







环境:Ubuntu16.4 python版本:3.6.4 库:wordcloud
这次我们要讲的是爬取QQ音乐的评论并制成云词图,我们这里拿周杰伦的等你下课来举例。
第一步:获取评论
我们先打开QQ音乐,搜索周杰伦的《等你下课》,直接拉到底部,发现有5000多页的评论。
这时候我们要研究的就是怎样获取每页的评论,这时候我们可以先按下F12,选择NetWork,我们可以先点击小红点清空数据,然后再点击一次,开始监控,然后点击下一页,看每次获取评论的时候访问获取的是哪几条数据。最后我们就能看到下图的样子,我们发现,第一条数据就是我们所要找的内容,点击第一条数据,打开它的response拉到最下面,发现他的最后一条评论rootcommentcontent跟我们网页中最后一条评论是一致的,那这时候已经成功了一般了,我们接下来只需要研究这条数据获取的规律就可以获取到所有的评论了。
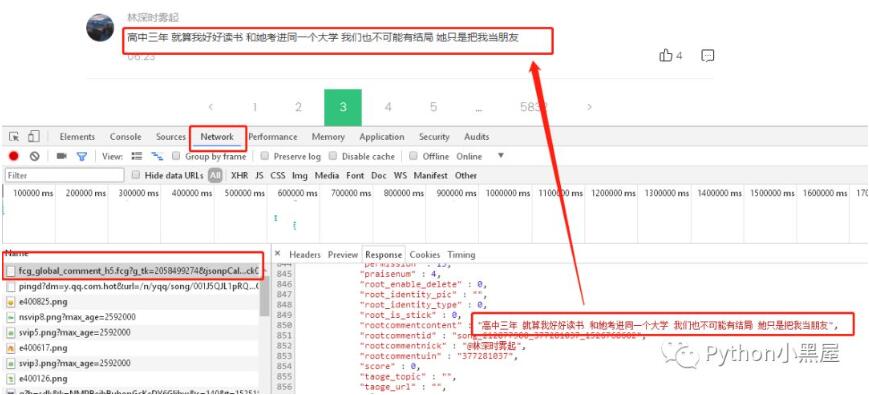
我们先查看这条数据的Headers分析下Request URL,通过点开不同的页码进行比较,发现每次发出的情况网址大部分内容是相同,不同的地方有两个,就是pagenum跟JsonCallBack,pagenum从英文上很明显能看出来就是页码,JsonCallBack又是啥呢?
https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg?g_tk=2058499274&jsonpCallback=jsoncallback7494258674829413&loginUin=2230661779&hostUin=0&format=jsonp&inCharset=utf8&outCharset=GB2312&am
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1762
1762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









