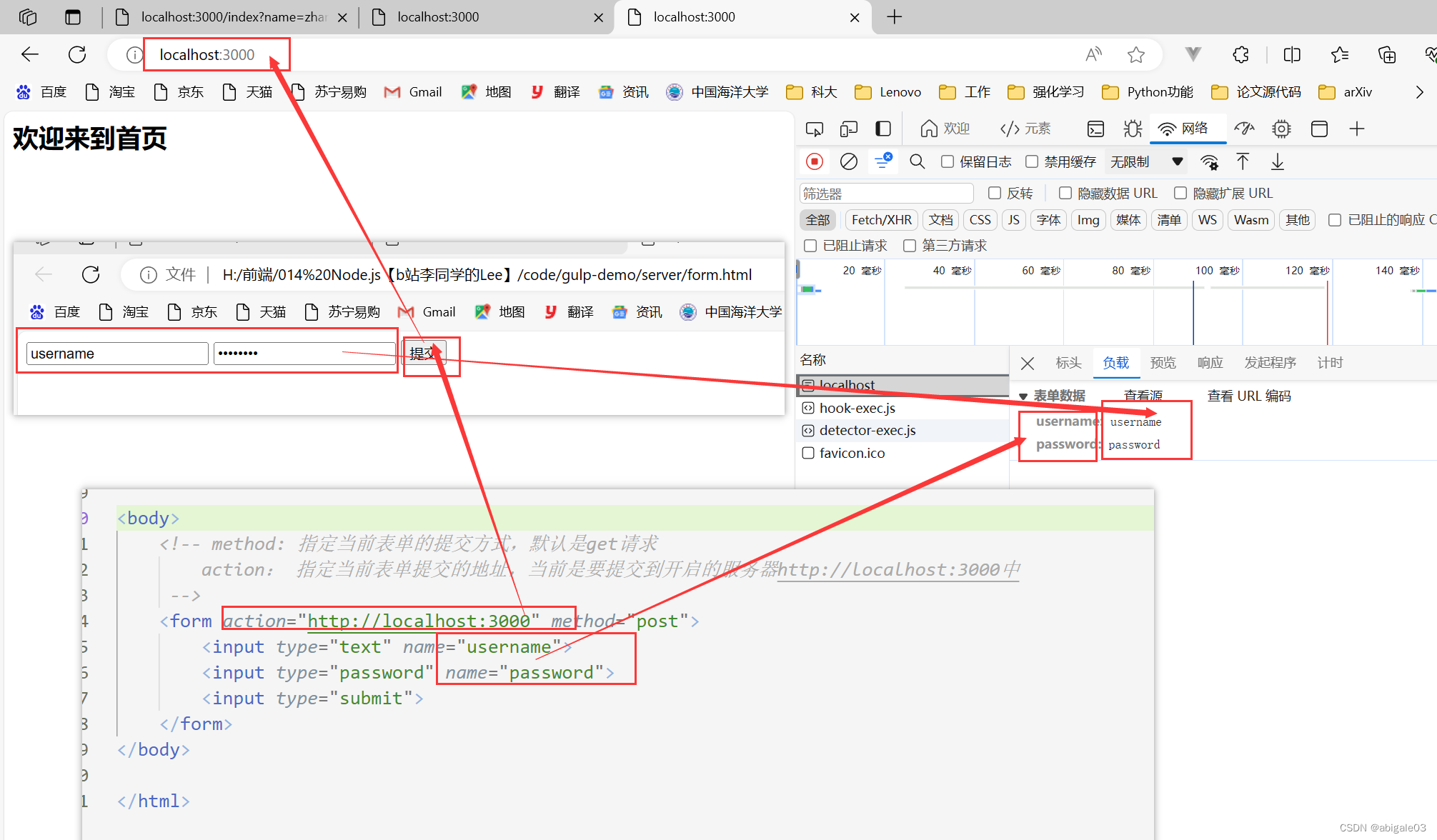
这里对post参数做了下显式优化。
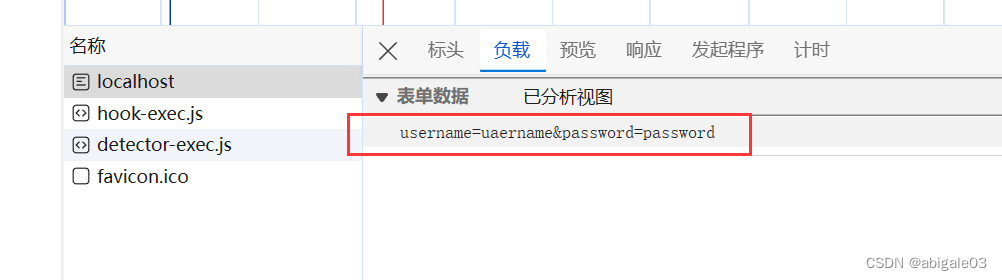
无论post还是get参数,格式都是相同的。
下图,post请求参数与get请求参数格式是相同的,只是get请求参数放在url后,并用?分隔。
12.3.2 接收请求参数
服务器接收post请求参数。
post参数理论上数据量可以是无限的。作为服务器,为减轻压力,post参数不是一次就接收完的。
比如传100M的数据,可能分为10次接收,每次只会接收10M数据。
当有请求参数传出时,会触发data事件。当请求参数传递完成时,会触发end事件。
问题:给谁绑定事件?
请求参数也是请求相关的信息,因此要给req对象绑定事件。
注意:对于客户端每次请求,服务器都要做出响应,否则客户端都处于等待状态。
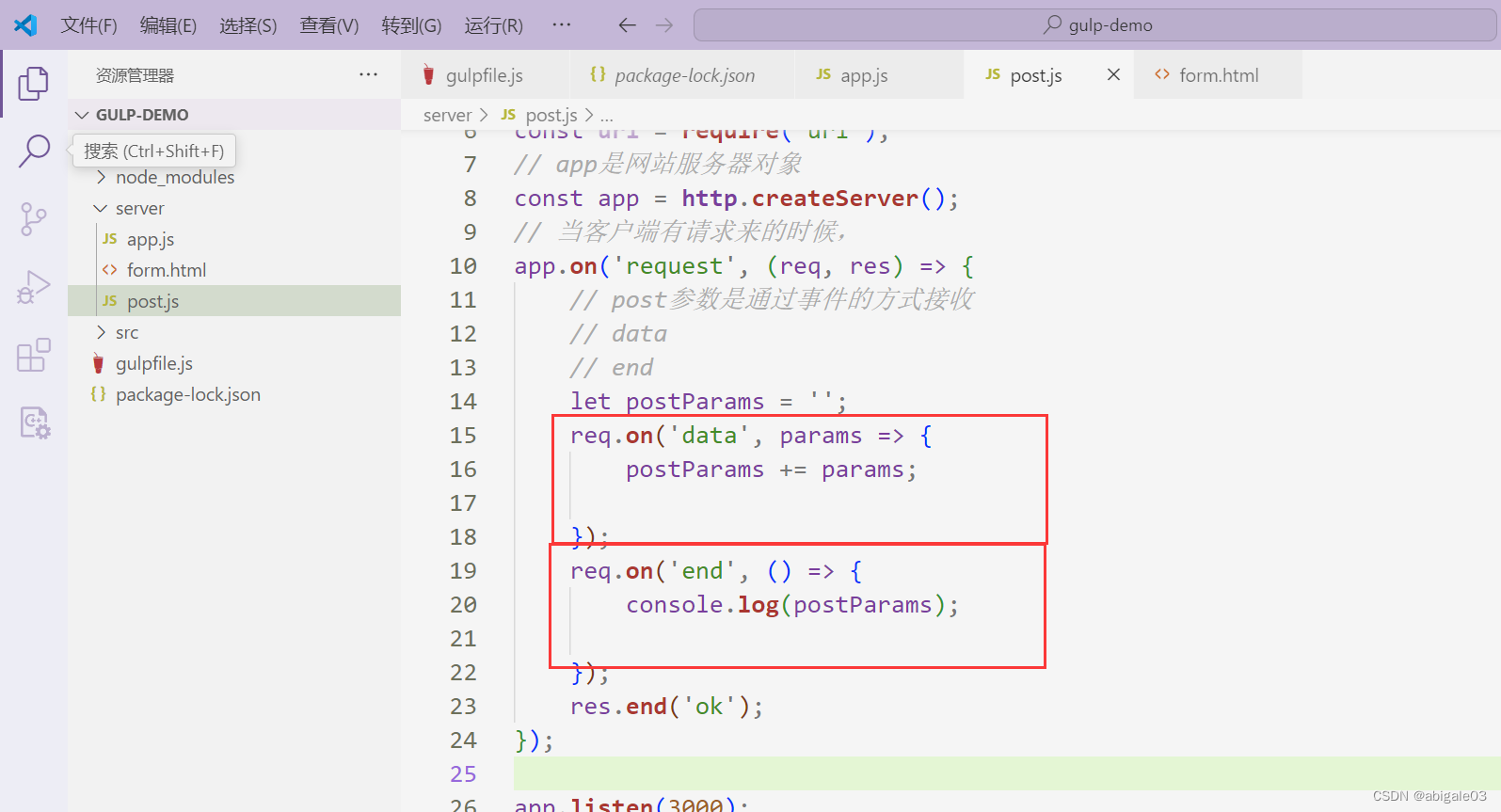
1 服务器给req绑定事件,接收post请求参数
data事件接收请求参数,end事件打印服务器接收到的请求参数。
2 浏览器填写表单并提交
3 服务器控制台打印结果
服务器接收到的参数还是字符串形式。

此时还能使用url模块转换成对象格式吗?
注意:url模块是专门用于处理请求地址的,而此时只是一个字符串,此时是不适合的。
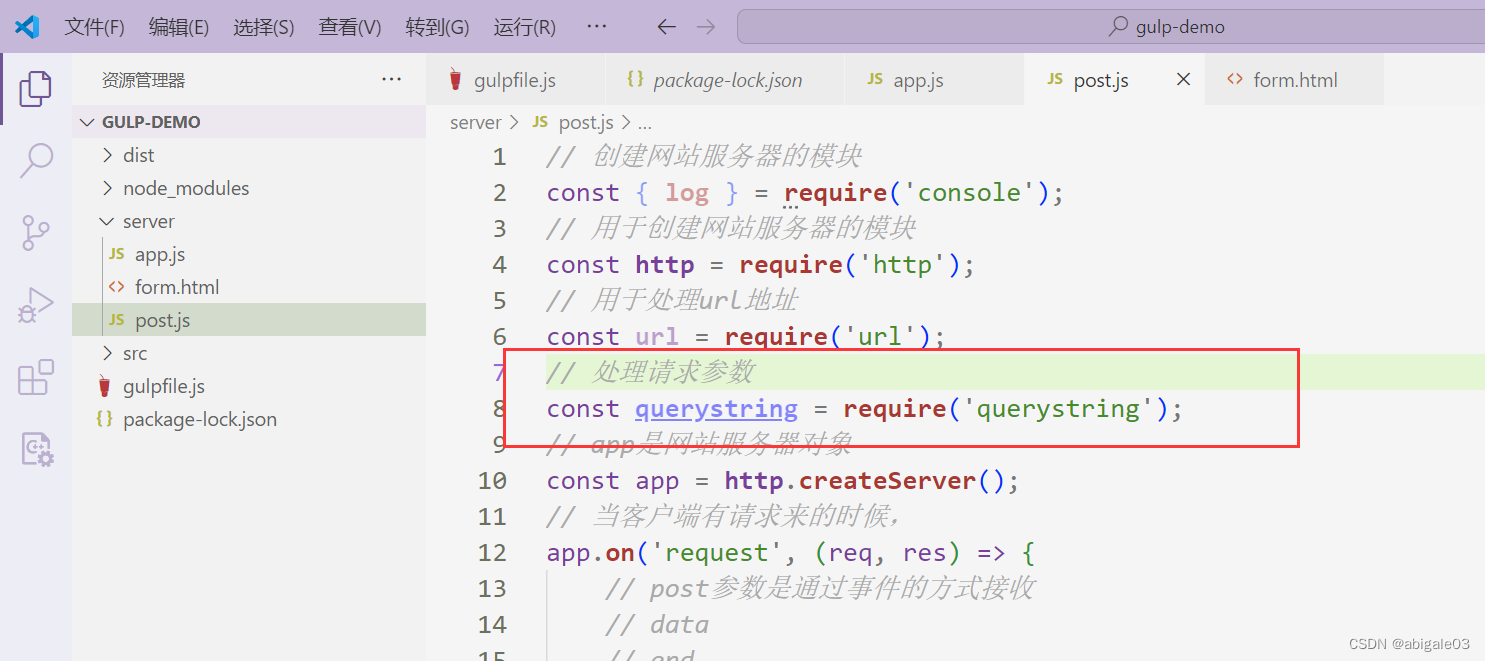
注意2:Node.js提供了一个内置模块用于处理此格式的字符串,内置模块querystring。
4 引入内置模块querystring
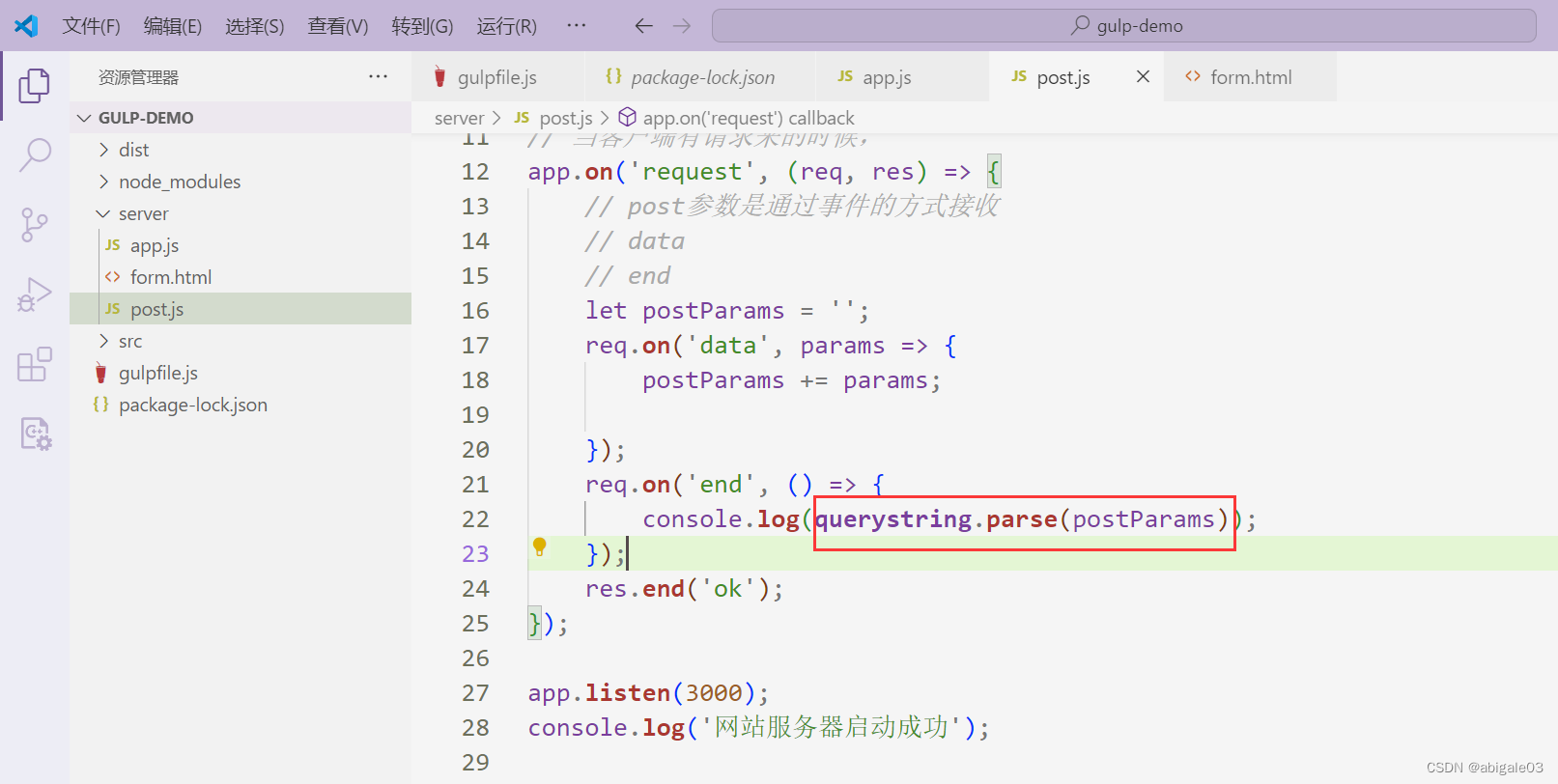
5 调用querystring的parse方法解析请求参数
方法也是返回一个对象。
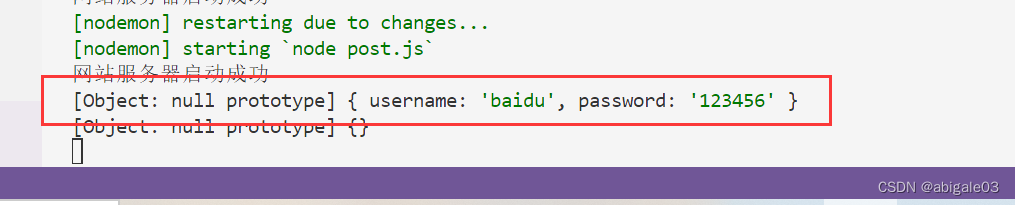
6 浏览器填写并提交表单
7 查看控制台结果
此时有一个对象,对象里存储请求参数。
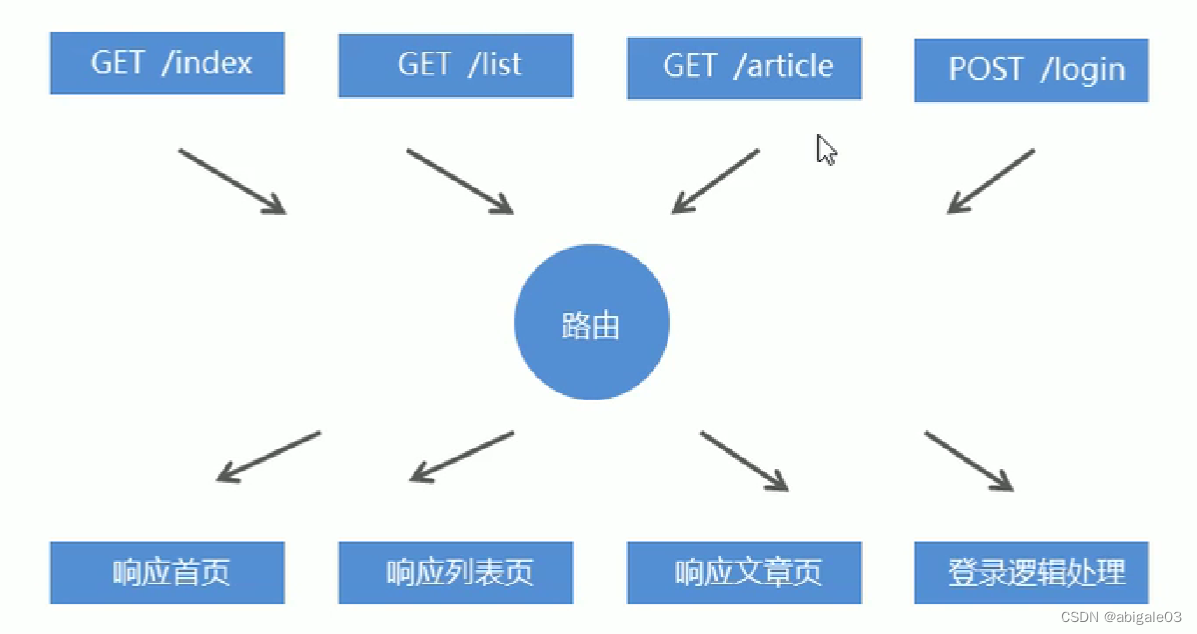
12.4 路由
在一个完整的网站应用中,用户在网站浏览器的地址栏中输入不同请求地址,服务器端会为客户端响应不同的内容。
比如访问地址 /index,会得到首页内容;访问地址 /login,会得到登录页内容。
这是怎么做到的呢?
在网站应用中,通过路由可以做到上述事情。
12.4.1 路由
路由是指客户端请求地址与服务器端程序代码的对应关系。简单说,就是客户端请求什么服务器端响应什么。
客户端请求地址:即浏览器地址栏输入的请求地址。服务器端程序代码,实际就是请求地址所对应的处理逻辑。
比如说客户端访问 /index 这个地址,服务器端为客户端响应首页内容,这里的响应就是服务器端首页代码。
下图,路由上方是客户端的请求地址和请求方式,下方是客户端请求地址对应的服务器端处理代码。两者要进行匹配和对应,就需要路由。
实际上路由就是一段判断代码,判断客户端请求的地址是什么,然后调用服务器端程序对应的代码。
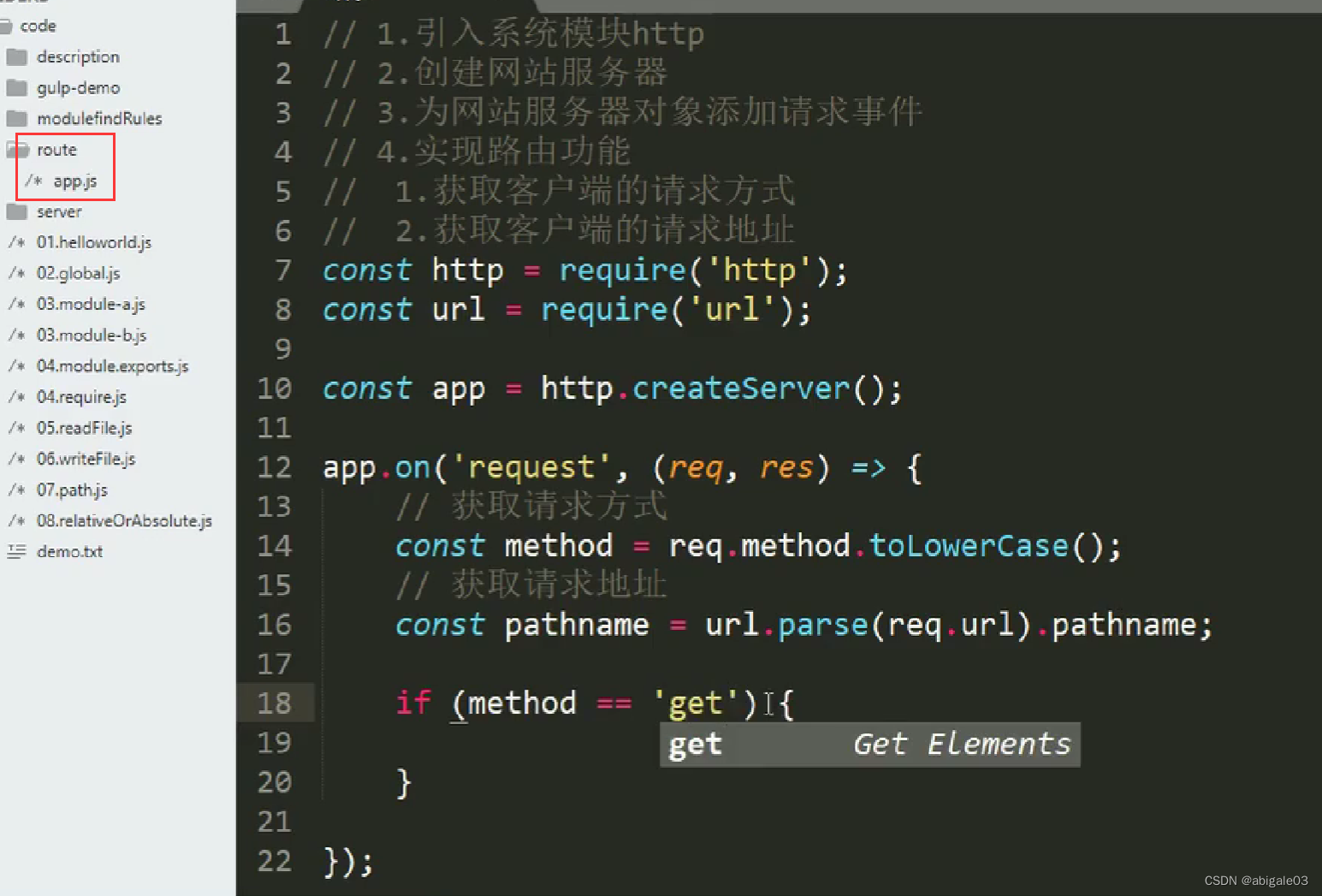
12.4.2 代码实现

对处理后得到的不含请求参数的请求路径进行判断,如果判断条件成立,就可以执行请求路径对应的逻辑处理代码。
请求地址对应的逻辑代码是由开发人员决定的。
route:路由。
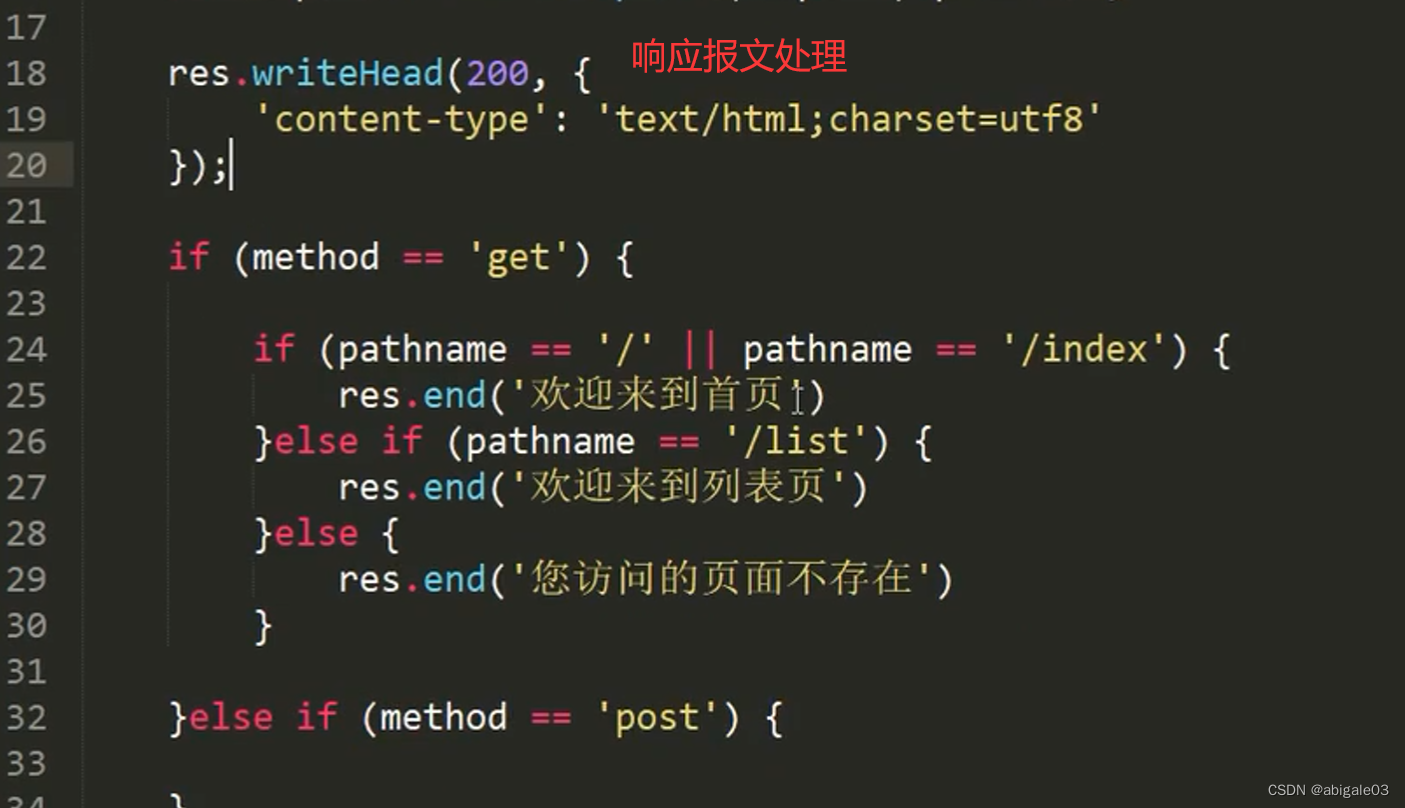
响应报文处理
监听端口
效果
浏览器地址输入localhost:3000、localhost:3000/index、和其他路径,服务器端会响应不同的内容。
这里不做示例。
12.5 静态资源
静态资源:服务器端不需要处理,可以直接响应给客户端的资源,例如css、JavaScript、image文件等。
http://www.itcast.cn/image/logo.png
服务器接收到请求后,只需要找到这张图片并响应给客户端。
12.5.1 访问静态资源
注意:请求地址只是一个字符串标识,请求地址看起来很像路径,但这只是看上去像。即请求地址的路径和服务器资源的真实路径是可以不一致的。
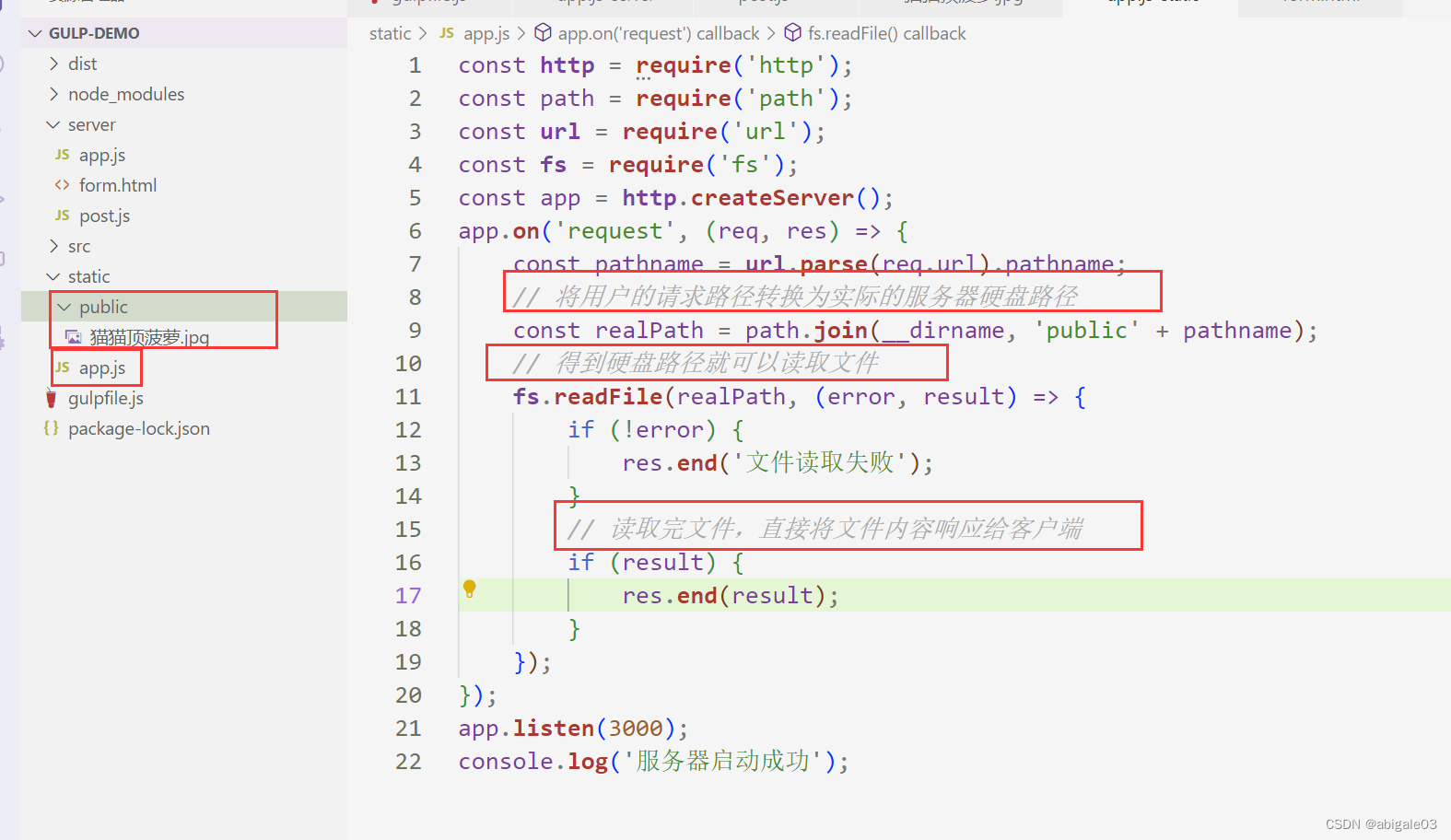
(本地文件路径包含中文,项目访问静态资源失败)
处理:如果路径为/,那么手动设置要返回的文件内容。
还有,浏览器返回了html文件,但是html文件可能会有外链文件(例如图片等文件)。当浏览器读到外链文件,会自动向服务器发送请求去请求当前的外链文件。不管请求的是css、image还是js文件,都是通过fs.readFile读取的。但是不确定浏览器请求的文件类型,这里用到mime第三方模块。
12.6 动态资源
动态资源:相同的请求地址,传递不同的请求参数,得到不同的响应结果,这里的响应结果就是动态资源。
http://www/itcast.cn/article?id=1
http://www/itcast.cn/article?id=2
上述网址请求地址相同,但是请求参数不同,得到的结果是不同的。
12.7 mime第三方模块
1 下载模块
npm install mime下载
2 引入模块
3 调用模块方法
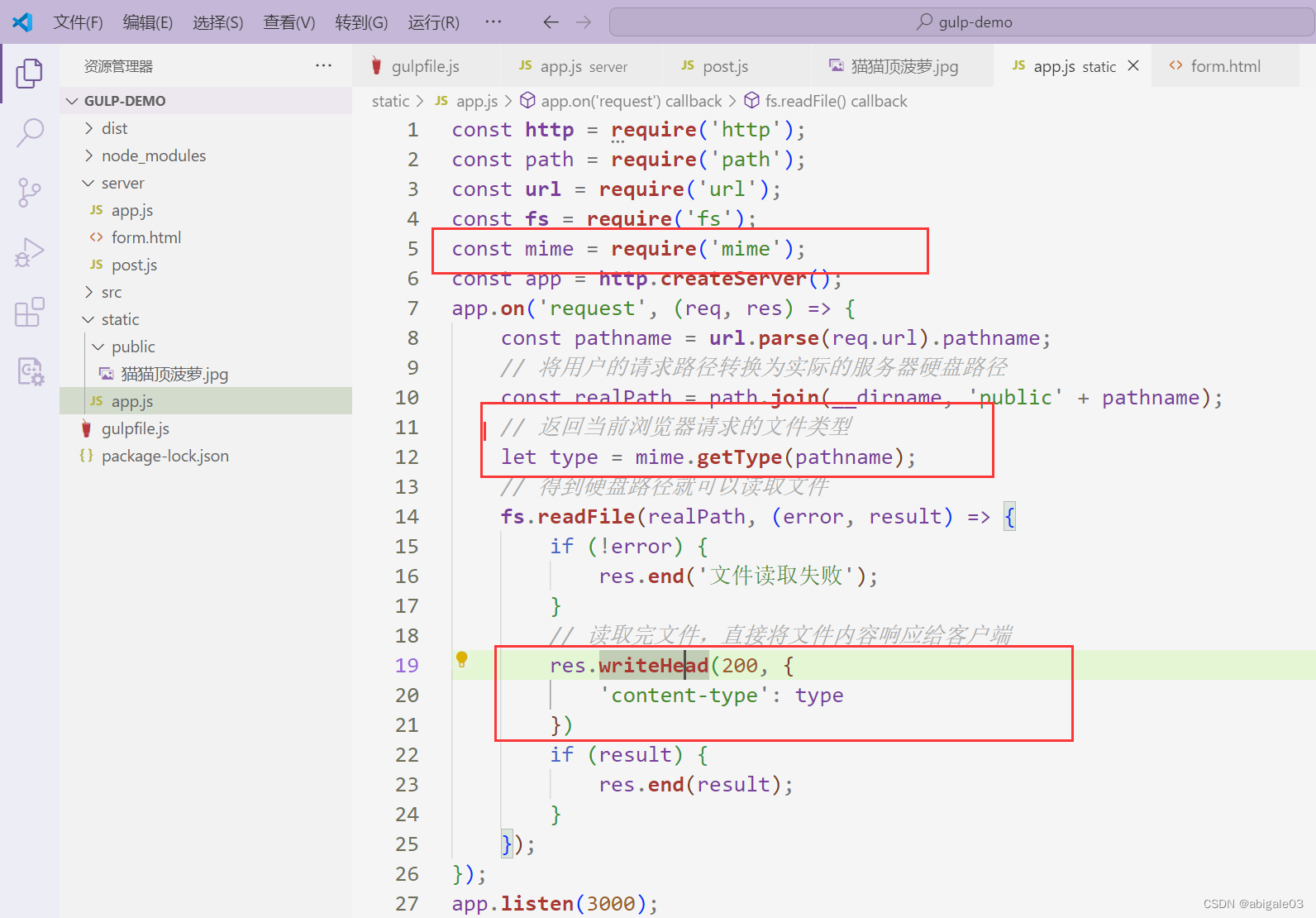
如果代码里不声明content-type,浏览器的响应报文里没有content-type的。
不过不指定content-type,浏览器还是可以正常显示页面的,因为现在的浏览器都是高级浏览器。旧版本的浏览器可能会出现问题。这都是网站应用中隐藏的隐患,必须要解决他。因此一定要指定返回资源的文件类型。
13 Node.js异步编程
到目前为止,关于Node.js中的API已经了解了一些,在这些API中,有的通过返回值的方式拿到API的执行结果。有的通过函数的方式拿到结果。

接下来会来解答此问题。
13.1 同步API,异步API
同步API:只有当前API执行完成后,才能继续执行下一个API。
比如下面代码,在控制台先输出before,再输出after。即只有当第一句代码执行后,才能执行第二句代码。

所谓同步,就是代码从上到下一行一行执行。只有上一行代码执行完成才能执行下一行代码。
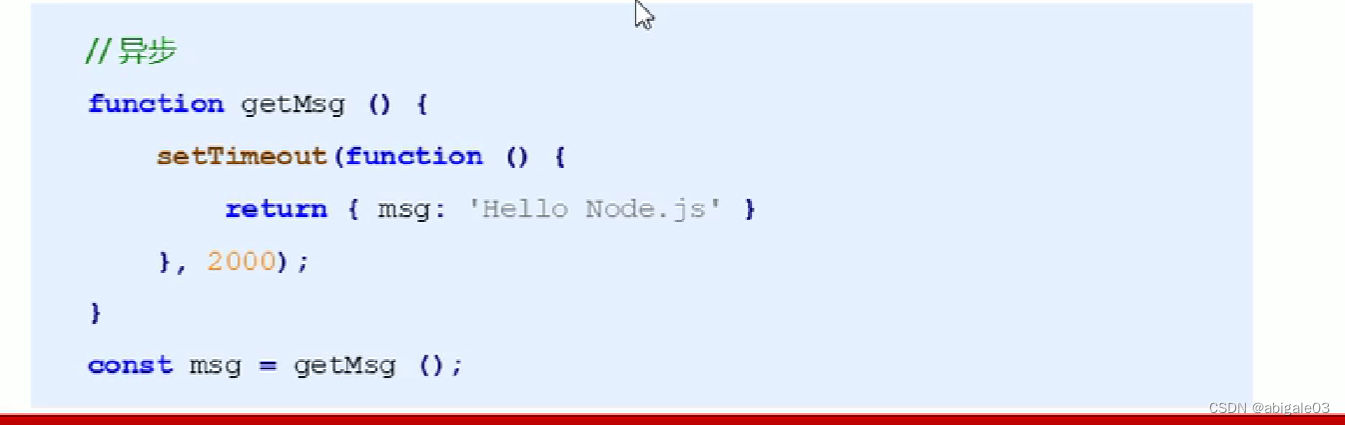
异步API:当前API的执行不会阻塞后续代码的执行。
下列代码结果:before after last。当前代码中,定时器是异步API,程序不需要等待异步API执行完成后再执行后续代码,即异步API不会阻塞后续代码执行。

在Node.js中,异步API可以说是无处不在,掌握Node.js异步编程是非常重要的。
13.2 同步API,异步API的区别(获取返回值)
最大的区别。
同步API可以从函数返回值中拿到API执行的结果,但异步API是不可以的。
下列代码可以从函数返回值拿到执行结果。

下列代码,不能从返回值里拿到结果。执行代码发现,msg结果是undefined。
原因
使用getMsg调用这个函数时,异步API不会阻塞后续代码的执行,因此在函数结尾return undefined。
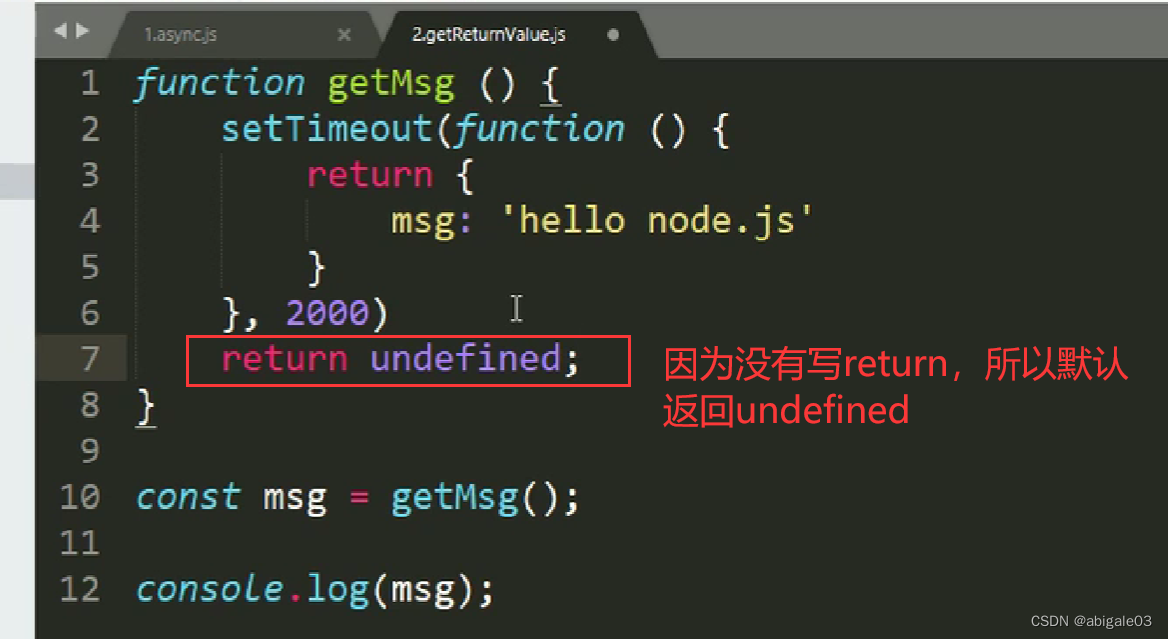
再过2秒后,在setTimeout内部返回一个对象,但是函数返回值早就拿到undefined,并直接在12行进行输出。
结论:在异步API里,无法通过返回值的方式拿到异步API的执行结果。
那么异步API的结果到底怎么拿呢?
回调函数
学完回调函数回来。
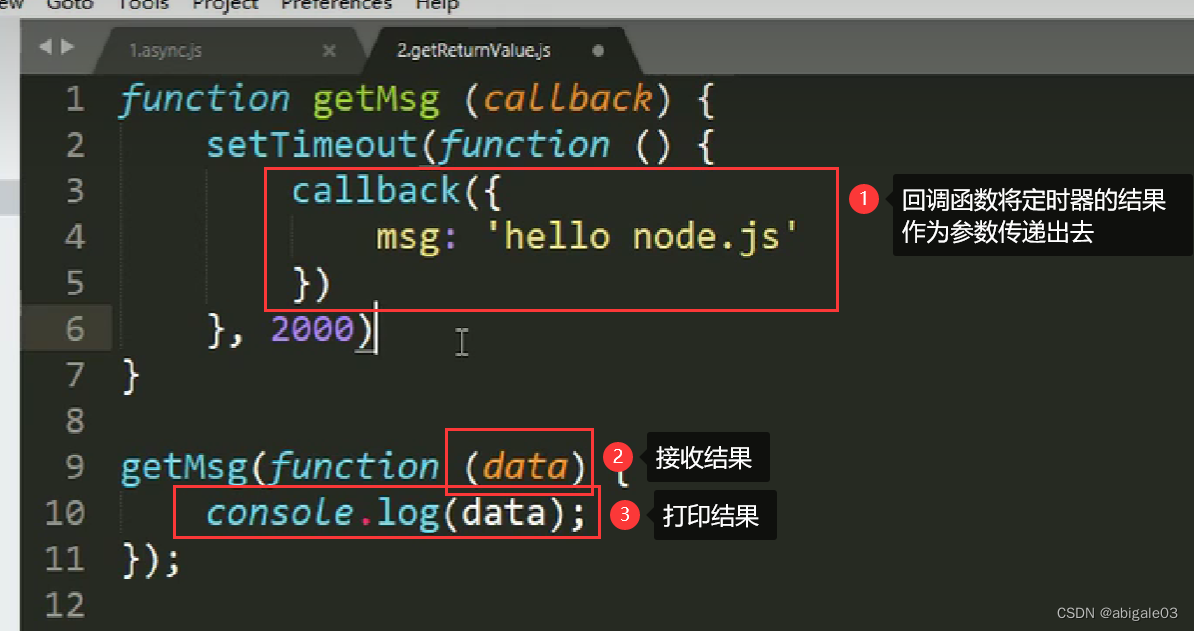
13.3 回调函数
回调函数:自己定义函数让别人去调用。
下图,定义getData(),然后调用getData()。
getData()有一个形参,名为callback,形参对应的实参实际是一个函数。将一个函数作为另外一个函数的参数,这是没有问题的。
callback对应的函数就是回调函数。
在调用getData时,传递了一个匿名函数,实际函数是在getData内部调用的。根据实际的情况决定是否要调用,决定什么时候调用。这个参数就是回调函数。

示例
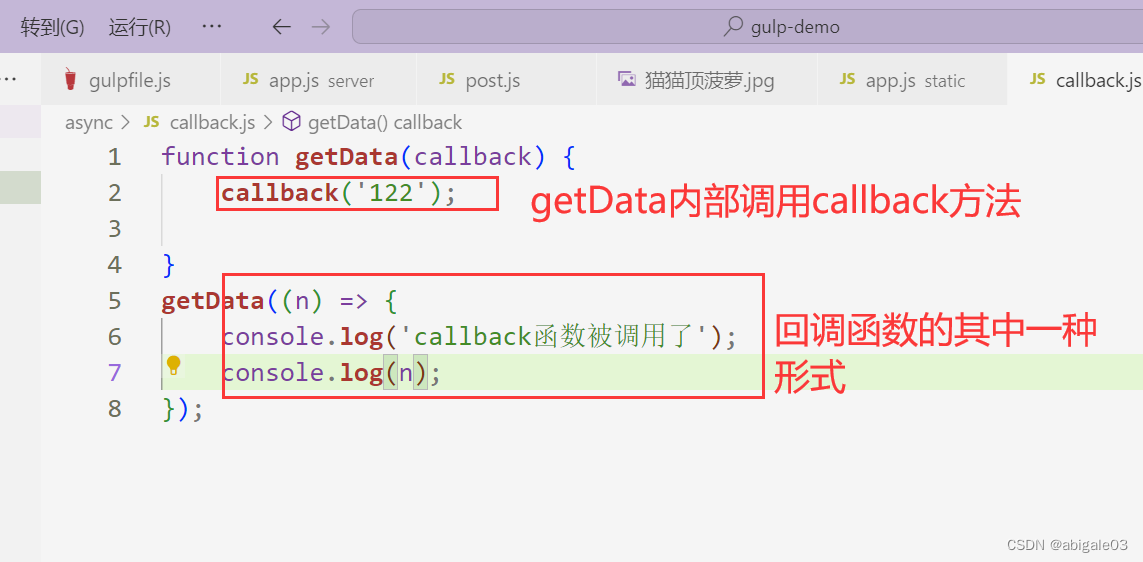
如果getData内部有异步操作,那么在异步操作执行完成后,可以调用回调函数把异步API执行的结果通过参数传递给callback。然后在调用getData里面的回调函数里就可以拿到异步API执行的结果。
(感觉还是没讲明白)
13.5 同步API,异步API的区别(代码执行顺序)
同步API从上到下依次执行,前面代码会阻塞后面代码的执行。
异步API不会等待API执行完成后再向下执行代码
13.6 代码执行顺序分析
Node.js执行代码时,会先将所有的同步API执行完,然后再执行异步API。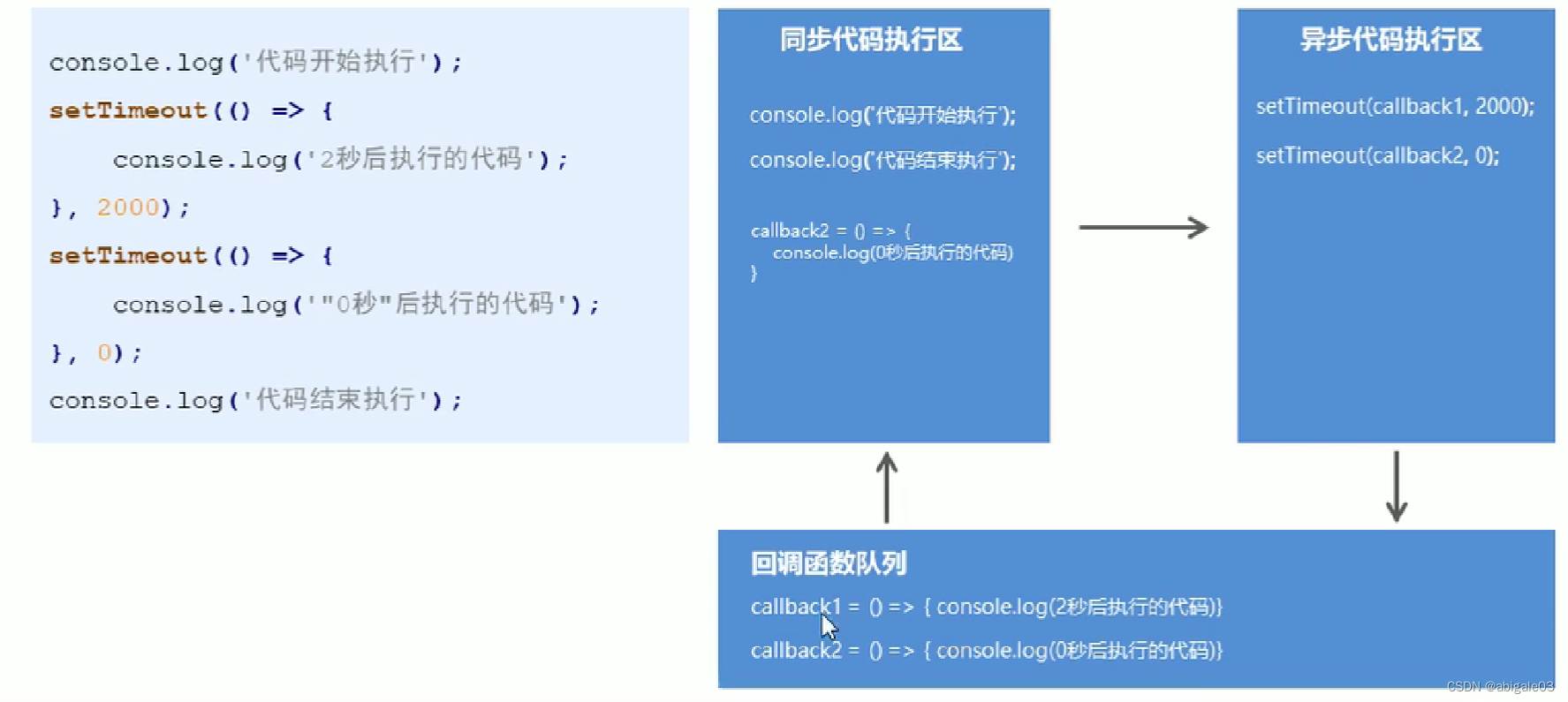
总结:Node.js依次执行代码,遇到同步API会将它放到同步代码执行区去执行,遇到异步API不会执行,而是放到异步代码执行区中。
当代码中所有的同步代码都执行完毕,再到异步代码执行区中依次执行代码。
当异步代码执行完成后,系统会去回调函数队列中找异步API对应的回调函数,将回调函数放到同步代码执行区中执行。
以上就是同步和异步API的执行顺序。
13.7 Node.js中的异步API

Node.js中异步API无处不在。
读取文件操作就是异步API。读取文件的操作与setTimeout操作是类似的,都需要一定时间。所以文件读取结果不能通过返回值拿到,需要通过回调函数。第2个参数就是回调函数,系统调用回调函数,将文件读取结果通过回调函数参数的形式传递出来。
事件监听的API也是异步API,事件处理函数就是回调函数。在为服务器对象添加请求事件时,没有主动调用事件处理函数。事件处理函数的执行都是在事件发生时系统去调用的。系统在调用函数时传递了req和res两个参数。所以在定义这两个参数时可以通过形参的方式去接收这两个参数。
如果异步API后面代码的执行依赖当前异步API的执行结果,但实际上后续代码在执行的时候异步API还没有返回结果,这个问题要怎么解决呢?

需求:依次读取A文件、B文件、C文件。
可以在A文件读取的回调函数里读取B文件,B文件读取的回调函数里读取C文件。
这样会导致回调函数嵌套层次过多,代码难以维护。
示例
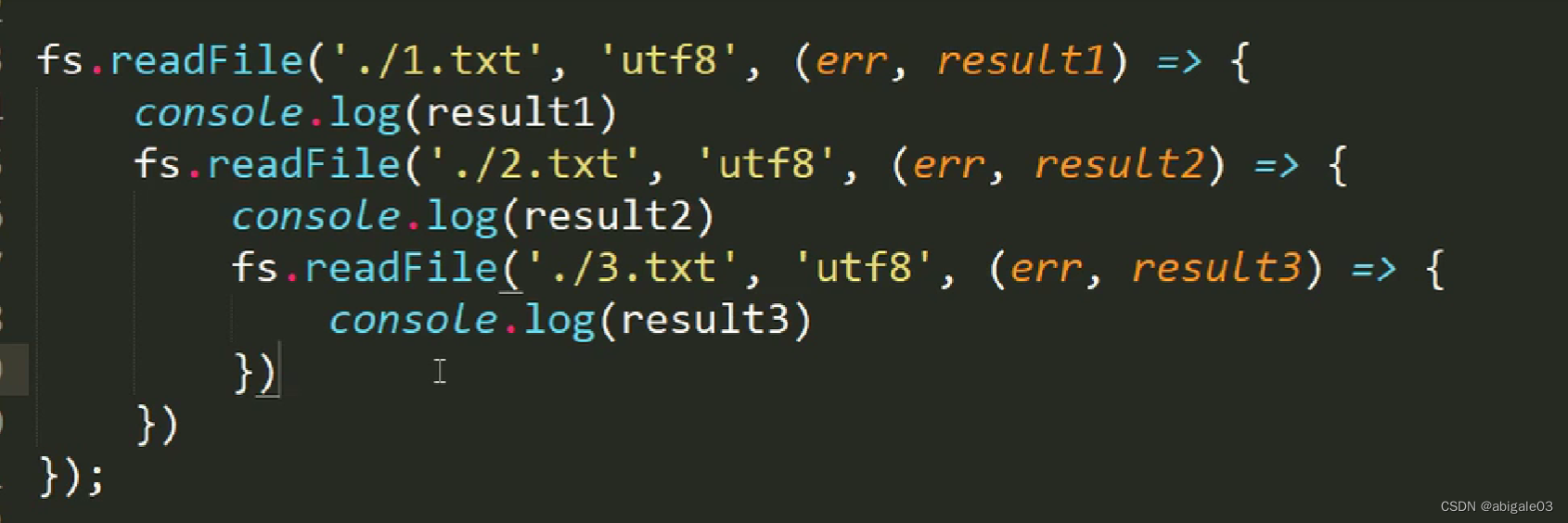
可以发现,代码嵌套了3层。如果是嵌套5层、7层,那么此时的代码就是一个不可维护的代码(虽然可以实现需求,但是代码不易维护)。
这样回调嵌套回调的代码被称为回调地狱,回调地狱是异步编程中存在的一大问题。
解决回调地狱(让代码避免写成回调嵌套回调的形式)。
Promise(ES6推出)
13.8 Promise
Promise出现的目的是解决Node.js异步编程中回调地狱的问题。
Promise本身没有推出新功能,只是一种异步编程语法上的改进,可以将异步API的执行和结果的处理进行分离。
13.8.1 Promise基本语法
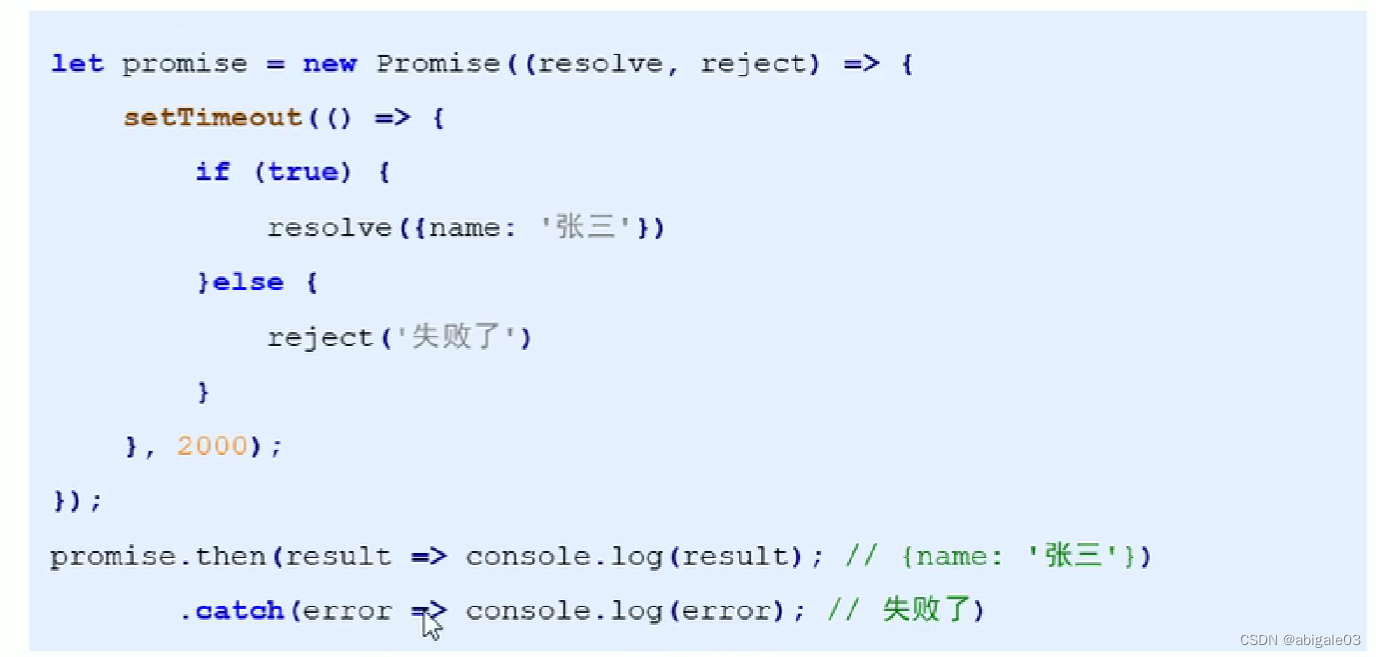
Promise对象有一个then方法。
Promise允许链式编程。
13.8.2 Promise解决回调地狱
看这篇就行了。
【b站咸虾米】ES6 Promise的用法,ES7 async/await异步处理同步化,异步处理进化史-CSDN博客
13.9 异步函数
ES7新增了异步函数语法。使代码看起来清晰明了。
异步函数基于promise进行了封装,将看起来比较臃肿的代码封装起来,然后开放一些关键字供开发者使用。
异步函数是异步编程语法的终极解决方案,可以让我们将异步代码写成同步的形式,让代码不再有回调函数嵌套,使代码变得清晰明了。

异步函数就是在普通函数定义的前面加上async关键字。async是异步的意思。
13.9.1 async关键字
1、普通函数定义前加async关键字,普通函数就变成了异步函数;
2、异步函数默认的返回值是promise对象;

那么可以在调用fn方法后调用其then方法。
即这里的return关键字可以替代resolve方法。那么异步函数内部API执行出错,如何将错误信息返回到函数外。
以前使用reject方法,现在使用throw关键字。
13.9.2 throw关键字
3、在异步函数内部使用使用throw关键字抛出错误。
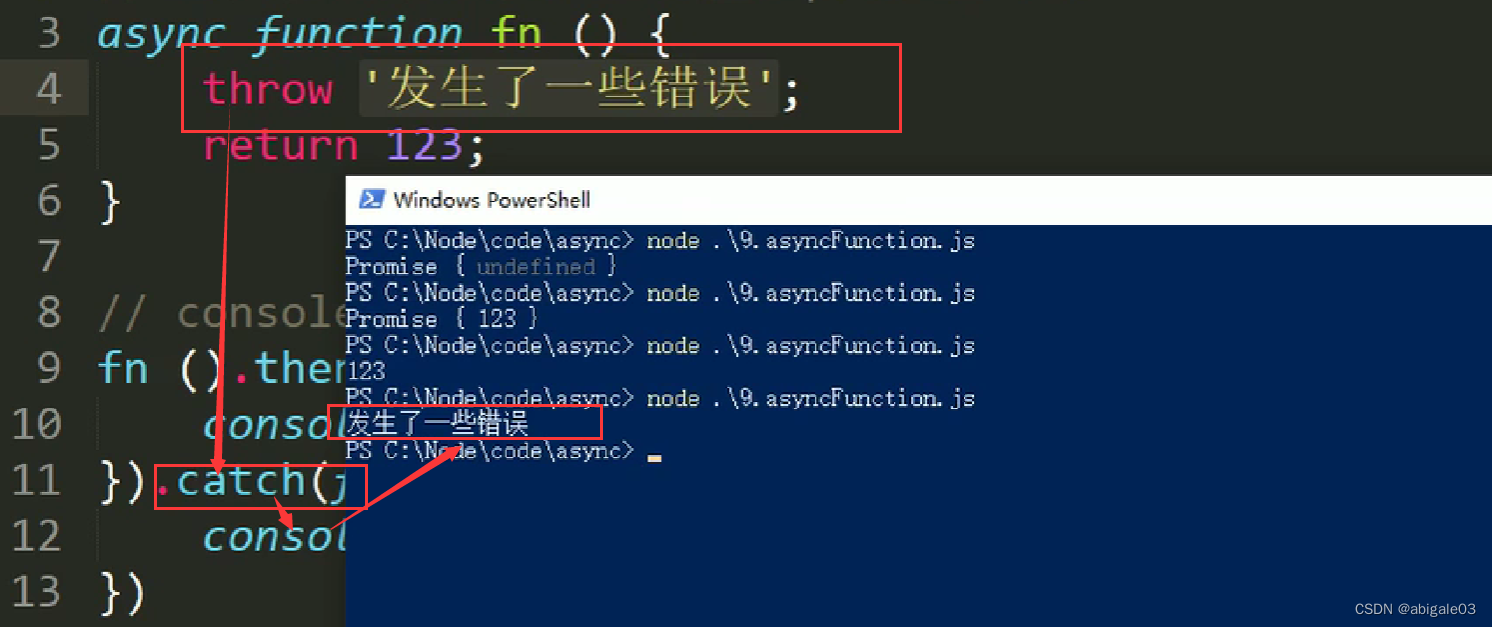
13.9.3 await关键字
await
1 await只能出现在异步函数中。
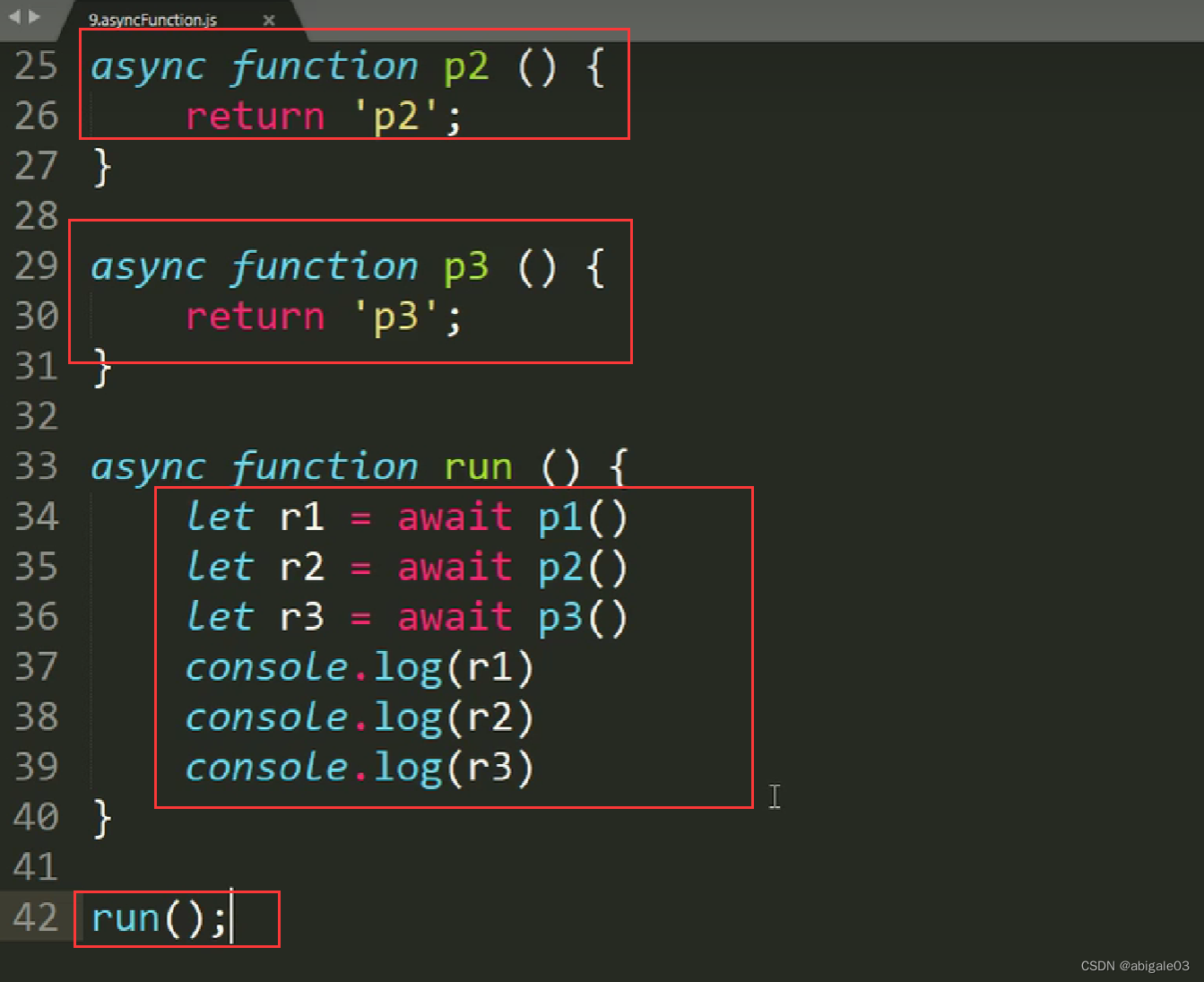
2 await后面跟promise对象。await可以暂停异步函数的执行,等到promise对象返回结果后,再向下执行函数。
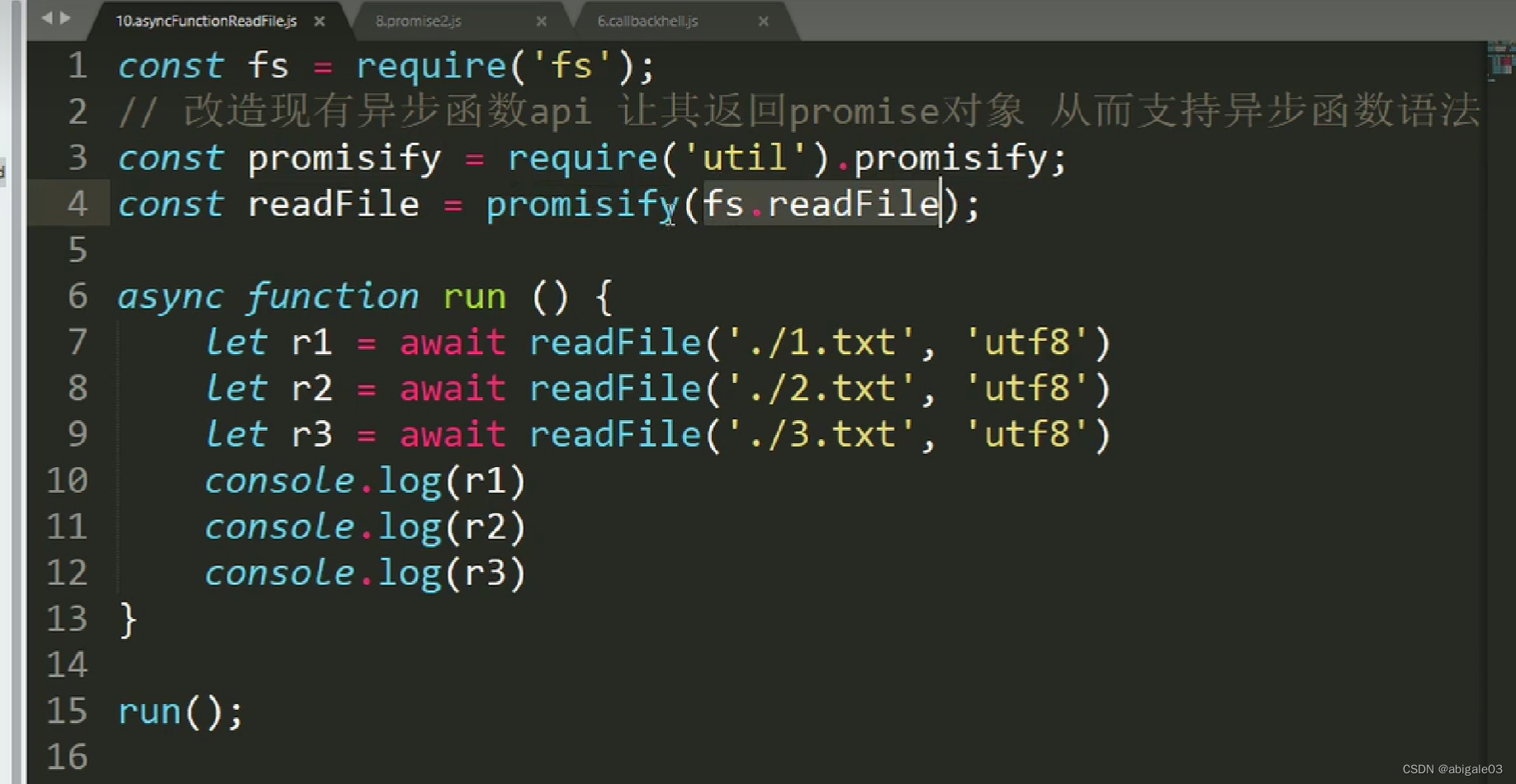
使用await,依次读取三个文件。
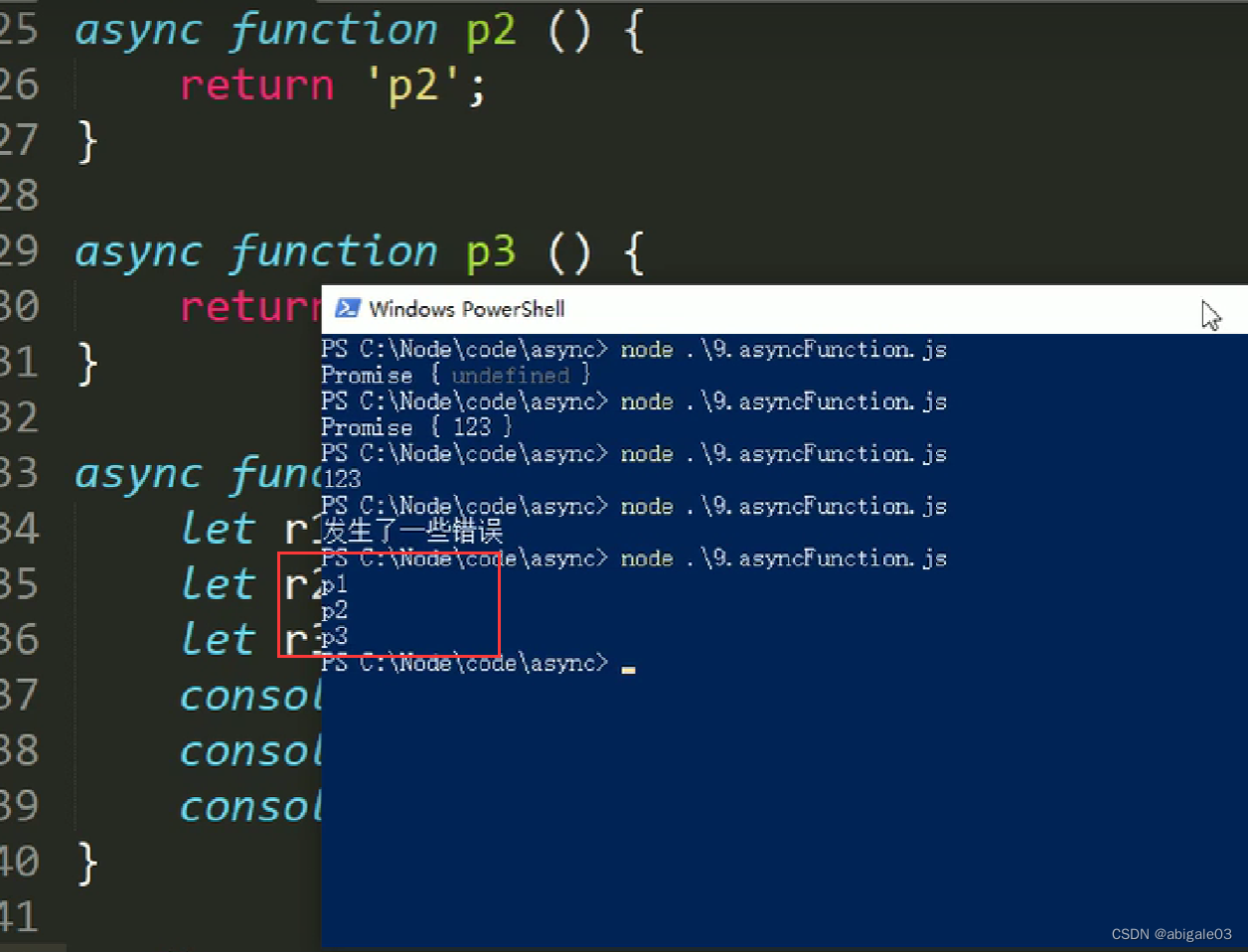
结果
依次读取三个文件。
13.9.4 总结
1 async关键字
- 1 普通函数定义前加async关键字,普通函数变成异步函数
- 2 异步函数默认返回promise对象(省去在函数内部手动创建promise对象)
- 3 在异步函数内部使用return关键字进行结果返回,结果会被包裹在promise对象中,return 关键字代替了resolve方法
- 4 在异步函数内部使用throw关键字抛出程序异常
- 5 调用异步函数再链式调用then方法获取异步函数执行结果
- 6 调用异步函数再链式调用catch方法获取异步函数执行的错误信息。
2 await关键字
- 1 await关键字只能出现在异步函数中
- 2 await promise,await后面只能写promise对象,写其他类型的API是不可以的
- 3 await关键字可以暂停异步函数向下执行,直到当前的promise对象返回结果。
13.9.5 文件读取-async和await改造
















 759
759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









