









本文根据最近学习TensorFlow书籍网络文章的情况,特将一些学习心得做了总结,详情如下.如有不当之处,请各位大拿多多指点,在此谢过。
一、AlexNet模型及其基本原理阐述
1、关于AlexNet
2012年,AlexKrizhevsky提出了深度卷积神经网络模型AlexNet,可以看作LeNet的一种更深更宽的版本。该模型包含了6亿3000万个连接,6000万个参数和65万个神经元,拥有5个卷积层,其中3个卷积层后面连接了最大池化层,最后还有3个全连接层。它将LeNet的思想得到更广泛的传播,把把CNN的基本原理应用到很深很宽的网络中。
2、AlexNet主要使用到的新技术点
(1)成功使用RelU作为CNN的激活函数,并验证其效果在较深的网络超过Sigmoid函数,成功解决了Sigmoid函数在网络较深时梯度弥散问题。
(2)训练时使用Droupout随机忽略一部分神经元,以避免出现模型过拟合。
(3) 在CNN中使用重叠的最大池化。
(4) 提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
(5) 使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。
(6) 数据增强,随机地从256*256的原始图像中截取224*224大小的区域(以及水平翻转的镜像),相当于增加了(256-224)^2=2048倍的数据量。
3、原理阐释
整个AlexNet包括8个需要训练参数的层(不含LRN和池化层),前5层为卷积层,后3层为全连接层,如图1所示。AlexNet最后一层是有1000类输出的Softmax层用作分类。LRN层出现在第1个及第2个卷积层后,而最大池化层出现在两个LRN层及最后一个卷积层后。RelU激活函数则应用在这8层每一层的后面。

图1AlexNet的网络结构
AlexNet每层的超参数如图1所示,其中输入的图片尺寸为224*224,第一个卷积层使用了较大的卷积核尺寸11*11,步长为4,有96个卷积核;然后是一个LRN层;再往后是一个3*3的最大池化层,步长为2。再往后的卷积核尺寸都比较小,基本都是5*5或3*3的大小,且步长都是1,即会扫描全图像所有像素;而最大池化层依然保持为3*3,步长为2。
这里不难发现,前几个卷积层里面,虽然计算量很大,但参数量很小,基本都在1M左右甚至更小,只占AlexNet总参数量很小一部分。这也是卷积层的价值所在:通过较小的参数量提取有效的特征。
如果前几层直接使用全连接层,则参数量和计算量将会难以想象。尽管每一个卷积层只占整个网络参数量的1%不到,但如果抛弃任何一个卷积层,都会迫使整个网络的分类能力大幅度下降。
图1中特殊的地方是卷积部分都是画成上下两块,意思是说把这一层计算出来的featuremap分开,但是前一层用到的数据要看连接的虚线,如图中input层之后的第一层第二层之间的虚线是分开的,是说二层上面的128map是由一层上面的48map计算的,下面同理;而第三层前面的虚线是完全交叉的,就是说每一个192map都是由前面的128+128=256map同时计算得到的。
Alexnet有一个特殊的计算层,LRN层,做的事是对当前层的输出结果做平滑处理,图2所示:
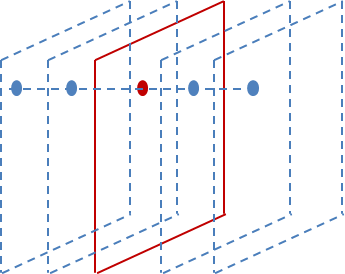
图2
前后几层(对应位置的点)对中间这一层做一下平滑约束,计算方法如下:
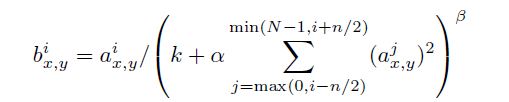
二、经典卷积神经网络AlexNet模型实现过程
1、简要说明
因为使用ImageNet数据集训练一个完整的AlexNet非常耗时,这里AlexNet的实现将不涉及实际数据的训练,但会创建一个完整的AlexNet卷积神经网络,然后对它每个batch的前馈计算(forward)和反馈计算(backward)的速度进行测试。下面使用随机图片数据来计算每轮前馈、反馈的平均耗时。当然,读者也可以自行下载ImageNet数据完成训练并测试。
2、实现过程
==============================================================================
from datetime import datetime
import math
import time
import tensorflow as tf
#这里总共测试100个batch的数据。
batch_size=32
num_batches=100
#定义一个用来显示网络每一层结构的函数print_activations,展示每一个卷积层或池化层输出的tensor尺寸。
def print_activations(t):
print(t.op.name, ' ', t.get_shape().as_list())
#设计AlexNet网络结构。
#设定inference函数,用于接受images作为输入,返回最后一层pool5(第5个池化层)及parameters(AlexnNet中所有需要训练的模型参数)
#该函数包括多个卷积层和池化层。
def inference(images):
parameters = []
# 第1个卷积层
with tf.name_scope('conv1') as scope:
kernel = tf.Variable(tf.truncated_normal([11, 11, 3, 64], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(images, kernel, [1, 4, 4, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[64], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(bias, name=scope)
print_activations(conv1)
parameters += [kernel, biases]
# 添加LRN层和最大池化层
lrn1 = tf.nn.lrn(conv1, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='lrn1')
pool1 = tf.nn.max_pool(lrn1,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID',
name='pool1')
print_activations(pool1)
# 设计第2个卷积层
with tf.name_scope('conv2') as scope:
kernel = tf.Variable(tf.truncated_normal([5, 5, 64, 192], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(pool1, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[192], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv2 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv2)
# 对第2个卷积层的输出进行处理,同样也是先做LRN处理再做最大化池处理。
lrn2 = tf.nn.lrn(conv2, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='lrn2')
pool2 = tf.nn.max_pool(lrn2,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID',
name='pool2')
print_activations(pool2)
# 设计第3个卷积层
with tf.name_scope('conv3') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 192, 384],
dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(pool2, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[384], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv3 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv3)
# 设计第4个卷积层
with tf.name_scope('conv4') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 384, 256],
dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(conv3, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv4 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv4)
# 设计第5个卷积层
with tf.name_scope('conv5') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 256, 256],
dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(conv4, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv5 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv5)
# 最大池化层
pool5 = tf.nn.max_pool(conv5,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID',
name='pool5')
print_activations(pool5)
return pool5, parameters
#构建函数time_tensorflow_run,用来评估AlexNet每轮计算时间。
def time_tensorflow_run(session, target, info_string):
num_steps_burn_in = 10
total_duration = 0.0
total_duration_squared = 0.0
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target)
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print ('%s: step %d, duration = %.3f' %
(datetime.now(), i - num_steps_burn_in, duration))
total_duration += duration
total_duration_squared += duration * duration
mn = total_duration / num_batches
vr = total_duration_squared / num_batches - mn * mn
sd = math.sqrt(vr)
print ('%s: %s across %d steps, %.3f +/- %.3f sec / batch' %
(datetime.now(), info_string, num_batches, mn, sd))
#主函数
def run_benchmark():
with tf.Graph().as_default():
image_size = 224
images = tf.Variable(tf.random_normal([batch_size,
image_size,
image_size, 3],
dtype=tf.float32,
stddev=1e-1))
pool5, parameters = inference(images)
init = tf.global_variables_initializer()
config = tf.ConfigProto()
config.gpu_options.allocator_type = 'BFC'
sess = tf.Session(config=config)
sess.run(init)
time_tensorflow_run(sess, pool5, "Forward")
objective = tf.nn.l2_loss(pool5)
grad = tf.gradients(objective, parameters)
# Run the backward benchmark.
time_tensorflow_run(sess, grad, "Forward-backward")
#执行主函数
run_benchmark()3、执行结果分析
这里有三部分如下:
首先是AlexNet的网络结构
conv1 [32, 56, 56, 64]
pool1 [32, 27, 27, 64]
conv2 [32, 27, 27, 192]
pool2 [32, 13, 13, 192]
conv3 [32, 13, 13, 384]
conv4 [32, 13, 13, 256]
conv5 [32, 13, 13, 256]
pool5 [32, 6, 6, 256]其次是Forward运行的时间。
2018-02-26 08:08:01.966903: step 0, duration = 0.914
2018-02-26 08:08:11.376824: step 10, duration = 0.939
2018-02-26 08:08:21.075799: step 20, duration = 0.953
2018-02-26 08:08:30.983637: step 30, duration = 0.930
2018-02-26 08:08:40.616086: step 40, duration = 0.938
2018-02-26 08:08:50.259619: step 50, duration = 0.965
2018-02-26 08:09:01.280123: step 60, duration = 1.128
2018-02-26 08:09:11.993487: step 70, duration = 0.998
2018-02-26 08:09:22.223815: step 80, duration = 0.935
2018-02-26 08:09:31.741528: step 90, duration = 0.921
2018-02-26 08:09:40.085934: Forward across 100 steps, 0.990 +/- 0.082 sec / batch最后是backward运行的时间。
2018-02-26 08:10:19.714161: step 0, duration = 3.387
2018-02-26 08:10:55.765137: step 10, duration = 3.495
2018-02-26 08:11:32.451839: step 20, duration = 4.189
2018-02-26 08:12:07.982546: step 30, duration = 3.369
2018-02-26 08:12:43.531404: step 40, duration = 3.415
2018-02-26 08:13:18.980045: step 50, duration = 3.470
2018-02-26 08:13:54.535575: step 60, duration = 3.371
2018-02-26 08:14:29.413705: step 70, duration = 3.655
2018-02-26 08:15:06.147061: step 80, duration = 3.583
2018-02-26 08:15:43.403758: step 90, duration = 3.921
2018-02-26 08:16:16.511215: Forward-backward across 100 steps, 3.602 +/- 0.237 sec / batch
三、小结
AlexNet为卷积神经网络和深度学习正名,为复兴神经网络做出了很多贡献,当然,超大型的数据集ImageNet也给深度学习带来了很大贡献。训练深度卷积神经网络,必须要有一个类似于ImageNet这样超大型数据集才能避免出现过拟合现象,从而更能体现深度学习的优势所在。因此,传统机器学习模型更适合一个小型数据集,在面对大型数据集时,需要更大学习容量的模型,那就是深度学习模型。
深度学习的参数不一定比传统机器学习模型多,尤其是在卷积层使用的参数量一般都比较少,但其抽取特征的能力非常强悍,这是CNN之所以有效的原因。
参考资料 主要参考资料《TensorFlow实战》(黄文坚 唐源 著)(电子工业出版社)。















 9091
9091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









