




 本文介绍如何通过Python爬取QQ音乐评论数据的过程,包括理解g_tk加密函数原理及其实现,解析评论API接口参数,并展示完整的爬虫代码。
本文介绍如何通过Python爬取QQ音乐评论数据的过程,包括理解g_tk加密函数原理及其实现,解析评论API接口参数,并展示完整的爬虫代码。
QQ音乐评论爬取分析
1.随便选个音乐
https://y.qq.com/n/yqq/song/0039MnYb0qxYhV.html
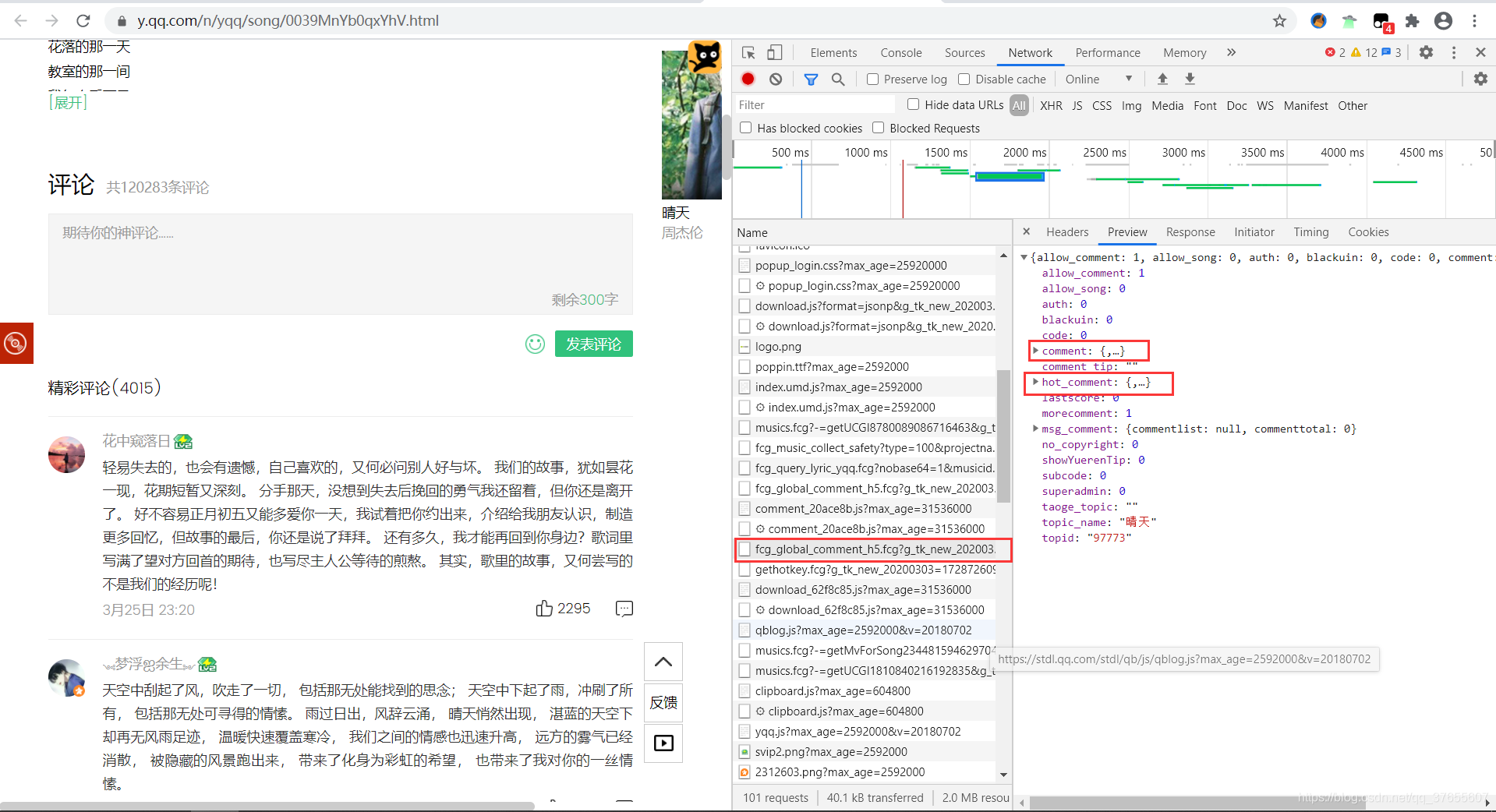
找到评论的数据接口:
https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg?g_tk_new_20200303=1728726093&g_tk=1728726093&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=GB2312¬ice=0&platform=yqq.json&needNewCode=0&cid=205360772&reqtype=2&biztype=1&topid=97773&cmd=8&needmusiccrit=0&pagenum=0&pagesize=25&lasthotcommentid=&domain=qq.com&ct=24&cv=10101010
参数列表:
| 参数名 | 参数值 |
|---|---|
| g_tk_new_20200303 | 1728726093 |
| g_tk | 1728726093 |
| loginUin | 0 |
| hostUin | 0 |
| format | json |
| inCharset | utf8 |
| outCharset | GB2312 |
| notice | 0 |
| platform | yqq.json |
| needNewCode | 0 |
| cid | 205360772 |
| reqtype | 2 |
| biztype | 1 |
| topid | 97773 |
| cmd | 8 |
| needmusiccrit | 0 |
| pagenum | 0 |
| pagesize | 25 |
| lasthotcommentid | |
| domain | qq.com |
| ct | 24 |
| cv | 10101010 |
可以发现两者值相等
| 参数名 | 参数值 |
|---|---|
| g_tk_new_20200303 | 1728726093 |
| g_tk | 1728726093 |
2. g_tk函数介绍
在百度后才知道 g_tk 是个加密函数 ,而且还是javascript写的
然后再所有 js 中搜索 g_tk 按 Ctrl +F
终于找到了
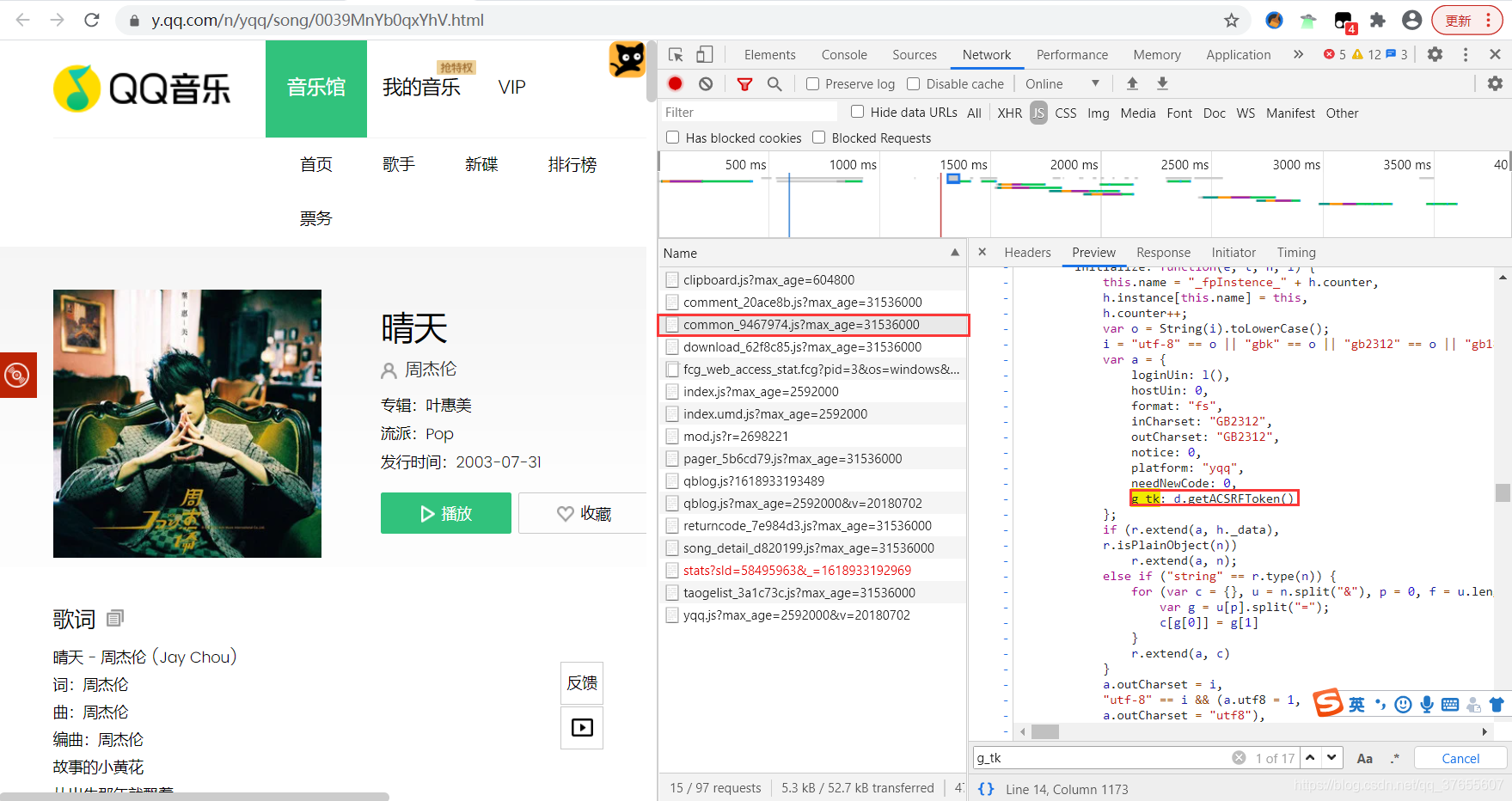
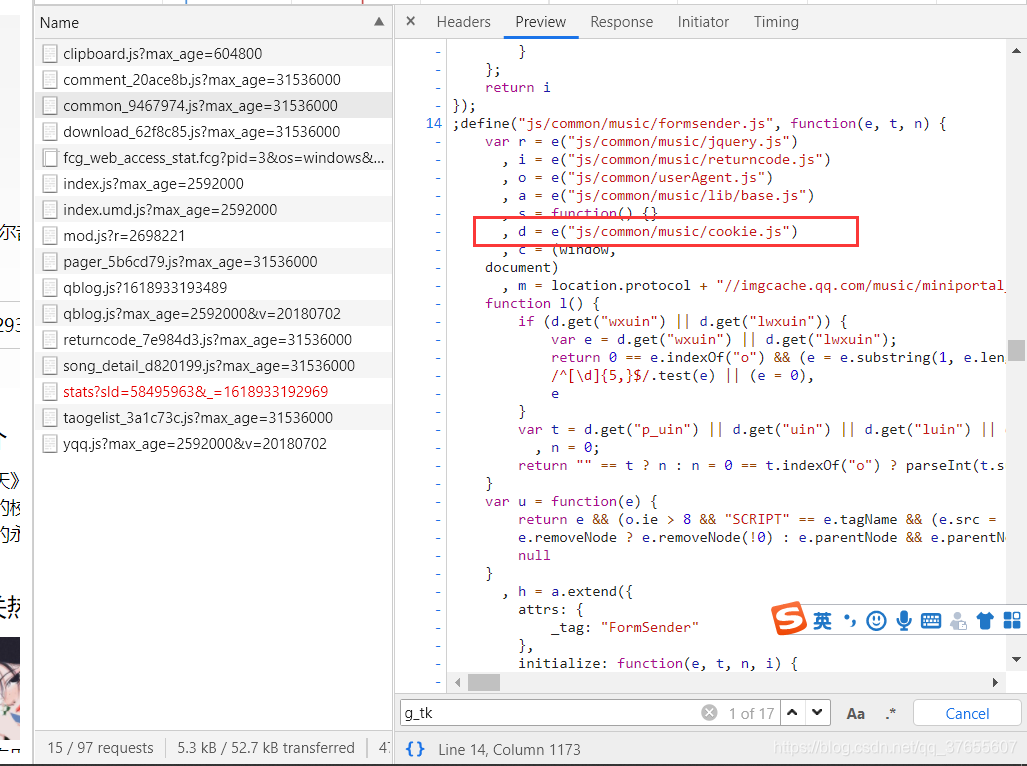
d 引用的是 cookie.js
https://y.gtimg.cn/music/portal/js/common/music/cookie.js
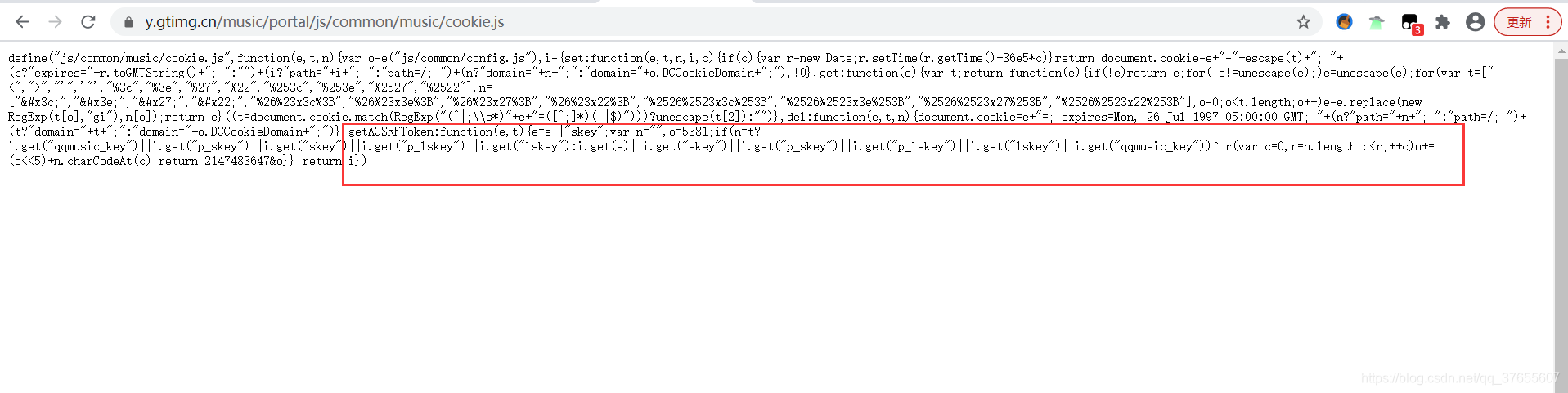
代码:
define("js/common/music/cookie.js", function(e, t, n) {
var o = e("js/common/config.js"),
i = {
set: function(e, t, n, i, c) {
if (c) {
var r = new Date;
r.setTime(r.getTime() + 36e5 * c)
}
return document.cookie = e + "=" + escape(t) + "; " + (c ? "expires=" + r.toGMTString() + "; " : "") + (i ? "path=" + i + "; " : "path=/; ") + (n ? "domain=" + n + ";" : "domain=" + o.DCCookieDomain + ";"), !0
},
get: function(e) {
var t;
return function(e) {
if (!e) return e;
for (; e != unescape(e);) e = unescape(e);
for (var t = ["<", ">", "'", '"', "%3c", "%3e", "%27", "%22", "%253c", "%253e", "%2527", "%2522"], n = ["<", ">", "'", """, "%26%23x3c%3B", "%26%23x3e%3B", "%26%23x27%3B", "%26%23x22%3B", "%2526%2523x3c%253B", "%2526%2523x3e%253B", "%2526%2523x27%253B", "%2526%2523x22%253B"], o = 0; o < t.length; o++) e = e.replace(new RegExp(t[o], "gi"), n[o]);
return e
}((t = document.cookie.match(RegExp("(^|;\\s*)" + e + "=([^;]*)(;|$)"))) ? unescape(t[2]) : "")
},
del: function(e, t, n) {
document.cookie = e + "=; expires=Mon, 26 Jul 1997 05:00:00 GMT; " + (n ? "path=" + n + "; " : "path=/; ") + (t ? "domain=" + t + ";" : "domain=" + o.DCCookieDomain + ";")
},
getACSRFToken: function(e, t) {
e = e || "skey";
var n = "",
o = 5381;
if (n = t ? i.get("qqmusic_key") || i.get("p_skey") || i.get("skey") || i.get("p_lskey") || i.get("lskey") : i.get(e) || i.get("skey") || i.get("p_skey") || i.get("p_lskey") || i.get("lskey") || i.get("qqmusic_key")) for (var c = 0, r = n.length; c < r; ++c) o += (o << 5) + n.charCodeAt(c);
return 2147483647 & o
}
};
return i
});
所以生成 g_tk 函数如下:
getACSRFToken: function(e, t) {
e = e || "skey";
var n = "",
o = 5381;
if (n = t ? i.get("qqmusic_key") || i.get("p_skey") || i.get("skey") || i.get("p_lskey") || i.get("lskey") : i.get(e) || i.get("skey") || i.get("p_skey") || i.get("p_lskey") || i.get("lskey") || i.get("qqmusic_key")) for (var c = 0, r = n.length; c < r; ++c) o += (o << 5) + n.charCodeAt(c);
return 2147483647 & o
}
三元表达式:
表达式1?表达式2:表达式3
表达式1是一个条件,值为Boolean类型
若表达式1的值为true,则执行表达式2的操作,并且以表达式2的结果作为整个表达式的结果;
若表达式1的值为false,则执行表达式3的操作,并且以表达式3的结果作为整个表达式的结果;
|| 任意 一个条件成立 就为成立
用python替换
def g_tk(skey):
hash = 5381
length = len(skey)
for i in range(length):
if i < length:
hash += (hash<<5) + ord(skey[i])
return 2147483647&hash
但是需要传入一个参数
假设 n = t
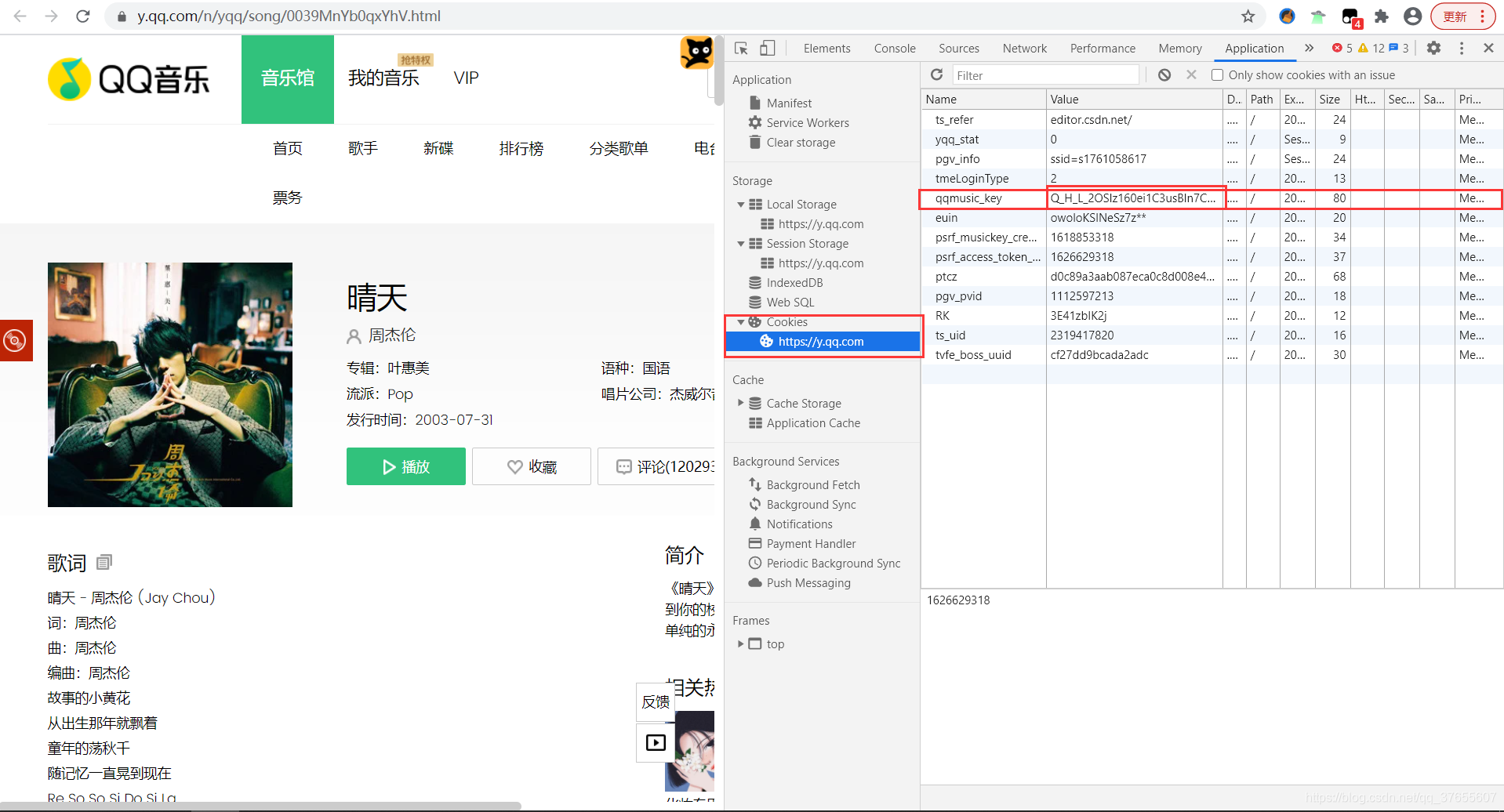
i.get("qqmusic_key")
从 cookie 中取值
我们 先找找 cookie
def g_tk(skey):
hash = 5381
length = len(skey)
for i in range(length):
if i < length:
hash += (hash<<5) + ord(skey[i])
return 2147483647&hash
print(g_tk("Q_H_L_2OSlz160ei1C3usBln7CHpyKTimzESqdlHwVunbIFXiBSZjlxL5LKbmz25RIkA3"))
打印

这不刚好是 g_tk 参数的值吗
这个值登录后获取,会改变的
Q_H_L_2OSlz160ei1C3usBln7CHpyKTimzESqdlHwVunbIFXiBSZjlxL5LKbmz25RIkA3
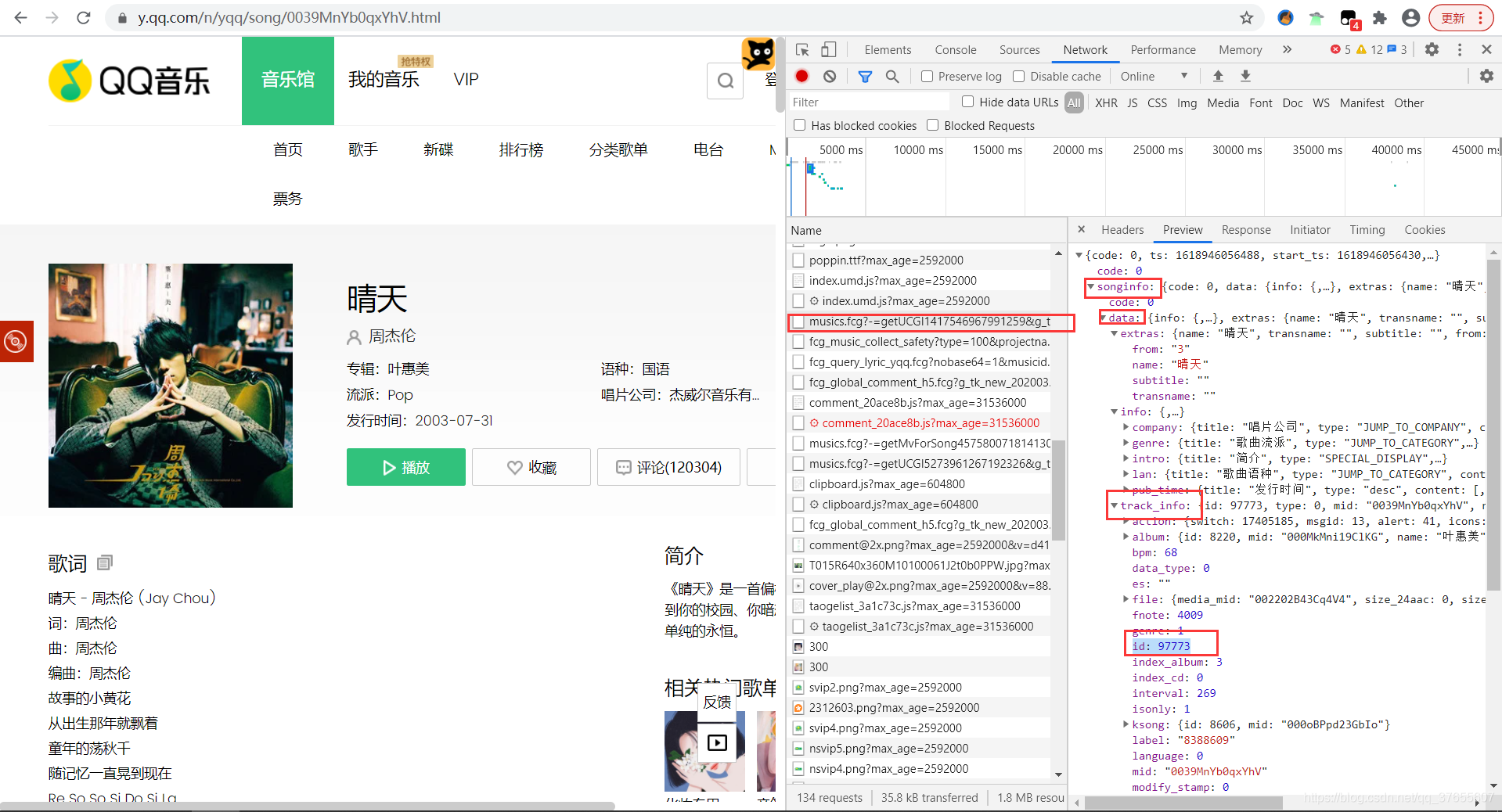
3. topid
4. python 代码
import requests
from urllib import parse
import json
import pandas as pd
import os
import time
def g_tk(skey):
hash = 5381
length = len(skey)
for i in range(length):
if i < length:
hash += (hash<<5) + ord(skey[i])
return 2147483647&hash
page = 0
df_all = pd.DataFrame()
while True:
comment_url = "https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg?"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'}
params = {
'g_tk_new_20200303':g_tk("Q_H_L_2Ou6-160eWT0kjGauzHMtXeJETzw9dz7sEuZ-3rx4M2Mt3qowToV8PY0bK_XLLE"),
'g_tk':g_tk("Q_H_L_2Ou6-160eWT0kjGauzHMtXeJETzw9dz7sEuZ-3rx4M2Mt3qowToV8PY0bK_XLLE"),
'loginUin':'0',
'hostUin':'0',
'format':'json',
'inCharset':'utf8',
'outCharset':'GB2312',
'notice':'0',
'platform':'yqq.json',
'needNewCode':'0',
'cid':'205360772',
'reqtype':'2',
'biztype':'1',
'topid':'97773',
'cmd':'8',
'needmusiccrit':'0',
'pagenum':'0',
'pagesize':'25',
'lasthotcommentid':'',
'domain':'qq.com',
'ct':'24',
'cv':'10101010'
}
params= parse.urlencode(params)
url = comment_url + params
response = requests.get(url,headers=headers)
result = response.text
comment_info = json.loads(result)
topid = comment_info['topid']
topic_name=comment_info['topic_name']
comment = comment_info['comment']
comment_total = comment['commenttotal']
comment_list = comment['commentlist']
page_total =int((comment_total-1)/25) + 1
if page >=100 :
break
for i in comment_list:
comment_id = i['commentid']
avatar_url =i['avatarurl']
nick=i['nick']
try:
content=i['rootcommentcontent']
except Exception as e:
content = ''
comment_time=i['time']
timeArray = time.localtime(comment_time)
comment_time = time.strftime("%Y年%m月%d日 %H:%M:%S", timeArray)
praise_num=i['praisenum']
vip_icon=i['vipicon']
if vip_icon == '' :
vip_icon = '未开通会员'
else:
vip_icon = vip_icon[-9:-4]
df = pd.DataFrame({
'评论ID':comment_id,
'头像链接':avatar_url,
'昵称':nick,
'评论内容':content,
'评论时间':comment_time,
'点赞数量':praise_num,
'等级图标':vip_icon
},index=[0])
df_all = df_all.append(df, ignore_index=True)
page = page + 1
time.sleep(1)
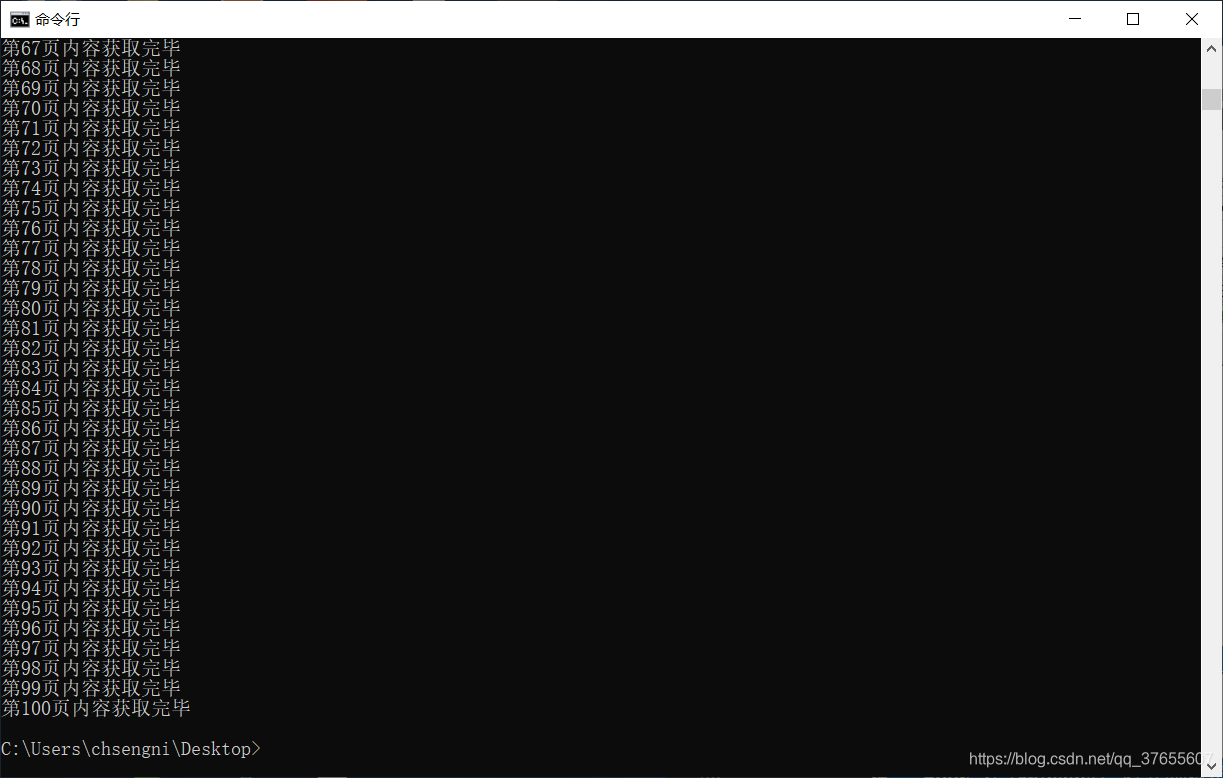
print("第"+str(page)+"页内容获取完毕")
df_all.to_excel(os.getcwd()+"\\"+topic_name+'_'+str(comment_total)+'_最新评论.xlsx',index = False)
5. 结果
总共4000 多页,延迟1秒
需要一个多小时才能跑完
暂时只演示 100条数据
if page >=100 :
break
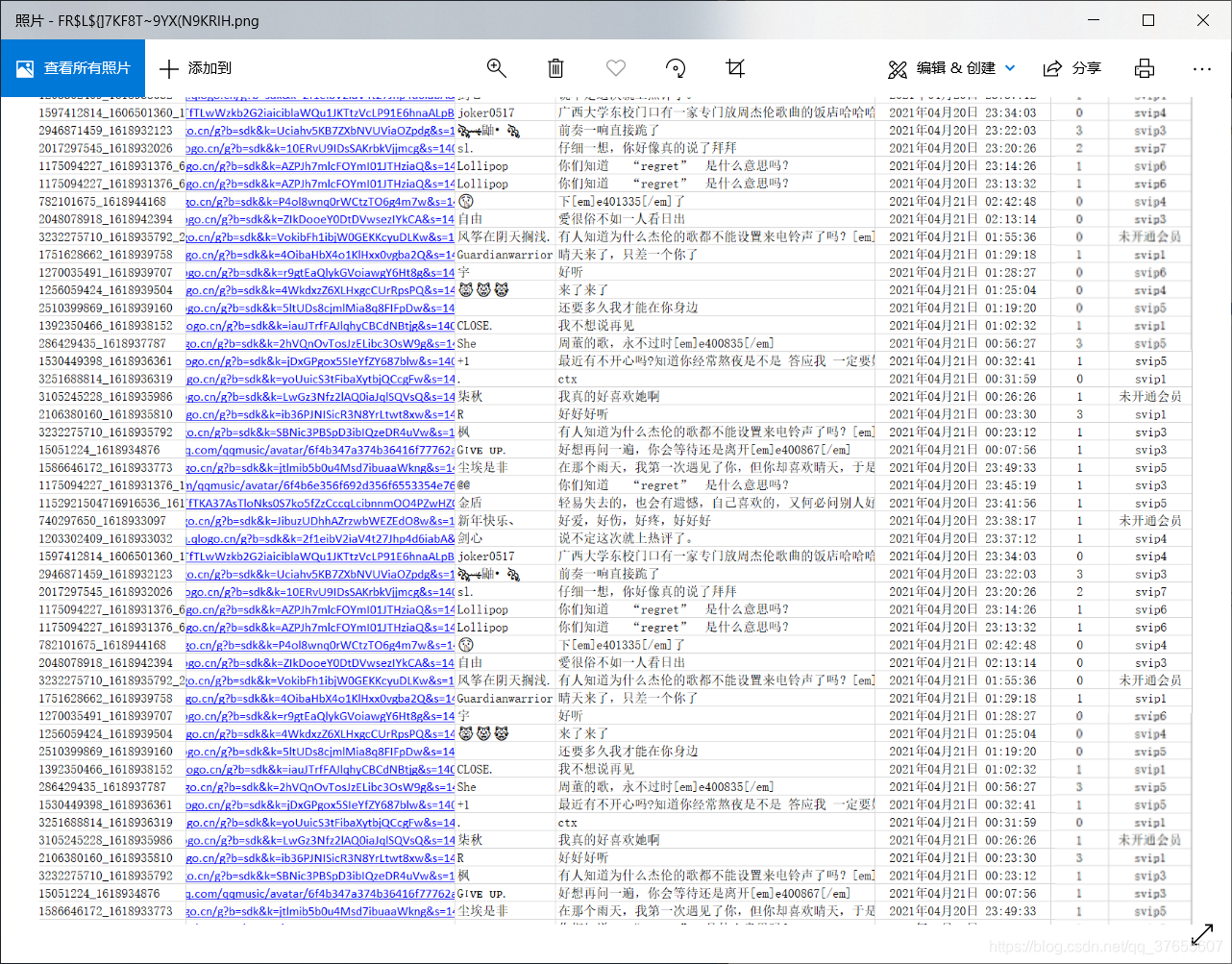
太长了 上传不了随意截图了一段


















 2108
2108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











